Turbo codes with rate-m/(M+1) constituent convolutional codes
Texte intégral
Figure
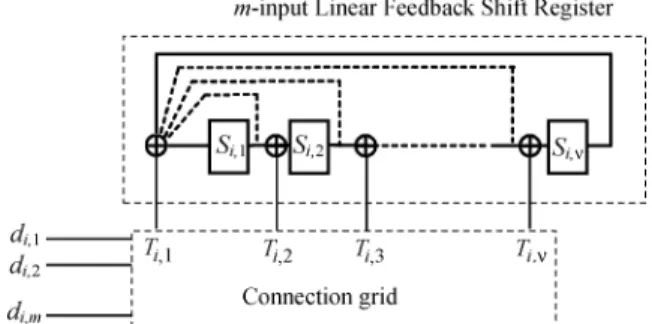
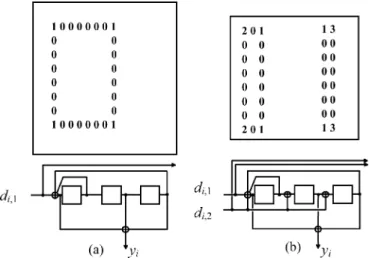
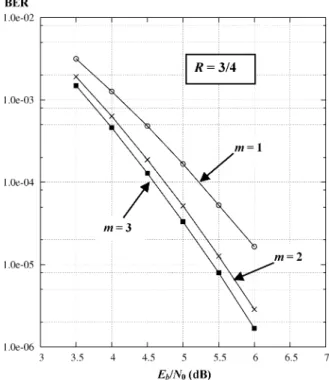

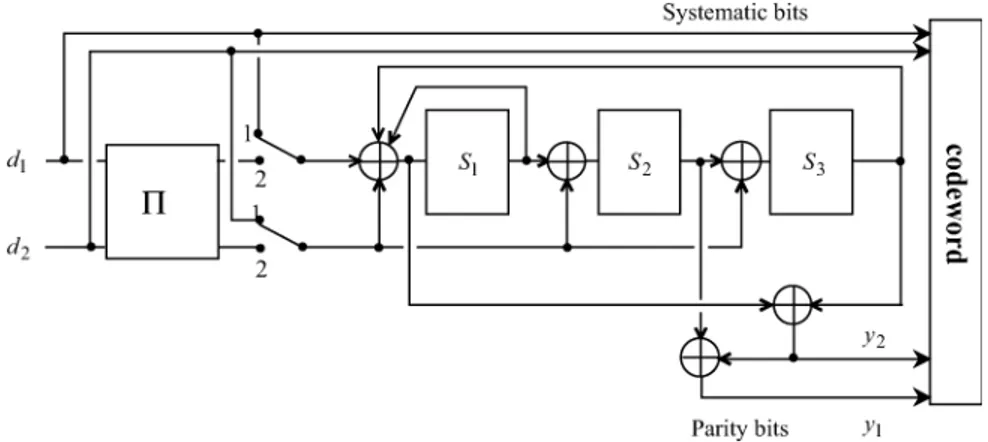
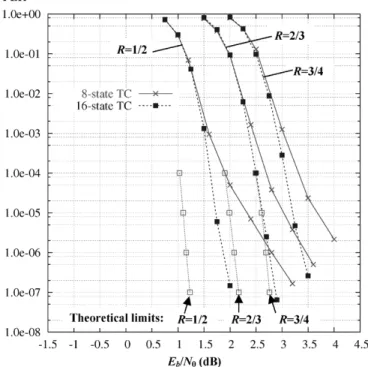
Documents relatifs
Capacity-Approaching Non-Binary Turbo Codes: A Hybrid Design Based on EXIT Charts and Union
1) Stochastic computation: In a stochastic computing pro- cess, the probabilities are converted into Bernoulli sequences using random number generators and comparators [5]. The
Roth’s book [Rot06], where many algebraic codes are presented through the prism of alternant codes, con- siders the list-decoding of these codes and shows how to reach the q-ary
Roth in his book [8] considers the list-decoding of alternant codes, and shows how to reach the q-ary Johnson radius τ q (δ), where δ is the minimum distance of the
For this particular case of quadratic residue codes, several authors have worked out, by hand, formulas for the coefficients of the locator polynomial in terms of the syndroms,
In the present paper, we prove that the system of the Newton’s identities can be used for offline Gr¨obner bases computation, (called One Step Decoding in de Boer and
Unité de recherche INRIA Rhône-Alpes : 655, avenue de l’Europe - 38334 Montbonnot Saint-Ismier (France) Unité de recherche INRIA Rocquencourt : Domaine de Voluceau - Rocquencourt -
Comparison between the standard and the proposed method using a rate-0.5 optimized LDPC code, a rate-5/6 convolutional code and the the soft-input Viterbi algorithm to perform
