TRAITEMENT DE L'INFORMATION VISUELLE POUR L'EXTRACTION D'INFORMATION À PARTIR DE DOCUMENTS VISUELLEMENT RICHES
THÈSE PRÉSENTÉE
corvnvIE EXIGENCE PARTIELLE
DU DOCTORAT EN INFORMATIQUE COGNITIVE
PAR
BENOIT POTVIN
Avertissement
La diffusion de cette thèse se fait dans le respect des droits de son auteur, qui a signé le formulaire Autorisation de reproduire et de diffvser un travail de recherche de cycles supérieurs (SDU;..522 - Rév.07-2011 ). Cette autorisation stipule que «Conformément à l'article 11 du Règlement no 8 des études de cycles supérieurs, [l'auteur] concède à l'Université du Québec à Montréal une licence non exclusive d'utilisation et de publication de la totalité ou d'une partie importante de [son] travail de recherche pour des fins pédagogiques et non commerciales. Plus précisément, [l'auteur] autorise l'Université du Québec à Mqntréal à reproduire, diffuser, prêter, distribuer ou vendre des copies de [son] travail de recherche à des fins non commerciales sur quelque support que ce soit, y compris l'Internet. Cette licence et cette autorisation n'entraînent pas une renonciation de [la] part [de l'auteur] à [ses] droits moraux ni à [ses] droits de propriété intellectuelle. Sauf entente contraire, [l'auteur] conserve la liberté de diffuser et de commercialiser ou non ce travail dont [il] possède un exemplaire.»
Je souhaiterais d'abord remercier le Prof. Roger Villemaire qui a été un directeur de thèse exceptionnel. Le Prof. Villemaire m'a guidé tout en me laissant une liberté de création qui à mon avis est essentielle au doctorat. Je me suis senti à la fois libre et encadré. Le Prof. Villemaire m'a écouté et s'est intéressé à mes idées, il s'est efforcé de les comprendre même lorsqu'elles n'étaient que des intuitions. À chacune de nos discussions, mes pensées évoluaient et mon doctorat progressait. Encore une fois, merci beaucoup ! Ces dernières années ont été passionnantes. Le Prof. Stevan Harnad, mon codirecteur de thèse, a joué un rôle important dans mes études. Le Prof. Harnad m'a appris l'importance de traduire en des termes simples les pensées les plus complexes. Il existe aussi des idées simples mais dif-ficiles à comprendre, du moins à prendre avec soi ( cum-prendere) comme être sensible. À cet égard, je remercie le Prof. Harnad de militer contre l'exploitation animale et pour la libre transmission de la connaissance. De tout mon parcours académique, le Prof. Harnad a été celui qui m'a donné le plus bel exemple d'au-thenticité et d'engagement.
Je n'aurais pas effectué mes études à l'UQAM sans l'aide du Prof. Pierre Poirier. Avant même mon inscription au doctorat, le Prof. Poirier m'a accueilli, il m'a pré-senté l'Université, ses départements et professeurs. Nous avons eu de nombreuses discussions sur mes intérêts de recherche. Surtout, il m'a motivé à poursuivre mes études. Je lui en suis très reconnaissant.
Pour leur influence, soutien et amitié, je voudrais remercier le Prof. Yvon Gauthier, le Prof. Serge Robert, mes collègues Louis Chartrand, Sarah Audrey Arnaud et 'làn Ngoc Le.
En dehors de ma vie académique, j'ai aussi la chance d'être entouré de personnes exceptionnelles.
Je remercie Guy, Sylvie et Catherine pour leur soutien inconditionnel.
Je remercie Gabrielle pour son amour conditionnel.
A
chaque jour, nous renou-velons notre volonté de partager notre quotidien. Je n'aurais pu imaginer un plus beau quotidien, une plus belle histoire d'amour. Je nous souhaite encore beaucoup de mensiversaires.Il y a aussi Léonard qui n'a pas encore été jeté dans le monde mais dont la présence se fait déjà sentir.
LISTE DES TABLEAUX LISTE DES FIGURES . RÉSUMÉ ... INTRODUCTION
CHAPITRE I REVUE DE LA LITTÉRATURE . 1.1 Méthodes pour l'extraction de données sur le Web .
ix xi xiii 1 7 7 1.1.1 Les systèmes basés sur la structure des documents HTML . . 8 1.1.2 Les systèmes basés sur des structures prédéfinies. . . 9 1.1.3 Les systèmes basés sur l'apprentissage inductif . . . 10 1.1.4 Les systèmes basés sur le traitement automatique du langage
naturel. . . 11 1.1.5 Les systèmes basés sur les ontologies . . . 13 1.1.6 Vue d'ensemble des cinq approches de systèmes d'extraction de
données pour le \Veb . . . 14 1.2 Les systèmes d'extraction basés sur l'information visuelle 15
1.2.1 Les systèmes d'extraction basés sur l'identification d'objets vi-s11els . . . 16 1.2.2 Les systèmes d'extraction basés exclusivement sur l'information
visuelle . . . · 17 1.2.3 Les systèmes d'extraction qui utilisent l'information visuelle
pour une tâche spécifique . . . 18 1.3 Travaux sur le traitement de l'information visuelle chez l'humain . . . 19
1.3.1 Couleur 1.3.2 Forme . 1.3.3 Position et taille 19 20 21
1.3.lJ, Culture . . . 21
1.4 Conclusion. . . 23
CHAPITRE II EXTRACTION DE DONNÉES FINANCIÈRES DANS DES DOCUMENTS PDF À PARTIR D'UNE MÉTHODE BASÉE SUR LA POSITION . . . 25 2.1 2.2 2.3 2.4 2.5 Résumé Abstract Introduction . Related \Vorks Method 2.5.1 Preprocessing 2.5.2 Bucketing . . 2.5.3 Clustering ... 2.5.4 Optional NER module 2.5.5 Structuring 28 29 30 31 35 37 38 39 43 44 2.6 Summary . . . 44 2. 7 Evaluation . . . 45 2.8 Conclusion . . . 47
CHAPITRE III VALIDATION VISUELLE NON SUPERVISÉE POUR L'EXTRACTION DU CONTENU PRINCIPAL DE PAGES WEB . . . . 49
3.1 Résumé . . . 52 3.2 Abstract . . . 53 3.3 Introduction . . . 54 3.4 Background . . . 57 3.5 Anomaly Detection . . . 58 3.6 Proposed Method . . . 59 3.6.1 Rationale . 3.6.2 Data normalization . 60 61
3.7 Evaluation . . . . 3.7.1 Performance . 3.7.2 Dataset ... 3.7.3 Experirnental Setup 3.7.4 Results 3.8 Related Works 3.9 Conclusion . . .
CHAPITRE IV VALIDATION VISUELLE NON SUPERVISÉE POUR L'EXTRACTION DE DONNÉES DANS DES DOCUMENTS
HÉTÉRO-61 62 63 64 65 68 71 GÈNES . . . 73 4.1 Résumé 4.2 Abstract 4.3 Introduction . 4.4 Related Work 4.5 Background
4.5.1 Web data extraction as a classification problem 4.5.2 Visual validation 4. 6 Methodology . . 4.6.1 Selection . 4.6.2 Visual Validation 4. 7 Experimental Setup . 4.7.1 Data.set . 4. 7.2 Selection . 4. 7.3 Visual Validation
4. 7.4 1.ools and Implementation 4.8 Experirnental Evaluation ..
4.8.1 Training Classifiers
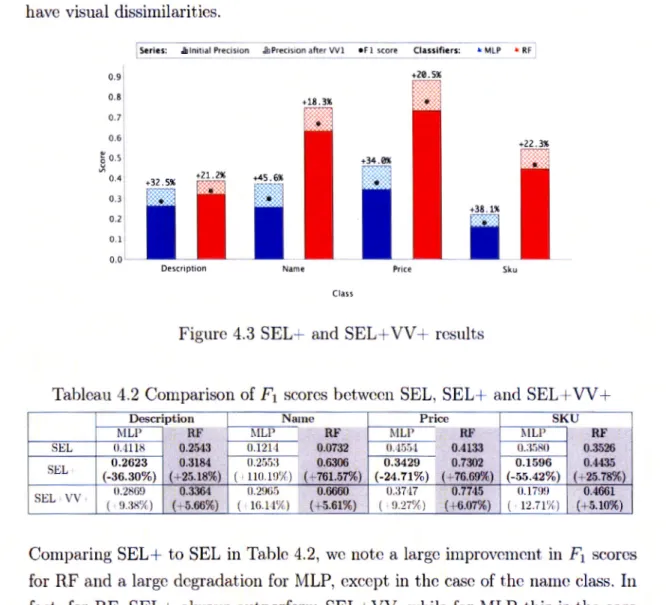
4.8.2 Cornparing SEL and SEL+VV
75 76 77 78 80 80 81 83 83 83 84 84 85 85 86 86 87 87
4.8.3 Comparing SEL+ and SEL+VV+ and classification to VV . . 88
4.9 Utilisation de la validation visuelle lors du processus d'extraction . . 90
4.9.1 Présentation des résultats . . . 91
4.10 Conclusion . . . 93 CHAPITRE V DISCUSSION . . . 95 5.1 Limitations . . . 95 5.1.1 Cadre d'application . 5.1.2 Temps d'exécution 5.1.3 Variabilité . 95
96
96
5.2 Directions futures . . . 975.2.1 Optimisation de la validation visuelle . . . 97
5.2.2 Processus d'élimination des entités visuellement aberrantes . . 98
CONCLUSION . . . 101
Tableau Pa.ge 3.1 F1 scores and related results for k-NN with different values of k and
HBOS. . . 67 3.2 Increase in percenta.ge compa.red to Boilerpipe ...
4.1 Comparison of F1 scores between SEL and SEL+ VV
67 88 4.2 Comparison of F1 scores between SEL, SEL+ and SEL+ VV + . . 89
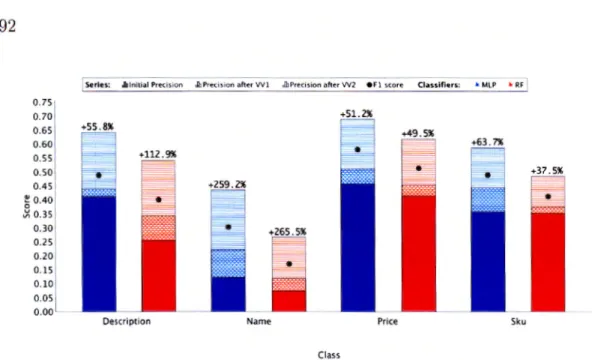
4.3 Comparaison des scores F1 entre SEL, 5SEL et 5SEL+ VV . . . . 92
Figure
1.1 Délimiteurs linéaires (a) et imbriqués (b) (Liu et Ôzsu, 2009). 1.2 Architecture usuelle d'un système d'extraction de l'information basé
sur le traitement automatique du langage naturel (T11rmo et al.,
Page 11
2006). . . 12
1.3 Architecture d'un système d'extraction basé sur une ontologie (Wi-malasuriya et Dou, 2010). . . 13
1.4 Cinq approches pour la génération des extracteurs selon leurs degrés d'automatisation et de robustesse (Laender et al., 2002b ). . . 15
1.5 Les huit variables visuelles proposées par Bertin (Bertin, 1983). 22 2.1 Flowchart of the proposed method for the extraction of financial data in PDF documents. . . 36
2.2 An cxample of a rectilincar search from a numerical value. . . 40
2.3 An example of satellite information from identified buckets. . . 41
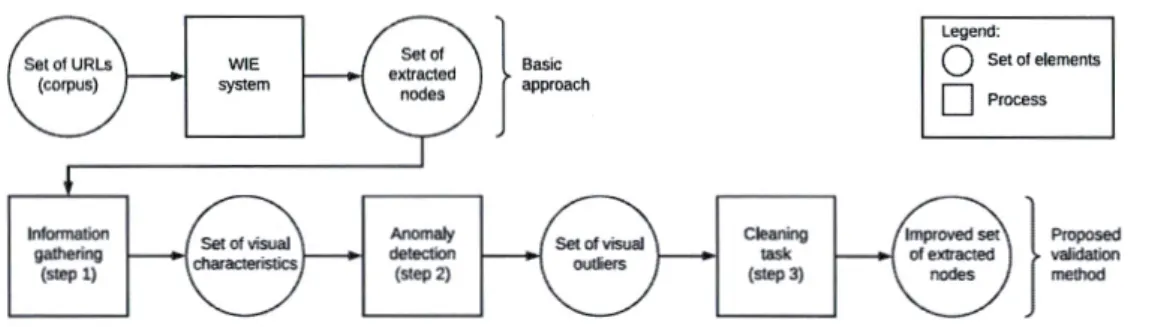
3.1 The successive steps of the proposed method . . . 60
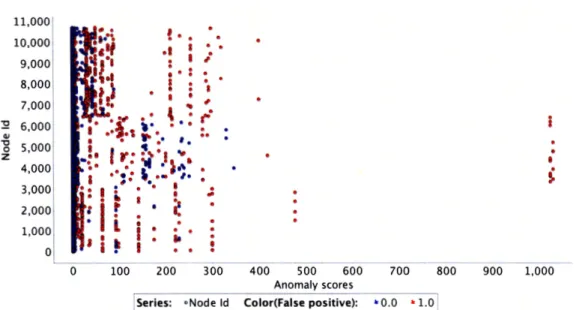
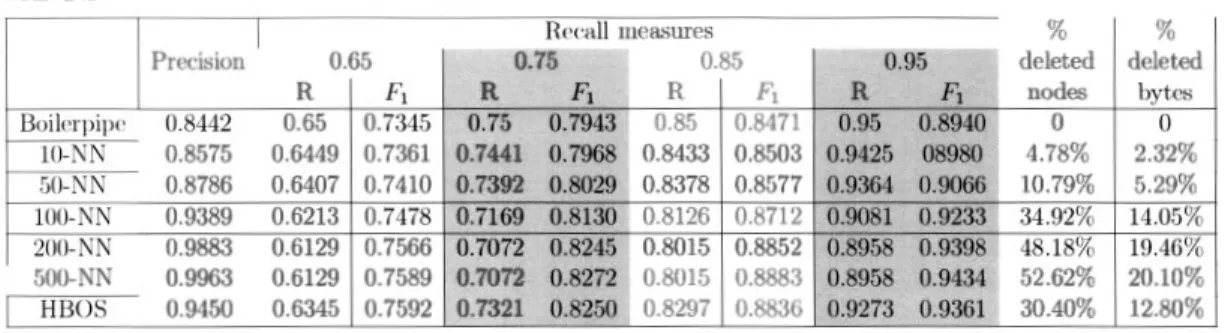
3.2 Boilerpipe's retrieved entities; k-NN anomaly scores for k = 200. . 66
3.3 Variation of
Fi
scores across node deletion for 200-NN, 500NN, and HBOS for recall values of 0.65 (left) and 0.95 (right). . . 68 4.1 The successive stcps of the proposed method . . . . .4.2 SEL (solid bars) and SEL+VV (crosshatched bars) results 4.3 SEL+ and SEL+ VV + rcsults . . . .
4.4 Résultats obtenus pour SEL, 5SEL et 5SEL+ VV
83 88 89 92
Cette thèse traite du problème d'extraire d'une manière automatique l'informa-tion de documents Visuellement Riches Destinés à une Consommation Humaine (VRDCH), tels que les pages Web et les documents PDF. Plus précisément, nous avons été motivé par la possibilité de faciliter le traitement de l'information vi-suelle lors de tâches d'extraction. En effet, bien que l'information vivi-suelle joue un rôle important dans la définition des documents VRDCH, les méthodes actuelles permettent un traitement limité de ce type cl 'information qui, à notre sens, ne rend pas compte de son importance réelle.
Nous avons pour hypothèse que, dans des documents VRDCH, les entités ho-mogènes partagent des caractéristiques visuelles similaires. Nous montrons qu'il est possible de faciliter le traitement de 1 'information visuelle en exploitant cette idée. Pour ce faire, nous présentons trois articles de conférence qui traitent chacun d'une tâche d'extraction particulière fondée sur l'hypothèse énoncée. Les résultats obtenus tendent à valider notre hypothèse.
Le premier article présente une méthode basée sur la position de l'information pour l'extraction de données financières dans des documents PDF. Nous montrons que, selon l'hypothèse susmentionnée, la position de l'information est un indicateur de relation sémantique. Ainsi, nous utilisons deux heuristiques concernant la proxi-mité et la densité de l'information de manière à faciliter le processus d'extraction. Nous évaluons notre méthode sur un corpus de documents financiers fournis par un partenaire industriel et montrons que les résultats d'extraction obtenus sont excellents et satisfont les besoins de l'industrie.
Le deuxième article introduit la validation visuelle non supervisée, une méthode de validation pour le traitement de l'information visuelle. La méthode propo-sée permet de distinguer, d'une manière non supervipropo-sée, les entités visuellement aberrantes des entités qui partagent des caractéristiques visuelles communes. Nous
montrons que dans le contexte de l'extraction d'information à partir de documents VRDCH, les entités visuellement aberrantes correspondent majoritairement à des faux positifs. Conséquemment, l'élimination de ces entités permet d'améliorer les résultats d'extraction. Nous évaluons notre méthode sur une tâche d'extraction du contenu principal de pages Web à partir d'un corpus de documents d'articles de nouvelles. Pour ce faire, nous utilisons Boilerpipe, un algorithme bien connu dans la littérature, et montrons que la validation visuelle permet d'en améliorer les résultats d'extraction.
Le troisième article évalue la performance de la validation visuelle non supervisée pour une tâche d'extraction de données effectuée sur un ensemble de documents visuellement hétérogènes. L'objectif est d'évaluer la robustesse de la méthode pro-posée, c'est-à-dire la possibilité d'améliorer les résultats d'extraction nonobstant les variations à travers l'information visuelle des différents documents. En effet, les méthodes d'extraction basées sur l'information visuelle ont généralement un im-pact négatif sur la robustesse des extracteurs puisqu'elles exploitent des régularités visuelles qui peuvent devenir incohérentes lorsque les documents sont modifiés ou lorsqu'elles sont appliquées à de nouveaux corpus. Ainsi, nous évaluons notre mé-thode sur la tâche d'extraire des informations de produits à partir d'un ensemble visuellement hétérogène de pages Web. Nous montrons que la validation visuelle non supervisée est une méthode robuste qui peut être utilisée pour l'extraction d'information sur de nouveaux documents.
Enfin, la validation visuelle non supervisée offre la possibilité d'exploiter l'informa-tion visuelle des documents à un degré qui n'avait pas été atteint jusqu'à présent. Notre méthode se distingue des méthodes d'extraction existantes quant à sa por-tée d'application, sa robustesse et sa facilité d'utilisation. Dans certains cas, le temps d'exécution nécessaire au traitement de l'information visuelle peut aussi être amélioré.
Mots clés. Validation visuelle non supervisée, extraction d'information sur le
Le vVeb est le témoin de nos expériences et le miroir - parfois déformé - de nos réalités. C'est le produit d'une activité principalement humaine qui génère une quantité astronomique d'information numérique. Le \Veb est humain trop hurnœin
puisqu'il a été créé par et pour l'humain, d'abord comme moyen de communica-tion, ensuite comme véritable extension de nos vies. L'information transite d'un cerveau à l'autre par l'intermédiaire d'un réseau de machines qui interprètent dif-ficilement le contenu destiné à une consommation humaine. Conséquemment, les visées du Web sont limitées par les capacités de nos systèmes à traiter cette in-formation selon nos besoins. Le projet d'un \:Veb sémantique «où les ordinateurs seront capables d'analyser toutes les données » (Berners-Lee et al., 2001) est une réponse proposée au problème du traitement algorithmique de l'information où les créateurs d'information numérique sont invités à structurer sémantiquement leurs contributions par le biais de standards technologiques (la Semantic Web Stack). Il y a vingt ans, Tim Berners-Lee écrivait :
The Web was designed as an information spacc, with the goal that it should be useful not only for human-human communication, but also that machines would be able to participate and help. One of the major obstacles to this has been the fact that most information on the vVeb is designed for human consumption, and even if it was derived from a database with well defined meanings (in at least some terms) for its columns, that the structure of the data is not evident to a robot browsing the web. (Berners-Lee
et
al., 1998)Les efforts de la communauté pour une sémantisation du \:Veb ont contribué de manière significative à l'évolution du \:Veb tel qu'on le connait aujourd'hui, notam-ment par la mise en place d'un vVeb de données (Bizer et al., 2011). De nombreux outils, comme le K nowledge Graph de Google qui affiche des données structurées suite à une recherche textuelle, utilisent des technologies du vVeb sémantique.
Parallèlement, un progrès technologique incroyable s'est opéré dans les dernières années, autant au niveau de la puissance de calcul des ordinateurs que des techno-logies de télécommunication. La plupart d'entre nous sommes connectés en tout temps à Internet et accédons à notre guise au \:Veb. À chaque jour, nous consultons et créons du contenu numérique. Cela est d'autant plus vrai avec l'avènement du Web social 2.0. Le vVeb est devenu une véritable plateforme de communication où l'information transite en temps réel d'un individu connecté à l'autre. Le \:Veb est aujourd'hui la plateforme privilégiée pour le partage d'information, que ce soit au niveau social, politique ou commercial.
À cet égard, les technologies du Web ont permis l'ajout de contenu visuel riche et attrayant pour les humains. Il y a une dizaine d'années seulement, les pages Web étaient élaguées de leurs propriétés visuelles de manière à faciliter leur accessibi-lité. Aujourd'hui, l'utilisation de contenu visuel est au contraire mise de l'avant. Les ordinateurs et appareils mobiles sont dotés d'une puissance de calcul éton-nante et peuvent facilement traiter l'information visuelle envoyée par les serveurs. Avec l'avènement des applications \Veb (Web app) - littéralement des applications logicielles émulées par les navigateurs Web - et la popularité grandissante du lan-gage .Javascript, quasi omniprésent dans la communauté - autant au niveau client ( e.g. AngnlarJS) que serveur ( e.g. NodeJs) - on assiste à une transformation du \Veb axée sur l'expérience utilisateur (UX) et le développement d'interfaces usa-gers (UI) riches et dynamiques. La dernière version du langage HTML (HTML5 qui a été finalisée en octobre 2014) va en ce sens en renforçant le lien entre la représentation visuelle du document et la sémantique du langage, notamment en offrant des alternatives aux éléments génériques (e.g. span ou div peuvent être remplacés par des balises comme header,
f
ooter, article, etc.) (Consortium et al., 2014).Évidemment, les entreprises prennent avantage de ces technologies pour la com-mercialisation de leurs produits et services. Dans une conférence TED intitulée
The next Web, Tim Berners-Lee énonce cette tendance et ajoute « Make a beau-tiful website but first give us the unaltered data » (Berners-Lee, 2009). Il va sans dire que le vVeb d'aujourd'hui est autant, voire peut-être plus, destiné à une consommation humaine qu'à ses balbutiements. Il est intéressant de noter que
---Berners-Lee distingue clairement le projet du \i\Teb sémantique des recherches en intelligence artificielle. Il écrit :
Leaving aside the artificial intelligence problem of training machines to behave like people, the Semantic Web approach instead develops languages for expressing information in a machine processable form. (Berners-Lee et al., 1998)
Le vVeb sémantique offre des mesures concrètes et une solution simple au pro-blème du traitement automatique de l'information destinée à une consommation humaine. Or, ce problème peut aussi être abordé du point de vue de l'intelligence artificielle. Les progrès technologiques énoncés précédemment et la numérisation des connaissances ont d'ailleurs contribué significativement à l'avancement des méthodes d'apprentissage automatique. Il n'est donc pas étonnant que plusieurs solutions provenant du domaine de l'intelligence artificielle aient été proposées pour l'extraction automatique de l'information à partir de documents non struc-turés. À titre d'exemple, Kushmerick proposa en 1997 - c'est-à-dire à peu près au même moment que BernersLee partageait sa vision du Web sémantique -une méthode pour l'extraction d'information sur le \:Veb basée sur l'apprentissage automatique (Kushmerick et al., 1997).
Le domaine de l'extraction d'information sur le \:Veb s'intéresse spécifiquement à l'extraction automatique d'information structurée à partir des documents \Veb. Les systèmes d'extraction pour le \:Veb diffèrent considérablement de ceux du do-mafae traditionnel de l'extraction d'information tel que défini à travers les _Message
Understanding Conferences (Grishman et Sundheim, 1996). Cette différence s'ar-ticule autant au niveau des méthodes utilisées que de leurs objectifs. Tandis que les méthodes traditionnelles visent l'extraction d'information hautement complexe et riche de sens sur des ensembles relativement petits de documents, les méthodes d'extraction pour le \Veb tendent à extraire des informations relativement simples en exploitant des régularités sur le plus grand nombre possible de documents, sans égard au domaine de connaissance (Yates, 2007). À cela s'ajoute la nature particulière des documents Web où l'information visuelle joue un rôle important pour la compréhension du lecteur.
En effet, le contenu visuel des documents Visuellement Riches Destinés à une Consommation Humaine (VRDCH) - tel que les documents Web et Portable
Do-cument Format (PDF) - contient un bagage sémantique pertinent qui précise le contexte de l'information et en bonifie le sens (Burget et Rudolfova, 2009). La sémantique des documents VRDCH est littéralement imbriquée dans leur repré-sentation visuelle et dépasse le cadre défini par le contenu textuel - ou la structure dans le cadre de pages Web. En effet, une page vVeb dépourvue de toute informa-tion visuelle serait difficilement compréhensible, voire impossible à naviguer. De la même manière que le contenu visuel aide les humains à comprendre un docu-ment VRDCH, celui-ci peut être utilisé pour améliorer l'extraction automatique d'information structurée.
Pourtant, l'utilisation de l'information visuelle pour l'extraction d'information est inhabituelle et le plus souvent ad hoc. Il existe certes de nombreuses méthodes d'extraction qui utilisent l'information visuelle mais celles-ci concernent typique-ment des tâches d'extraction précises ou des corpus de docutypique-ments limités. Dans le premier cas, l'information visuelle des documents est majoritairement ignorée de manière à utiliser seulement l'information pertinente pour exécuter une tâche précise, comme par exemple extraire des tableaux ou des entités fortement vi-suelles. Dans le deuxième cas, l'information visuelle des documents est exploitée d'une manière générale mais limitée à travers son application, c'est-à-dire que la tâche d'extraction est restreinte aux documents visuellement similaires d'un même domaine, d'une même source, etc. Ainsi, l'information visuelle est rarement ex-ploitée d'une manière générale sur un grand ensemble de documents, comme il est souhaitable pour l'extraction d'information sur le Web.
Cette thèse traite du problème d'extraire d'une manière automatique l'information de documents VRDCH, tels que les pages Web et les documents PDF. Plus préci-sément, nous nous intéressons aux méthodes d'extraction basées sur l'information visuelle et aux possibilités de faciliter le traitement de ce type d'information. Plusieurs inconvénients sont associés à l'utilisation de l'information visuelle pour l'extraction d'information. Parmi ceux-ci, l'impact négatif sur la robustesse de l'extracteur, c'est-à-dire le degré d'insensibilité de l'extracteur vis-à-vis les change-ments effectués dans la présentation du document, est peut-être le plus important.
La robustesse est étroitement liée à la maintenance et à l'évolutivité des extrac-teurs, deux éléments extrêmement importants pour l'extraction d'information sur le \Veb.
Nos objectifs à travers ce travail de recherche sont multiples. D'abord, nous cher-chons à expliquer pourquoi l'utilisation de l'information visuelle a généralement un impact négatif sur la robustesse des extracteurs. Ensuite, nous souhaitons ex-plorer les possibilités qui permettraient d'optimiser le traitement de l'information visuelle pour l'extraction d'information. Finalement, nous aimerions proposer une méthode générale qui faciliterait l'utilisation de l'information visuelle, tout en minimisant les inconvénients qui sont habituellement associés à ce traitement. Cette thèse s'appuie sur l'hypothèse selon laquelle, dans des documents VRDCH, des entités homogènes ont des caractéristiques visuelles similaires. Notre contribu-tion s'articule à travers trois articles scientifiques qui exploitent cette hypothèse. Le premier article (Section 2) présente une méthode pour l'extraction d'infor-mation financière à partir de documents PDF. Cet article introduit l'hypothèse susmentionnée et montre qu'il est possible de simplifier le processus d'extraction d'information à partir de tableaux, à savoir un objet visuellement discriminable. Nous proposons une méthode basée sur deux heuristiques simples pour extraire les données financières qui sont contenues, entre autres, dans des tableaux. La méthode proposée se distingue des méthodes usuelles pour l'extraction d'infor-mation à partir de tableaux ( Table Extraction) dans la mesure où le processus d'extraction ne repose pa..'3 sur la décomposition et la reconstruction des tableaux. Le deuxième article (Section 3) introduit une méthode de validation non super-visée pour le traitement de l'information visuelle. Cette méthode montre qu'il est possible de traiter l'information visuelle sans reposer sur un ensemble de régula-rités visuelles prédéfinies. Cet avantage substantiel permet d'utiliser l'information visuelle d'une manière générale, c'est-à-dire pour toute tâche d'extraction de l'in-formation, sans affecter négativement la robustesse de l'extracteur. Nous appli-quons notre méthode, appelée la validation visuelle non supervisée, à une tâche d'extraction du contenu principal (main content extraction). La validation visuelle non supervisée consiste à éliminer les entités visuellement aberrantes à travers
l'en-semble des entités extraites dans le but d'améliorer la précision de l'extraction. Notre méthode permet d'améliorer Boilerpipe - l'un des meilleurs algorithmes d'extraction du contenu principal - sur un corpus d'articles de nouvelles.
Le troisième article (Section 4) évalue la robustesse de la méthode proposée. En effet, bien que la validation visuelle non supervisée n'ait aucun impact négatif sur la robustesse de l'extracteur, il reste toutefois à démontrer que celle-ci peut être appliquée avantageusement sur un corpus de documents visuellement hétéro-gènes. Ainsi, nous souhaitons montrer que la validation visuelle non supervisée est une méthode robuste qui peut être utilisée pour l'extraction de nouveaux docu-ments ayant des représentations visuelles inconnues. Pour ce fa.ire, nous appliquons notre méthode à une tâche d'extraction de données à partir d'un ensemble de do-cuments visuellement hétérogènes et montrons que celle-ci permet d'en améliorer les résultats d'extraction. La tâche d'extraction sélectionnée vise l'extraction d'in-formation de produits (prod,uct ind'in-formation extraction).
En plus de ces trois articles, nous présentons une revue de la littérature (Section 1) sur les principaux travaux du domaine de P extraction de données sur le Web, ainsi que sur les méthodes d'extraction basées sur l'information visuelle. Nous présentons aussi quelques travaux sur l'importance de l'information visuelle chez l'humain. Finalement, nous discutons de notre contribution, de ses limitations et des directions de recherches futures (Section 5).
REVUE DE LA LITTÉRATURE
Dans cc chapitre, nous présentons les travaux d'importance qui concernent l'ex-traction de données sur le Web (Section 1.1), l'exl'ex-traction d'information basée sur l'information visuelle (Section 1.2) et le traitement de l'information visuelle chez l'humain (Section 1.3).
1.1 Méthodes pour l'extraction de données sur le \:Vcb
Un système d'extraction pour le Web est « un logiciel qui extrait de manière automatique et répétée les données hétérogènes du \Veb et qui rend disponible celles-ci pour le stockage ou la réutilisation » (Baumgartner et al., 2009) 1 .
Dans le contexte du \:Veb, un extracteur (Chang et al., 2006) : 1. Effectue une requête HTTP à un serveur.
2. Extrait les données à partir des documents HTML reçus. 3. Intègre celles-ci à une source de données.
Nous recensons plusieurs travaux présentant différents types de classification pour les systèmes d'extraction du Web (Laender et al., 2002b; Chang et al., 2006; Ferrara et al., 2014). Ainsi, les extracteurs peuvent être différenciés selon plusieurs
1. Traduction libre de « [ ... ) software extmcting, autornatically and repeatedly, data /rom Web pages with changing conten:ts1 and that delivers extracted data to a database or some other
caractéristiques, à savoir leur domaine d'application, le degré d'automatisation, le type de méthode utilisé ou toute autre distinction pertinente. Dans cette section, nous utilisons une classification qui s'articule autour de la méthode utilisée pour générer l'extracteur (Laender et al., 2002b). En pratique, ces méthodes sont combinées de manière à créer des systèmes d'extraction multisources.
Nous distinguons cinq grandes familles d'extracteurs de données pour le \Veb (Laender et al., 2002b). Ces méthodes :
1. exploitent les régularités à travers les balises HTML des documents Web
(HTML-aware extractors).
2. reposent sur des structures prédéfinies à travers la représentation des do-cuments ( lv! odeling-based extractors).
3. induisent des règles d'extraction à partir d'un corpus d'apprentissage ( Wrap-per ind'uction).
4. appliquent des techniques propres au traitement automatique du langage naturel (NLP-based extractors ).
5. s'articulent autour d'ontologies ( Ontology-based extractors ).
Nous présentons les principaux travaux associés à chacune de ces familles d'ex-tracteurs.
1.1.1 Les systèmes basés sur la structure des documents HTML
Les systèmes basés sur la structure des documents HTML, tels que Lixto ( Gottlob
et al., 2004), RoadRunner (Crescenzi et al., 2001), XWRAP (Liu et al., 2000) et Xtractorz (Gultom et al., 2010), utilisent les balises HTML pour extraire de manière automatisée et répétitive les informations du \Veb. Des règles sont appli-quées sur l'arborescence du document HTML de manière à identifier des régula-rités discriminantes. Plusieurs logiciels commerciaux ( e.g. Import.io, Kimonolabs ou Lixto) utilisent cette approche puisqu'elle facilite la mise en place d'une in-terface graphique où l'utilisateur est invité à sélectionner les données recherchées.
A
partir de cette sélection, le système génère un ensemble de règles cohérentesvisant l'extraction d'éléments similaires.
Lixto (Baumgartner et al., 2001a; Gottlob et al., 2004) est un système d'extrac-tion basé sur la structure HTML des documents. Il s'agit d\m outil semi-supervisé qui nécessite une participation de l'utilisateur pour identifier les données perti-nentes sur une page vVeb à l'aide d'une interface graphique. Suite à la sélection des données, un ensemble de règles d'extraction est défini sous la forme d'un programme déclaratif. Ces déclarations sont générées dans le langage de program-mation ELOG (semblable à Datalog). Le code HTML ou XML d'un document est ensuite analysé syntaxiquement et les règles déclaratives sont appliquées de manière à extraire l'information recherchée. Finalement, un fichier XML et un fichier Document Type Definition (DTD) sont générés.
1.1.2 Les systèmes basés sur des structures prédéfinies
Certains systèmes, comme NoDoSE (Adelberg, 1998) et DEByE (Data E:r;traction
By E:r;ample) (Laender et al., 2002a), reposent sur des structures prédéfinies dans la représentation des documents. Ces structures sont identifiées à travers une interface graphique selon les besoins d'extraction définis par l'utilisateur. Les documents sont ensuite comparés et l'information retrouvée à travers les structures identifiées est extraite.
NoDoSE et DEByE procèdent environ de la même manière. l'utilisateur décom-pose à l'aide d'une interface graphique quelques documents de manière à générer une structure sémantique d'information imbriquée (nested tables). Ensuite, cette structure est validée à travers d'autres documents similaires et peut être modifiée au besoin, toujours à l'aide de l'interface graphique. La principale différence entre NoDoSE et DEByE est que NoDoSE demande à l'utilisateur de décomposer le document dans son entièreté, tandis que DEByE permet de structurer des par-ties de documents. Cette dernière approche rend l'extraction plus robuste dans la mesure où différents documents pourraient partager des parties semblables.
1.1.3 Les systèmes basés sur l'apprentissage inductif
Les systèmes inductifs tels que \Vien (Kushmerick et al., 1998), Stalker (Mus-lea et al., 1998) et SoftMealy (Hsu et Dung, 1998) permettent de générer des règles d'extraction à partir d'un corpus d'apprentissage annoté. Kushmerick fut le premier à introduire ce type de système (Kushmerick et al., 1997). Les sys-tèmes inductifs reposent sur des méthodes d'apprentissage supervisé où des règles d'extraction sont générées à partir d'un corpus de documents annotés.
Le problème de créer des extracteurs par induction est défini comme un problème de satisfaction de contraintes où toutes les combinaisons de délimiteurs doivent être satisfaites (Kushmerick et al., 1997). Un délimiteur est un mot ou une balise
tokenisé. L'utilisateur annote d'abord les entités recherchées dans un ensemble
de documents. Ensuite, différentes combinaisons de délimiteurs sont recherchées à l'aide d'un algorithme de couverture séquentielle de manière à identifier toutes les informations annotées et aucune information non pertinente (M uslea et al., 1998).
Il existe plusieurs classes d'induction permettant de générer des extracteurs in-ductifs. Par exemple, la classe inductive LR (Left-Right) prend deux délimiteurs qui définissent respectivement la tête et la queue de l'entitée annotée. Ainsi, LR
définit par L1
=
<b> et R1=
<em> s'appliquera à toutes les combinaisonsoù la balise <em> sera précédée de la balise <b>. À cet égard, les patrons de contraintes peuvent être comparés à des expressions régulières. On peut alors défi-nir d'autres classes d'induction telles que H LRT (Head-Left-Right-Tail) où H est un délimiteur supérieur (i.e. haut de la page) et Test un délimiteur inférieur (i.e. bas de la page), OCLR ( Open-Clo8e-Left-Right) où 0 définit le début de la zone
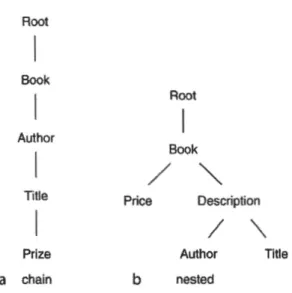
de recherche et C correspond à la fin de la zone de recherche, et HOCLRT, une combinaison des deux classes précédentes. Ces classes définissent des agencements linéaires ( chain) mais il est aussi possible de définir des classes N ( nested) où les éléments sont imbriqués les uns dans les autres, tels que N-LR et N-H LRT
(Figure 1.1).
11 Root Book Root Author Book
/
""
Tit!e Price Description
/
.'\
Prize Author Title
a chain b nested
Figure 1.1 Délimiteurs linéaires (a) et imbriqués (b) (Liu et Ôzsu, 2009). ceux-ci permettent difficilement l'extraction d'information à partir de documents inconnus (Lockard et al., 2018).
1.1.4 Les systèmes basés sur le traitement automatique du langage naturel Les systèmes basés sur le traitement automatique du langage naturel, tels que RAPIER (lviooney, 1999), SRV (Freitag, 1998) et \VHISK (Soderland, 1999), sont utilisés afin de résoudre des problèmes d'extraction qui nécessitent une analyse textuelle de l'information. À titre d'exemples, ces méthodes peuvent être utilisées pour l'extraction d'articles de journalLX, de commentaires sur les réseaux sociaux, de courriels électroniques ou toute autre tâche nécessitant une analyse approfon-die du contenu textuel. Ces systèmes sont plus près de l'approche traditionnelle de l'extraction d'information et sont construits selon des architectures usuelles propres aux systèmes d'extraction de l'information (Figure 1.2).
Ces systèmes se distinguent notamment par leur capacité à traiter les contraintes linguistiques du contenu textuel mais aussi par leurs difficultés à considérer les éléments structuraux inhérents aux documents HTML (Turmo et al., 2006). Plusieurs systèmes utilisant des techniques de traitement automatique du langage
~
!LexicalftWysis1Figure 1.2 Architecture usuelle d'un système d'extraction de l'information basé sur le traitement automatique du langage naturel (Turmo et al., 2006).
naturel, tels que Know ItAll (Etzioni et al., 2004), TextRunner (Yates et al., 2007), ReVerb (Etzioni et al., 2011) et R2A2 (Fader et al., 2011), se sont d is-tingués par leur capacité àtraiter un grand nombre d'information, littéralement des millions de documents Web. TextRunner, ReVerb et R2A2 sont des systèmes d'extraction ouverts (Open Information Extraction), c'est-à-dire des systèmes qui construisent des relations sous laforme de tripletsàpartir du textebrut. Ces sys -tèmesne reposentsur aucun schémade relationset permettent d'extraire un grand nombre de tripletsàpartir de patrons généraux d'extraction (domain-independant extraction patterns).
Bien que les systèmes d'extraction ouverts soient utiles pour la création d' im-portantes banques de connaissance, ils s'appliquent davantage au domaine de la recherche d'information (Information retrieval) -àsavoir la recherche de docu-ments pertinents -qu'àcelui de l'extractiond'information structurée pour leWeb. En effet, les systèmes d'extraction ouverts minimisent la portée de ~ sé -mantique afin de maximiser le nombre de documents traités. De récents travaux (Vo et Bagheri, 2016) montrent qu'il est possible d'alimenter des ontologies par le
biais d'un alignement entre lestripletstrouvés par un système d'extraction ouvert et les concepts et relations définis dans une ontologie.
1.1.5 Les systèmes basés sur les ontologies
Les systèmes d'extraction de données pour le Web basés sur des ontologies, tels que BYU (Dinget al.,2006), Textpresso (Mülleret al.,2004) ou le système présenté par Konys (Konys, 2015), sont les plus robustes mais aussi ceux qui nécessitent le plus d'efforts de développement (Figure 1.4). Ces systèmes utilisent une ou plusieurs ontologies pour créer des objets sémantiques à partir des données analysées.Àcet égard, ils ne dépendent pas de la structure ou de la nature des documents. Les extracteurs générés sont robustes, en ce sens qu'ils s'adaptent à des sources d'information distinctes d'un même domaine et ne sont pas affectés par les variations à travers lareprésentation des documents.
User Human {domainexpert)
OS!Esystem
:
...- ---- -- ~ ___.....
.-
..... -
__...__,. _________-
---
--
--., 1 1 : 1 1 1 : 1 1 1 : 1 : :,.---... Textinput 1 : 1!
:1 :!
1!
: : 1 1 1!
1 1 1-
·-·
-···---
-
-
·
-
·
·---· .. ·
----.J
Other inputsFigure 1.3 Architecture d'un système d'extraction ba..i;;;é sur une ontologie (W ima-lasuriya et Dou, 2010).
Ces avantages n'appartiennent qu'à cette catégorie de systèmes. Les systèmes d'extraction basés sur lesontologies ne sont toutefoispas adaptés aux domaines où ilest difficile de créer une ontologie,par exemple dans le cas d'ontologies générales, commeOpen Gye Ontology(Matuszeket al.,2006) dont l'univers du discours et
la granularité de l'analyse correspondent aux limites définies par la connaissance humaine, ou des ontologies d'application où il n'y a pas de concensus au niveau de la conceptualisation.
Les systèmes d'extraction basés sur les ontologies offrent des avantages uniques par rapport aux autres systèmes d'extraction mais nécessitent aussi des efforts de conception incomparables afin de développer des ontologies satisfaisantes. Il est intéressant de noter que de tels systèmes sont à la croisée du domaine de l'information d'extraction et de celui du Web sémantique.
1.1.6 Vue d'ensemble des cinq approches de systèmes d'èxtraction de données pour le Web
Toutes les approches présentées exploitent des régularités à travers l'information afin d'extraire les entités recherchées. Conséquemment, la performance de ces systèmes dépend de la présence des régularités identifiées à travers les documents analysés. Certaines régularités sont reconnues pour être très robustes comme, par exemple, les régularités textuelles, tandis que d'autres le sont difficilement, à savoir les régularités basées sur le Document Object Model (DOIVI) (Figure 1.4). Le DOM est une recommandation du \V3C visa.nt à offrir une interface standardisée pour permettre à des programmes et des scripts d'accéder ou modifier le contenu, la structure et le style des documents (Wood et al., 2000). Ainsi, lorsque le navigateur Web interprète le document HTML reçu par le serveur, celui-ci crée un arbre du DOM permettant d'une part, d'afficher l'information à l'utilisateur et, d'autre part, d'exécuter les scripts visant à modifier sa représentation.
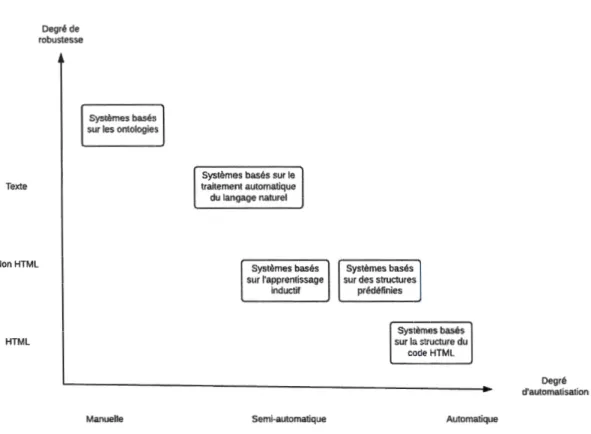
De manière générale, le degré d'automatisation est inversement proportionnel au degré de robustesse (Laender et al., 2002b). Ainsi, plus une approche sera robuste et plus elle aura été façonnée par un travail manuel, qu'il s'agisse d'annoter un corpus ou de développer une ontologie. Il est aussi possible de rendre un système d'extraction plus performant au dépend de sa robustesse (Parameswaran et al.,
2011). En effet, des régularités très précises (i.e. peu flexibles) peuvent être dé-finies de manière à augmenter les performances sur un ensemble de documents similaires. Ce compromis s'effectue généralement lorsque des régularités à travers
Texte Non HTML HTML Degré de robustesse Systèmes basés sur les ontologies
Manuelle
Systèmes basés sur le traitement automatique du langage naturel Systèmes basés sur l'apprentissage inductif Semi-automatique Systèmes basés sur des structures
prédéfinies Systèmes basés sur la structure du code HTML Automatique Degré d'automatisation
Figure 1.4 Cinq approches pour la génération des extracteurs selon leurs degrés d'automatisation et de robustesse (Laender et al., 2002b).
l'information visuelle sont exploitées.
Dans les prochains paragraphes, nous présentons plusieurs systèmes d'extraction basés sur 1 'information visuelle.
1.2 Les systèmes d'extraction basés sur l'information visuelle
Les systèmes d'extraction de l'information ont évolué historiquement à travers les conférences du Message Understanding Conferences (MUC) (Grishman et Sund-hcim, 1996; Kaufman, 1998) où un corpus au format brut ASCII permettait à la communauté scientifique de comparer leurs solutions pour des tâches définies comme, par exemple, l'identification d'entités nommées ou la résolution de coré-fércnce. À cet égard, toute propriété visuelle était élaguée du corpus d'évaluation, ne laissant place qu'à l'information textuelle.
Plus récemment, plusieurs approches ont été proposées afin de traiter l' informa-tion visuelle lors de tâches d'extraction. Les documents VRDCH sont devenus omniprésents, en grande partie àcause de l'évolution du Web, et l'information visuelle peut difficilement être ignorée lors de tâ.ches d'extraction.
Dans les prochains paragraphes, nous présentons des travaux d'importance pour l'extraction d'information où l'information visuelle est analysée. Notons que cer-tainsauteurs utilisent lestermes Vùntal Web Inforrnation Extractionpour désigner l'utilisationd'un interface graphique (Baumgartner et al.,2001b), nonobstant le fait que l'informationvisuelle des documents ne soit pas utilisée lorsdu processus d'extraction.
1.2.1 Les systèmes d'extraction basés sur l'identificationd'objets visuels L'approche appelée Visual Inforrnation Extraction(VIE) apporte un cadre théo-rique et pratique àlaspatialisation des objets visuels contenus dans un document (Della Penna et Orefice, 2016). VIE repose sur une théorie des relations spatiales où les objets sont identifiés selon leurs positions et leurs connexions réciproques. En pratique, VIE permet aux utilisateurs d'extraire des objets graphiques à par-tirde requêtes formelles énoncées dans le langage Spatial relation query(SRQ), similaires àdes requêtes SQL. Les relations sont divisées en deux familles, àsavoir les relations basées sur laposition et celles basées sur les connexions réciproques. Les relations de position (position-based relations)permettent de définir des pro-priétés spatiales telles que
«
Haut>>, << Bas», «
Gauche»
et«
Droite».Ellespermettent aussi de définir des propriétés de chevauchement comme«Inclus»et «Intersecter», ou une propriété d'attachement comme «Toucher». Les relations de ~ réciproques (connection-based relations)offrent lapossibilité de
dé-finir des liensd'interconnectivité entre les objets de manière àidentifier différents agencements spatiaux qui peuvent être propres àdes objets visuels complexes comme, par exemple, des graphes, des objets emboités
(puzz
le
)
ou des diagrammes. VIE pose les bases théoriques nécessaires àune formalisation des représentations visuelles qui s'accompagne, en pratique, d'un outil de requêtes permettant l'ex-17
traction d'objets graphiques dans des documents Web et PDF. Il s'agit d'une proposition à adopter un langage graphique pour l'identification de contenu vi-suel et surtout, d'une belle démonstration de l'importance jouée par l'information visuelle dans les documents V RD CH.
1.2.2 Les systèmes d'extraction basés exclusivement sur l'information visuelle
Aumann et alii. (Aumann et al., 2006) proposent un système d'extraction de l'information basé exclusivement sur l'aspect visuel des documents, sans aucune considération du contenu textuel ou structurel. L'algorithme vise à structurer le document en objets visuels. Ces objets sont identifiés en fonction de la proximité physique de l'information et des similarités au niveau des caractéristiques de style comme la famille de la police, la taille des caractères, etc. À partir des objets visuels identifiés, un Object-Tree ( 0-Arbre) est construit de manière à organiser hiérarchiquement les objets entre eux, où les éléments de haut-niveau (tels que des paragraphes) regroupent des éléments de bas-niveau (telles que des lignes dans un paragraphe). Ainsi, on obtient une structure arborescente basée uniquement sur l'aspect visuel du document. Des règles d'extraction sont ensuite générées à partir d'un corpus annoté, selon la structure définie par les objets visuels. Ces auteurs proposent, dans le but d'améliorer les résultats d'extraction, de définir des gabarits d'extraction ( template) et de comparer la similarité visuelle des documents avec ces gabarits.
La méthode PDF Extraction System (PES) (Rosenfold et al., 2002) utilise l'infor-mation visuelle d'une manière similaire à la précédente. PES identifie des objets visuels à travers un regroupement d'objets perccptuels (percepfoal gro11,ping) et
organise hiérarchiquement ces objets par le biais d'un H-Graph, i.e. une forme moins restrictive de 0-Tree. Ces deux systèmes visent l'extraction d'information à partir de documents PDF.
1.2.3 Les systèmes d'extraction qui i1tilisent l'information visuelle pour une tâche spécifique
Certains systèmes d'extraction utilisent l'information visuelle des documents dans le but d'exécuter des tâches spécifiques où ce type d'information joue un rôle important.
Plusieurs systèmes destinés à extraire le contenu de tableaux reposent sur un traitement des caractéristiques visuelles (Chu et al., 2015; Tanaka et Ishida, 2006; Yildiz et al., 2005; Silva et al., 2003). Bien que les tableaux puissent être identifiés à partir des balises HTML <table>, il en va autrement lorsque ceux-ci se retrouvent dans un document PDF ou sous la forme d'un texte brut. L'identifica-tion et la décomposiL'identifica-tion des tableaux (table extracL'identifica-tion) est une tâche bien connue dans le domaine de l'extraction d'information et réputée comme étant difficile. Les systèmes destinés à extraire les tableaux utilisent des ensembles de règles per-mettant d'identifier les colonnes et les rangées en fonction de l'espacement entre les valeurs (Chu et al., 2015; Yildiz et al., 2005; Silva et al., 2003). La densité de l'information est couramment utilisée, ainsi que d'autres heuristiques basées sur la représentation visuelle de ce,s objets.
Vision-Based Page Segrnentation (VIPS) (Cai et al., 2003) est un autre exemple de méthode qui utilise l'information visuelle pour exécuter une tâche spécifique, à savoir une seg1nentation visuelle. VIPS permet de décomposer une page \Veb en segments visuels à partir de l'arborescence du DOM. L'objectif de VIPS est de restructurer le DOM de manière à obtenir une segmentation des objets vi-suels identique à celle qui serait effectuée par un humain. Les auteurs définissent les composantes visuelles selon un ensemble de signaux ( wes) correspondant à une interprétation sémantique des balises HTML. Par exemple, les balises ayant un impact sur la représentation visuelle, comme <hr> ou <br>, permettront de restructurer le DOM selon l'aspect visuel du document ( tag c1œs ). Les autres si-gnaux concernent la couleur des arrière-plans ( eolor eues), l'imbrication de noeuds de texte ( text eues) et la taille des caractères ( size eue). L'algorithme VIPS pro-cède à partir du noeud racine du DOM de manière à traverser l'arbre et analyser syntaxiquement chacun des noeuds selon un ensemble de règles associées aux types
de noeud. Les segments visuels se définissent au fur etàmesure que l'arbre est traité.
Les résultats obtenus par VIPS pour latâchede segmenter visuellement 140 pages Web ont été validés par des utilisateurs humains qui devaient se prononcer sur les structures visuelles proposées, àsavoir si celles-ci étaient parfaites, satisfaisantes ou mauvaises.Àcet égard, 61%des segmentations visuelles identifiées par VIPS ont été jugées parfaites et 36% comme étant satisfaisantes.
VIPS présente certaines similitudes avec l'approcheprésentée dans cette thèse. En effet, VIPS suppose, comme lavalidation visuelle non supervisée (Chapitre 3), que le sens des éléments d'une page \Veb est liée àsa représentation visuelle. Ainsi, en segmentant l'information en blocs, VIPS rassemble des éléments visuellement et sémantiquement similaires, ce qui s'accorde avec notre hypothèse selon laquelle des entités homogènes ont des caractéristiques visuelles similaires.
1.3 Travaux sur le traitement de l'information visuelle chez l'humain
Cette section présente des travauxqui témoignentde l'importancede l'information visuelle chez l'humain.
Le système visuel de l'homme est extraordinaire par la quantité et la qualité des informationsqu'il lui fournit sur le monde. Un rapide coup d'oeil suffit pour connaître la position, la taille, la forme, la couleur [...). (Augustineet al.,2015)
Nous aborderons donc chacune de ces caractéristiques (couleur, forme, position et taille), en plus de présenter des travauxqui montrent l'influence de laculture sur la représentation visuelle de l'information dans des documents VRDCH.
1.3.1 Couleur
Les couleurs affectent nos émotions et notre cognition. Bien qu'on explique diffici -lement les mécanismes physiques associés aux stimuli de couleurs, ceux-ci existent
~
Jacobs et Hustmyer (Jacobs et Hustmyer Jr, 1974) ont enregistré des différences quant à la résistance électrique de la peau (la conductance cutanée) relativement à des stimuli de couleurs. Ils ont déduit que le bleu est une couleur plus relaxante que le rouge et le jaune. Soldat et alii. (Soldat et al., 1997) ont montré que la couleur des questionnaires d'un examen universitaire peut faire varier les notes des étudiants. Becker (Becker, 2002), pour sa part, a démontré que les couleurs influencent les habitudes des consommateurs.
Bonnardel et alii. (Bonnardel et al., 2011) démontrèrent que les couleurs in-fluencent la navigation des utilisateurs à travers une page vVeb. Certaines cou-leurs sont plus attrayantes pour l'utilisateur et font en sorte que celui-ci passe plus de temps à naviguer sur un même site Web. Les couleurs ont aussi un impact sur la mémorisation de l'utilisateur. Par exemple, la couleur orange favorise la mémorisation de l'information.
1.3.2 Forme
Le gestaltisme, aussi appelé la psychologie de la forme (Koffka, 2013), stipule que les processus de la perception et de la représentation ne résultent pas d'une simple juxtaposition des éléments visuels, mais bien de manière spontanée, comme un ensemble structuré de formes. Dès lors, le terme gestalt réfère au regroupement des formes et à notre capacité visuelle à percevoir des patrons formels. Selon le gestaltisme, la vision serait totale, où le tout est différent de la somme de ses parties.
Les principes d'organisation de l'information dans la psychologie de la forme re-posent sur une liste de lois (Todorovic, 2008) :
1. La loi de la bonne forme stipule qu'un ensemble de parties informes tend à être perçue comme une bonne forme, c'est-à-dire une forme simple et symétrique.
2. La loi de la continuité soutient qu'un ensemble de points discontinus sera d'abord perçu comme une forme continue.
les plus proches et à les considérer comme faisant parti d'un même en-semble.
4. La loi de similitude veut que si la distance entre un ensemble de points ne permet pas de regrouper ceux-ci pour percevoir une forme, nous allons repérer les points similaires de manière à les rattacher.
5. La loi du destin commun énonce notre tendance à percevoir une forme com-mune lorsque des parties partagent une même trajectoire (i.e. des parties en mouvement).
6. La loi de familiarité veut que nous percevions en priorité les formes les plus familières.
1.3.3 Position et taille
Le cartographe Jacques Bertin (Bertin, 1983) proposa une sémiologie graphique pour la représentation visuelle des données, à savoir un ensemble de règles visant à traduire graphiquement toute information. Dans son ouvrage fondateur, Bertin proposa un ensemble de variables visuelles à utiliser pour la création de cartes géographiques, diagrammes et réseaux. Cette classification reste à ce jour une référence en graphisme.
Les huit variables visuelles identifiées par Bertin sont : la position (en X et en Y), la grandeur, la forme, le contraste, la couleur, l'orientation et la texture.
Parmi les éléments les plus importants, Bertin suggère que la taille du texte rende compte d'un niveau de hiérarchie entre les éléments. La couleur peut, quant à elle, être utilisée pour différencier les éléments en thématique.
1.3.4 Culture
Hofstede (Hofstede et al., 1991) identifia cinq dimensions culturelles inhérentes
à toute société et évalua 53 pays sur une échelle de 0 à 100 pour chacune de ces dimensions. Ces dimension culturelles sont :
~ indie x. ylocation Slttchange ln lcngth.ru"Ca ~ Sl>llPf ~ numbcr -Of sllllPC Value - ~~ froniligl•10dnrk Coioo.r d.angcsin ~ ru a givcn " due Orkaiailon di:llljlCSin alÏ!JJUllCllt T01Ure variation in•grain"
Figure 1.5 Les huit variables visuelles proposées par Bertin (Bertin, 1983). 1. la distance hiérarchique,
2. le contrôle del'incertitude,
3. l'individualisme et le collectivisme, 4.la dimension masculine et féminine, 5. l'orientation court terme et long terme
Marcus et Gould (Marcus et Gould,2001) reprirent les résultats de Hofstede pour comparerle contenu textuel et visuel de pages Web provenant de pays qui, pour chacune des dimensions proposées,sont les plus éloignés l'un de l'autre.
Àtitred'exemple,la distance hiérachique rend comptedu degré de toléranceface àl'inégalité dans une société.Àcet égard, Marcus et Gould comparèrent les sites Web de deux universités, l'uneen Malaisie où la note relativeàla distance hié -rachique est la plus élévée (i.e. très tolérant) et l'autre aux Pays-Bas, où la note est la plus faible. Les auteurs constatèrent que lesite Web malaisien était hau -tement symétrique avec une description élaborée et élogieuse des dirigeants de l'université. Les logos de l'institution étaient aussi mis del'avant. Lesite hol lan-dais, pour sa part, avait un visuel asymétrique et mettait un accent beaucoup moindre sur le corps professoral et les logos de l'université,tout en montrant des photos d'étudiants.
Marcus et Gould donnent un autre exemple basé sur ladimension du contrôle de l'incertitude. Ils choisirent les sites \Veb de deux compagnies d'aviation, l'une en Belgique (note lamoins bonne pour le contrôle de l'incertitude) et l'autreen Angleterre (note laplus élevée). Les auteurs notèrent que le site belge minimisait toutecomplexité visuelle et navigationnelle, et était trèsminimaliste, voire stable, avec des couleurs et attributs de style redondants. Au contraire,lesite anglais était beaucoup plus complexe visuellement. La navigation étaient plus élaborée, des fenêtres pouvaient apparaîtres de manière imprévueet des événements dynamiques pouvaient être enclenchés par des actions de l'utilisateur.
Ces travaux montrent que les différences culturelles associées à une conception du monde particulière s'étendent jusque dans les représentations formelles de la connaissance qui dépassent le cadre du contenu textuel pour finalement s'imbr i-quer sémantiquement dans le contenu visuel des documents VRDCH.
1.4 Conclusion
Dans cc chapitre, nous avons présenté les principaux systèmes d'extraction de données pour le Web en catégorisa.nt ceux-ci selon le typed'approche utilisé pour extraire rinformation. Nous avons montré que, de manière générale, le degré d 'au-tomatisation des systèmes d'extraction de données est inversement proportionnel à leur degré de robustesse. Ainsi, les systèmes qui nécessitent le plus d'efforts de conception,àsavoir ceux basés sur les ontologies et le traitement automatique du langage naturel, sont les plus robustes. Au contraire, les systèmes d 'extrac-tion basés sur la structure HTML des documents, bien qu'ayant un degré d 'au-tomatisation élevé, sont habituellement les moins robustes. Nous avons ensuite présenté les principaux systèmes d'extraction basés sur l'informationvisuelle. Ces travauxmontrent l'importanceque jouel'information visuelle dans les documents VRDCH. Finalement, nous avons présenté plusieurs travaux justifiant l' impor-tancede l'information visuelle chez l'humain.
-EXTRACTION DE DONNÉES FINANCIÈRES DANS DES DOCUMENTS PDF À PARTIR D'UNE 1\tlÉTHODE BASÉE SUR LA POSITION
Le texte de ce chapitre provient de l'article intitulé A Position-Based lv!ethod for
the Extractfon of Financial Infomiation in PDF Dornments publié dans l'acte de conférence ADCS '16 Proceedings of the 21 st A ustralasian Document Computing
Syrnposiurn (Potvin et al., 2016).
Les travaux présentés ont été réalisé dans le cadre d'un stage Mita.es Accélération pour l'entreprise Metix qui travaillait au développement d'un outil d'extraction de l'information pour la Caisse de Dépôt et de Placement du Québec (CDPQ). L'objet principal de cet article, c'est-à-dire la méthode d'extraction basée sur la position de l'information, a été intégralement élaborée et développée par le présent auteur, sous la supervision du Prof. Villemaire. Dans le cadre des recherches en partenariat avec Mitacs, mon collègue Ngoc-Tan Le a aussi été impliqué dans le projet en travaillant au développement d'un module pour la reconnaissance d'entités nommées (présenté à la Section 2.5.4). Par conséquent, Ngoc-Tan Le est le troisième auteur de cet article.
L'article présente une méthode basée sur la position de l'information pour l'ex-traction de données financières dans des documents PDF. Ce n'est pas un hasard si les donnéés financières sont partagées par le biais de documents destinés à une consommation humaine plutôt que dans un format standardisé qui facilite l'extrac-tion automatique 1 . En effet, un accès privilégié aux données financières permet de
1. Le langage eXtensible Business Reporting Lang11,age (XBRL) existe depuis 2003 et permet le partage d:information financière dans un format standardisé (XBRL, 2013).
prendre de bonnes décisions plus rapidement, ce qui procure un avantage considé-rable dans l'industrie. Les données sont donc partagées par le biais de documents PDF dans le but d'en restreindre l'usage. Conséquemment, les organisations fi-nancières investissent des sommes significatives pour un accès privilégié à l'infor-mation. Dans l'industrie, ce sont majoritairement des humains qui travaillent à l'extraction des données, à savoir des analystes financiers engagés à l'interne ou à l'externe lorsque la tâche est sous-traitée (parfois dans d'autres pays).
Le fait d'avoir recours à une expertise humaine plutôt qu'à des méthodes automa-tiques s'explique principalement par la difficulté d'obtenir des résultats d'extrac-tion satisfaisants, notamment en ce qui concerne la précision des résultats. Les données financières sont contenues en grande partie dans des tableaux de divers formats. Bien que l'interprétation des différents types de tableaux ne pose pas problème aux lecteurs humains, c'est au contraire une tâche très complexe pour un ordinateur. L'extraction d'information à partir de tableaux (Table Extraction) dans des documents VRDCH a été amplement étudiée.
Dans le cas de pages vVeb, si le tableau a été construit conformément aux ba-lises HTML destinées à la création de tels objets (<table>, <tr>, <th>, <td>) alors l'extraction d'information structurée est aisée. Or, il est aussi possible de construire des tableaux en positionnant de manière absolue des balises (<div>) sur la page \:Veb. Ainsi, on obtient un ensemble de données qui apparait comme étant un tableau pour le lecteur humain mais qui, selon la structure du code HTML, n'en est pas un. De tels tableaux sont similaires à ceux que l'on retrouve dans des documents PD F où les éléments sont positionnés de manière absolue et où les lignes de contour - lorsque présentes - sont en fait des vecteurs graphiques qui ne sont pas directement associés au contenu textuel dans le code du document. Dans de tels cas, l'extraction d'information est trf'.s ardue. Dès lors, les méthodes d'extraction existantes ne correspondaient pas aux besoins de la CDPQ. C'est pour cette raison qu'une nouvelle méthode a été développée.
Cet article introduit l'idée selon laquelle, dans des documents VRDCH, des enti-tés homogènes ont des caractéristiques visuelles similaires. Cette hypothèse sera exploitée tout au long de cette thèse et c'est en fait ce premier article qui pave la voie au développement de la méthode de validation non supervisée qui sera
2.1 Résumé
Les documents financiers sont omniprésents et requièrent des ressources humaines significatives pour extraire, valider et exporter leur contenu. Les données finan-cières jouent un rôle important dans le processus décisionnel des acteurs écono-miques où la nécessité d'obtenir des données fiables surpasse les gains qui pour-raient être obtenus en accélérant le processus ou en tentant de limiter les ressources déployées. Bien que plusieurs méthodes ont été suggérées dans la littérature, la problématique d'extraire automatiquement des données financières de manière fiable demeure difficile et l'extraction dans l'industrie se fait encore, en grande partie, par le biais d'une expertise humaine. Cette difficulté provient du fait que les données financières se trouvent majoritairement dans des tableaux hautement hétérogènes. Dans de telles situations, les méthodes d'extraction d'information à partir de tableaux (Table Extraction) sont considérées comme essentielles. Or, les performances obtenues par l'utilisation de telles méthodes - surtout au niveau de la précision - ne correspondent généralement pas aux besoins de l'industrie. Dans cet article, nous présentons une méthode pour l'extraction d'information fi-nancière qui ne tente pas de décomposer l'information contenue dans les tableaux comme c'est habituellement le cas. Notre approche est basée sur l'idée que la position de l'information dans des documents VRDCH est un indicateur de rela-tion sémantique. Partant de cette hypothèse, nous avons développé une méthode qui utilise seulement deux heuristiques pour l'eÀ'iraction d'information financière. Nous avons implémenté notre méthode pour la Caisse de Dépôt et de Placement du Québec. Dans cet article, nous présentons notre méthode et son évaluation sur un corpus de 600 documents financiers, où un F-score de 0.91 est atteint.
2.2 Abstract
Financial documents are omnipresent and necessitate extensive human efforts in order to extract, validate and export their content. Considering the high impor-tance of such data for effective business ~ the need for accuracy goes
beyond any attempt toaccelerate theprocess or save resources. vVhile many me -thodshave been suggested in the literature, theproblem toautomatically extract reliable financial data remains difficult to solve in practice and even more cha l-lenging to implement in a rea.1 life context. This difficulty is driven by thespecific nature of financial text where relevant information is principally contained in tables of varying formats. Table Extraction ('TE) is considered as an essential but difficult step for restructuring data ina handleable format by identifying and decomposing table components. Inthis paper, we present a novcl method for ex -tractingfinancial informationby themean of two simple heuristics. Our approach is based on theideathattheposition of information, in unstructured but visually rich documents -as itis thecase for thePortable Document Format (PDF) -is an indicatorof semantic relatedness. This solution has been developed inpartnership with theCaisse de Dépot et Placement du Québec. We present here our method and its evaluation on a corpus of 600 financial documents, where a F-measure of 0.91 is reached.
2.3 Introduction
vVhile XBRL (eXtensible Business Reporting Language) (XBRL, 2013) is a glo-bal standard XML-based language for business information exchanges that can be used to import reliable financial information from structured documents, al-most all financial documents in the industry are shared in the Portable Document Format (PDF). This format allows users to read a document on different output devices while offering a compelling visual aspect. PDF documents are meant to be read by humans - not machines - and their content is orga.nized relatively to their encapsulated layout, i.e. position of content, style and gra.phical elements. In other words, PDF documents are structured by and for humans and offer a rich visual prcsentation wherc information is nested in the layout and where semantic content may be implicit (Gabdulkhakova et Hassan, 2012). Consequently, PDF documents are difficult to seize with usual Information Extraction (IE) methods and usually require a substantial prcprocessing task (Chao et Fan, 2004). Our method exploits the idea that a PD F document is built over thcse visual charactcristics and that its meaning is embedded in the visual representation.
In this paper, we present a novel approach to eÀrtract numerica1 financial infor-mation contained in PDF documents. Table Extraction (TE) is considered as an essential but difficult step in IE for restructuring data of tables in a handleable format by identifying and decomposing their elements. \Vhile most suggested me-thods use involved set of rules in order to seize several types of tables, we use only two heuristics based on the idea that the position of information, in unstructured but visually rich documents, is an indicator of semantic relatedness - or as the proverb says birds of a feather flock together. Our approach is slightly influen-ced by the Simrank algorithm (Jeh et vVidom, 2002) where the object-to-object relationship is given by their relative distance (interpreted as proximity) 2 •
Our two heuristics are respectively based on the density and the proximity of information. The first heuristic defines a line density threshold that plays the role 2. vVe do not implement the recursive SimRank equations. By this comparison, we want to rœall the intuition that guided us through the development of our algorithm.