L’impact de l’ambiguïté sur les anticipations
subjectives déclarées
Mémoire Manuel Paradis Maîtrise en économique Maître ès sciences (M.Sc.) Québec, Canada © Manuel Paradis, 2014Résumé
Nous avons réalisé une expérience dans laquelle les participants ont pu exprimer des antici-pations subjectives sous forme de probabilité de deuxième et de premier ordre. Les données recueillies lors de l’expérience permettent de calculer pour chacun des participants, à par-tir des probabilités de premier ordre déclarées une série de probabilités de deuxième ordre estimées. La comparaison des probabilités de deuxième ordre déclarées et estimées, à l’aide d’une fonction de pondération de probabilité, permet de classer les participants en 3 types de comportements concernant la sur-pondération ou la sous-pondération des probabilités de première ordre déclarées par rapport à celles deuxième ordre. Les données recueillies per-mettent de plus d’observer l’impact de l’ambiguïté sur les anticipations subjectives déclarées et l’hétérogénéité des comportements des participants.
Le premier type de comportement pondère correctement les probabilités de deuxième ordre déclarées par rapport à celle que l’on estime. Le deuxième type de comportement est modal : on observe une pondération plus importante des distributions de deuxième ordres déclarées par rapport à celle que l’on estime. Le troisième type de comportement est l’inverse du deuxième type. Les données obtenues lors de l’expérience permettent d’établir que 55% des participants de l’expérience appartiennent au premier type, 23% au deuxième et 21% au troisième.
Table des matières
Résumé iii
Table des matières v
Liste des tableaux vii
Liste des figures ix
Remerciements xiii
Introduction 1
1 Revue de la littérature 5
1.1 Ambiguïté . . . 5
1.2 Anticipations subjectives déclarées . . . 6
2 L’expérience 7
2.1 Détail administratif. . . 7
2.2 Plan expérimental . . . 7
3 Méthodes d’estimations 11
3.1 Anticipations subjectives estimées. . . 11
3.2 Estimation des paramètres de la fonction de pondération de probabilités . . . . 14
3.3 Courbe de pondération de probabilités . . . 16
3.4 Interprétation du paramètre α . . . 16
4 Descriptions des données et résultats 19
4.1 Paramètres ˆα et ˆβ . . . 19
4.2 Courbe de pondération de probabilités, anticipations subjectives déclarées et anticipations subjectives estimées . . . 22
4.3 Absence de variation et variation des caractéristiques du paramètre ˆα . . . 23
Conclusion 29
A Instructions - Traitement de base 31
B Instructions - Traitement modifié 39
Bibliographie 47
Liste des tableaux
4.1 Statistiques descriptives paramètre ˆα . . . 19
4.2 Statistiques descriptives paramètre ˆβ . . . 20
4.3 Utilisation de l’option "je ne sais pas" - Faible ambiguïté . . . 21
4.4 Utilisation de l’option "je ne sais pas" - Forte ambiguïté . . . 22
4.5 Absence de variation des caractéristiques du paramètre ˆα . . . 25
4.6 Variation des caractéristiques du paramètre ˆα . . . 27
C.1 Traitement de Base - α < 1 . . . 41 C.2 Traitement de Base - α > 1 . . . 41 C.3 Traitement de Base - α = 1 . . . 42 C.4 Traitement modifié- α < 1 . . . 42 C.5 Traitement modifié- α > 1 . . . 43 C.6 Traitement modifié - α = 1 . . . 43
C.7 Traitement de Base - 6 premières périodes de prédiction - α < 1 . . . 44
C.8 Traitement de Base - 6 premières périodes de prédiction - α > 1 . . . 44
C.9 Traitement de Base - 6 premières périodes de prédiction - α = 1 . . . 45
C.10 Traitement modifié - 6 premières périodes de prédiction - α < 1 . . . 45
C.11 Traitement modifié - 6 premières périodes de prédiction - α > 1 . . . 46
Liste des figures
2.1 Interface graphique de l’expérience, probabilité de deuxième ordre . . . 8
2.2 Interface graphique de l’expérience, construction d’histogramme. . . 9
2.3 Différent niveau d’ambiguïté. À gauche : faible ambiguïté. À droite : forte ambiguïté. . . 10
3.1 Graphique composé des Ptk etPˆ˜tk du participant 20606. . . 13
3.2 Exemple de courbe de pondération probabilité estimée pour le participant 20606, α = 2.93 et β = 1.1 . . . 16
3.3 Impact d’une variation des paramètres α (0.25, 0.5, 1.5, 3.5 ) sur la courbe de pondération de probabilité, β constant. . . . 17
4.1 Traitement de base . . . 20
4.2 Traitement modifié, sans les participants 30705 et 30706 . . . 21
4.3 4 participants au traitement de base avec un paramètre ˆα plus grand que 1 . . . . 22
4.4 4 participants au traitement de base avec un paramètre ˆα plus petit que 1 . . . . 23
4.5 Traitement de base, 6 premières périodes . . . 24
4.6 Traitement modifié, sans les participants 30705 et 30706, 6 premières périodes. . . 25
4.7 4 participants au traitement de base avec un paramètre ˆα plus grand que 1, 6 premières périodes . . . 26
4.8 4 participants au traitement de base avec un paramètre ˆα plus petit que 1, 6 premières périodes . . . 26
A.1 Instructions - traitement de base . . . 31
A.2 Instructions - traitement de base . . . 32
A.3 Instructions - traitement de base . . . 32
A.4 Instructions - traitement de base . . . 33
A.5 Instructions - traitement de base . . . 33
A.6 Instructions - traitement de base . . . 34
A.7 Instructions - traitement de base . . . 34
A.8 Instructions - traitement de base . . . 35
A.9 Instructions - traitement de base . . . 35
A.10 Instructions - traitement de base . . . 36
A.11 Instructions - traitement de base . . . 36
A.12 Instructions - traitement de base . . . 37
A.13 Instructions - traitement de base . . . 37
B.1 Instructions - traitement modifié . . . 39
B.3 Instructions - traitement modifié . . . 40
« Je viens te chercher dans environ 5 minutes, peut-être 10, je sais pas trop, c’est dur à dire. »
Remerciements
Je remercie chaleureusement Monsieur Charles Bellemare et Madame Sabine Kröger pour leur soutient, appui et conseils. Je remercie Xavière Audet Mackay et Marie-Claire Gagnon pour les conseils et accompagnement durant mon parcours académique. Je remercie finalement Steeve Marchand pour sa voiture et ce même s’il refuse jusqu’à ce jour de lire mon mémoire.
Introduction
Gilboa et al.(2008) définissent le risque comme une situation où les probabilités des différents états du monde sont connues ou, du moins, dans laquelle il est possible de les connaître et de les calculer à partir de l’information disponible. Ils définissent ensuite l’incertitude comme une situation où les probabilités sont inconnues ; il est impossible de les déduire, de les calculer ou de les estimer de manière objective. En présence d’incertitude, l’approche classique est de supposer que l’individu forme des anticipations subjectives à partir de l’information dispo-nible. De plus, Savage (1954) a proposé que l’individu se comporte comme s’il formait une distribution d’anticipation subjective unique. Or, Ellsberg(1961) démontra qu’il est possible de concevoir des situations dans lesquelles l’individu ne forme pas nécessairement une distri-bution d’anticipation subjective unique : il peut en former plusieurs ou aucune. On appelle ce concept l’ambiguïté.
Afin de modéliser le choix de l’individu en présence d’incertitude, on considère généralement ses préférences, exprimées par sa fonction d’utilité, et les anticipations subjectives des diffé-rents états du monde pertinents à sa décision. A posteriori, lorsque que l’on cherche à faire de l’inférence à partir de choix observés, on rencontre un problème d’identification impor-tant : combinées, des anticipations subjectives et des préférences différentes peuvent générer les mêmes choix observés. Il devient alors impossible de distinguer les unes des autres. Bien que l’on puisse émettre certaines hypothèses expliquant la façon dont les individus forment des probabilités subjectives, Manski (2004) souligne qu’il est possible, voire souhaitable, de demander directement aux individus leurs anticipations subjectives : il s’agit alors d’antici-pations subjectives déclarées. Manski propose aussi de permettre aux individus de rapporter l’ambiguïté lors de leurs déclarations.
Généralement, on collecte les anticipations subjectives déclarées par le biais de sondages. Une pratique de plus en plus répandue est de recueillir les déclaration sous forme d’intervalles : plutôt que de demander la probabilité subjective d’un événement, on demandera l’anticipation subjective que la probabilité de l’événement se situe dans un certain intervalle. En répétant l’exercice pour différents intervalles, on pourra ainsi construire une distribution d’anticipations subjectives à partir des réponses obtenues. Le désavantage de cette façon de faire est que le répondant ne pourra exprimer d’ambiguïté, celui-ci étant forcé de ne déclarer qu’une seule
distribution d’anticipation subjective.
L’objectif de ce travail est d’établir une caractérisation des anticipations subjectives déclarées en présence d’ambiguïté. Une particularité de notre travail la capacité d’analyse de l’hétéro-généité des anticipations subjectives par rapport à différents niveaux d’ambiguïté.
Nous avons réalisé une expérience durant laquelle les participants ont observé des réalisations de profits durant 100 périodes en sachant que ces réalisations étaient générées par l’une des trois distributions de profit affichées à l’écran. Ici, une distribution de profit est définie sur 6 intervalles, soient [-30,-20], [-20,-10], [-10, 0], [0,10], [10,20], [20,30]. À chaque dix périodes, nous avons demandé aux participants d’évaluer la probabilité que chacune des distributions affichées soit celle qui génère les réalisations de profit observées.
Nous avons ensuite demandé aux participants de rapporter leurs anticipations subjectives concernant la probabilité que la réalisation de profit suivante se situe dans chacun des inter-valles mentionnés plus haut. Essentiellement, il s’agissait ici de construire un histogramme, soit une distribution de probabilité du premier ordre.
Notons qu’on définit généralement dans la littérature les a priori, soit, dans ce cas, les dis-tribution de profit affichées, comme des probabilités de premier ordre. On définit ensuite les anticipations subjectives de l’individu1 par rapport à ces a priori comme des probabilités de deuxième ordre. Les participants ont donc déclaré dans la première partie de l’expérience des probabilités du deuxième ordre, tandis qu’ils ont déclarés dans la deuxième partie de l’expérience des probabilités de premier ordre.
Les participants ont répété l’expérience en situation de faible et de forte ambiguïtés ; la moitié d’entre eux ont eu accès à une option leur permettant de répondre «je ne sais pas» lors de la déclaration de probabilité de deuxième ordre. Cette option à été mise à leur disposition afin qu’ils puissent exprimer l’absence d’anticipation ou l’absence de volonté d’exprimer leurs anticipations.
Les données recueillies lors de l’expérience nous permettent de calculer pour chacun des participants, à partir des histogrammes construits, une série de probabilité de deuxième ordre estimé. On calcule ensuite, à partir des probabilités de deuxième ordre estimées et celles effectivement déclarées, les paramètres d’une fonction de pondération de probabilités. Les paramètres de la fonction de pondération de probabilités nous permettent de classer les participants par types de comportement.
Le premier type de comportement représente une correspondance entre les probabilités de deuxième ordres déclarées et celles estimées à partir de l’histogramme construit par le
parti-1. Dans notre cas il s’agira de l’évaluation de la probabilité que chacune des distributions affichées soit celle qui génère les réalisations de profit observées.
cipant. Autrement dit, l’histogramme construit par le participant semble être une réduction des trois distributions de profits affichées en fonctions des probabilités de deuxième ordre déclarées.
Le deuxième type de comportement est modal : on observe une pondération plus importante des distributions de deuxième ordres déclarées comme plus probables dans l’histogramme construit par le participant : celui-ci n’est pas une réduction des trois distributions de profits en fonction des probabilités de deuxième ordre déclarées, mais plutôt le résultat d’une sur-pondération des distributions déclarées comme plus probables.
Le troisième type de comportement est l’inverse du deuxième type : on observe une pondé-ration moins importante des distributions déclarées comme plus probables ans l’histogramme construit par le participant : celui-ci n’est pas une réduction des trois distributions de pro-fits en fonction des probabilités de deuxième ordre déclarées, mais plutôt le résultat d’une sous-pondération des distributions déclarées comme plus probables.
Les données obtenues lors de l’expérience permettent d’établir que 55% des participants de l’expérience appartiennent au premier type, 23% au deuxième et 21% au troisième. De plus, nous constatons l’absence de différence significative entre les résultats des participants ayant accès à l’option « je ne sais pas » et ceux n’ayant pas cette option. Nous observons aussi une absence de variation des comportements chez plus de 50% des participants lorsqu’ils font face à différents niveaux d’incertitude.
Le chapitre 1 procède à un bref survol de littérature. Le chapitre 2 décrit l’expérience. Le chapitre 3 définit la méthode d’estimation et explique les particularités de la fonction de pondération de probabilités que nous utilisons. Le chapitre 4 décrit les données et expose les résultats. Enfin, nous résumons les conclusions de l’analyse.
Chapitre 1
Revue de la littérature
L’objectif de ce chapitre est de présenter brièvement le concept d’ambiguïté et les anticipations subjectives déclarées.
1.1
Ambiguïté
Von Neumann and Morgenstern (1944) ont développé le modèle d’utilité espérée (EU) qui considère seulement les situations risquées.Savage(1954) a adapté la théorie de von Neumann et Morgenstern pour développer la théorie de l’utilité espérée subjective (SEU). Ce modèle prend en compte l’incertitude en présumant que l’individu se comporte comme s’il formait une distribution de probabilités subjectives unique lors de la maximisation de son utilité.
Ellsberg(1961), par une expérience simple, arriva à démontrer que les individus, tout en étant rationnels ne se conforment pas toujours à l’hypothèse d’unicité de distribution de probabilités subjectives de Savage. Il est donc possible de croire que l’individu peut former plusieurs distributions de probabilités subjectives par rapport au même ensemble d’événements1. Plusieurs se sont consacrés à recréer l’expérience d’Ellsberg dans différents contextes.Camerer and Weber(1992) résument une série d’études influencées et inspirées de l’expérience des urnes d’Ellsberg. Ils recensent plusieurs résultats obtenus de manières expérimentales démontrant l’existence et l’influence de l’ambiguïté sur les décisions. Ils soulignent qu’il est essentiel de prendre en compte ce concept lorsque l’on modélise les choix des individus. Halevy (2007) démontra que l’attitude face à l’ambiguïté était fortement associée à la capacité de réduction
1. « Consider Ellsberg’s “Two Urns” problem : there are two urns, each containing 100 balls, which can be either red or black. It is known that the first urn holds 50 red and 50 black balls. The number of red (black) balls in the second urn is unknown. Two balls are drawn at random, one from each urn. The subject is asked to bet on the color of one of the balls. A correct bet wins her $100, an incorrect guess loses nothing (and pays nothing). The modal response exhibits uncertainty (ambiguity) aversion : the decision maker prefers a bet on red or black drawn from the first urn to a bet on red or black drawn from the second urn, but she is be indifferent between betting on red or black in each urn separately. » Halevy, Yoram et Vincent Feltkamp, A bayesian approach to uncertainty aversion, The Review of Economic Studies, 2005, p. 1
de probabilités de second ordre et a avancé que la non réduction de probabilités de seconde ordre pouvait, en partie, expliquer les observations d’Ellsberg.
1.2
Anticipations subjectives déclarées
Dans le cadre de l’expérience que l’on décrira plus bas, les participants sont appelés à rapporter des probabilités en situation d’incertitude ; il s’agit d’anticipations subjectives déclarées. Il importe d’abord de savoir si les participants d’une expérience ont la capacité d’articuler leurs anticipations en termes de distribution de probabilités.Manski(2004) affirme que les individus sont capables et enclins à le faire. Il maintient que les individus sont tout aussi aptes à répondre de cette manière qu’à répondre par une probabilité unique et qu’ils utilisent l’ensemble du domaine des probabilités afin de préciser la distrbution de leurs anticipations.Dominitz and Manski(1994) parviennent aux mêmes conclusions avec un échantillon d’adolescents sur des questions à propos de rendement scolaire2. Ils soulignent aussi que la collecte d’anticipations subjectives déclarées sous forme de probabilités ne souffre pas des mêmes possibilités de biais que celle des anticipations subjectives déclarées sous forme « verbale ».
Fischhoff and Bruine De Bruin(1999) ont souligné un doute quant à la compréhension des participants par rapport à certaines anticipations subjectives déclarées sous forme de proba-bilités : selon eux, la probabilité déclarée 50 sur 100 ou 50% serait parfois mal utilisée par les participants et aurait plutôt comme signification l’ignorance quant à la situation et non la pro-babilité objective qu’elle représente.Kleinjans and van Soest(2010) se sont aussi attardés sur la question, déterminant dans leur étude qu’une majorité des réponses correspondant à 50% était dues à un effet d’arrondissement. Dans l’expérience décrite plus bas, nous avons permis à la moitié des participants de déclarer « je ne sais pas » afin de vérifier si ces considérations sont pertinentes dans le cadre de notre travail.
Bellemare et al.(2008) démontrent aussi la capacité des individus à déclarer des anticipations en termes de probabilités. Notamment, ils ont suggéré que l’utilisation d’anticipations subjec-tives déclarées générait de meilleures prédictions (intra et extra échantillon) que l’utilisation d’hypothèses de rationalité des anticipations des participants.
L’expérience décrite dans le chapitre suivant nous permet de recueillir les anticipations sub-jectives déclarées des participants en situation d’ambiguïté. On verra au chapitre 3 de quelle manière nous pouvons, à partir des anticipations subjectives déclarées obtenues, estimer les paramètres d’une fonction de pondération de probabilités et caractériser les participants par type.
2. "We find that respondents, even ones as young as high school juniors, are willing and able to respond meaningfully to questions eliciting their earnings expectations in probabilistic form.” Dominitz and Manski
(1994) p. 1
Chapitre 2
L’expérience
Ce chapitre décrit le protocole expérimental. Les séances de l’expérience ont eu lieu entre octobre 2012 et février 2013 au Laboratoire d’Économie Expérimentale de l’Université Laval (LEEL).
2.1
Détail administratif
Au total, 89 participants se sont inscrits volontairement à l’expérience par le système de recrutement du LEEL dans 7 séances regroupant de 9 à 24 participants. Ils ont été rémunérés 30 dollars canadiens pour leur participation à l’expérience, 5 dollars canadiens pour leur ponctualité et, finalement, 5 dollars canadiens pour remplir un sondage sur leur niveau de connaissance à propos des probabilités. Les séances ont eu une durée d’environ deux heures. À leur arrivée au laboratoire, les participants ont reçu un cahier d’instructions.1 Ils ont aussi visionné une vidéo des instructions au poste informatique leur étant assigné aléatoirement. Un minimum de deux expérimentateurs était présents durant les séances, disponibles pour répondre aux questions des participants. L’expérience a été programmée avec le logiciel Z-Tree (Fischbacher, 2007). En tout temps, les participants ont eu accès à du papier et à un crayon afin d’effectuer des calculs ou prendre des notes ainsi qu’à une calculatrice disponible via l’interface graphique de l’expérience.
2.2
Plan expérimental
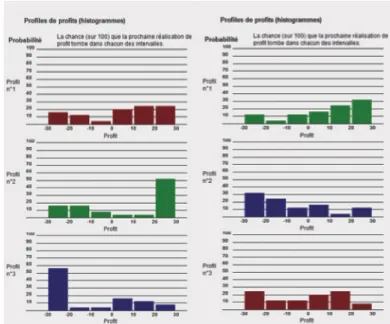
Le participant est d’abord informé qu’il observera les réalisations de profit d’une compagnie. Les réalisations observées proviennent d’une des trois distributions de profit affichées à l’écran (figure 2.1). Le participant ne sait pas laquelle des trois distributions de profit génère les réalisations de profit observées.
Une distribution de profit est un histogramme comprenant six intervalles : [-30,-20], [-20,-10], [-10, 0], [0,10], [10,20], [20,30].
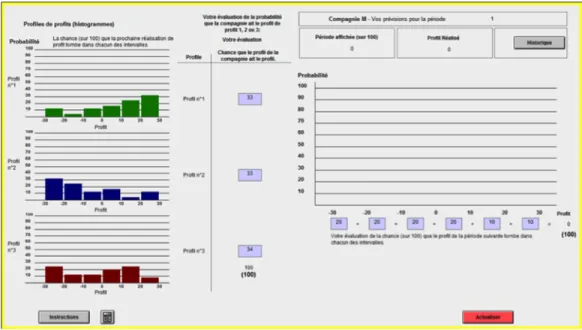
Figure 2.1 – Interface graphique de l’expérience, probabilité de deuxième ordre
Le premier objectif du participant est de déterminer, par une déclaration en pourcentage, de laquelle des trois distributions de profit affichées à l’écran proviennent les réalisations de profit observées. Autrement dit, nous demandons au participant son «évaluation de la probabilité que la compagnie (dont il observe les réalisations de profit) ait le profil de profit 1, 2 ou 3» (figure 2.1).2 Par exemple, à la période 0, lorsqu’il n’a pas observé encore de réalisation de profit, une réponse possible serait de déclarer qu’il y a 33% de chance que le vrai profil de profit soit le numéro 1, 33% de chance que ce soit le numéro 2 et 34% de chance que ce soit le numéro 3. Il s’agit donc d’une distribution de distribution de probabilités de deuxième ordre. Le deuxième objectif du participant est de construire un histogramme de six intervalles qui reflète son « évaluation de la chance sur 100 que le profit de la période suivante tombe dans chacun des intervalles » (voir figure 2.2). Cette étape correspond à celle que l’on demande normalement aux individus lorsqu’il s’agit de rapporter des anticipations subjectives lors de sondage, soit de rapporter une distribution unique de probabilités. Il s’agit donc d’une distribution de probabilités de premier ordre
Après avoir réalisé les deux tâches demandées, le participant observe les réalisations de profit durant 10 périodes. L’écran affiche un histogramme qui s’adapte selon les réalisations de profit tirées à partir de la distribution de profit réelle. Le participant peut, en tout temps, consulter l’histogramme des réalisations de profit, ainsi que la liste des réalisations des profits antérieurs.
2. On appelle les distributions des profils de profit dans le cadre de l’expérience
Supposons que les réalisations de profit des périodes 1 à 9 observées permettent au participant de croire qu’il est maintenant plus probable qu’elles proviennent du profil de profit numéro 1, qu’il est peu probable qu’elles proviennent du profil de profit numéro 2 et qu’il est très improbable qu’elles proviennent du profil de profit numéro 3. À la période 9, le participant peut modifier sa prédiction initiale et déclarer, par exemple, qu’il y a maintenant, selon lui, 60% de chance que le vrai profil de profit soit le profil de profit numéro 1, 30% de chance que le vrai profil de profit soit le profil de profit numéro 2 et 10% de chance que le vrai profil de profit soit le profil de profit numéro 3. Il doit ensuite, encore une fois, construire un histogramme qui reflète son «évaluation de la chance sur 100 que le profit de la période suivante tombe dans chacun des intervalles».
Figure 2.2 – Interface graphique de l’expérience, construction d’histogramme
Le participant répète ces deux tâches aux périodes 0, 9, 19, 29, 39, 49, 59, 69, 79, 89 et 99 en ajustant ses anticipations déclarées selon les réalisations de profit qu’il observe. On numérotera ces périodes où le participant rapporte ses anticipations de 1 à 11 (voir section suivante).
Le participant réalise la procédure expliquée plus haut deux fois, soit dans un contexte de faible ambiguïté et dans un contexte de forte ambiguïté (figure2.3). Une ambiguïté faible se traduit ici par des profils de profit affichés à l’écran très différents les uns des autres. Inversement, une ambiguïté forte se traduit par des profils de profit affichés à l’écran très semblables les uns aux autres. L’ordre des niveaux d’ambiguïté est choisi de manière aléatoire. Parmi les trois distributions de profit affichées à l’écran, la distribution générant les profits observés est aussi choisie de manière aléatoire au début de l’expérience.
Figure 2.3 – Différent niveau d’ambiguïté. À gauche : faible ambiguïté. À droite : forte ambiguïté.
Nous observons donc 22 périodes où le participant rapporte ses anticipations.
Le traitement de base (47 participants) correspond à la procédure expliquée plus haut. Le traitement modifié (42 participants) correspond à la procédure décrite plus haut avec, comme unique différence, l’ajout d’un bouton qui permet de déclarer « je ne sais pas » lorsqu’il s’agit de déterminer lequel des trois profils de profit affichés à l’écran est le profil de profit réel. Le participant qui n’a pas formé d’anticipations subjectives ou qui ne souhaite pas les déclarer pourra ainsi utiliser cette option dans ce traitement. Reprenant l’exemple plus haut, à la période 0, soit lorsque le participant n’a pas encore observé de réalisation de profit, une réponse possible est, dans le deuxième traitement, d’appuyer sur le bouton « je ne sais pas » et ainsi d’éviter de déclarer des pourcentages. Le participant peut, dans le deuxième traitement, utiliser le bouton « je ne sais pas » à chaque période où il doit rapporter ses anticipations. À la fin de l’expérience, le participant est invité à répondre à un sondage visant à déterminer son niveau de connaissance au sujet des probabilités et à donner des informations sur son champ d’études et sa stratégie durant l’expérience.
Chapitre 3
Méthodes d’estimations
3.1
Anticipations subjectives estimées
Les participants ont répété l’expérience décrite plus haut deux fois, soit en contexte de faible et de forte ambiguïté. Donc, pour chaque itération de l’expérience, les participants ont dus procéder à chaque étape 11 fois, c’est à dire qu’ils ont dus à 11 reprises déclarer 3 probabilités de deuxième ordre et construire à 11 reprises un histogramme de probabilités de premier ordre.
Nous obtenons donc les données suivantes pour chaque participant : 66 probabilités subjec-tives, soit les probabilités de deuxième ordre exprimées en pourcentage, en groupes de trois, correspondant aux trois distributions de profit affichées à l’écran, et 22 constructions d’histo-gramme, soit 22 distributions de probabilités de premier ordre.
Les probabilités de deuxième ordre déclarées sont notées
Ptk| Ptk∈ [0, 1] et
k X
k=1
Ptk = 1 ∀ t (3.1)
où k ∈ {1, 2, 3} et représente le profil de profit auquel correspond la probabilité déclarée et où t ∈ {1, 2, . . . , 11} et correspond à la période à laquelle est faite la prédiction.1
Nous notons les probabilités affichées dans les intervalles des distributions de profit affichées à l’écran πtk| πkt ∈ [0, 1] et j X j=1 πtk= 1 ∀ k (3.2)
1. Dans la section précédente, on note que chaque itération de l’expérience s’étale sur 100 périodes mais que le participant ne rapporte ses anticipations qu’aux périodes 0, 9, 19, 29, 39, 49, 59, 69, 79, 89 et 99. D’où
Nous notons les probabilités déclarées par le participant dans la construction d’histogramme, ce que nous avons plus tôt défini comme une distribution de probabilité de premier ordre,
πj,tu | πuj,t∈ [0, 1] et
j X
j=1
πj,tu = 1 ∀ t (3.3)
où j ∈ {1, 2, 3, 4, 5, 6} représente l’intervalle de l’histogramme auquel correspond la probabilité déclarée ( j = 1 représentera donc l’intervalle [-30,-20], j = 2 l’intervalle [-20,-10] et ainsi de suite ).
À titre de rappel, soulignons ici que l’objectif de notre démarche est d’établir un lien entre les équations3.1,3.2et3.3. Essentiellement, nous tentons de comprendre comment le participant utilise les équations3.1et3.2 afin de former l’équation 3.3.
À partir des données, nous construisons le programme de minimisation suivant pour chaque période t min ˜ P1, ˜P2, ˜P3 j X j=1 (πju− ˜P1∗ π1 j − ˜P2∗ π2j − ˜P3∗ πj3)2 (3.4)
Sous contrainte que
˜
P1+ ˜P2+ ˜P3 = 1 (3.5)
Et
0 ≤ ˜Pi ≤ 1 où i ∈ 1, 2, 3, (3.6)
Donc, pour chaque période t nous obtenons
Pt1 etPˆ˜1t
Pt2 etPˆ˜2t (3.7)
Pt3 etPˆ˜3t
soit une comparaison des pondérations déclarées et des pondérations estimées. En théorie, si le participant est parfaitement sophistiqué en terme de probabilité, on pourrait croire que l’équation3.3est le résultat d’un calcul intégrant exactement les équations3.1et3.2et donc que Ptk=Pˆ˜kt. En pratique on verra plus loin que ce n’est pas nécessairement le cas.
Rappelons ici que Pk
t correspond à la probabilité de deuxième ordre effectivement déclarée
par le participant et que ˜Ptk correspond à la probabilité de deuxième estimée à partir des distributions de premier ordre déclarée par le participant.
Nous obtenons donc 66 paires de coordonnées (P et P ) par participant. Nous pouvons ainsiˆ˜
tracer le graphique de ces paires de coordonnées en mettant les anticipations subjectives dé-clarées (P ) du participant en abscisse et les anticipations subjectives estimées (P ) en ordonnéeˆ˜
(figure 3.1).
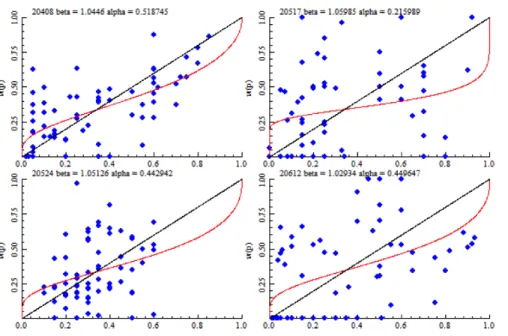
Figure 3.1 – Graphique composé des Ptk et Pˆ˜ t
k du participant 20606
Ici, chaque point du graphique représente une paire de coordonnées. La droite à 45 degrés représente l’espace où l’anticipation subjective déclarée du participant correspond exactement à l’anticipation subjective estimée à partir de l’histogramme construit (Ptk=Pˆ˜kt).
3.1.1 Relation entre anticipation subjective déclarée et anticipation subjective estimée
Dans le cadre de l’expérience, nous avons d’abord demandé au participant de faire « l’évalua-tion de la probabilité que la compagnie (dont il observe les réalisal’évalua-tions de profit) ait le profil de profit 1, 2 ou 3 ». Nous lui avons ensuite demandé « l’évaluation de la chance sur 100 que le profit de la période suivante tombe dans chacun des intervalles ». D’où si
Ptk>Pˆ˜kt (3.8)
c’est que l’anticipation subjective déclarée pour cette distribution de profit est plus grande que l’anticipation subjective estimée à partir de l’histogramme construit. Autrement dit, on estime que cette distribution a été pondérée plus fortement dans la construction de l’histogramme par rapport à l’anticipation subjective déclarée qui lui correspond.
Inversement, si
Ptk<Pˆ˜kt (3.9)
c’est que l’anticipation subjective déclarée pour cette distribution de profit est plus petite que l’anticipation subjective estimée à partir de l’histogramme construit. Autrement dit, on estime que cette distribution a été pondérée plus faiblement dans la construction de l’histogramme par rapport à l’anticipation subjective déclarée qui lui correspond.
La figure 3.1 semble donc illustrer un comportement de sous-pondération des distributions de profit correspondant à des anticipations subjectives déclarées faibles (< .4) et une sur-pondération des distributions de profit correspondant à des anticipations subjectives déclarées forte (> .4) lors de la construction de l’histogramme. Autrement dit, le participant sous-pondère ici les distributions de profit auquel il assigne une faible probabilité et sur-sous-pondère les distributions de profit auquel il assigne une forte probabilité lorsqu’il réduit les probabilités de deuxième ordre en probabilités de premier ordre.
On utilisera les deux séries d’anticipations, celles déclarées et celles estimées, afin de d’estimer les paramètres de la fonction de pondération de probabilités.
3.2
Estimation des paramètres de la fonction de pondération
de probabilités
L’idée qu’un individu puisse traiter les probabilités de manière non-linéaire a été développée par Preston and Baratta (1948). Par une expérience dans laquelle ils demandaient à des participants d’assigner une valeur à une loterie, ils ont pu démontrer que ceux-ci avaient une échelle de probabilités « psychologique » en termes d’évaluation de valeur de loterie qui ne correspondait pas à la valeur probabiliste de la dite loterie. Ils furent, entre autres, les premiers à démontrer que les participants surpondéraient systématiquement les probabilités objectives faibles et sous-pondéraient les probabilités objectives élevées. Ils avancèrent même l’idée d’une relation fonctionnelle entre échelle de probabilités « psychologique » et probabilités réelles.
Cette idée correspond à la fonction de pondération de probabilités tel que nous l’entendons. La différence principale repose sur le fait que, dans le cas de Preston et Baratta, il s’agissait d’une fonction de pondération de probabilités qui associait une probabilité objective à une probabilité subjective. Dans notre cas, il s’agira plutôt d’une fonction de pondération de probabilité qui relie une probabilité subjective déclarée à une probabilité subjective estimée. La fonction de pondération de probabilités que l’on utilisera plus bas à été développée par
Prelec (1998). Sa contribution principale à été de développer cette fonction selon quatre propriétés établies par Tversky and Kahneman (1992) dans le développement de la théorie des perspectives cumulatives : selon eux, la fonction doit être régressive, asymétrique, en forme de S et finalement réflective. Par régressive et en forme de S, on entend que la forme de la fonction doit être concave puis convexe ( elle peut par contre aussi être convexe puis concave selon la valeur des paramètres ). La qualité régressive de la fonction permet de capter les comportements non-linéaires de pondération de probabilités. Par asymétrique, on entend qu’elle doit croiser une droite à 45 degrés environ au tiers d’un domaine allant de 0 à 1. L’aspect réflectif de la fonction réfère à une symétrie entre probabilités concernant une perte et probabilités concernant un gain, aspect que nous ignorerons ici. On doit noter que la fonction de pondération de probabilités développé par Prelec l’a été dans un contexte de risque. Nous l’utilisons ici dans un autre contexte pour son caractère succinct et facile à estimer, avec comme objectif d’établir une caractérisation des anticipations subjectives déclarées reposant sur peu de paramètres. En ce sens, cette fonction convient relativement bien à ces spécifications.
Il s’agit donc d’estimer les paramètres d’une courbe de pondération de probabilités pour chaque participant. La forme fonctionnelle de cette courbe de pondération de probabilités (Prelec,1998) est définie tel que
ˆ˜
P = exp(−β(− log(P )α)) (3.10)
Nous construisons le programme de minimisation suivant
min α,β t X t=1 k X k=1 (Pˆ˜kt = exp(−β(− log(Ptk)α))2 (3.11)
duquel nous obtenons pour chaque participant deux paramètre, ˆα et ˆβ. À partir de ces deux
paramètres, nous pouvons construire une courbe de pondération de probabilités (figure 3.2). Cette courbe se superpose à une droite à 45 degrés quand les paramètres α et β sont égaux à 1. Lorsque que α et β ne sont pas égaux à 1, la courbe a généralement une forme en S ou en S inversé. Plus précisément, le paramètre α détermine l’amplitude de la courbe par rapport à la droite à 45 degrés et sa courbure, tandis que le paramètre β détermine le point d’inflexion de la courbe. On notera que dans le cas où nous superposons la courbe de pondération de
probabilités à une droite à 45 degrés, le point d’inflexion est toujours le point où la courbe et la droite se croisent.
Figure 3.2 – Exemple de courbe de pondération probabilité estimée pour le participant 20606, α = 2.93 et β = 1.1
Finalement, nous établissons à l’aide d’un test joint (Wald) si les paramètres ˆα et ˆβ sont
significativement différents de 1.
Pour la suite du travail, nous rapporterons les résultats pour les paramètres ˆα et ˆβ, mais nous
interprèterons seulement le paramètre ˆα.
3.3
Courbe de pondération de probabilités
La valeur du paramètre α affecte la forme de la courbe de pondération de probabilités, tel qu’illustré dans la figure3.3.
– Quand α est plus petit que 1, la courbe est concave puis convexe (panel du haut, figure
3.3).
– Quand α est plus grand que 1, la courbe est convexe puis concave (panel du bas, figure
3.3).
– Nous constatons aussi que plus α s’éloigne de 1, plus la courbe à une grande amplitude.
3.4
Interprétation du paramètre α
Nous pouvons interpréter le paramètre ˆα du participant en termes de type de comportement :
Figure 3.3 – Impact d’une variation des paramètres α (0.25, 0.5, 1.5, 3.5 ) sur la courbe de pondération de probabilité, β constant.
– Lorsque qu’il est non significativement différent de 1, nous présumerons qu’il s’agit du premier type de comportement, soit une correspondance entre les probabilités de deuxième ordre déclarées et celles estimées à partir de l’histogramme construit par le participant. Autrement dit, l’histogramme construit par le participant semble être une réduction des trois distributions de profit en fonctions des probabilités de deuxième ordre déclarées.
– Lorsque le paramètre ˆα est plus grand que 1, il s’agira du deuxième type de
comporte-ment, soit le type modal : on observe une pondération plus importante des distributions déclarées comme plus probables lorsque le participant construit l’histogramme. Autre-ment dit, l’histogramme construit par le participant n’est pas une réduction des trois distributions de profit en fonction des probabilités de deuxième ordre déclarées, mais plutôt le résultat d’une sur-pondération des distributions déclarées comme plus pro-bables.
– Lorsque le paramètre ˆα est plus petit que 1, il s’agira du troisième type de comportement,
soit l’inverse du deuxième type : on observe une pondération moins importante des distri-butions déclarées comme plus probables lorsque le participant construit l’histogramme. Autrement dit, l’histogramme construit par le participant n’est pas une réduction des trois distributions de profit en fonction des probabilités de deuxième ordre déclarées, mais plutôt le résultat d’une sous-pondération des distributions déclarées comme plus probables.
– Finalement, plus le paramètre ˆα s’éloignera de 1, plus le type de comportement sera
Chapitre 4
Descriptions des données et
résultats
4.1
Paramètres ˆ
α et ˆ
β
Les tableaux 4.1et4.2rapportent les caractéristiques des paramètres ˆα et ˆβ des participants
à l’expérience selon le traitement.1 2
Table 4.1 – Statistiques descriptives paramètre ˆα
Traitement de base Traitement modifié ˆ α < 1 (type 3) (21%) 10 9 ˆ α = 1 (type 1) (55%) 26 23 ˆ α > 1 (type 2) (24%) 11 10 minimum -0,12 0 maximum 7,82 62,26 moyenne 1,34 14 Écart type (1,28) (11,22)
Statistique t d’égalité de moyenne ˆα 1,51
Dans chacun des traitements, plus de la moitié des participants ont des paramètres ˆα et ˆβ
non-significativement différents de 1. La moyenne des ˆα et des ˆβ n’est pas significativement
différente entre les traitements.
1. Le traitement de base correspond à l’expérience sans l’option de déclarer «je ne sais pas», le traitement modifié correspond à l’expérience avec l’option de déclarer «je ne sais pas»
Table 4.2 – Statistiques descriptives paramètre ˆβ
Traitement de base Traitement modifié ˆ β < 1 (12%) 7 4 ˆ β = 1 (55%) 26 23 ˆ β > 1 (33%) 14 15 minimum 0,52 0,89 maximum 1,36 554,95 moyenne 1,01 4,90 Écart type (11,22) (85,45)
Statistique t d’égalité de moyenne ˆβ 1,01
Dans les figures 4.1 et 4.2, nous représentons les paramètres ˆα et ˆβ non significativement
différents de 1 par des croix et les paramètres ˆα et ˆβ significativement différents de 1 par des
points3.
Figure 4.1 – Traitement de base
3. Dans le traitement modifié, nous excluons les participants 37005 et 30706 car la trop grande disparité de leurs résultats rendait le graphique illisible.
Figure 4.2 – Traitement modifié, sans les participants 30705 et 30706
On notera qu’un seul participant a, à la fois, des paramètres ˆα et ˆβ significativement plus
petits que 1 dans le traitement de base, aucun dans le traitement modifié.
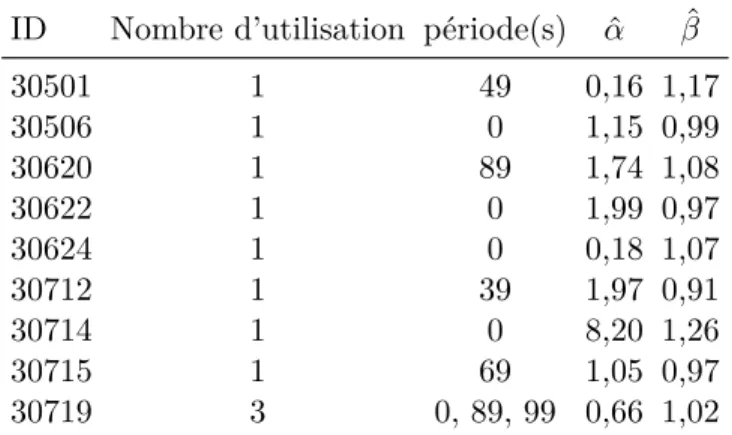
Tel que mentionné dans le chapitre 2, les participants au traitement modifié ont eu la pos-sibilité d’utiliser l’option « je ne sais pas » afin d’éviter d’avoir à déclarer des probabilités concernant les trois profils de profit affichés. L’option a été utilisée 17 fois au total (Table4.3
et 4.4). On remarquera que l’option a été utilisée 11 fois en contexte de forte ambiguïté, 6 fois en contexte de faible ambiguïté. Les tableaux suivant rapporte le numéro d’identification des participants ayant utilisé l’option « je ne sais pas » en contexte de faible et de forte am-biguïté, le nombre d’utilisation, la ou les périodes à laquelle l’option à été utilisée ainsi que leurs paramètre ˆα et ˆβ.
Table 4.3 – Utilisation de l’option "je ne sais pas" - Faible ambiguïté ID Nombre d’utilisation période(s) αˆ βˆ
30617 1 89 1,30 0,95
30624 1 0 0,18 1,07
30714 1 0 8,20 1,26
30715 2 0, 9 1,05 0,97
Table 4.4 – Utilisation de l’option "je ne sais pas" - Forte ambiguïté ID Nombre d’utilisation période(s) αˆ βˆ
30501 1 49 0,16 1,17 30506 1 0 1,15 0,99 30620 1 89 1,74 1,08 30622 1 0 1,99 0,97 30624 1 0 0,18 1,07 30712 1 39 1,97 0,91 30714 1 0 8,20 1,26 30715 1 69 1,05 0,97 30719 3 0, 89, 99 0,66 1,02
4.2
Courbe de pondération de probabilités, anticipations
subjectives déclarées et anticipations subjectives estimées
Pour chaque participant, nous estimons les paramètres de la courbe de pondération de proba-bilités à partir des anticipations subjectives déclarées et des anticipations subjectives estimées (voir chapitre 3). Nous pouvons, tel que mentionné précédemment, superposer ces dernières et la courbe de pondération de probabilités de chaque participant sur un même graphique. Les graphiques4.3et4.4montrent chacun 4 participants au traitement de base, les 4 premiers ayant ˆα significativement plus grand que 1, les 4 derniers avec un ˆα significativement plus
petit que 1.
Figure 4.3 – 4 participants au traitement de base avec un paramètre ˆα plus grand que 1
Figure 4.4 – 4 participants au traitement de base avec un paramètre ˆα plus petit que 1
Nous observons dans les figures 4.3 et 4.4 que le paramètre α semble être plus représentatif des données lorsqu’il est plus grand que 1. Ainsi, nous pouvons observer, selon la caractéri-sation expliquée au chapitre 3, que le paramètre α semble mieux traduire le comportement du troisième type, soit celui dans lequel l’histogramme construit par le participant n’est pas une réduction des trois distributions de profits en fonction des probabilités de deuxième ordre déclarées, mais plutôt le résultat d’une sous-pondération des distributions déclarées comme plus probables.
Dans les deux sous-sections suivantes, nous tenterons d’explorer la variation ou l’absence de variation présentes dans les résultats des participants par la comparaison de leur paramètre
ˆ
α résultant de l’estimation à partir des 6 premières périodes où le participant rapporte ses
anticipations et ceux résultant de l’ensemble de l’expérience. Nous présumons que les anticipa-tions rapportées durant les 6 premières périodes correspondent à un niveau d’incertitude plus grand que durant les 5 dernières. Ainsi, l’analyse du paramètre ˆα des 6 premières périodes
par rapport à l’ensemble de l’expérience est équivalent à l’analyse du paramètre dans des situations d’incertitude différentes, plus précisément en situation d’incertitude décroissante.
4.3
Absence de variation et variation des caractéristiques du
paramètre ˆ
α
Les figures4.5 et4.6 représentent encore une fois les paramètres ˆα et ˆβ, de la même manière
que les figures4.3et4.4, cette fois-ci pour les 6 premières périodes où le participant rapporte ses anticipations. Dans ce cas, parmi les participants ayant des paramètres ˆα et ˆβ,
significative-ment différent de 1, aucun n’a à la fois les deux paramètres plus petit que 1. Bien qu’à première vue les graphiques semblent garder sensiblement la même forme, nous verrons plus loin qu’il existe une variation des caractéristiques chez certains participants lorsque nous considérons leurs paramètres individuels pour les 6 premières périodes et pour l’ensemble de l’expérience. Pour plusieurs participants, par contre, les paramètres conservent les mêmes caractéristiques. Nous considèrerons, dans la prochaine section, des exemples de ce type de comportement en les illustrant graphiquement à l’aide des courbes de pondération de probabilités.
Il importe de comprendre à ce sujet qu’une variation du paramètre ˆα peut être considérée
comme normale. Supposons un participant ayant un paramètre ˆα différent de 1 pour les 6
premières périodes où il rapporte ses anticipations et qui, pour l’ensemble de l’expérience, a un paramètre ˆα non significativement différent de 1. On peut, dans ce cas, présumer que le
comportement de pondération des premières périodes à été compensé par un comportement de pondération inverse en fin d’expérience. On s’inquiétera davantage d’un participant qui passe d’un paramètre ˆα non significativement différent de 1 en début d’expérience à un paramètre
ˆ
α différent de 1 en fin d’expérience.
Figure 4.5 – Traitement de base, 6 premières périodes
Figure 4.6 – Traitement modifié, sans les participants 30705 et 30706, 6 premières périodes
4.3.1 Absence de variation des caractéristiques du paramètre ˆα
Dans le cas du traitement de base, 25 participants conservent les mêmes caractéristiques entre les 6 premières périodes où ils rapportent leurs anticipations et l’ensemble de l’expérience concernant le paramètre ˆα. Dans le cas du traitement modifié, 23 participants conservent les
mêmes caractéristiques concernant ˆα. La table4.5 désagrège les participants n’ayant pas de variation de leur paramètre ˆα selon le type auquel ils appartiennent :
Table 4.5 – Absence de variation des caractéristiques du paramètre ˆα Traitement de base Traitement modifié ˆ α < 1 (type 3) (15%) 7 6 ˆ α = 1 (type 1) (36%) 15 17 ˆ α > 1 (type 2) (3%) 3 0
Les figures4.7et4.8illustrent les résultats des mêmes participants que ceux observés plus haut (figures4.3et4.4), mais ici pour les 6 premières périodes où ils rapportent leurs anticipations. Il s’agit de participants ayant des paramètres qui ne changent pas de caractéristiques entre les 6 premières périodes et l’ensemble de l’expérience.
Figure 4.7 – 4 participants au traitement de base avec un paramètre ˆα plus grand que 1, 6 premières périodes
Figure 4.8 – 4 participants au traitement de base avec un paramètre ˆα plus petit que 1, 6 premières périodes
4.3.2 Variation des caractéristiques du paramètre α
Dans le cas du traitement de base, 22 (25%) participants ont un paramètre ˆα qui varie entre
les 6 premières périodes et l’ensemble de l’expérience. Dans le cas du traitement modifié, 19
(21%) participants ont un paramètre ˆα qui varie entre les 6 premières périodes et l’ensemble
de l’expérience. La table 4.6 illustre les variations des caractéristiques du paramètre ˆα en
désagrégeant les participants par type de variations.
Table 4.6 – Variation des caractéristiques du paramètre ˆα Traitement de base Traitement modifié ˆ α < 1 → ˆα > 1 1 6 ˆ α < 1 → ˆα = 1 0 0 ˆ α = 1 → ˆα < 1 3 4 ˆ α = 1 → ˆα > 1 9 4 ˆ α > 1 → ˆα < 1 3 0 ˆ α > 1 → ˆα = 1 6 5
Conclusion
L’expérience et les méthodes d’estimations décrites plus haut nous permettent de caractériser les anticipations subjectives des individus lorsqu’ils sont en situation d’ambiguïté.
Les paramètres de la fonction de pondération de probabilités que nous estimons nous per-mettent de classer les participants par types de comportement.
Nous définissons trois types de comportement. Le premier type de comportement correspond à un comportement correct de réduction des probabilités de deuxième ordre en probabilité de premier ordre. Le deuxième type de comportement est modal, c’est à dire qu’il correspond à un comportement de sur pondération des distributions déclarées comme plus probables lors de la réduction des probabilités de deuxième ordre en probabilité de premier ordre. Le troisième type de comportement est l’inverse du deuxième type, c’est-à-dire qu’il correspond à un comportement de sous pondération des distributions déclarées comme plus probables lors de la réduction des probabilités de deuxièmes ordres en probabilité de premier ordre. Les données obtenues lors de l’expérience permettent d’établir que 55% des participants de l’expérience appartiennent au premier type, 23% au deuxième et 21% au troisième. De plus, nous constatons l’absence de différence significative entre les résultats des participants ayant accès à l’option « je ne sais pas » et ceux n’ayant pas cette option. Nous observons aussi une absence de variation des comportements chez plus de 50% des participants lorsqu’ils font face à différents niveaux d’incertitude.
Cette classification est une première étape dans une démarche plus large de caractérisation des anticipations subjectives déclarés en situation d’ambiguïté. L’expérience que nous avons construite permet d’observer le comportement des individus qui incorporent de l’information nouvelle et ajustent ainsi leurs anticipations. Cette question, de nature dynamique, mènera à une caractérisation plus complète des anticipations subjectives déclarées. En effet, il s’agira de déterminer les types d’individus en terme de convergence, c’est-à-dire par rapport à leur capacité d’incorporer l’information afin de ne plus être affectés par l’ambiguïté.
Lorsque l’on reconsidère la question des sondages et la cueillette des anticipations subjec-tives sous forme d’intervalles, nous avons noté en introduction que cette manière de faire ne permet pas la déclaration d’ambiguïté. Or, en caractérisant ce type de déclaration, nous
pourrons éventuellement établir certaines mesures de l’ambiguïté. Nous pourrons aussi propo-ser de nouvelles questions à inclure aux sondages afin de détecter la présence d’ambiguïté et l’influence de celle-ci sur les anticipations subjectives déclarées des individus. Une meilleure compréhension de celle-ci permettra une meilleure compréhension des résultats des sondages et conséquemment, une meilleure utilisation de ceux-ci.
Annexe A
Instructions - Traitement de base
Figure A.2 – Instructions - traitement de base
Figure A.3 – Instructions - traitement de base
Figure A.4 – Instructions - traitement de base
Figure A.6 – Instructions - traitement de base
Figure A.7 – Instructions - traitement de base
Figure A.8 – Instructions - traitement de base
Figure A.10 – Instructions - traitement de base
Figure A.11 – Instructions - traitement de base
Figure A.12 – Instructions - traitement de base
Annexe B
Instructions - Traitement modifié
Les instructions dans le traitement modifié sont les mêmes, sauf en ce qui concerne le bouton « je ne sais pas ». Voir les figures suivantes :
Figure B.2 – Instructions - traitement modifié
Figure B.3 – Instructions - traitement modifié
Annexe C
Les paramètres α et β
Table C.1 – Traitement de Base - α < 1 beta alpha ID 1,111849397 -0,123213926 20607 1,059851949 0,215989015 20517 1,074154012 0,224018209 20521 1,11603442 0,259222079 20319 1,051263048 0,442942458 20524 1,029344864 0,449646523 20612 1,044598171 0,518745207 20408 1,04712762 0,583310229 20608 1,026806004 0,911567229 20602 0,99695511 0,949470299 20304
Table C.2 – Traitement de Base - α > 1 beta alpha ID 0,96031231 1,509060728 20411 1,016073643 1,538973203 20519 0,954806866 1,666379905 20303 0,943565768 1,675623362 20312 1,014537636 1,720214604 20412 1,052929148 2,542305168 20610 0,966677305 2,686903302 20325 1,107101255 2,932956383 20606 0,847471472 3,179561702 20513 1,362540922 4,479606173 20322 0,522166868 7,823052672 20407
Table C.3 – Traitement de Base - α = 1 beta alpha ID 1,011711142 0,804038163 20301 1,006262525 1,050640111 20302 1,001063543 0,987112242 20305 1,029669233 1,267189729 20306 0,964910513 1,200313408 20317 1,034578721 0,962642656 20318 0,979198524 1,400606836 20320 1,043045861 1,189007702 20321 1,025386642 0,824026922 20409 0,962030931 1,537647364 20413 0,98487314 1,227261991 20414 1,00911746 0,771162497 20415 1,003106594 1,002911542 20416 1,01823121 0,857018991 20514 0,974130504 0,801020855 20515 1,022370162 0,667725237 20516 0,983534926 1,382606277 20518 1,023061972 0,730085505 20520 0,981063599 1,404662293 20522 1,0005631 1,080415096 20523 1,187726238 1,509252544 20601 1,02567608 0,710643779 20603 1,082349751 0,155054231 20604 0,995682137 1,202734447 20605 1,022886424 0,794357564 20609 1,038805091 1,29209491 20611
Table C.4 – Traitement modifié- α < 1 beta alpha ID 1,01314201 4,97E-06 30721 1,091825835 0,063509533 30702 1,174388871 0,160242064 30501 1,078962227 0,180534979 30624 1,001155153 0,234274697 30722 1,073508287 0,30982959 30720 1,068022285 0,36864981 30703 1,092112183 0,378897385 30502 1,02130523 0,663006777 30719 42
Table C.5 – Traitement modifié- α > 1 beta alpha ID 0,999028086 1,624838838 30623 1,069669959 1,731825537 30614 1,070652334 1,808355727 30708 0,97166694 1,99940177 30622 1,037199523 2,571825842 30709 1,064865943 2,804690077 30724 0,98469934 2,915088159 30507 0,897579259 3,150321793 30512 1,268417617 8,209261809 30714 554,9538805 62,26309096 30706
Table C.6 – Traitement modifié - α = 1 beta alpha ID 1,009004087 0,859715308 30503 0,933856882 1,679640386 30504 1,043247893 1,505849383 30505 0,994549432 1,154619367 30506 0,928177147 1,457131478 30508 0,966016115 1,545225156 30509 1,092402392 1,090291794 30510 1,07620562 1,168151752 30511 1,007327513 0,87871814 30613 1,004660683 0,98445432 30615 0,939685867 1,886745923 30616 0,954248886 1,309812472 30617 0,959967358 1,229396 30618 1,021250232 1,507285324 30619 1,081331894 1,742649824 30620 1,408693195 8,67770239 30621 6,344763407 41,86817049 30705 0,980335807 1,229240209 30707 0,917240751 1,970635971 30712 0,955516474 1,381713087 30713 0,979797386 1,050860253 30715 0,971287267 1,709466219 30718 0,973680145 1,271647098 30723
Table C.7 – Traitement de Base - 6 premières périodes de prédiction - α < 1 beta alpha ID 1,121189407 -0,213105342 20607 1,088412932 0,091444404 20409 1,088652337 0,098516414 20521 1,087527862 0,099618098 20517 1,047761018 0,34708025 20612 1,139406203 0,391751153 20319 1,028161776 0,649077921 20408 1,000104555 0,950047875 20304
Table C.8 – Traitement de Base - 6 premières périodes de prédiction - α > 1 beta alpha ID 0,94345118 1,679090483 20312 1,038888857 2,033272841 20306 0,995890344 2,092476405 20603 0,921409665 2,492263052 20303 1,048074266 2,596864159 20610 0,897695805 2,753626773 20606 0,990390182 2,941203709 20325 0,848085343 3,157481333 20513 1,61127024 5,468081157 20322 0,522127582 7,824022717 20407 44
Table C.9 – Traitement de Base - 6 premières périodes de prédiction - α = 1 beta alpha ID 1,003802655 0,814221909 20301 1,004102021 1,045319489 20302 1,001903614 0,994295652 20305 0,892125661 2,0603639 20317 1,011982952 1,393153934 20318 0,978845188 1,408290744 20320 1,019173462 1,352757364 20321 0,99238958 1,108288217 20411 0,957738032 1,79533434 20412 0,963840815 1,571755609 20413 0,991027088 1,043451141 20414 1,007814288 0,706592339 20415 1,039297292 0,719235347 20416 1,005813362 1,00626324 20514 0,974718047 0,849237891 20515 1,013153135 0,836244459 20516 0,96945678 1,366698538 20518 0,977033839 1,286686713 20519 1,019384191 0,882026419 20520 0,945534861 1,707614139 20522 1,006449512 0,934256227 20523 1,046098738 0,47811968 20524 1,191535744 1,630316044 20601 1,022266016 0,924815273 20602 1,04093425 0,561832313 20604 0,981873414 1,388670008 20605 1,028457593 0,857786972 20608 0,988763521 1,395910724 20609 0,992030566 1,208216101 20611
Table C.10 – Traitement modifié - 6 premières périodes de prédiction - α < 1 beta alpha ID 1,094089197 0,04040272 30624 1,023147799 0,057673877 30721 1,088334575 0,093857422 30702 1,077640422 0,169164354 30501 1,004068748 0,180514276 30722
Table C.11 – Traitement modifié - 6 premières périodes de prédiction - α > 1 beta alpha ID 1,069590161 1,731896754 30614 0,993039436 2,671917895 30709 0,902226964 3,028647533 30512 1,174338662 3,20451118 30724 1,268666938 8,208274118 30714 1018,538944 69,17429761 30706
Table C.12 – Traitement modifié - 6 premières périodes de prédiction - α = 1 beta alpha ID 1,031278127 0,520972566 30502 1,023040331 0,694904774 30503 0,924342219 1,986436065 30504 0,937807362 1,871217037 30505 0,998467531 1,051257194 30506 1,029792098 4,811066116 30507 0,93422426 1,76579441 30508 0,99102851 1,112648103 30509 1,075138163 1,070669331 30510 1,060259578 1,106076753 30511 1,014046202 0,734102491 30613 1,004623878 0,984517343 30615 0,939690316 1,886699635 30616 1,010948307 0,77467563 30617 0,906752167 1,389864853 30618 1,026193417 1,416473205 30619 0,986472313 2,593153487 30620 1,408721177 8,67763051 30621 0,917741608 2,174223533 30622 1,003207337 1,197223834 30623 0,991654029 1,010351008 30703 5,294323563 34,37032943 30705 0,976930607 1,116187805 30707 1,017548744 1,521241529 30708 0,949449548 1,542112794 30712 0,939055561 1,530406071 30713 0,966244426 1,334983659 30715 0,970976019 1,697135964 30718 1,027474445 0,616042388 30719 1,01545172 0,964788822 30720 1,005646184 0,986838891 30723 46
Bibliographie
Bellemare, C., Kröger, S., and van Soest, A. (2008). Measuring Inequity Aversion in a Hete-rogeneous Population Using Experimental Decisions and Subjective Probabilities.
Econo-metrica, 76(4) :815–839.
Camerer, C. and Weber, M. (1992). Recent Developments in Modeling Preferences: Uncer-tainty and Ambiguity. Journal of Risk and Uncertainty, 5(4) :325–70.
Dominitz, J. and Manski, C. F. (1994). Eliciting Student Expectations of the Returns to Schooling. NBER Working Papers 4936, National Bureau of Economic Research, Inc. Ellsberg, D. (1961).Risk, Ambiguity and the Savage Axioms. Levine’s Working Paper Archive
7605, David K. Levine.
Fischbacher, U. (2007). z-Tree: Zurich toolbox for ready-made economic experiments.
Expe-rimental Economics, 10(2) :171–178.
Fischhoff, B. and Bruine De Bruin, W. (1999). Fifty/Fifty=50%? Journal of Behavioral Decision Making, 12(2) :149–163.
Gilboa, I., Postlewaite, A. W., and Schmeidler, D. (2008). Probability and Uncertainty in Economic Modeling. Journal of Economic Perspectives, 22(3) :173–88.
Halevy, Y. (2007). Ellsberg Revisited: An Experimental Study. Econometrica, 75(2) :503–536. Kleinjans, K. J. and van Soest, A. (2010). Nonresponse and Focal Point Answers to Subjective Probability Questions. IZA Discussion Papers 5272, Institute for the Study of Labor (IZA). Manski, C. F. (2004). Measuring Expectations. Econometrica, 72(5) :1329–1376.
Prelec, D. (1998). The Probability Weighting Function. Econometrica, 66(3) :497–528. Preston, M. G. and Baratta, P. (1948). An Experimental Study of the Auction-Value of an
Uncertain Outcome. The American Journal of Psychology, 61(2) :pp. 183–193.
Savage, L. (1954). The Foundations of Statistics. Dover Books on Mathematics Series. DO-VER PUBN Incorporated.
Tversky, A. and Kahneman, D. (1992). Advances in Prospect Theory: Cumulative Represen-tation of Uncertainty. Journal of Risk and Uncertainty, 5(4) :297–323.
Von Neumann, J. and Morgenstern, O. (1944). Theory of Games and Economic Behavior. Science Editions. Princeton University Press.