SURVEILLANCE VIDEO
par
Andre Caron
Memoire presente au Departement d'informatique
en vue de I'obtention du grade de maitre es sciences (M.Sc.)
FACULTE DES SCIENCES
UNIVERSITE DE SHERBROOKE
Library and Archives Canada Published Heritage Branch Biblioth6que et Archives Canada Direction du Patrimoine de l'6dition 395 Wellington Street Ottawa ON K1A 0N4 Canada 395, rue Wellington Ottawa ON K1A 0N4 Canada
Your file Votre r6f6rence ISBN: 978-0-494-83661-3 Our file Notre rdf6rence ISBN: 978-0-494-83661-3
NOTICE:
The author has granted a non
exclusive license allowing Library and Archives Canada to reproduce, publish, archive, preserve, conserve, communicate to the public by
telecommunication or on the Internet, loan, distrbute and sell theses
worldwide, for commercial or non commercial purposes, in microform, paper, electronic and/or any other formats.
AVIS:
L'auteur a accorde une licence non exclusive permettant d la Biblioth&que et Archives Canada de reproduire, publier, archiver, sauvegarder, conserver, transmettre au public par telecommunication ou par I'lnternet, preter, distribuer et vendre des thises partout dans le monde, k des fins commerciales ou autres, sur support microforme, papier, 6lectronique et/ou autres formats.
The author retains copyright ownership and moral rights in this thesis. Neither the thesis nor substantial extracts from it may be printed or otherwise reproduced without the author's permission.
L'auteur conserve la propri6t6 du droit d'auteur et des droits moraux qui protege cette thdse. Ni la thdse ni des extraits substantiels de celle-ci ne doivent §tre imprimis ou autrement
reproduits sans son autorisation.
In compliance with the Canadian Privacy Act some supporting forms may have been removed from this thesis.
While these forms may be included in the document page count, their removal does not represent any loss of content from the thesis.
Conform6ment d la loi canadienne sur la protection de la vie priv6e, quelques formulaires secondares ont 6t§ enlev&s de cette thdse.
Bien que ces formulaires aient inclus dans la pagination, il n'y aura aucun contenu manquant.
le jury a accepte le memoire de Monsieur Andre Caron
dans sa version finale.
Membres du jury
Professeur Pierre-Marc Jodoin Directeur de recherche Departement d'informatique
Professeur Hugo Larochelle Evaluateur interne au programme
Departement d'informatique
Professeur Maxime Descoteaux President rapporteur Departement d'informatique
Sommaire
Les systemes de surveillance video sont omnipresents dans les lieux publics acha-landes et leur presence dans les lieux prives s'accroit sans cesse. Si un aeroport ou une gare de trains peut se permettre d'employer une equipe de surveillance pour sur-veiller des flux video en temps reel, il est improbable qu'un particulier effectue une telle depense pour un systeme de surveillance a domicile. Qui plus est, l'utilisation de videos de surveillance pour l'analyse criminalistique requiert sou vent une analyse
a posteriori des evenements observes. L'historique d'enregistrement correspond
sou-vent a plusieurs jours, voire des semaines de video. Si le moment ou s'est produit un evenement d'interet est inconnu, un outil de recherche video est essentiel. Un tel outil a pour objectif d'identifier les segments de video dont le contenu correspond a une description approximative de l'evenement (ou de l'objet) recherche. Ce memoire presente une structure de donnees pour l'indexation du contenu de longues videos de surveillance, ainsi qu'un algorithme de recherche par le contenu base sur cette structure.
A
partir de la description d'un objet basee sur des attributs tels sa taille, sa couleur et la direction de son mouvement, le systeme identifie en temps reel les segments de video contenant des objets correspondant a cette description. Nous avons demontre empiriquement que notre systeme fonctionne dans plusieurs cas d'utilisa tion tels le comptage d'objets en mouvement, la reconnaissance de trajectoires, la detection d'objets abandonnes et la detection de vehicules stationnes. Ce memoire comporte egalement une section sur l'attestation de qualite d'images. La methode presentee permet de determiner qualitativement le type et la quantite de distortion appliquee a l'image par un systeme d'acquisition. Cette technique peut etre utilisee pour estimer les parametres du systeme d'acquisition afin de corriger les images, ou encore pour aider au developpement de nouveaux systemes d'acquisition.Mots-cles: video; surveillance; recherche; indexation; qualite; image; distorsion;
flou; bruit.
Remerciements
Je remercie Pierre-Marc Jodoin pour sa direction et ses conseils. Son enthousiasme face a mes projet, ainsi que le financement qu'il m'a fourni ont rendu cette maitrise possible.
J'aimerais aussi remercier Venkatesh Saligrama de Boston University de m'avoir invite a Boston pour une duree de 4 mois. Travailler de pres avec lui et ses etudiants a ete une experience stimulante.
Je souligne aussi l'aide considerable de Christophe Charrier de l'Universite de Caen dans mes recherches sur l'attestation de la qualite d'images.
Enfin, j'aimerais remercier mes parents et ma conjointe. Leur support moral durant ces deux annees d'etude a ete crucial dans l'atteinte de mes objectifs.
Table des matieres
Sommaire iii
Remerciements v
Table des matieres vii
Liste des figures ix
Liste des tableaux xi
Liste des programmes xiii
Introduction 1 1 Surveillance video 7 1.1 Introduction 11 1.2 Previous work 13 1.3 Feature extraction 15 1.3.1 Structure 15 1.3.2 Resolution 16 1.3.3 Features 18 1.4 Indexing 19 1.4.1 Hashing 20 1.4.2 Data structure 22
1.4.3 Building the lookup table 24
1.5 Search engine 25
1.5.1 Queries 26 1.5.2 Lookup of partial matches 27
1.5.3 Full matches 27
1.5.4 Ranking 32
1.6 Experimental Results 33
1.6.1 Datasets 33
1.6.2 Comparison with HDP-based video search 38 1.6.3 Dynamic Programming Evaluation 40 1.6.4 Exploratory search 43
1.7 Conclusion 43
2 Attestation de qualite d'images 51
2.1 Introduction 55
2.2 Previous Work 56
2.3 Our Contributions 61
2.4 The MS-SSIM factors 61
2.5 Noise and Blur Distortions 63 2.6 Distortion Estimation as an Optimization Problem 67 2.6.1 Brute Force Search (BF) 68 2.6.2 Simplex Search (SI) 69
2.6.3 NewUOA (NU) 69
2.7 Fast 2D to 3D Mapping 70 2.7.1 Patch-Based Optimization Procedures 72 2.7.2 Newton-Raphson Search (NR) 72
2.7.3 Refined Patches 73
2.8 Blind Distortion Estimation 74
2.9 Results 76 2.9.1 Experimental apparatus 76 2.9.2 Results 77 2.10 Conclusion 83 Conclusion 97 viii
Liste des figures
1.1 Video model 16
1.2 Feature pyramids 17
1.3 Clustering through LSH 22
1.4 Hash table structure 23
1.5 Experimental search tasks 35 1.6 Precision and recall analysis 41 1.7 Increasing accuracy in lookup 44 2.1 Example projections in MS-SSIM space 64 2.2 Distance in MS-SSIM and parameter spaces 66 2.3 Schematic representation of the optimization procedure 67 2.4 Example of optimization cost function 69 2.5 Manifold structure of projection in MS-SSIM space 71 2.6 Error distribution for different noise types 75 2.7 Comparison with state-of-the-art techniques 78 2.8 Example of estimated point-stread-functions 79 2.9 Global comparison of distortion estimation techniques 80 2.10 Example estimation results 81 2.11 Average error over all data sets 83 2.12 Comparison of the seven proposed methods 84
Liste des tableaux
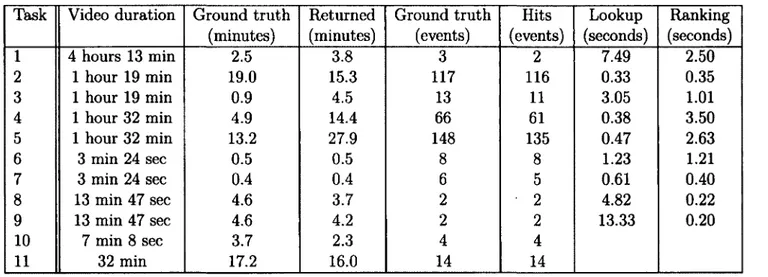
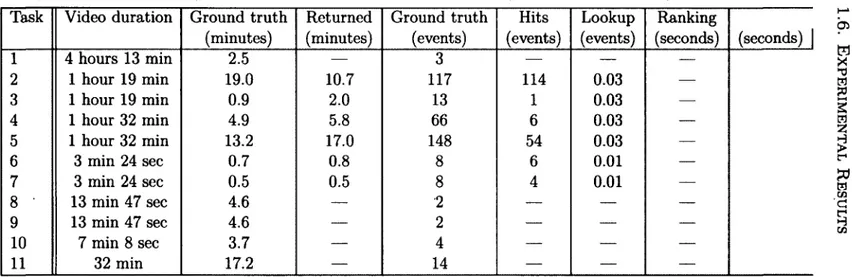
1.1 Experimental search tasks 34 1.2 Results for expermental search tasks 37 1.3 Results for all search tasks using HDP 39 1.4 Results for dynamic programming algorithm 42 2.1 Confusion matrix in blind estimation 76 2.2 Distortion estimation algorithms 86 2.3 Control points used to build parametric patches 87
Liste des programmes
1.1 Updating the LSH-based Index 25 1.2 Greedy search algorithm 28
2.1 Refined Patches 73
2.2 Blind Distortion Estimation 74
Introduction
Les systemes de surveillance video ont conmi un essor enorme depuis la fin des an-nees 1990. Les systemes d'acquisition, d'enregistrement et d'affichage d'alors etaient principalement de type analogique. Leur utilisation etait restreinte a la surveillance de lieux publics critiques tels les gares et les aeroports, ou une equipe de surveillance visionnait les flux video en temps reel. L'objectif etait de detecter les situations proble-matiques et de reagir le plus rapidement possible. Ces systemes etaient generalement constitues d'un reseau de cameras, d'une batterie d'ecrans de visualisation localisee dans un centre de controle, ainsi que des unites de stockage de type Betacam ou VHS. Avec l'avenement de cameras video numeriques bon marche, le nombre de cameras de surveillance s'est multiplie1, rendant impossible pour le personnel de securite de
surveiller simultanement tous les flux video [120, 119, 101]. La camera numerique, dont le flux video se prete a l'analyse par ordinateur, a permis le developpement de logiciels pour aider le personnel de securite dans ses taches. Ces logiciels precedent a une analyse en temps reel du contenu de la scene et prennent la forme d'alarmes automatisees ou bien d'annotations visuelles superposees aux flux videos. Parmi les applications les plus etudiees flgurent la detection d'objets abandonnes [118, 115], le suivi de pietons [103] et la detection d'evenements anormaux [108, 105].
Plus recemment, on a assiste a l'apparition de cameras de surveillance dans les commerces de detail et meme a domicile. Contrairement a certains lieux publics cri tiques, il y a rarement un etre humain pour suivre en temps reel le flux video de ces cameras. Dans ce type d'installations, les utilisateurs s'interessent a la consultation au besoin, souvent pour des fins d'analyse criminalistique. Dans ce cas, on cherche
1. Selon un article de Popular Mechanics paru en 2008, des cameras de securite enregistrent plus de 4 milliards d'heures par semaine aux fitats-Unis seulement [121].
a eviter autant que possible de visionner au complet les flux video. Cela implique que la plupart des videos sont archivees et peu consultees. Lorsqu'on s'interesse a un evenement particulier, on effectue un retour en arriere en visionnant les donnees video enregistrees sur disque. Cependant, il peut etre fastidieux de regarder des di-zaines voire des centaines d'heures d'enregistrement pour trouver une ou quelques sous-sequences d'interet. Ainsi, le besoin de naviguer a travers de longues videos a motive le developpement d'une nouvelle categorie de techniques d'analyse video. Re-cemment, plusieurs articles portant sur des techniques pour naviguer a travers une video [110], pour resumer ou condenser une video [116, 125] et pour comprendre la dynamique d'objets dans la scene [113, 124, 117, 122] ont ete publiees. Ces techniques facilitent grandement la visualisation et la navigation des enregistrements. Par contre, les solutions pour 1'identification automatique de sous-sequences d'interet tardent a faire leur apparition. Suite a une revue de litterature, je n'ai trouve aucune tech nique permettant d'extraire rapidement un sous-ensemble d'enregistrements video en reponse a une requete deerivant approximativement un objet ou une activite. Ce me-moire presente une technique permettant l'indexation et la recherche par le contenu de longues videos de surveillance.
Le present memoire presente deux contributions ayant mene a la publication d'un article de conference, d'un article de revue et a la soumission d'un second article de revue.
La premiere contribution est une methode d'indexation et de recherche par le contenu permettant de retrouver en temps reel des segments de video correspondant a une requete soumise par l'utilisateur. Etant donnee une description approximative d'un objet ou d'une activite, le systeme dresse une liste de segments videos ayant une forte probability de contenir des objets decrits par la requete. Une requete decrit un objet a l'aide de mots-cles caracterisant des attributs tels la taille, la couleur, la direction du mouvement et la persistance. La methode est particulierement utile pour compter des objets, detecter des objets suivant une trajectoire donnee, detecter des objets abandonnes et detecter des vehicules stationnes. L'objectifs de ces travaux est de demontrer que ces taches peuvent etre effectuees a l'aide d'une seule solution de recherche par le contenu [114].
Pour etre efficace, la methode proposee prend en compte certains facteurs propres
INTRODUCTION
aux videos de surveillance dont l'afflux constant de donnees, la duree imprevisible d'evenements et la complexite semantique du contenu observe. D'abord, il est cou-rant pour un systeme de surveillance de faire une acquisition continue et de conserver en tout temps un historique de plusieurs jours de video. La methode developpee prend done en compte cet afflux continuel de donnees. Les besoins de l'utilisateur etant in-connus a priori, le systeme permet egalement une large gamme de requetes utilisateur. Ces requetes servent a decrire un objet ou une activite qui interesse l'utilisateur. Le type de contenu reellement cherche par l'utilisateur est susceptible d'impliquer des relations complexes entre les objets et les evenements. Formuler une requete est done une tache difficile, car la modelisation de l'evenement (objet) recherche par l'utilisa teur peut etre d'une complexite arbitraire.
Ensuite, la recherche doit selectionner des sous-sequences de la video a montrer a l'utilisateur. Contrairement a une video de diffusion telle un film, une video de surveillance ne presente aucune transition de scene brusque. En plus d'avoir un fond statique, la video de surveillance contient des evenements debutant a tout moment, d'une duree variable et chevauchant d'autres evenements. Une video de surveillance ne peut done pas etre divisee en scenes ou en sous-sequences de contenu distinct. La methode doit etablir ses propres divisions en fonction du contenu de la requete.
Pour repondre au renouvellement des donnees, la methode presente une strategie d'indexation avec une complexite algorithmique 0( 1) pour la recherche et la mise a jour. L'indexation est basee sur le locality sensitive hashing [111, 102], une me thode qui approxime la recherche par k plus proches voisins. Afin d'identifier les sous-sequences video correspondant a la requete, la methode utilise une fonction de cout et un algorithme d'optimisation. L'optimiseur divise la video en sous-sequences tout en s'ajustant a la duree variable des evenements observes. La combinaison de la base de donnees et de l'algorithme de recherche permet de repondre en temps reel a des requetes telles "trouver des objets oranges qui ont une taille d'environ 1000 pixels" ou encore "trouver des objets recemment apparus dans la scene, mais immobiles depuis au moins dix secondes et d'une taille d'environ 500 pixels". La rapidite du systeme per met d'appliquer des recherches dites "exploratoires" [123] a la surveillance video. Un systeme de recherche exploratoire permet a l'utilisateur d'alterner en temps reel entre des phases d'exploration et de recherche. Dans une phase de recherche, l'utilisateur
peut poser plusieurs requetes. Bien que notre methode ne permette pas l'utilisation de plusieurs requetes simultanees, elle peut neanmoins etre jumelee a une methode existante de navigation pour implementer un systeme de recherche exploratoire.
Lors de nos experimentations, nous avons remarque que la qualite visuelle des images influe grandement sur la precision de notre systeme de recherche par le contenu. Les systemes de surveillance ont parfois recours a des techniques de rehaussement de la qualite d'images telles le debruitage et la deconvolution [109, 104]. Malheureusement, plusieurs techniques de debruitage et de deconvolution doivent connaitre au prealable les parametres du modele de degradation. On presente done une procedure pour es-timer les parametres du modele de degradation implique dans I'acquisition d'images numeriques. Ces parametres pourront ensuite etres utilises pour rehausser la qualite des images apres I'acquisition. L'objectif de ces travaux est d'aider au developpement de sytemes d'acquisition et de compression video.
La degradation induite par le systeme d'acquisition peut etre modelisee par une equation parametrique ou les parametres sont determines par le systeme physique. Dans une camera numerique, la lentille introduit du flou et le capteur produit un bruit thermique. Lorsque les objets de la scene sont situes approximativement a la meme distance de la camera, la degradation induite par le systeme peut etre modelisee par le processus suivant [112] :
g = D ( f ] a , /? )
= hfi*f + Afa, (1)
ou / denote l'image d'origine et g l'image degradee. Les operateurs hp et Na repre
sented un filtre passe-bas determine par un parametre /?, ainsi qu'un bruit blanc additif de moyenne nulle et de variance a. Les parametres a et /3 sont definis par la structure du materiel et sont inconnus a priori. L'objectif est de retrouver les para metres a et /? du systeme d'acquisition. En d'autres mots, le defi consiste a trouver l'inverse du processus D(-). Or, l'inverse de D(.) est parfois difficile a obtenir ana-lytiquement, ou encore n'existe tout simplement pas. La methode presentee consiste a estimer les parametres du systeme d'acquisition a et /? a partir de l'equation (1), d'une image de reference / et de sa version degradee g. Contrairement aux methodes
INTRODUCTION
publiees a ce jour, le methode proposee ne depend pas d'un modele de degradation particulier et estime simultanement a et /?. L'efficacite de la methode est demontree pour deux types de flou (filtre gaussien et filtre moyenneur) et deux types de bruit additif (bruit gaussien et bruit poivre et sel).
Ce memoire est organise de la fagon suivante. Le premier chapitre presente la methode de recherche par le contenu adapte aux besoins de la video surveillance. Le deuxieme chapitre presente la methode d'estimation quantitative de distortion dans des images en presence de processus de distortion complexes.
Chapitre 1
Recherche exploratoire de videos
de surveillance
Resume
Ce chapitre presente une methode de recherche par le contenu adaptee aux be-soins de la surveillance video. Etant donnee une requete soumise par l'utilisateur, le systeme dresse une liste de segments videos qui ont une forte probability de contenir des objets decrits par la requete. Les requetes prennent la forme d'une description approximative d'un objet ou d'une activite. Cette methode comprend une structure de donnees pour l'indexation du contenu, ainsi qu'une procedure de recherche. Le processus d'indexation est base sur l'extraction de caracteristiques couramment uti-lisees : soustraction de fond, histogrammes de couleur et histogrammes de vecteurs de mouvement. La structure de donnees proposee construit un index inverse, soit une correspondance entre le contenu observe et l'emplacement de ce contenu dans la video. L'utlisation du locality-sensitive hashing (LSH), une technique pour l'approxi-mation de la recherche des k plus proches voisins, accelere la recherche par contenu dans la video. La procedure de recherche utilise un algorithme d'optimisation pour separer la video en sous-sequences tout en prenant compte de la variability des evene-ments observes. La procedure de recherche procede en trois phases. Dans un premier temps, la requete entree par l'utilisateur est convertie en caracteristiques. Ensuite, les
sous-sequences de la video dont le contenu correspond a la requete entree par l'uti-lisateur sont localisees. Les sous-sequences sont localisees a l'aide de l'index inverse construit au prealable. Finalement, les divisions optimales dans la video sont trouvees. La methode est a la fois simple a mettre en place, rapide d'execution et assez flexible pour etre utilisee dans plusieurs taches reliees a l'analyse de videos. Finalement, l'ar-ticle presente comment jumeler la methode proposee a une methode d'exploration du contenu de la video pour developper un systeme de recherche exploratoire.
Commentaires
Ce developpement est issu d'un partenariat avec Venkatesh Saligrama, de Boston
University. Ce fut Venkatesh qui proposa l'utilisation de la technique locality-sensitive hashing pour accelerer la recherche dans l'index. J'ai a propose la structure d'index
inverse pour l'indexation de la video et implemente le systeme au complet. Greg Cas-tanon, etudiant de doctorat a Boston University a propose et implemente l'optimiseur base sur l'algorithme Smith-Waterman afin de reduire les faux positifs dans les resul-tats. Le co-auteur Pierre-Marc Jodoin a dirige l'ensemble du projet. La redaction fut un effort partage, avec une contribution majoritaire de ma part.
L'article, dans sa forme presente ici, est sur le point d'une soumission a une revue internationale. De nouveaux developpements prometteurs de la part de nos collegues americains ont retarde legerement la soumission de 1'article. Ces nouveaux develop pements portent sur un algorithme d'optimisation et d'ordonancement des resultats. Une fois les hypotheses validees experimentalement, les resultats seront ajoutes a l'article et la soumission suivra.
Exploratory Search of Long Surveillance Videos
Andre Caron
Departement d'lnformatique Universite de Sherbrooke Sherbrooke, Quebec, Canada J1K 2R1 [email protected]
Greg Castafion
Department of Electrical and Computer Engineering Boston University Boston, MA 02215, USA [email protected] Pierre-Marc Jodoin Departement d'lnformatique Universite de Sherbrooke Sherbrooke, Quebec, Canada J1K 2R1 pierre-marc.j odoinSusherbrooke.ca
Venkatesh Saligrama
Department of Electrical and Computer Engineering Boston University
Boston, MA 02215, USA srvObu.edu
Keywords: video surveillance; content-based search and retrieval; locality-sensitive
hashing; indexing; greedy algorithm
Abstract
This paper presents a fast and flexible content-based retrieval method for surveil lance video. The method can be used as a basis for implementation of exploratory search systems. In contrast to document retrieval systems, search for activity patterns in a video poses additional challenges. Due to uncertainty in activity duration and
high variability in object shapes and scene content, designing a system that allows the user to enter simple queries and retrieve video segments of interest is very challeng ing. The proposed method relies on four fundamental elements: (1) a light-weight pre-processing engine for real-time extraction of local video features, (2) an inverted indexing scheme to accelerate retrieval, (3) a query interface which converts keywords into feature-based queries and (4) a dynamic matching algorithm implementing an efficient search engine for automatic selection of variable-length matching video sub sequences. The matching algorithm is based on a value optimization framework which identifies video segments that match the query while dealing with uncertainty in length of matching segments. Pre-processing is performed as video streams in and retrieval speed scales as a function of the number of matches rather than the amount of video. We present a theorem that guarantees a low probability of false alarms, and then demonstrate the effectiveness of the system for counting, motion pattern recognition and abandoned object applications using seven challenging video datasets.
1.1. INTRODUCTION
1.1 Introduction
Surveillance video camera networks are increasingly ubiquitous, providing per vasive information gathering capabilities1. In many applications, surveillance video
archives are used for forensic purposes to gather evidences after the fact. This calls for based retrieval of video data matching user defined queries. Typical content-based retrieval systems assume that the user is able to specify their information needs at a level to make the system effective. Being fundamentally situation-driven, the na ture of queries depends widely on the field of view of the camera, the scene itself and the type of observed events. Moreover, independent events frequently overlap in the same video segment. Formulating an accurate query in presence of these complex video dynamics is fundamentally difficult. Thus, unlike typical document retrieval applications, video surveillance systems call for a search paradigm that goes beyond the simple query/response setting. The retrieval engine should allow the user to iteratively refine its search through multiple interactions.
Exploratory search [37] is a specialization of information seeking developped to address such situations. It describes the activity of attempting to obtain information through a combination of querying and collection browsing. Development of ex ploratory search systems requires addressing two critical aspects: video browsing and content-based retrieval. While the former is well covered in the litterature, the latter is still mostly unresolved. This paper presents such a method for fast content-based retrieval adapted to caracteristics of surveillance videos. The greatest challenges with surveillance video retrieval are the following:
- Data lifetime: since video is constantly streamed, there is a perpetual renewal
of video data. As a consequence, this calls for a model that can be updated incrementally as video data is made available.
- Unpredictable queries-, the nature of queries depends on the field of view of
the camera, the scene itself and the type of events being observed. The system should support queries of different nature, such as identifying abandoned objects and finding instances of cars performing a U-turn.
1. According to a 2008 article in Popular Mechanics, over 4 billion hours of footage is produced per week in the US
- Unpredictable event duration: events in video are ill-structured. Events start
at any moment, vary in length and overlap with other events. The system is nonetheless expected to return complete events whatever their duration may be and regardless of whether other events occur simultaneously.
- Clutter and occlusions: urban scenes are subject to high number of occlusions.
Tracking and tagging objects in video is still a challenge, especially when real time performance is required.
- Retrieval speed: surveillance videos are very lengthy. Search systems must be
fast if multiple user interactions are expected.
The proposed system archives, in a light-weight lookup table, low-level video fea tures which the user can retrieve with simple, yet generic, queries. This lookup table is designed for incremental update. As video data is captured, local low-level features are extracted in real-time and inserted into the lookup table. The computational burden of matching these features to queries is left to the search engine. This im plements a two-step search procedure. First, a lookup is performed in the index to retrieve video segements that partially match the query. Then, the dynamic match ing algorithm groups these partial matches to find optimal relevance to the query. Postponing high-level analysis has four benefits. First, the index update operation does not perform context analysis, so it is very fast. Second, it allows the dynamic matching algorithm to perform temporal segmentation of the video with respect to events relevant to the query. Third, optimizing over local matches has the effect of ignoring any concurrent video activity if it has no relevance to the query. Last, the O(l) lookup operation filters out all video content not relevant to the query. Thus, total retrieval time is a function of the amount of video relevant to the query, not the total amount of video.
The paper includes theoretical proof and empirical demonstration that the sys tem provides high-precision result sets with a low number of false positives. Experi ments show effectiveness of the system for event counting, motion pattern recognition, abandoned object detection and parked vehicle detection. Our results demonstrate excellent statistical performance, high query flexibility, fast retrieval and low storage requirements.
1.2. PREVIOUS WORK
Contributions: The proposed system includes many contibutions to content-based
retrieval applied to video surveillance.
1. The inverted indexing scheme of local video features exhibits constant-time update and constant-time identification of video segments with a high-likelihood or relevance to the query.
2. The dynamic matching algorithm allows matching variable-length video seg ments and is robust to concurrent video activity.
3. Theorem 1.5.1 guarantees results with a low probability of false positives. 4. A novel retrieval system that addresses challenges specific to video surveillance
applications and simultaneously addresses multiple problems of high-interest in video surveillance applications.
The reminder of this paper is organized as follows. Section 1.2 presents a survey of existing literature on video surveillance techniques. Section 1.3 describes how video data is prepared for retrieval. Section 1.5 defines low-level search operators and the matching algorithm. Section 1.6.4 shows how our search algorithm can be used to implement exploratory search. Finally, section 2.9 demonstrates validity of the algorithm under multiple test scenarios.
1.2 Previous work
The goal of image-based and video-based retrieval is to recover an image or a video segment that best fits the queried image or video clip.
Many papers that describe video search do so for specific isolated instances rather than for arbitrary user defined queries. Stringa et al. [32] describe a system to recover abandoned objects, Lee et al. [19] describe a user interface to retrieve basic events such as the presence of a person, and Meesen et al. [21] presents an object-based dissimilarity measure to recover objects based on low-level features.
There is extensive literature devoted to summarization and search; however they focus almost exclusively on broadcast videos such as music clips, sports games, movies, etc. These methods typically divide the video into "shots" [31, 27, 29, 12] by locating and annotating key frames corresponding to scene transitions. The search procedure
exploits the key frames content and matches either low-level descriptors [29] or higher-level semantic meta-tags to a given query [42], These methods are motivated by the need to identify transitions within a video to enable quick indexing and summariza tion. Surveillance videos have different needs. No such transitions within the video may exist; and even if it does exist, these key frames do not provide a means for quickly identifying video segments for arbitrary user defined queries. Some research is focused on summarization of surveillance videos [43, 23]. These methods attempt to condense video by applying a temporal distortion which reduces the gap between events in the video. Ultimately, events occuring at different times may overlap in the video digest.
Scene-understanding is closely related to search but differs in important ways. Scene understanding deals with classifying observed activities in terms of activities learnt from a training video. For instance, activities observed in public areas often follow some basic rules (such as traffic lights, highways, building entries, etc), which are learnt during the training phase. Common modeling techniques include HMMs [24, 34, 18], Bayesian networks [38], context free grammars [35], and other graphical models [20, 28, 36]. The classification stage is either used to recognize pre-defined patterns of activity [41, 28, 26, 40, 16] (useful for counting [33]) or detect anomalies by flagging everything that deviates from what has been previously learned [25, 22, 15, 5, 24]. We point out that techniques that require global behavior understanding often rely on tracking [24, 34, 20] while those devoted to isolated action recognition rely more on low-level features [11, 26, 41].
Nevertheless, techniques that attempt scene understanding do not meaningfully account for the issues posed in a search system. Search systems for surveillance video must index the dynamic content of archived video in a sufficiently flexible manner so as to be compatible with arbitrary user-defined queries. As we pointed out earlier, user defined queries can vary significantly, ranging from rarely seen to typically seen patterns. By focusing exclusively on typical patterns, scene understanding suppress rarely seen activities which could be extremely useful in video forensics. Furthermore, pre-processing archived video to learn typical patterns carries a significant compu tational burden which must be repeated if the learned models cannot be updated incrementally. To the best of our knowledge, Wang et al. [36] is the only paper
1.3. FEATURE EXTRACTION
ing with scene understanding that also mentions search. Nevertheless, search here is restricted to searching among the inferred activity patterns/clusters.
Use of surveillance videos for forensic purposes carries an inherently investigative approach which requires a combination of search and browsing. Work on exploratory search [37] has motivated the need for a combination of browsing and search in infor mation exploration. To the best of our knowledge Shi-Fu et al. [9] is the only paper that applies a combination of search and browsing to video. However, the proposed system targets broadcast video and does not account for the needs of video surveil lance. It requires segmentation of the video into shots as discussed earlier and the data structure behind the search algorithm requires storing features explicitly. Ex plicitly storing features requires a heavy indexing structure and comparing features with a distance function implies a retrieval algorithm complexity of at least O(n). Both of these side-effects are prohibitive for long surveillance videos.
In contrast to the aforementioned methods, we develop a framework for content-based retrieval specifically tailored to the problems of video surveillance. The pro posed search for arbitrary user defined queries carries low computational burden on pre-processing archived video. We exploit the inherent temporal dependence within a query to identify coherent matches within the archived video.
1.3 Feature extraction
1.3.1 Structure
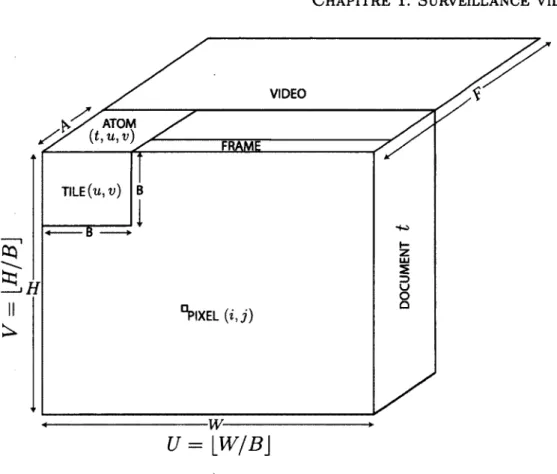
A video is a spatio-temporal volume of size H x W x F where H x W is the image size in pixels and F the total number of frames in the video. The video is divided along the temporal axis into contiguous documents each containing A frames. As shown in figure 1.1, each frame is divided into tiles of size B x B. An atom is formed by grouping the same tile over A frames. As the video streams in, features are extracted from each frame. Whenever a document is created, each atom n is assigned a set of motion-based features x^ describing the dynamic content over that region. The motion-based features used by our method are described in section 1.3.3.
VIDEO ATOM FRAME CQ 5" LU
•w-u
= [ W / B \
Figure 1.1: Given an W x H x F video, d o c u m e n t s are non-overlapping video clips e a c h c o n t a i n i n g A f r a m e s . E a c h o f t h e f r a m e s a r e d i v i d e d i n t o t i l e s o f s i z e B x B . Tiles form an atom when aggregated together over A frames.
1.3.2 Resolution
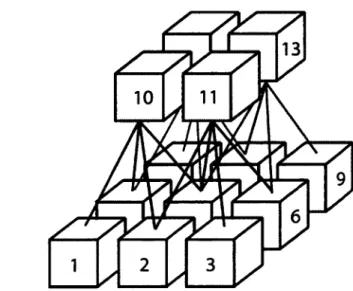
Choosing a suitable atom size ( A and B ) is an important issue. Small-sized atoms are sensitive to noise while large-sized atoms aggregate features extracted from unrelated objects and smooth out object details, which are important for precise retrieval. A solution to this problem is to build a pyramidal structure such as the o n e i n f i g u r e 1 . 2 . T h i s s t r u c t u r e i s m a d e o f A:-level t r e e s e a c h c o n t a i n i n g M = £?= i I2 nodes. In that way, a document containing U x V atoms will be assigned
(U — k +1) x (V — k +1) partially overlapping trees to be indexed. The combination
of features at multiple resolutions generate a signature of content which captures local scene structure. This implies that a query can be designed to match precise patterns
1.3. FEATURE EXTRACTION
and object silhouettes.
Figure 1.2: Schematic representation of a two-level pyramidal structure containing 9 atoms grouped into 4 two-level (k = 2) trees. A three-level ( k = 3) tree could be created by aggregating the nodes 10,11,12 and 13.
Each node of a tree is assigned a feature vector obtained by aggregating the feature vector of its 4 children. Let n be a non-leaf node and o, 6, c, d its 4 children. The aggregation process can be formalized as
>
where tpf is an aggregation operator for feature /. Such an operator is used to summarize the content of four neighboring nodes. The aggregation operator used for each feature is detailed in section 1.3.3.
Given that several features are extracted for each atom, aggregating a group of
k x k atoms results in a set of feature trees {tree/}, one for each feature /. Given
that a fc-level tree contains M nodes, each tree/ contains a list of M feature instances, namely tree/ = {^/^} where i stands for the ith node in the tree.
1.3.3 Features
As reported in the literature [21, 32, 39], atom features can be of any kind such as color, object shape, object motion, tracks, etc. The indexing scheme can accom modate high-level features as long as those features can be divided and assigned to each atom. However, we only use local descriptors in this paper. The reason is that local processing is computationally tractable and better suited to the constant data renewal constraint and to real-time feature extraction. Furthermore, high-level features based on tracking and pattern recognition are sensitive to occlusion and cluttered environments. Feature extraction proceeds at the pixel-level. The extrac tion procedure computes a single value for each pixel. Then, the pixel-level features are condensed into a single descriptor for each atom. Finally, atom descriptors are grouped into feature trees. Our method uses the following five features:
Activity xa: Activity is detected using a basic background subtraction method [6].
The initial background is estimated using a median of the first 500 frames. Then, t h e b a c k g r o u n d i s u p d a t e d u s i n g t h e r u n n i n g a v e r a g e m e t h o d . A t t h e l e a f l e v e l , xa
contains the proportion of active pixels within the atom. Aggregation for non-leaf nodes in feature trees, Vo, is the mean of the four children.
Object Size xs: Objects are detected using connected components analysis [14] of
the binary activity mask obtained from background subtraction. Object size is the total number of active pixels covered by the connected component. The aggregation operator ip3 for non-leaf nodes in feature trees is the median of non-zero children.
Whenever all four children have a zero object size, the aggregation operator returns zero.
Color xc: Color is obtained by computing the quantized histogram of every active
pixel in the atom. RGB pixels are then converted to the HSL color space. Hue, satu ration and luminance are quantized into 8, 4 and 4 bins respectively. The aggregation operator ipa for non-leaf nodes in feature trees is the bin-wise sum of histograms. In
order to keep relative track of proportions during aggregation, histograms are not normalized at this stage.
1.4. INDEXING
Persistence xp: Persistence is a detector for newly static objects. It is computed
by accumulating the binary activity mask obtained from background subtraction over time. Objects that become idle for a long period of time thus get a large persistence measure. The aggregation operator tj)p for non-leaf nodes in feature trees is the
maximum of the four children.
Motion xm: Motion vectors are extracted using Horn and Schunck's optical flow
method [7], Motion is quantized into 8 directions and an extra "idle" bin is used for flow vectors with low magnitude. xm thus contains a 9-bin motion histogram.
The aggregation operator ipm for non-leaf nodes in feature trees is a bin-wise sum
of histograms. In order to keep relative track of proportions during aggregation, histograms are not normalized at this stage.
As mentioned previously, these motion features are extracted while the video streams in. Whenever a document is created, its atoms are assigned 5 descriptors, namely {xa,xs,xc,xp,xm}. These descriptors are then assembled to form the 5 feature
trees {treea} , {tree,,} , {treec} , {treep} , {treem}. These feature trees are the basis for
the indexing scheme presented in section 1.4. After feature trees are indexed, all extracted feature content is discarded.
1.4 Indexing
When a document is created, features are grouped into atom descriptors and aggregated into (U — k) x (V — k) /c-level trees. As mentioned earlier, a tree is made of 5 feature trees, namely {treea} , {tree.,} , {treec} , {treep} , {treeTO}. This section
describes how these feature trees are indexed for efficient retrieval.
Our method uses an inverted index for content retrieval [17]. Inverted index ing schemes are popular in content-based retrieval because they allow sublinear-time lookup in very large document databases. In an inverted index, content is mapped to its location in the database. In this paper, "content" refers to a feature tree and its location in the database is the spatio-temporal position in the video. In other words, given the current document number t and a feature tree's spatial position (u, v), the goal is to store in the database the triplet (t, u, v) based on the content of tree/. This
is done with a mapping function which converts "tree/" to some entry in the database where (t, u, v) is stored. This mapping can be made very fast via a hash table, for which update and lookup exhibit flat performance (O(l) complexity). Because mul tiple locations may have the same feature tree representation, this defines a single to many mapping in the sense that a tree is mapped to multiple locations. Similar activity in the video produces similar feature tree representations, so this mapping allows us to recover locations containing a given activity provided that we can define the feature tree representation of that activity.
1.4.1 Hashing
A hash-based inverted index uses a function to map content to an entry in the i n dex.. This is done with a hashing function h such that h : tree/ -> j, where j is a hash table bucket number. Usually, hash functions attempt to distribute content uniformily over the hash space by minimizing the probability of collisions between two non-equal entries:
x 7£ y = > P { h ( x ) = h ( y ) } « 0.
However, in a motion feature space, descriptors for two similar events are never exactly equal. Moreover, it is unlikely that a user query can be translated to feature vectors with sufficient accuracy for such a strict hash function.
As a solution, we resort to a locality-sensitive hashing (LSH) [13] technique. LSH is a technique for approximation of nearest-neighbor search. In contrast to most hashing techniques, LSH attempts to cluster similar vectors by maximizing the probability of collisions for descriptors within a certain distance of each other:
x ~ y ==> P{h(x) = h(y)} > 0.
If feature trees are close in Euclidian distance, then the probability of them having the same hash code is high. Because our feature trees contain M real-valued variables,
1.4. INDEXING
LSH functions can be drawn from the p-stable [10] family:
^a,6,r(tree/) a • tree/ + b
r
where a is a M-dimensional vector with random components drawn from a stable dis tribution, b is a random scalar drawn from a stable distribution and r is an application-dependant parameter. Intuitively, a represents a random projection, b an alignment offset and r a radius controlling the probability of collision.
Indices are built and searched independantly for each feature. Thus, the database is made of five indices If, one for each feature /. Each index If is composed of a set of n hash tables {T/^} , Vi = 1,... ,n. Each hash table is associated its own hash function Hfti drawn from the p-stable family hs^r. The parameter r can be adjusted
to relax or sharpen matches. In our implementation, r is fixed for a given feature. The random parameters a and b ensure projections from the different hash functions complement each other.
Given a feature tree tree/ with hash code (read: bucket number) Z//,t(tree/) = j ,
T f , i [ j , u , v ] d e n o t e s t h e s e t o f d o c u m e n t n u m b e r s { t } s u c h t h a t f e a t u r e t r e e a t ( t , u , v)
have similar content. Lookup in the index If consists of taking the union of document numbers returned by lookup in all tables
/(tree/, u , v ) = UJLJTf t i [ Hf t i(tree/), u , v ] ,
Hashing histograms: Let us mention that descriptors xc and xm based on normal
ization are not normalized at the feature extraction stage. Histograms are normalized before hashing to ensure that histogram aggregation is associative and respects rela tive proportions of the size of video content described by aggregated descriptors.
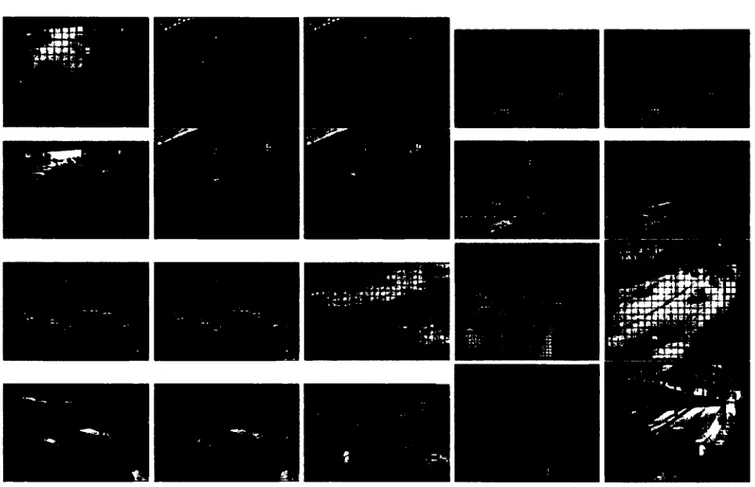
Figure 1.3 illustrates several feature trees partitioned into groups, where trees in the same group have been given the same hashing key. For a given video, we plotted the content of 4 of the most occupied buckets for the motion feature treem. As one
can see, the trees associated to similar motion patterns in various parts of the scene have been coherently hashed into similar buckets.
Figure 1.3: Illustration of the contents of 4 buckets of a hash table for the m o t i o n feature. Arrow size is proportional to the number of hits at the specified location across the entire video. The hash buckets are associated to activity (a) on the side walk (b) on the upper side of the street (c) on the lower side of the street and (d) on the crosswalk have been coherently hashed into 4 buckets.
1.4.2 Data structure
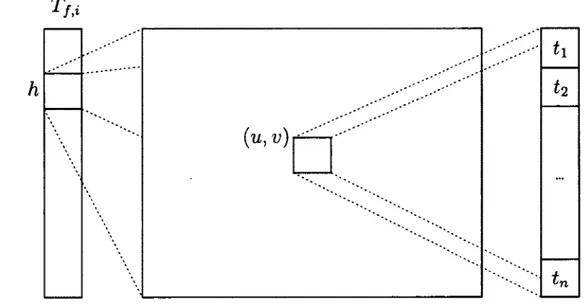
As described previously, the inverted index stores in the same bucket the spatio-temporal position {(£, u, v)} of all trees whose content is similar. In order to reduce retrieval time, instead of storing the {(t,u,v)} triplet directly in each bucket, the spatial position (u, v) is made implicit. As shown in figure 1.4, each bucket is a
(U — k) x (V — k) matrix (see section 1.3.2) whose cells contain a list of document
numbers {t}. Such a structure has a major advantage for our system. As it will be explained in section 1.5.1, queries are often related to a spatial position in the video. For example, a query such as "show me every object going to the left on the upper bound of the highway" has a strong notion of spatial position (the "upper bound of the highway"). In that way, having an (u, v) matrix lookup located right after the
1.4. INDEXING
hashing lookup ensures a retrieval time of 0(1).
T f , i ti h
\
{ u , v ) " -t-i tnFigure 1.4: Hash table structure. For a given tree tree/ with i//it(tree/) = j , lookup
Tfj[h,u,v] is performed in two steps: (1) fetch the bucket at position j and (2) fetch the list of document numbers at position (it, v) in the bucket.
Absence of Activity: In order to minimize the storage requirements of the index
If, features are only retained for areas of the video containing non-zero activity. During the indexing phase, if the activity xa is lower than a certain threshold T for
all nodes in the tree, the tree is not indexed.
Storage Requirements: The feature index I f is lightweight. In contrast to ap proaches relying on a distance metric, such as K-nearest neighbor search, the hash-based index representation does not require storage of feature descriptors. As men-tionned previously, Tfit contains only document numbers {t}. These are stored on
4-byte variables. The storage requirement is thus linear in the amount of indexable content. Assuming the amount of indexable content in the video is a proportion a of
the video length, the size (in bytes) of the hashing table can be estimated using:
siz e { Tf j i) = { U - k ) x { V - k ) x ^ x A x a
where ( U — k ) x ( V — k ) x ^ corresponds to the total number of trees in the video and a is the proportion of trees that contain enough activity to be indexed. For example, a typical setup calls for the settings B = 16, A = 30, H = 240, W = 320, k = 2 and an activity rate a = 2.5%. Consider 5 features, each using 3 tables. The total size of the index for a 5 hour video requires only 5Mb while the input color video requires almost 7Gb (compressed).
Let us mention that there is some overhead in implementing the hash table and the buckets. Supposing a hash table Tjti with b buckets, Tf}i requires at least an array
with b pointers to buckets and b matrices of (U — k) x (V — k) pointers to lists (this structure is depicted in figure 1.4). If r is small, Hfti will generate a very large number
of hash codes and each hash table bucket will contain few entries. If this overhead is prohibitive, a sparse matrix representation may prove useful.
1.4.3 Building the lookup table
As video streams in, the index for each feature is updated. The updating procedure is simple and fast. The index is updated online and does not require to be re-built when new data arrives. Thus, the index is guaranteed to be up to date and search is ready to proceed at any time. This is an important property for surveillance videos for which data is constantly renewed.
Algorithm 1.1 contains pseudo-code for the update procedure. After extraction of feature / for document t is completed, the extracted features are grouped into trees, a s d e s c r i b e d i n s e c t i o n 1 . 3 . T h e n , I f i s u p d a t e d w i t h t h e m a p p i n g t r e e / —> ( t , u , v ) for each tree position (u, v) covering an area with significant activity. This update is repeated for each feature /.
Note that the index update operation is performed immediately after the docu ment is acquired, and document numbers t are unique and sequential. Because of this,
1.5. SEARCH ENGINE
Algorithm 1.1 Updating the LSH-based Index procedure UPDATEINDEX(/, t )
for each feature / do
{atom/} <— features extracted from document t {tree/} A:-level trees for {atom/}
for each tree ( u , v ) do for each table i do
if treea > T then h <— H ft i( t r e e f & t ( u , v ) ) T ft i[ h , u , v ] < - T ft i[ h , u , v \ U t end if end for end for end for end procedure
T ft i[ h , u , v ] can be represented as a list, and appending to this list keeps T ft i[ h , u , v ]
sorted at all times. Keeping the list sorted allows efficient implementation of set operations, which are used to implement combined queries in section 1.5.1.
1.5 Search engine
In the previous sections, we have shown how to extract low-level features from a video sequence and index them for 0(1) content-based retrival. This section explains how to use this feature index as a basis for high-level search.
A query is a combination of features located within a region of interest (ROI). Lookup in the feature index is based on converting the query features into a set of feature trees. These trees are used to lookup location of similar content in the feature index. Table lookup results are called partial matches. Partial matches correspond to areas in the video that locally match the query. Full matches occur when complemen tary partial matches are combined together. Two partial matches are complementary when they correspond to different parts of the query. For example, when a vehicle performs a U-turn motion at a street light, partial matches at the beginning of a U-turn motion an at the end of the U-turn motion are complementary because they
match different parts of the ROI. As stated earlier, activities in a video are inherently complex and show significant variability in time duration. Thus, full matches may span across document boundaries. The search engine uses an optimization procedure to find video segments (one or more documents) that contain complementary partial matches and fit the query well. The video segments are ranked and only the best segments are returned.
The search engine may be summarized in the following steps: 1. input a query and convert to feature trees;
2. lookup partial matches using the index built in section 1.4;
3. find full matches using an optimization procedure accounting for the variable duration of events;
4. rank video segments and select those that best match the query.
1.5.1 Queries
A query is a combination of features located within a ROI drawn by the user. As explained in section 1.4, a feature index // contains the spatio-temporal location
(u,v,t) of every feature tree tree/ recorded in the video. A simple query q describes
desired results by assigning a feature tree tree/ to each spatial position (u,v) over a ROI. In other words, q{u,v) denotes a feature tree tree/ that is expected to be found at position (u, v) in the results. The ROI can be the entire field of view or a smaller area in which to perform the search.
When a user initiates a search, a blank document like the one in figure 1.1 is created. The user then roughly selects a ROI (green regions in figure 2.10) together with the size and/or the color and/or the persistence and/or the motion of the object the user is looking for. Specification of color, persistence and size is straightforward. The motion value is computed based on the user's depiction of the direction of motion. This direction of motion is depicted with a specific brush (red arrows in figure 2.10). Once this is done, feature trees are built following the method described in section 1.3.2. Figure 2.10 presents 10 different queries with their ROI.
1.5. SEARCH ENGINE
1.5.2 Lookup of partial matches
At the lowest level, search is a simple lookup in the index for one feature used in the query. For example, a U-turn motion query will require a lookup for matching motion feature trees in motion index Im. Lookup of partial matches in a single feature
index Ij is expressed as:
L if ( q ) = U (u, „) € R Oi { ( t , u , v ) , E I f
(
q ( u,
v ) , u , u ) } .A richer query language can be made with so-called compound queries. A com
pound query is a combination of more than one lookup, which allows to express queries
such as "find small red or green objects" or "find large stationary objects". The query
Q "find small red or green objects" is a combination of three simple queries: q\ (small
objects), q2 (red objects) and <73 (green objects). Given the color index Ic and the
object size index I3, the partial matches satisfying complex query Q can be expressed
as:
M ( Q ) = LI a( q i ) H ( L ic( q 2 ) U L je( q3) ) .
This query language can express arbitrarily large queries, provided that the query logic can be expressed using lookups and standard operators: union, intersection and set difference.
1.5.3 Full matches
Search in a surveillance video requires more than partial matches. Activities in a video are inherently complex and show significant variability in time duration. For instance, a fast car taking a u-turn will span across fewer documents and generate different motion features than a slow moving car. Also, due to the limited size of a document (typically between 30 to 100 frames), partial matches may only correspond t o a p o r t i o n o f t h e r e q u e s t e d e v e n t . F o r e x a m p l e , p a r t i a l m a t c h e s i n a d o c u m e n t t may only correspond to the beginning of a u-turn. The results expected by a user are so-called full maches, i.e. video segments [t,t + A] containing one or more documents (A > 0). For example, the video segment R — {t,t + l,t + 2} corresponds to a full u-turn match when documents t,t + l,t + 2 contain the beginning, the middle and
the end of the u-turn. Given a query Q and a set of partial matches M ( Q ) , a full match starting at time r is defined as
RQIT( A) = {(u, <u)|(t, u , v ) € M ( Q ) , Vt € [r, r + A]} .
Thus, RQ,T(A) contains the set of distinct coordinates of trees partially matching Q in the video segment [r, r + A]. As stated earlier, the duration of the match A
is unknown a priori. However, this value can be estimated using a simple value optimization procedure.
Algorithm 1.2 Greedy search algorithm
L: procedure SEARCH (Q)
2: r <r- 0
3: T 4-1
4: while r < number of documents do
5: A* 4- arg maxA>o UQ,T(A)
6 : r f - r U RQ> t(A*)
7: T 4- T + A*
8: end while
9: return r
10: end procedure
Full matches using a greedy algorithm
The main difficulty in identifying full matches comes with the inherent variabil ity between the query and the target. This includes time-scaling, mis-detections and other local spatio-temporal deformations. Consequently, we are faced with the problem of finding which documents to fuse into a full match given a set of partial matches.
We formulate this issue as the optimization problem:
A* = argmaxi>G)T(A). (1.1)
where Q is the query, r is a starting point and A the length of the retrieved video segment. The value function VQ,T(A) maps the set of partial matches in the interval
1.5. SEARCH ENGINE
[T, T + A] to some large number when the partial matches fit Q well and to a small value when they do not. To determine the optimal length of a video segment starting at time r we maximize the above expression over A.
A simple and effective value function VQ> T(A) is:
.RQ,T(A) = { ( u , v ) \ ( t , u , v ) G M ( Q ) , V*G[T,T + A]}
U0FT(A)= I-RQ,T(A)| — AT, (1.2)
The value function is time-discounted since RQ^t(A) is increasing in A (by definition,
RqA&) C Rq,t(A + 1)). The parameter A serves as a time-scale parameter and
controls the size of retrieved video segments.
We can determine A by a simple and fast greedy algorithm (see algorithm 1.2). As will be shown in section 2.9, Eq. (1.2) and 1.1 produce compact video segments while keeping low false positives and negatives rates.
The fact that this simple algorithm produces effective matches may seem surpris ing. To build intuition we consider the case of a random video model and attempt to characterize the probability of obtaining a good match. In other words, our objec tive is to characterize the false alarm probability arising from a random video. Our random video, 1Z, is a temporal sequence of documents. Each document is populated with a fixed number of trees drawn uniformly at random from the set, 7I of all dis tinct trees. We next consider a query containing |Q| distinct trees and characterize the false alarm probability for a thresholding algorithm that thresholds VQ< t(A).
Theorem 1.5.1 Suppose the query Q consists of |Q| distinct trees and the random
video has RQ,t(A) matches. For A = I\Q\ the probability that log(t>Q) T(A)) > A\Q\
for some a E (0, 1) is smaller than 0(1/|<3|2).
This result suggests that the false alarm probability resulting from an algorithm that is based on thresholding t>gjT(A) is small. This result is relevant because we
expect log(tfQjT(A)) for video segments that match the query to have a value larger
than a|<3| for some a when A — f2(|Q|).
Proof: For simplicity we only consider each document to contain a single random tree drawn from among \H\ trees. The general result for a fixed number of trees
follows in an identical manner. We compute the value of random video of length r, i.e.,
P {uq,o(A) > exp(o|Q|)} = P{\RQi0{A)\ > a|Q| + 7} ,
where we substituted j = 7 and taken logarithms on both sides to obtain the second equation. Let, Aj be the number of documents before we see a new document among the set Q after just having seen the j — 1th new document. This corresponds to the inter-arrival time between the (j — l)th and jth document. Given our single tree random model we note that RQto(A) is a counting process in A and so we have the
following equivalence,
e
RQ% O(A) > I <==> ^ 2 A J < A.
j = 1
Thus we are now left to determine the P A j < A| where £ = a \ Q \ + j . Next, Ai, A2,... are independent geometric random variables. The jth random variable A_, has a geometric distribution with parameter pi = Using these facts we can determine the mean value and variance of the sum using linearity of expectations. Specifically, it turns out that
v=i / 3=1 •
Upon computation the mean turns out to be 0(\H\), while the variance turns out to be 0(|"H|2/|Q|2). We now apply Chebyshev inequality to conclude
P { vQ,0(A) > exp(a|<5|)} < 0(1/|Q|2),
which establishes the result. •
Full matches using dynamic programming
For complicated action such as making an illegal u-turn or hopping a subway turnstile, the greedy optimization presented in Section 1.5.3 can prove ineffective at
1.5. SEARCH ENGINE
eliminating false positives. As an alternative, we present a dynamic programming approach that leverages the structure of the activity to dramatically reduce false alaxm rates for applicable queries.
In this approach, the query activity is broken down by the user into component actions to create a query for each action component. For each component action, matches in a given document are clustered based on proximity within the image to identify which matches are generated by a single actor. The cluster labels Li applied t o e a c h m a t c h m a i n t a i n t h e i n v a r i a n t i n ( 1 . 3 ) f o r m a x i m u m d i s t a n c e D .
V ( i , j ) d i j < D => L i = L j . (1.3)
After clustering has been done, we employ the Smith-Waterman algorithm [30] for dynamic programming, originally developed for gene sequencing. This approach is designed to be robust to two types of noise: insertion of unrelated documents into the search video, and the deletion of parts of the query action. In the U-turn example, a car may stop at a light before taking a U-turn, creating a number of documents which do not involve any of the 3 action components. Alternatively, we may not observe the part of the U-turn where the car comes up to the stop light before the U-turn; this would represent a deletion of a component of the query. In addition to insertion and deletion, we observe in video sequences continuation distortion: that for any given activity, a single action component might span multiple documents.
Our dynamic approach solves, for each video segment Am of the search video,
and each action component £?„, what the optimal sequence of matches which ends in document n with action component Bn. Given an activity query sequence B with