HAL Id: hal-02602346
https://hal.inrae.fr/hal-02602346
Submitted on 16 May 2020
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Incertitudes liées à la régionalisation de la méthode
SHYREG
P. Arnaud, P. Cantet
To cite this version:
P. Arnaud, P. Cantet. Incertitudes liées à la régionalisation de la méthode SHYREG. [Rapport de recherche] irstea. 2015, pp.24. �hal-02602346�
PROGRAMME MEDDE (DGPR / SRNH) - IRSTEA 2015
Connaissance et prévention des risques naturels et hydrauliques
Ces travaux bénéficient du soutien du Ministère chargé de l’Ecologiepar décision de subvention n°2101527675
Décembre 2015
Patrick ARNAUD
Philippe CANTET
Irstea, Unité de recherche « RECOVER »
3275 Route Cézanne – CS 40061
13 182 Aix-en-Provence Cedex 5
www.irstea.fr
Action 2-1 : Evaluation quantitative de
l’aléa hydrologique (SHYREG)
Sous action 2-1-2 : Détermination
des incertitudes de la méthode
SHYREG
PHASE 2 - INCERTITUDES LIEES A LA REGIONALISATION DE
LA METHODE
Table des matières
I. Introduction _______________________________________________________________________ 4
II. Methodologie _____________________________________________________________________ 5
III. Les données _______________________________________________________________________ 6 IV. Régionalisation de la méthode ________________________________________________________ 7
V. Résultats _________________________________________________________________________ 9
1. Différence entre le Local et le Regional _______________________________________________ 9 2. Différence sur les durées _________________________________________________________ 10 3. Dissymétrie de l’intervalle de confiance _____________________________________________ 11 4. Localisation ____________________________________________________________________ 13
VI. Conclusion _______________________________________________________________________ 17
VII. Références bibliographiques ______________________________________________________ 19
VIII. ANNEXE 1 : Rappel sur la méthode SHYREG __________________________________________ 21
Liste des figures
Figure 1 : Principe de la procédure de bootstrap appliquée au calage de la méthode SHYREG. ____________________ 5 Figure 2 : Exemple illustrant la variabilité des caractéristiques d’échantillonnage d’un paramètre du générateur de pluies (paramètre PJMAX été : et ). _______________________________________________________________ 6 Figure 3 : Principe de la régionalisation du paramètre hydrologique _________________________________________ 7 Figure 4 : Méthode mise en œuvre pour estimer les intervalles de confiance de la méthode SHYREG. _______________ 8 Figure 5 : Distribution des amplitudes des intervalles de confiance des quantiles de débits de pointe (de périodes de retour 2 à 1000 ans), calculés sur les bassins jaugés (Locale) et sur les pixels « France » (Régionale). _______________ 9 Figure 6 : Distribution des amplitudes des intervalles de confiance des quantiles de débits de pointe et des débits journaliers, de périodes de retour 2 à 1000 ans, estimés régionalement._____________________________________ 10 Figure 7 : Distribution des amplitudes positives et négatives des intervalles de confiances des quantiles de débits de pointe et des débits journaliers, de périodes de retour 2 à 1000 ans, estimés régionalement. ____________________ 11 Figure 8 : Distribution des coefficients d’asymétrie des distributions d’échantillonnage des quantiles de débits de pointe de périodes de retour 2 à 1000 ans, estimés localement et régionalement.___________________________________ 12 Figure 9 : Distribution des coefficients d’aplatissement des distributions d’échantillonnage des quantiles de débits de pointe de périodes de retour 2 à 1000 ans, estimés localement et régionalement. _____________________________ 12 Figure 10 : cartographie des amplitudes des intervalles de confiances des débits de pointe, pour les valeurs décennales et millénales. ____________________________________________________________________________________ 13 Figure 11 : cartographie des amplitudes des intervalles de confiances des débits journaliers, pour les valeurs
décennales et millénales. __________________________________________________________________________ 13 Figure 12 : Corrélation entre la valeur du paramètre de production S0/A et l’amplitude des incertitudes calculées sur les débits de pointes (en haut) et les débits journaliers (en bas), pour les périodes de retour de 10 ans (à gauche) et 1000 ans (à droite).____________________________________________________________________________________ 15 Figure 13 : Corrélation entre la valeur de la pluie journalière décennale et l’amplitude des incertitudes calculées sur les débits de pointes (en haut) et les débits journaliers (en bas), pour les périodes de retour de 10 ans (à gauche) et 1000 ans (à droite).____________________________________________________________________________________ 16 Figure 14 : Principe du calage de la méthode SHYREG Débit _______________________________________________ 22
I. INTRODUCTION
Ce travail est un livrable de la convention Multirisques SNRH – Irstea 2015, et la poursuite des travaux effectués en 2014 sur l’estimation des incertitudes liées à la mise en œuvre de la méthode SHYREG.
Pour rappel, c’est dans le cadre de ses missions de recherches et d’appuis aux politiques publiques, et avec l'aide de financements du Ministère de l'écologie (MEDDE/DGPR/BRM), que la méthode SHYREG débit de cartographie quantitative de l’aléa hydrologique a été développée à l’Irstea. L’application de cette méthode permet l’élaboration d’une base de données, nommée base SHYREG-débit, qui fournit les quantiles de débits de crues (débit de pointe et les débits moyens sur 1 à 72 heures) pour des périodes de retour de 2 à 1000 ans, sur l’ensemble du territoire de France métropolitaine, à la résolution kilométrique. Cette base de données a été mise à disposition de la Direction Générale de la Prévention des Risques (DGPR) en 2013 (http://shyreg.irstea.fr) [Patrick Arnaud et al., 2013].
Bien que jugée robuste et fiable suite à une évaluation comparative dans le cadre du projet ANR Extraflo [Patrick Arnaud et al., 2014; Carreau et al., 2013; Kochanek et al., 2013], la méthode présente des marges d’amélioration qui nécessitent la poursuite de son développement. En parallèle, des recherches sur les incertitudes de la méthode sont menées pour produire des intervalles de confiances associés aux quantiles de crues fournis par la méthode.
L’étude des incertitudes est relativement complexe dans ce genre de méthode combinant plusieurs étapes de modélisation et multipliant ainsi les facteurs d’incertitudes. Un premier travail a été conduit par l’étude des incertitudes du générateur de pluie, réalisée lors de la thèse de Aurélie Muller [Muller, 2006; Muller et
al., 2009]. Bien que cette étude soit partielle et réalisée sur quelques stations pluviométriques, elle montre
que pour les pluies, la méthode SHYREG produit des intervalles de confiances plus étroits que ceux produits par l’ajustement d’une loi à trois paramètres (loi GEV). Par ailleurs, des travaux ont été menés sur l’estimation des incertitudes liées au paramétrage des modèles hydrologiques [Bourgin, 2014; Coron, 2013], mais ces travaux ont été réalisés en simulation de chroniques et pas encore transposés au contexte de la prédétermination des crues (extrapolation vers des événements extrêmes).
En 2014, un premier travail a consisté à évaluer les incertitudes sur l’estimation des débits, dues à la modélisation hydrologique réalisée dans la méthode SHYREG. Ce travail exploratoire a porté sur les incertitudes liées au calage du modèle hydrologique sur les données des bassins versants jaugés, tout en prenant en compte la propagation des incertitudes liées à la pluie.
En 2015, le travail a été de poursuivre les investigations sur les différentes sources d’incertitudes de la méthode, en particulier dans sa version régionalisée. Les premiers résultats sont présentés dans ce rapport.
II. METHODOLOGIE
En 2014, l’étude des incertitudes s’est focalisée sur les quantiles de débits fournis lors du calage de la méthode, c'est-à-dire dans un contexte « jaugé ». L’exploration des incertitudes a été abordée par quatre cas d’étude :
- Cas 1 : les incertitudes uniquement liées aux incertitudes dues à la pluie, - Cas 2 : les incertitudes uniquement liées au calage du modèle hydrologique,
- Cas 3 : les incertitudes liées à la pluie et à la modélisation hydrologique, prises de façon indépendantes, - Cas 4 : les incertitudes liées à la pluie et à la modélisation hydrologique, prises en compte de façon
dépendante.
La configuration la plus réaliste est la configuration du cas 4. En effet, il faut prendre en compte la chronologie du calage de la méthode, qui s’appuie sur l’information de la pluie (calage préalable du générateur de pluies) pour ensuite caler le modèle hydrologique. Les incertitudes liées au calage du modèle de pluie sont alors prises en compte de façon indirecte lors du calage du modèle hydrologique, les rendant ainsi dépendantes.
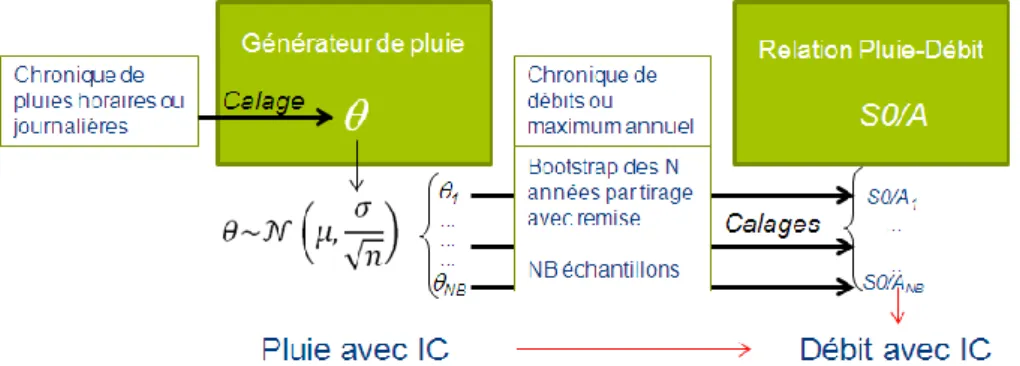
On retient donc pour la suite le cas numéro 4, c'est-à-dire l’estimation des incertitudes liées aux pluies et aux débits en prenant en compte leur dépendance dans la mise en œuvre de la méthode. Dans ce cas, l’unique paramètre calé bassin par bassin, le paramètre est déterminé en prenant en compte à la fois le re-calage du générateur de pluie sur des pluies ré-échantillonnées (permettant la prise en compte de l’incertitude sur les données de pluies) et le ré-échantillonnage des chroniques de débits (permettant la prise en compte de l’incertitude sur les données de débits) (Figure 1).
Figure 1 : Principe de la procédure de bootstrap appliquée au calage de la méthode SHYREG.
La procédure de bootstrap, effectuée dans un premier temps sur la mise en œuvre locale de la méthode (calage sur des données), prend donc en compte les deux principales composantes à l’origine des incertitudes : l’échantillonnage des pluies et l’échantillonnage des débits observés servant aux calages des paramètres de la méthode. Cette procédure va alors être appliquée sur les bassins de calage pour déterminer un jeu de paramètres qui sera ensuite régionalisé. On obtiendra ainsi un ensemble de jeux de paramètres régionalisés (ou cartes de paramètres régionalisés) permettant de transférer l’incertitude sur les bassins non jaugés.
III. LES DONNEES
Le travail a été réalisé sur l’ensemble du territoire métropolitain français, à partir des données de bassins versants jaugés répertoriés dans la base de données HYDRO (http://www.hydro.eaufrance.fr/). Ces données correspondent à 1891 bassins versants localisés sur la carte ci-contre (contre 1162 bassins lors de l’étude 2014). Leur surface est comprise entre 1 et 10000 km², avec une médiane à 184 km². Ces stations de mesure ont été critiquées en partie lors de l’étude de régionalisation de la méthode SHYREG [Aubert et
al., 2014; Organde et al., 2013a] et puis dans le cadre du travail de thèse de Jean Odry [Odry, 2015].
Ces stations présentent une information
hydrométrique de plus de 20 ans (avec une médiane à 40 ans). Cette information permet le calage de lois statistiques (GEV « bornée », Gumbel) permettant d’estimer des quantiles de crues. Ces quantiles vont servir à caler le paramètre de la méthode (sur les quantiles courants 2, 5 et 10 ans).
Les paramètres du générateur de pluie sont ceux ayant servi à calculer la base de données SHYREG-Pluie [Patrick Arnaud and Lavabre, 2010]. Ces valeurs sont issues de moyennes calculées sur des données de pluies observées entre 1977 et 2002. Pour estimer
l’incertitude sur ces paramètres il faut connaitre l’écart-type et l’effectif des valeurs ayant servi à calculer les moyennes. Ces valeurs ont été calculées à partir des données SAFRAN entre 1977 et 2002. On a donc estimé un écart-type et un effectif pour les différents paramètres du générateur de pluie (exemple sur la Figure 2). Ces valeurs, déterminées aux centroïdes des bassins versants, permettent de paramétrer le générateur de pluies et de prendre en compte ses incertitudes.
Figure 2 : Exemple illustrant la variabilité des caractéristiques d’échantillonnage d’un paramètre du
générateur de pluies (paramètre PJMAX été : et ).
On dispose donc de données suffisantes pour évaluer les intervalles de confiance de la méthode SHYREG, appliquée localement sur 1891 bassins versants sur l’ensemble de la France métropolitaine. Ces données serviront aussi à la régionalisation du paramètre de production .
IV. REGIONALISATION DE LA METHODE
La régionalisation de la méthode SHYREG a été présentée dans de nombreux rapports [P. Arnaud, 2015;
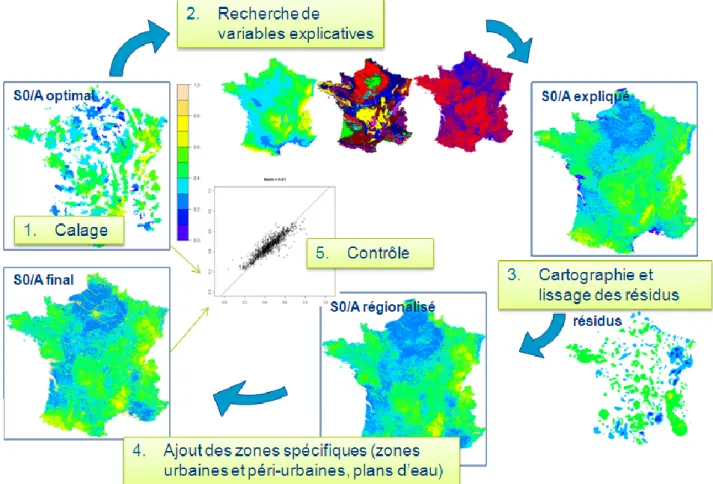
Aubert, 2012a; Organde et al., 2013b]. Elle consiste à cartographier l’unique paramètre calé bassin par
bassin : le paramètre . La méthode de régionalisation choisie est présentée sur la Figure 3. Elle repose sur la recherche de régressions linéaires simples entre le paramètre optimisé sur chaque bassin versant de calage et des variables environnementales, suivi d’une interpolation spatiale des résidus à cette régression par la méthode IDW (inverse des distances pondérées). Certaines zones comme les zones urbaines, péri-urbaines et les plans d’eau voient leur paramétrage fixé. Ces zones (représentant 5,2 % du territoire) ne font pas partie des processus de calage et de régionalisation car les valeurs du paramètre y sont imposés.
Figure 3 : Principe de la régionalisation du paramètre hydrologique
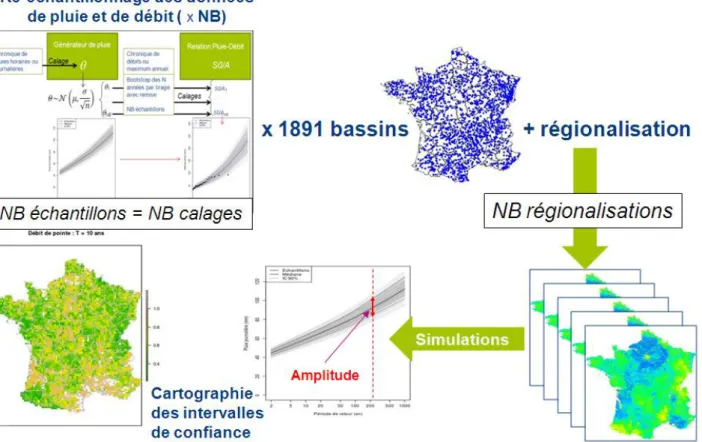
Cette mise en œuvre de cette procédure de régionalisation est relativement simple et suffisament « automatisable » pour être appliquée un grand nombre de fois. La régionalisation est alors appliquée pour chaque jeu de paramètres issus du calage de la méthode sur les données ré-échantillonnées des 1891 bassins versants. Le nombre d’échantillons (NB) a été fixé à 200 (nombre suffisant pour attendre une certaine stabilité dans l’estimation des intervalles de confiance). A partir des NB simulations, issues des NB cartes de paramètres régionalisés, on obtient NB distributions de fréquences de pluies et de débits fournies par la méthode sur l’ensemble du territoire. A partir de ces distributions, on calcule pour chaque quantile de crues, la médiane des NB valeurs obtenues ainsi que les quantiles 5% et 95% (respect. et
Le principe de l’approche est résumé dans la Figure 4. Le ré-échantillonnage des données de pluies et de débits est effectué dans un premier temps pour chacun des 1891 bassins versants jaugés. Avec les données ré-échantillonnées, un calage de la méthode est réalisé et permet de déterminer les quantiles de pluies et de débits aux stations jaugées. La régionalisation des paramètres de la méthode permet ensuite de mettre en œuvre la méthode sur les bassins non jaugés et fournir une estimation des quantiles de pluies et de débits sur les sites non jaugés. Le ré-échantillonnage réalisé NB fois, permet d’estimer NB distributions de fréquences des pluies et des débits, fournissant ainsi une estimation de l’incertitude.
Figure 4 : Méthode mise en œuvre pour estimer les intervalles de confiance de la méthode SHYREG.
Les intervalles de confiance sont alors évalués par le calcul d’une amplitude relative égale à :
Pour étudier une éventuelle dissymétrie dans l’intervalle de confiance, on calcule aussi une amplitude positive ( ) et une amplitude négative ( ) :
et
Les calculs étant relativement longs, les débits spécifiques (associés à une maille de 1 km²) sont calculés tous les 5 km. La variabilité entre deux mailles de calculs sera alors supposée linéaire.
V. RESULTATS
Les incertitudes sont représentées par l’intermédiaire de Box Plot représentant la distribution des valeurs des amplitudes calculées soit sur les 1891 bassins versants jaugés (« local »), soit sur les différents pixels du territoire (1), appelés pixels « France » (« Régional »). Ces amplitudes sont calculées sur les quantiles de différentes durées et de différentes périodes de retour. Les Box plot représentent les quantiles 5%, 25%, 50%, 75% et 95% des valeurs considérées.
1. DIFFERENCE ENTRE LE LOCAL ET LE REGIONAL
Pour faire la transition entre les résultats obtenus en 2014 sur les bassins versants jaugés et ceux obtenus dans cette étude en sites non-jaugés, on compare les valeurs des amplitudes calculées sur les 1891 bassins de calage (approche « locale ») et sur les pixels situés en sites non jaugés (approche « régionale ») (Figure 5).
Figure 5 : Distribution des amplitudes des intervalles de confiance des quantiles de débits de pointe (de périodes de retour 2 à 1000 ans), calculés sur les bassins jaugés (Locale) et sur les pixels « France »
(Régionale).
On observe une augmentation de l’amplitude de l’intervalle de confiance sur les quantiles régionaux, par rapport à celle des quantiles locaux. Ce résultat était attendu car les valeurs du paramètre S0/A estimé régionalement « combinent » les incertitudes des plusieurs valeurs estimées localement aux sites de calage.
1
Pour juger de l’incertitude en sites non jaugés, on reste sur les données de la grille de débits spécifiques issues de la régionalisation du paramètre S0/A. Dans ce cas, on ne fait pas le calcul des débits à l’exutoire des bassins versants qui fait intervenir la FTS. On peut penser que les coefficients de la FTS étant déterminés de façon unique sur la France, leur estimation reste robuste (peu variable), même si elle n’est pas « optimale », et sans impact notable sur l’incertitude liées à l’échantillonnage.
2. DIFFERENCE SUR LES DUREES
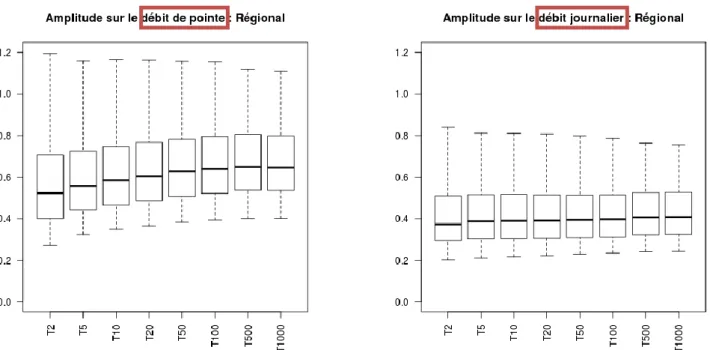
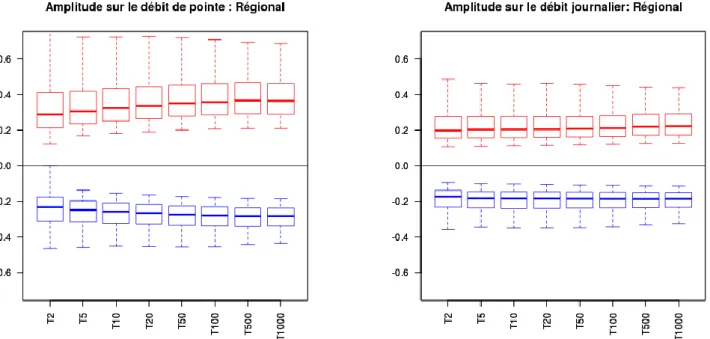
L’étude 2014 a montré des résultats uniquement sur l’incertitude des débits de pointe. Les incertitudes sont cependant différentes en fonction de la durée à laquelle on s’intéresse. Les graphiques de la Figure 6 montrent la gamme de variation des amplitudes calculées sur les débits de pointe et sur les débits journaliers (de façon régionale, c'est-à-dire sur les pixels « France »).
Figure 6 : Distribution des amplitudes des intervalles de confiance des quantiles de débits de pointe et des débits journaliers, de périodes de retour 2 à 1000 ans, estimés régionalement.
On s’aperçoit que les débits de courtes durées (débit de pointe) fournis par la méthode présentent en moyenne des amplitudes plus fortes que les débits journaliers. Cette différence est d’ailleurs accentuée pour les périodes de retour les plus fortes. Cela est dû au fait que les débits de pointe sont plus sensibles que les volumes de crues, aux valeurs prises par le paramètre et par la pluie. Les incertitudes sur la pluie et sur le paramètre a plus d’impact sur les débits de pointe car ces deux incertitudes peuvent avoir un impact sur la production des bassins (qui influence la pointe et le volume de la crue), mais aussi sur la cinétique des crues (qui influence surtout la pointe de la crue).
La non linéarité entre la pluie et le débit, introduite par le modèle hydrologique, conduit la méthode SHYREG a produire des crues de plus en plus dépendantes de la pluie lorsque l’on tend vers des pluies fortes ou des bassins productifs, et à modéliser dans ces cas là des crues de plus en plus rapides (ou « pointues »). Cette propriété conduit alors aux résultats présentés ici, à savoir que l’incertitude sur la pluie et l’incertitude sur la caractérisation du paramètre conduisent à des incertitudes d’autant plus élevées que l’on s’intéresse aux débits de courtes durées et aux périodes de retour les plus élevées.
3. DISSYMETRIE DE L’INTERVALLE DE CONFIANCE
On s’intéresse ici à la forme de l’intervalle de confiance, à travers la comparaison des amplitudes « positives » et « négatives ». Les graphiques de la Figure 7 montrent en rouge les amplitudes positives (erreur relative entre le quantile 95% et la médiane) et en bleu les amplitudes négatives (erreur relative entre le quantile 5% et la médiane).
Figure 7 : Distribution des amplitudes positives et négatives des intervalles de confiances des quantiles de débits de pointe et des débits journaliers, de périodes de retour 2 à 1000 ans, estimés régionalement.
On observe que les intervalles de confiance sont relativement centrés, avec des valeurs positives et négatives du même ordre. On observe toujours une amplification de l’intervalle pour les durées de débit courtes et pour les périodes de retour les plus élevées.
Pour mieux apprécier la forme de l’intervalle de confiance, on calcule les coefficients d’asymétrie et d’aplatissement des distributions d’échantillonnage des différents quantiles. Le coefficient d’asymétrie est égal à zéro si la distribution est symétrique, il est négatif si il y a une dissymétrie négative ou « droite » (vers les valeurs les plus faibles) et il est positif si il y a une dissymétrie positive ou « gauche » (vers les valeurs les plus fortes). Le coefficient d’aplatissement prend pour référence la forme d’une distribution normale (gaussienne). Le coefficient est égal à zéro s’il présente un aplatissement équivalent à celui d’une loi normale, il est négatif si l’aplatissement est moins fort que celui de la loi normale (distribution plus recentrée sur la moyenne) et il est positif si l’aplatissement est plus fort que celui de la loi normale (distribution plus dispersée autour de la moyenne). Les résultats sont présentés sur les graphiques des Figure 8 et Figure 9, pour les quantiles estimés localement et régionalement.
Figure 8 : Distribution des coefficients d’asymétrie des distributions d’échantillonnage des quantiles de débits de pointe de périodes de retour 2 à 1000 ans, estimés localement et régionalement.
Figure 9 : Distribution des coefficients d’aplatissement des distributions d’échantillonnage des quantiles de débits de pointe de périodes de retour 2 à 1000 ans, estimés localement et régionalement.
On s’aperçoit que la plupart du temps, les distributions d’échantillonnage des quantiles présentent une dissymétrie positive et un aplatissement proche de celui d’une loi normale. La dissymétrie est plus marquée sur les quantiles estimés régionalement. Dans ce cas, c’est plutôt l’incertitude sur la valeur du paramètre qui conduit à augmenter l’intervalle de confiance et produire une dissymétrie en proposant des valeurs de ce paramètre trop éloignée de sa valeur moyenne. La non-linéarité entre la valeur de ce paramètre et les quantiles qu’il produit, conduit alors à cette dissymétrie.
4. LOCALISATION
La distribution spatiale des amplitudes calculées sur les pixels, nous permet de localiser les régions où les incertitudes sont plus ou moins fortes. Cette variabilité spatiale est représentée sur les cartes des Figure 10 et Figure 11, pour les débits de pointe et les débits journaliers de périodes de retour 10 et 1000 ans.
Figure 10 : cartographie des amplitudes des intervalles de confiances des débits de pointe, pour les valeurs décennales et millénales.
Figure 11 : cartographie des amplitudes des intervalles de confiances des débits journaliers, pour les valeurs décennales et millénales.
Notons que les résultats présentés sur les quantiles estimés régionalement, sont associés aux quantiles de crues calculés sur des pixels. Bien qu’évalués sur des débits spécifiques, les intervalles de confiance (ou amplitude de l’intervalle de confiance) sont représentatifs des intervalles de confiance des débits intégrés sur les bassins versants.
Ils surestiment cependant les incertitudes que l’on aurait pu calculer en intégrant les quantiles sur les bassins versants. En effet, lors de la régionalisation et en particulier lors de l’étape de recherche de régression, des variables explicatives différentes peuvent être sélectionnées entre deux ré-échantillonnages. Cela peut conduire à une variabilité à l’échelle du pixel qui sera lissée lors de l’intégration sur les bassins versants. Les intervalles de confiance devraient donc être variables en fonction de la surface du bassin. Ce point devra être étudié ultérieurement. L’analyse des incertitudes, effectuée au niveau des pixels, conduit ainsi à des valeurs d’amplitudes parfois très fortes à l’échelle du pixel mais qui ne sont pas représentatives des résultats auxquels s’attendre à l’échelle de bassins versants. Pour éviter de biaiser les interprétations des résultats présentés dans ce paragraphe, on a choisi de supprimer 42 pixels (sur 25750) dont l’amplitude est supérieure à 2.
La répartition spatiale des amplitudes montrent une grande variabilité sur l’ensemble du territoire. Cette variabilité est le produit conjugué de plusieurs facteurs comme l’incertitude sur les pluies, l’incertitude sur la paramétrisation du modèle hydrologique et l’incertitude liée à la régionalisation. L’analyse des cartes montrent certaines de ces tendances :
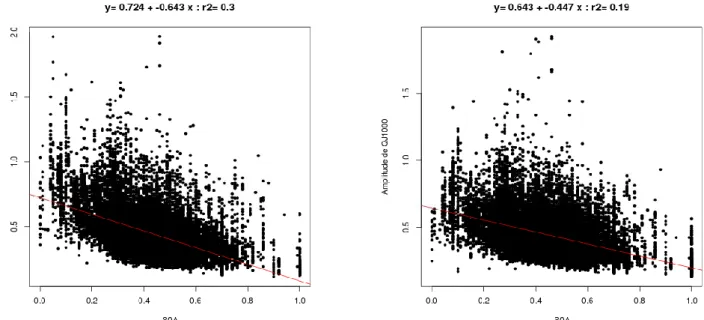
Les amplitudes semblent plus fortes sur les zones peu productives (Bassin Parisien, Aquitaine). On observe d’ailleurs une liaison entre l’amplitude et la valeur moyenne prise par le paramètre (Figure 12). Cette corrélation est négative ce qui montre que plus la valeur de est petite, plus les amplitudes peuvent être grandes. Cela traduit encore l’effet de la non linéarité produite par le modèle hydrologique.
Figure 12 : Corrélation entre la valeur du paramètre de production S0/A et l’amplitude des incertitudes calculées sur les débits de pointes (en haut) et les débits journaliers (en bas), pour les périodes de retour de
10 ans (à gauche) et 1000 ans (à droite).
Les amplitudes semblent plus faibles en zone d’altitude (Pyrénées, Jura, Vosges, Massif Central). Ce résultat peut être lié en partie à la prédominance du rôle du calcul du débit de base dont l’incertitude n’est pas prise en compte dans cette étude.
Les amplitudes semblent aussi plus fortes en climat méditerranéen (la bordure méditerranéenne en particulier). On observe cependant une faible corrélation entre la pluie (pluie journalier décennale) et l’amplitude de l’intervalle de confiance, bien que marquée de façon positive. Cette corrélation est plus significative pour les débits de pointe que les volumes de crues, ce qui reprend l’idée présentée plus haut que les débits de pointe sont plus sensibles à la pluie que les volumes de crues.
Figure 13 : Corrélation entre la valeur de la pluie journalière décennale et l’amplitude des incertitudes calculées sur les débits de pointes (en haut) et les débits journaliers (en bas), pour les périodes de retour de
VI. CONCLUSION
Le travail sur les incertitudes de la méthode SHYREG est particulièrement délicat du fait de l’utilisation de deux modèles : un générateur de pluie et un modèle hydrologique. La détermination des paramètres de ces deux modèles est alors entachée d’erreurs liées à l’échantillonnage des données mais aussi à toutes les erreurs liées à la métrologie, à l’équifinalité des paramètres (impactant le calage) ou le choix des critères de calage ...
La méthode est aussi une méthode régionalisée. L’étape de régionalisation ou d’interpolation des paramètres conduit aussi à des incertitudes sur les valeurs prises aux sites non-jaugés. L’ensemble de ces incertitudes doit être évalué au mieux, de façon « globale » (par opposition à « séparée ») mais la plus exhaustive possible.
On procède alors par ré-échantillonnage des données. Cette procédure permet de prendre en compte l’incertitude liée à l’échantillonnage des données sur les résultats de la méthode. L’intérêt de cette procédure par « bootstrap » est d’étudier dans un même temps, l’ensemble des incertitudes liées au calage et à la régionalisation de la méthode, en réappliquant systématiquement l’ensemble de la chaine de traitement de mise en œuvre de la méthode. On obtient alors une incertitude globale liée au calage des deux modèles et à leur régionalisation.
Les études réalisées en 2014 et en 2015 (étude actuelle), ont permis de montrer que la méthode SHYREG est finalement une méthode relativement précise malgré sa complexité. En effet, elle présente des intervalles de confiance raisonnables et inférieurs à ceux d’autres méthodes (comme l’utilisation d’une loi de probabilité à 3 paramètres par exemple).
On montre aussi que les intervalles de confiance sont variables et dépendent :
- de la durée de crue à laquelle on s’intéresse : les intervalles de confiance sont en moyenne plus grands pour les débits de courtes durées par rapport aux débits de longues durées.
- de la période de retour : les intervalles de confiance sont en moyenne un peu plus grands pour les périodes de retour élevées.
- de la localisation : les intervalles de confiance sont généralement plus grands sur les zones peu productives et sur les régions à plus forte pluviométrie. Cependant ces deux facteurs ne sont pas fortement explicatifs.
Le travail réalisé ici a permis de faire un état des lieux sur les incertitudes de la méthode SHYREG appliquée de façon régionalisée. Les paramètres les plus importants ont été étudiés, en particulier l’unique paramètre du modèle hydrologique sur lequel porte la régionalisation. Il reste cependant à étudier l’impact que peut avoir l’incertitude sur les paramètres fixés de façon unique sur le territoire d’étude, à savoir, certains paramètres du modèle hydrologique, les paramètres d’agglomération des quantiles sur les bassins (paramètres de la FTS) et l’estimation du débit de base.
Une étude complémentaire sera réalisée en 2016 pour prendre en compte ces autres sources d’incertitude et permettre de déterminer de façon plus exhaustive les intervalles de confiances des estimations de quantiles de crues fournis par la méthode SHYREG.
Ces estimations des intervalles de confiance pourront alors être intégrées à l’information fournie dans la base de données mise à disposition sur site web pour le MEDDE (http://shyreg.irstea.fr).
VII. REFERENCES BIBLIOGRAPHIQUES
Arnaud, P. (1997), Modèle de prédétermination de crues basé sur la simulation. Extension de sa zone de validité, paramétrisation du modèle horaire par l'information journalière et couplage des deux pas de temps. , in Thèse de l'Université Montpellier II. , edited, p. 258 p. + annexes.
Arnaud, P. (2005), Simplification de gr3h pour la prédétermination des crues. Application sur des petits bassins versants., in Note
interne., edited, p. 26 p.
Arnaud, P. (2010), Estimation de l’aléa « ruissellement » par la méthode SHYREG. Éléments de réflexions sur la difficulté d’estimation de l’aléa ruissellement., Rapport d'étude, 22 pages.
Arnaud, P. (2015), L'aléa hydrométéorologique : estimation régionale par simulation stochastique des processus - HDR, 137 pp, Aix-Marseille Université.
Arnaud, P., and J. Lavabre (1999a), Using a stochastic model for generating hourly hyetographs to study extreme rainfalls.,
Hydrological Sciences Journal, 44((3)), 433-446.
Arnaud, P., and J. Lavabre (1999b), Nouvelle approche de la prédétermination des pluies extrêmes., in Compte Rendu à l'Académie
des Sciences, Sciences de la Terre et des planètes, Géosciences de surface, hydrologie-hydrogéologie, edited by A. d. Sciences, pp.
615-620.
Arnaud, P., and J. Lavabre (2002), Coupled rainfall model and discharge model for flood frequency estimation., Water Resources
Research, 38(6).
Arnaud, P., and J. Lavabre (2010), Estimation de l'aléa pluvial en France métropolitaine, edited, p. 158 pages, QUAE, Paris. Update Sciences & Technologies.
Arnaud, P., J.-A. Fine, and J. Lavabre (2006a), An hourly rainfall generation model adapted to all types of climate., Atmospheric
Research, 85(2), 230-242.
Arnaud, P., P. Cantet, and Y. Aubert (2014), Relevance of an at-site flood frequency analysis method for extreme events based on stochastic simulation of hourly rainfall, Accepted Hydrological Sciences Journal., 20 pages.
Arnaud, P., J. Lavabre, B. Sol, and C. Desouches (2006b), Cartographie de l'aléa pluviographique de la France La houille blanche, 5, 102-111.
Arnaud, P., J. Lavabre, B. Sol, and C. Desouches (2008), Regionalization of an hourly rainfall generating model over metropolitan France for flood hazard estimation, Hydrological Sciences Journal, 53(1), 34-47.
Arnaud, P., Y. Eglin, B. Janet, and O. Payrastre (2013), Bases de données SHYREG-débit : méthode, performances et limites, Notice
utilisateurs - Publication Irstea, 35 pages.
Arnaud, P., J. Lavabre, C. Fouchier, S. Diss, and P. Javelle (2011), Sensitivity of hydrological models to uncertainties in rainfall input,
Hydrological Sciences Journal, 56(3), 397-410.
Aubert, Y. (2011), Estimation des valeurs extrêmes de débit par la méthode SHYREG : réflexions sur l'équifinalité dans la modélisation de la transformation pluie en débit. , Thèse doctorat Université Paris VI, 317 pages.
Aubert, Y. (2012a), Estimation des valeurs extrêmes de débit par la méthode Shyreg - Réflexions sur l’équifinalité dans la modélisation de la transformation pluie en débit 316 pp, Pierre et Marie Curie, Paris.
Aubert, Y. (2012b), Estimation des valeurs extrêmes de débit par la méthode SHYREG : réflexions sur l'équifinalité dans la modélisation de la transformation pluie en débit, thesis, 317 pp, Université Paris VI, Paris.
Aubert, Y., P. Arnaud, P. Ribstein, and J.-A. Fine (2013), La méthode SHYREG débit, application sur 1605 bassins versants en France Métropolitaine., Accepted Hydrological Sciences Journal.
Aubert, Y., P. Arnaud, P. Ribstein, and J.-A. Fine (2014), La méthode SHYREG débit - application sur 1605 bassins versants en France Métropolitaine, Hydrological Sciences Journal., 59(5), 993-1005.
Bourgin, F. (2014), Comment quantifier l’incertitude prédictive en modélisation hydrologique ? Travail exploratoire sur un grand échantillon de bassins versants., AgroParisTech thesis.
Carreau, J., L. Neppel, P. Arnaud, and P. Cantet (2013), Extreme rainfall analysis at ungauged sites in the South of France : comparison of three approaches, Journal de la Société Française de Statistique, 154(2), 119-138.
Cernesson, F. (1993), Modèle simple de prédétermination des crues de fréquences courante à rare sur petits bassins versants méditerranéens., in Thèse de doctorat de l'Université Montpellier II, edited, p. 240 p + annexes.
Coron, L. (2013), Les modèles hydrologiques conceptuels sont-ils robustes face à un climat en évolution ? Diagnostic sur un échantillon de bassins versants français et australiens., AgroParisTech thesis.
Folton, N., and J. Lavabre (2006), Regionalization of a monthly rainfall-runoff model for the southern half of France based on a sample of 880 gauged catchments, IAHS Publication Large Sample Basin Experiments for Hydrological Model Parameterization:
Results of the Model Parameter Experiment - MOPEX, vol. 4, 264-277.
Folton, N., and J. Lavabre (2007), Approche par modélisation pluie-débit pour la connaissance régionale de la ressource en eau: application à la moitié du territoire français, Houille-Blanche, n° 03-2007, 64-70.
Fouchier, C. (2010), Développement d’une méthodologie pour la connaissance régionale des crues, thesis, 231 pp, Université Montpellier II Sciences et techniques du Languedoc,, Montpellier.
Kochanek, K., B. Renard, P. Arnaud, Y. Aubert, M. Lang, T. Cipriani, and E. Sauquet (2013), A data-base comparison of flood frequency analysis methods used in France, Accepted Natural Hazards and Earth System Sciences, 20 pages.
Muller, A. (2006), Analyse du comportement asymptotique de la distribution des pluies extrêmes en France., thesis, 246 pp, Université Montpellier II - I3M, Montpellier.
Muller, A., P. Arnaud, M. Lang, and J. Lavabre (2009), Uncertainties of extreme rainfall quantiles estimated by a stochastic rainfall model and by a generalized Pareto distribution., Hydrological Sciences Journal, 54(3), 417-429.
Odry, J. (2015), Prédétermination des débits de crues extrêmes en sites non jaugés, amélioration de la méthode par simulation SHYREG : adaptation, regionalisation, incertitudes, Rapport de première année de thèse - ED251, 55 pages.
Organde, D., P. Arnaud, J.-A. Fine, C. Fouchier, N. Folton, and J. Lavabre (2013a), Régionalisation d'une méthode de prédétermination de crue sur l'ensemble du territoire français : la méthode SHYREG, Revue des Sciences de l’Eau, 26(1), 65-78. Organde, D., P. Arnaud, J. A. Fine, C. Fouchier, N. Folton, and J. Lavabre (2013b), Régionalisation d'une méthode de prédétermination de crue sur l'ensemble du territoire français : la méthode SHYREG, Revue des sciences de l'eau, 26(1), 65-78.
VIII. ANNEXE 1 : RAPPEL SUR LA METHODE SHYREG
Initialement, la méthode SHYPRE a été développée pour simuler des scénarios de crues sur un bassin versant donné [Patrick Arnaud and Lavabre, 2002]. Cette méthode associe un générateur stochastique de pluies horaires à une modélisation simple de la transformation pluie-débit [Patrick Arnaud, 1997;
Cernesson, 1993]. La méthode génère ainsi un très grand nombre d’hydrogrammes de crue, à partir
desquels on peut déduire les quantiles de débits maximums et moyens sur différentes durées, et ceci pour différentes périodes de retour. L'extrapolation vers les événements exceptionnels repose sur deux hypothèses :
1. le générateur de pluie est susceptible de fonctionner de manière satisfaisante sur l'ensemble de la plage de fréquence des pluies. Cette hypothèse a été vérifiée par les travaux ultérieurs qui montrent que les pluies exceptionnelles simulées par le générateur sont d'un ordre de grandeur pertinent et que l'ordre de grandeur des périodes de retour des événements exceptionnels observés peut être considéré comme correct[Patrick Arnaud and Lavabre, 1999a; b].
2. le paramétrage du modèle de transformation de la pluie en débit, effectué sur des événements courants, est applicable pour la modélisation des événements exceptionnels et rend bien compte de l'abattement des pluies sur le bassin versant. Des travaux récents ont permis d’apporter une réponse satisfaisante sur ce point [Aubert, 2011].
La méthode SHYREG a été développée à la suite de SHYPRE et repose sur les mêmes hypothèses, et elle a pour objectif la connaissance régionale des débits de crues extrêmes. Ceci a demandé :
1. La régionalisation du générateur de pluies horaires, sur la base de caractéristiques de pluies journalières. Ce travail a abouti à la cartographie des quantiles de pluies en France Métropolitaine [Patrick Arnaud et al., 2006b; Patrick Arnaud et al., 2008] et dans les DOM. Le travail en milieu tropical humide (La Réunion, Les Antilles) nous a permis de bien contrôler les performances du modèle pour des événements courants sous ces climats, mais exceptionnels en Métropole [Patrick
Arnaud et al., 2006a]. Avec la même structure, le générateur de pluie fonctionne à partir d’un jeu
de paramètres déterminé uniquement par des valeurs moyennes de caractéristiques liées à la pluie journalière.
2. La régionalisation du modèle hydrologique. On choisit de travailler à l’échelle du pixel de 1 km² pour pouvoir générer des quantiles de débits spécifiques qui seront ensuite agglomérés à l’échelle des bassins versants. Ce passage au pixel, imposé par la nature ponctuelle des pluies horaires modélisées, nous permet de simplifier le modèle hydrologique et de reporter toute la variabilité hydrologique des bassins versants sur un seul paramètre (noté ). Les problèmes d'abattement des pluies et de routage hydrologique sont négligés dans un premier temps car la modélisation s'effectue sur des pixels de 1 km², assimilés à des bassins versants virtuels. SHYREG génère donc des débits spécifiques géo-référencés obtenus par la pluviométrie locale et un paramètre hydrologique local.
3. L’agrégation de l’information sur les bassins. L’information pixellisée est utilisée pour estimer les quantiles de débits d'un bassin versant donné, par le biais d'une fonction d’abattement (Fonction de Transfert Statistique - FTS) qui prend en compte de façon globale, l’abattement des pluies et l’abattement hydraulique opérant sur des bassins de tailles différentes. La FTS est une fonction de
la superficie du bassin versant, qui est paramétrée de façon unique sur le territoire national, pour une durée de débit donnée.
La méthode SHYREG est donc une version régionalisée de la méthode SHYPRE. Elle s’appuie fortement sur la connaissance de la pluviométrie pour estimer les quantiles de crues courants à extrêmes. Cette pluviométrie (synthétisée dans la base SHYREG-pluie) est estimée régionalement suite au travail de cartographie des paramètres du générateur qui est détaillé dans un guide méthodologique [Patrick Arnaud, 2010].
Le travail présenté ici ne s’intéresse qu’aux incertitudes générées sur le calage de la partie hydrologique de la méthode SHYREG, c'est-à-dire sur le calage du seul paramètre . La procédure de calage de ce paramètre est présentée dans le paragraphe suivant.
Le calage de la méthode SHYREG-débit consiste à trouver une paramétrisation du modèle hydrologique qui permette de s’approcher au mieux de la distribution de fréquence des débits observés aux stations jaugées. Les étapes de calage sont décrites dans la Figure 14 10 7 1.
Figure 14 : Principe du calage de la méthode SHYREG Débit
La première étape consiste à générer des quantiles de débits de crue à la maille du pixel (1 km²). Pour cela, des événements indépendants de pluies horaires sont simulés à chaque maille, à partir des paramètres régionalisés du générateur de pluie. Ces événements de pluies sont transformés en événements de crues indépendants. Pour cela, on utilise un modèle hydrologique très simple, dont certains paramètres sont fixés, en partie en raison de son utilisation sur des mailles de 1 km².
Le modèle hydrologique est un modèle à réservoir du type GR (http://webgr.irstea.fr). Il est composé de deux réservoirs et d’un hydrogramme unitaire [Patrick Arnaud et al., 2011]. Il est utilisé en mode événementiel pour transformer les scénarios de pluies horaires en scénarios de crues. Les paramètres de ce modèle sont fixés, sauf le niveau de remplissage initial du premier réservoir. La capacité du premier réservoir ( ) a été imposée en fonction des grandes classes hydrogéologiques déterminées sur le territoire [Aubert, 2011; Aubert et al., 2013]. L’étude de 12 petits bassins versants de l’ordre de 1 km² a conduit à fixer la capacité du second réservoir ( ) à 50 mm au pas de temps horaire, et son niveau de remplissage (R) initial est imposé à 30% de la capacité de B [Patrick Arnaud, 2005]. Ce réservoir est un opérateur de transfert. Il est supposé unique pour modéliser le transfert se produisant sur des pixels de 1 km². Le taux de remplissage initial du réservoir A ( ) est donc le seul paramètre variable (entre 0 et 1). Il a un rôle de production.
Des simulations sont réalisées pour différentes valeurs de ce paramètre. Pour chaque valeur de , et à chaque pixel, des événements de crue sont simulés. Les quantiles de crue sont extraits de façon empirique de ces événements simulés. A l’ensemble des débits générés, on rajoute un débit de base (noté Q0) qui
correspond à l’estimation du débit spécifique mensuel moyen, fourni par une méthode régionale d’estimation de la ressource en eau (la méthode LOIEAU : [Folton and Lavabre, 2006; 2007]). Bien que cette valeur soit souvent négligeable face aux débits de crue simulés, il est important de la prendre en compte lors du calage de la méthode. En effet, elle permet de distinguer la partie « ruissellement » de la partie « écoulement de base », et éviter ainsi un biais dans le calage. La variabilité spatiale des débits, pour une même durée, une même période de retour et une même valeur de , est assurée principalement par la pluviométrie (variabilité des paramètres du générateur), mais aussi par la taille du réservoir A et à moindre échelle par le débit de base Q0. La notion de durée caractéristique du bassin versant a été, sinon éludée sur
cette modélisation au km², tout au moins considérée comme identique pour tous les pixels. Le paramétrage local ne porte donc que sur le rendement des pluies, à travers le calage du paramètre . Lors de son calage, ce paramètre doit alors compenser les hypothèses faites sur les autres paramètres qui ont été fixés. La méthode n’étant pas continue, on suppose que les événements pluvieux, générés de manière indépendante, se produisent toujours sur un système dont l’état initial est le même, et donné par le paramètre .
Les événements de crues ainsi générés, associés à une période de simulation, sont ensuite analysés empiriquement pour calculer des valeurs de quantiles de crue. Le nombre d’événements par an étant une des variables du modèle de pluie, on trouve une correspondance entre la fréquence empirique et la période de retour. Les quantiles de crues sont ensuite directement lus sur la distribution empirique pour des périodes de retour 100 fois plus faibles que la durée de simulation. Cela garantit une stabilité de la fréquence empirique. Pour obtenir des quantiles millénaux, on simule donc l’équivalent de 100 000 ans
0.00 0.10 0.20 0.30 0.40 0.50 0.60 0.70 0.80 0.90 1.00 1 10 100 1000 10000 f1(S) f2(S)
d’événements pluvieux et on retient la valeur de rang 100. Ce travail est effectué en chacun des 550 000 pixels recouvrant le territoire de la France métropolitaine.
Etape 2 : Agrégation et abattement
La seconde étape consiste à calculer pour les différentes valeurs du paramètre , les quantiles de débits de crues aux exutoires des bassins versants jaugés. Ainsi, pour chaque bassin versant et pour chaque valeur de , les débits moyens de durée (pour le débit de pointe, ) et de période de retour des pixels de un km² contenus dans le bassin, notés pour à , sont moyennés :
. Ces débits moyennés sont ensuite réduits par une fonction d’abattement qui dépend de
la surface du bassin (km²) et de la durée du débit moyen. Cette fonction permet de prendre en compte simultanément l’abattement des pluies avec la surface, mais aussi un abattement de nature hydraulique [Aubert, 2012b; Fouchier, 2010].
Elle s’exprime par le biais de deux équations dépendant de la durée sur laquelle le débit moyen est calculé :
avec
Les paramètres 1, 2, 1, 2, et ont été optimisés de façon unique sur un échantillon de 1291 bassins versants en France et sont considérés comme constants sur l’ensemble de la France métropolitaine2. On obtient alors pour chaque bassin versant les quantiles de débits de différentes durées : .
Le calage consiste à trouver la valeur du paramètre qui minimise les écarts la distribution empirique et la distribution fournie par la méthode. En pratique un écart relatif est calculé entre six quantiles issus des observations (débits de pointe et débits moyens journaliers de périodes de retour 2, 5 et 10 ans) et les six mêmes quantiles fournis par la méthode SHYREG. Les quantiles issus des observations sont obtenus par l’ajustement d’une loi de probabilité GEV dont le paramètre de forme a été borné (sa valeur doit être comprise entre 0 et 0,4). Le choix de cette loi a relativement peu d’importance tant que l’on reste dans le domaine des fréquences courantes (T<10 ans), nécessaire au calage de la méthode3. Ainsi, pour chaque bassin versant jaugé, la méthode peut-être calée en optimisant un seul paramètre. C’est sur ce paramètre que portera la régionalisation nécessaire pour pouvoir appliquer la méthode tout le long du réseau hydrographique (et donc en milieu non jaugé). C’est dans cette configuration que la méthode a été évaluée et comparée aux méthodes statistiques classiques.
2
Ces paramètres prennent respectivement les valeurs 0,01 / 0,25 / 0,24 / 10 / 5 et 0,9, avec de faibles variations lorsque l’on fait varier l’échantillon de calage lors de procédures de calage/validation.
3
Un poids est affecté aux différents quantiles dans le calcul du critère d’écart afin de limiter l’impact de l’échantillonnage sur le calage de la méthode. Les quantiles de période de retour 2 et 5 ans ont un poids de 2 et le quantile de période de retour 10 ans a un poids de 1.