HAL Id: hal-02600978
https://hal.inrae.fr/hal-02600978
Submitted on 16 May 2020
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of
sci-entific research documents, whether they are
pub-lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destinée au dépôt et à la diffusion de documents
scientifiques de niveau recherche, publiés ou non,
émanant des établissements d’enseignement et de
recherche français ou étrangers, des laboratoires
publics ou privés.
OTAMIN : OuTil Automatique d’estiMation de
l’INcertitude prédictive. Notice détaillée
J. Viatgé, C. Furusho
To cite this version:
J. Viatgé, C. Furusho. OTAMIN : OuTil Automatique d’estiMation de l’INcertitude prédictive. Notice
détaillée. irstea. 2014, pp.24. �hal-02600978�
IRSTEA – UR HBAN – ÉQUIPE HYDROLOGIE
20 OCTOBRE 2014
VIATGÉ JULIE
FURUSHO CARINA
Centre d'Antony
1, rue Pierre-Gilles de Gennes
CS 10030
92761 Antony Cedex
OTAMIN : OuTil
Automatique d’estiMation
de l’INcertitude prédictive
NOTICE DÉTAILLÉE
Institut national de recherche en sciences et technologies pour l’environnement et l’agricultureTitre
OTAMIN : OuTil Automatique d’estiMation de l’INcertitude prédictive
– Notice détaillée
Auteurs
Julie VIATGÉ, Carina FURUSHO
Date
Décembre 2014
Institution
Irstea – Unité HBAN – Équipe Hydro
Suivi
SPC LCI: Lionel BERTHET – Renaud MARTY
Commanditaire Convention SCHAPI – Irstea
Nb de pages
du rapport
24
Fournis avec le
Introduction
L’outil OTAMIN est conçu dans l’objectif d’associer de manière automatique et systématique des intervalles prédictifs aux prévisions hydrologiques et hydrauliques obtenues avec différents modèles déterministes utilisés de manière opérationnelle au sein du réseau SCP-SCHAPI.
Ce rapport présente les différents utilitaires d’OTAMIN : - L’analyse des séries passées
- Le calage des Abaques - L’utilisation en temps réel
L’idée de ce rapport est de présenter de manière simple le fonctionnement de l’outil OTAMIN et sa prise en main. La première partie sera consacrée à la définition de quelques mots-clés qui permettra d’éviter toute confusion, ainsi que la liste de quelques détails généraux nécessaires au bon fonctionnement de l’outil. Nous présentons ensuite dans 3 parties distinctes, les 3 utilitaires d’OTAMIN cités ci-dessus : leurs configurations, fichiers d’entrées, fonctionnement et données de sorties. Enfin, la mise en œuvre pas-à-pas d’OTAMIN est présentée dans une cinquième et dernière partie.
Tables des matières
INTRODUCTION ... 3
TABLES DES MATIERES ... 4
1 QUELQUES DEFINITIONS… ... 5
2 ANALYSE DES SERIES PASSEES ... 7
2.1. CONFIGURATION ... 7
2.2. DONNEES D’ENTREE _01_ANA/_IN ... 7
2.3. PROGRAMME R/INC_ANA.R, R/INC_ANA/*.R ET R/INC_CAL/*.R ... 7
2.4. FICHIERS DE SORTIE _01_ANA/_OUT... 9
3 CALAGE DES ABAQUES ... 10
3.1. CONFIGURATION ... 10
3.2. DONNEES D’ENTREE _02_CAL/_IN ... 10
3.3. PROGRAMME R/INC_CAL.R ET R/INC_CAL/*.R ... 10
3.4. FICHIERS DE SORTIE _02_CAL/_OUT ET _03_TR/_TR ... 10
4 UTILISATION EN TEMPS REEL ... 12
4.1. CONFIGURATION ... 12
4.2. DONNEES D’ENTREE _03_TR/_IN ... 12
4.2.1. Format CSV Scores ... 12
4.2.2. Format XML ... 13
4.3. PROGRAMME R/INC_TR.R ET R/INC_TR/*.R ... 13
4.4. FICHIERS DE SORTIE _03_TR/_OUT ... 14
4.4.1. Format CSV Scores ... 14
4.4.2. Format XML ... 14
5 MISE EN ŒUVRE PAS-A-PAS ... 16
REFERENCES ... 17
ANNEXE 1 : ARCHITECTURE D’OTAMIN ... 18
ANNEXE 2 : DETAILS SUR LA FONCTION UNCERTAINTY_CEMA_BASE (METHODE QUOIQUE) ... 19
1 Quelques définitions…
Avant de rentrer plus en détails dans le fonctionnement des différents utilitaires du modèle, il est important de redéfinir ici un certain nombre de termes qui seront largement utilisés par la suite de ce rapport. Le terme « Modèle » sera en effet largement abordé. On entend par là le code correspondant au modèle utilisé pour produire les séries de prévision. Ce code suit le format suivant :
- 2 caractères pour le SPC producteur de la prévision (exemple : LC pour le SPC Loire – Cher – Indre) ;
-
1 caractère pour la famille de modélisation (exemple : g pour une modélisation hydrologique globale) ;-
3 caractères identifiant la plate-forme de modélisation (exemple : GRP) ;-
1 caractère identifiant la nature de la sortie du modèle (d pour des sorties déterministes, e pour des sorties ensemblistes, p pour des sorties probabilistes et t pour des tendances de prévision) ;-
3 caractères libres (000 par défaut) qui peuvent être utilisés pour distinguer deux configurations internes différents, par exemple deux calages distincts d’un modèle hydrologique.On aura par exemple le code modèle suivant dans le cas du SPC Loire – Cher – Indre qui utiliserait GRP : LCgGRPd000. Un modèle peut être exécuté avec différents scenarios ce qui rend leur identification nécessaire. Ainsi on parlera de scenarios différents pour 2 entrées différentes dans un même modèle. Une manière de décrire de façon complète une série de prévision serait de combiner le modèle et le scenario comme cela peut être fait dans les fichiers CSV Scores via l’identifiant Id_series (voir ci-après) qui sera du type : Id_Series = Modele_Scenario (Par exemple LCgGRPd000_2001). OTAMIN ne traitera que les modèles déterministes.
Il est important ici de préciser les unités prises en compte par OTAMIN. Pour les fichiers XML l’unité est imposée : il s’agit de l/s pour les débits et de mm pour les hauteurs d’eau. OTAMIN se chargera donc de faire les conversions nécessaires. Pour les fichiers au format CSV Scores, l’unité n’est pas imposée mais elle devra être précisée en entête des fichiers d’entrée ou il sera décidé que l’unité par défaut sera le m3/s pour les débits et le m pour les hauteurs d’eau.
OTAMIN est indépendant du pas de temps du modèle en Analyse et Calage : l’utilisateur pourra à sa guise donner des fichiers d’entrée aux pas de temps horaire ou journalier. Ce n’est pas le cas de l’utilisateur Temps réel où il sera demandé de donner des données d’entrées à pas de temps horaire. L’horizon de prévision quant à lui devra être donné en heure. Nous recensons quelques performances en termes de temps d’exécution d’OTAMIN dans les tableaux suivants (un tableau par utilitaire). Ces performances ont été calculées sur un processeur Intel Xeon de 3,2 GHz.
- Utilitaire d’Analyse
Méthode Nombre de fichiers de données d’entrée Temps d’exécution (en sec) QUOIQUE 1 5.09 4 18.6 6 27.5 RQ 1 6 4 23.09 6 34.21 - Utilitaire de Calage
Méthode Nombre de fichiers de données d’entrée Temps d’exécution (en sec) QUOIQUE 1 2.7 4 11.06 6 16.53 RQ 1 4.01 4 16 6 23.76
- Utilitaire Temps Réel
Le temps d’exécution d’OTAMIN est assez variable en fonction du type de fichier d’entrée : il est beaucoup plus lent pour traiter les fichiers XML.
Type de fichier Nombre de scenarios de prévisions traités Temps d’exécution (en sec) CSV Scores 36 0.7 72 1.91 144 5.34 XML 36 8.46 72 17.54 144 38.61
2 Analyse des séries passées
L’étape d’analyse permet d’estimer et appliquer une méthode d’estimation de l’incertitude suivant une procédure de calage-contrôle. L’objectif principal de cette étape est de mettre en évidence certaines difficultés liées à la stabilité temporelle de la caractérisation du nuage d’erreurs.
Le manque de transférabilité temporelle est révélé par l’analyse de la fiabilité de l’estimation des incertitudes. Un manque de fiabilité manifeste doit amener l’utilisateur à s’interroger sur les raisons de cette instabilité (cohérence des données, caractéristiques des périodes,…) et à se méfier des résultats fournis de manière automatique.
2.1. Configuration
Format du nom de fichier : config_ana.txt Format du fichier :
#01# : Adresse du répertoire où sont situés les
fichiers d’entrée
#02# : Adresse du répertoire où seront écrits les
fichiers de résultats
#04# : Méthode choisie pour le calcul de l’incertitude
prédictive
#05# : Quantiles à estimer pour les abaques (3
valeurs max.) : valeurs basse, médiane et haute
#06# : Quantiles complémentaires à estimer
#07# : Quantiles à tracer dans les graphiques de
sortie (5 valeurs max.)
2.2. Données d’entrée _01_ANA/_in
Débits en m3/s au pas de temps horaires en Observation et Prévision (Simulation)
Format du nom de fichier : STATION_MODELE_HORIZON.csv Format du fichier :
3 Lignes d’entête comprenant :
Le(s) site(s) hydrologique(s) pour les prévisions de débit AAAAAAAA ou la(les) station(s) hydrologique(s) pour les donnée(s) de hauteur AAAAAAAAAA (séparés par des points-virgules)
Le(s) type(s) de donnée : A (séparés par des points-virgules) Le(s) modèle(s) : AAAA… (séparés par des points-virgules) 1 Ligne d’entête commençant par « # » et comprenant :
Les détails du contenu des colonnes Les données : JJ-MM-AAAA HH:MM;OBS;PREV Remarque :
- Pas de caractère « _ » dans le nom du modèle dans le titre des fichiers d’entrée. D’autre part :
o Les noms de fichiers doivent contenir le nom de modèle complet, de type : LCgGRPd000, et ce, pour les parties calage et analyse
- Les données peuvent être fournies au pas de temps journalier, il sera nécessaire, dans tous les cas, de préciser le format choisi au niveau de la ligne d’entête précédée d’un « # ». Par exemple : # JJ-MM-AAAA (pour le pas de temps journalier ; ou # JJ-MM-AAAA HH :MM (pour le pas de temps horaire).
2.3. Programme R/INC_ANA.R, R/INC_ANA/*.R et R/INC_CAL/*.R
1. Chargement des données de configuration du fichier _01_ANA/_config/config_calage.txt
2. Chargement de la liste des fichiers d’entrée qui nous permet de connaître : le nombre de bassin à traiter et
pour chaque bassin, le (les) modèle(s) utilisé(s), l’ (les) horizon(s) de prévision 3. Lancement d’une boucle sur les bassins à traiter
a. Détermination du (des) modèle(s) utilisé(s)
i. Lecture des données d’entrées dans _01_ANA/_in (fonction lecBV) ii. Identification de 2 périodes de durées égales
iii. Calcul de l’incertitude prédictive par période avec la méthode choisie en configuration (QUOIQUE ou RQ) (fonction mainBV qui appelle la fonction uncertainty_cema_base ou uncertainty_rq. Voir Annexe 2 : Détails sur la fonction uncertainty_cema_base (Méthode QuoiQue))
iv. Tracé des graphiques de sorties dans _01_ANA/_out/INC_ABA (fonction plotBV), Calcul des scores et tracé dans _01_ANA/_out/INC_EVAL (fonction plotDiagBV), écriture des résultats dans un fichier _01_ANA/_out/INC_TAB
2.4. Fichiers de sortie _01_ANA/_out
L’ensemble des fichiers de sorties de ce premier utilitaire sont regroupés dans le tableau ci-après avec leur emplacement, leur titre et description, et un exemple.
d
an
s
INC
_A
BA
STATION_MODELE_PERIODE_HORIZON_METHODE_O_S.png :Pour les 101 points « référence », on trace les valeurs que peut prendre le débit observé. Connaissant les quantiles d’erreur relative à tracer (config_ana.txt, balise #07#) pour les 101 catégories de débits prévus, on détermine les intervalles de confiance sur le débit observé.
STATION_MODELE_PERIODE_HORIZON_METHODE_EM_S.png :
Pour les 101 points « référence », on trace les quantiles sur les erreurs relatives à tracer (config_ana.txt, balise #07#) en fonction du débit prévu.
STATION_MODELE_PERIODE_HORIZON_METHODE_EA_S.png :
Pour les 101 points « référence », on trace les quantiles sur l’erreur additive (config_ana.txt, balise #07#) en fonction du débit prévu. C’est-à-dire la valeur observée possible moins la valeur prévue en fonction de la valeur prévue.
d
an
s
INC
_E
VA
L
STATION_MODELE_METHODE_HORIZON.png :Résultats du calage-contrôle, on observe pour les quantiles complémentaires choisis (config_ana.txt, balise #06#) d’une période, leurs probabilités de dépassement en contrôle. Par exemple, pour le quantile 90, la fréquence à laquelle sa valeur est dépassée en contrôle, ne doit pas être supérieure à 90%.
Une estimation fiable de l’incertitude prédictive se traduit donc par des points à proximité de la diagonale. A l’inverse, les déviations montrent que les caractéristiques des erreurs ne sont pas exactement identiques selon les périodes ; la transférabilité de l’incertitude n’est pas parfaite.
STATION_MODELE_METHODE_EVAL.txt :
Fichier contenant les données tracées ci-avant.
d
an
s
INC
_T
A
B
STATION_MODELE_METHODE_TAB.csv :Pour chaque période et pour chaque horizon, ce tableau récapitule les valeurs de débits simulés des 101 points référence et les quantiles complémentaires choisis (config_ana.txt, balise #06#) des erreurs relatives associées.
3 Calage des Abaques
L’étape de calage doit être conduite APRES l’étape d’analyse et seulement si l’étape d’analyse ne révèle pas de difficultés particulières. Elle se déroule de la même manière que l’étape d’analyse à la différence que le calcul de l’incertitude prédictive est appliqué à l’ensemble de la chronique de données observées. Cette étape est primordiale puisqu’elle va permettre la création d’Abaques qui seront ensuite utilisées en temps réel.
3.1. Configuration
Format du nom de fichier : config_cal.txt Format du fichier :
#01# : Adresse du répertoire où sont situés les fichiers d’entrée #02# : Adresse du répertoire où seront écrits les fichiers de
résultats
#03# : Adresse du répertoire où seront écrites les abaques pour
l’utilisation d’OTAMIN en temps réel.
#04# : Méthode choisie pour le calcul de l’incertitude prédictive #05# : Quantiles à estimer pour les abaques (3 valeurs max.) :
valeurs basse, médiane et haute
#06# : Quantiles complémentaires à estimer
#07# : Quantiles à tracer dans les graphiques de sortie (5 valeurs
max.)
3.2. Données d’entrée _02_CAL/_in
Débits en m3/s au pas de temps horaires en Observation et Prévision (Simulation)
Format du nom de fichier : STATION_MODELE_HORIZON.csv Format du fichier :
3 Lignes d’entête comprenant :
Le(s) site(s) hydrologique(s) pour les prévisions de débit AAAAAAAA ou la(les) station(s) hydrologique(s) pour les donnée(s) de hauteur AAAAAAAAAA (séparés par des points-virgules)
Le(s) type(s) de donnée : A (séparés par des points-virgules) Le(s) modèle(s) : AAAA… (séparés par des points-virgules) 1 Ligne d’entête commençant par « # » et comprenant :
Les détails du contenu des colonnes Les données : JJ-MM-AAAA HH:MM;OBS;PREV Remarque :
- Pas de caractère « _ » dans le nom du modèle dans le titre des fichiers d’entrée. D’autre part :
o Les noms de fichiers doivent contenir le nom de modèle complet, de type : LCgGRPd000, et ce, pour les parties calage et analyse
3.3. Programme R/INC_CAL.R et R/INC_CAL/*.R
Le programme fonctionne de la même manière que le programme utilisé pour la partie « Analyse des séries passées », à la différence qu’il est appliqué à l’ensemble des données d’entrée, c’est-à-dire qu’il n’y a pas de séparation des chroniques en 2 périodes égales en temps.
3.4. Fichiers de sortie _02_CAL/_out et _03_TR/_tr
Les fichiers de sorties sont identiques à ceux de la partie « Analyse des séries passées » à la différence qu’ils sont réalisés pour l’ensemble des données d’entrée. Ils sont présentés dans le tableau suivant avec leur emplacement, leur titre et description, et un exemple.
d
an
s
INC
_A
BA
STATION_MODELE_HORIZON_METHODE_O_S.png :Pour les 101 points « référence », on trace les valeurs que peut prendre le débit observé. Connaissant les quantiles d’erreur relative à tracer (config_cal.txt, balise #07#) pour les 101 catégories de débits prévus, on détermine les intervalles de confiance sur le débit observé.
STATION_MODELE_HORIZON_METHODE_EM_S.png :
Pour les 101 points « référence », on trace les quantiles sur les erreurs relatives (config_cal.txt, balise #07#) en fonction du débit prévu.
STATION_MODELE_HORIZON_METHODE_EA_S.png :
Pour les 101 points « référence », on trace les quantiles sur l’erreur additive (config_cal.txt, balise #07#) en fonction du débit prévu. C’est-à-dire la valeur observée possible moins la valeur prévue en fonction de la valeur prévue.
d
an
s
INC
_E
VA
L
STATION_MODELE_METHODE_EVAL.txt :On observe pour les quantiles complémentaires choisis (config_cal.txt, balise #06#) d’une période, leurs probabilités de dépassement. Par exemple, pour le quantile 90, la fréquence à laquelle sa valeur est dépassée en contrôle, ne doit pas être supérieure à 90%. Les écarts traduisent que les erreurs ne sont pas exactement identiques selon les périodes.
d
an
s
INC
_T
A
B
STATION_MODELE_METHODE_TAB.csv :Pour chaque horizon, ce tableau récapitule les valeurs de débits simulés des 101 points référence et les quantiles complémentaires choisis (config_cal.txt, balise #06#) des erreurs relatives associées.
d
an
s
_0
3_
CA
L/_
tr
STATION_MODELE_METHODE_INC_TAB.RData :Pour chaque période et pour chaque horizon, ce tableau récapitule les valeurs de débits simulés des 101 points référence et les quantiles à estimer (config_cal.txt, balise #05#) des erreurs relatives associées. Ces fichiers servent pour le fonctionnement de l’utilitaire temps réel.
4 Utilisation en temps réel
Cette utilitaire a pour objectif de donner, en temps réel, les incertitudes liées à la prédiction. Se basant sur les analyses passées (Abaques créées dans la partie « Calage »), l’utilitaire temps réel d’OTAMIN va permettre de déterminer automatiquement des intervalles prédictifs aux prévisions hydrologiques et hydrauliques issues de différents modèles.
4.1. Configuration
Format du nom de fichier : config_tr.txt Format du fichier :
#01# : Adresse du répertoire où sont situés les fichiers
d’entrée
#02# : Adresse du répertoire où seront écrits les fichiers de
résultats
#03# : Adresse du répertoire où sont écrites les abaques
pour l’utilisation d’OTAMIN en temps réel (ATTENTION ! Cette adresse doit être la même que celle définie à la balise #03# du fichier config_cal.txt).
#04# : Méthode à utiliser pour le calcul de l’incertitude prédictive
#05# : Quantiles à estimer (3 valeurs max.) : valeurs basse, médiane et haute
4.2. Données d’entrée _03_TR/_in
Remarques communes à tous les formats d’entrée :
- Pas de caractère « _ » dans le nom du modèle dans le titre des fichiers d’entrée. D’autre part :
o Les noms de fichiers doivent contenir le nom de modèle complet, de type : LCgGRPd000, et ce, pour les parties calage et analyse
o En temps réel, ce n’est pas nécessaire puisque le nom de modèle complet est récupéré dans le fichier - Toutes les balises d'une ligne commentée (débutant par un caractère #) sont précédées d'un espace : # Modeles,
# Scenarios...
- Il est possible d’avoir des espaces entre les colonnes des fichiers d’entrée pour plus de lisibilité, OTAMIN saura le gérer correctement
- Il est nécessaire de fournir la(les) date(s) de(s) la dernière(s) donnée(s) observée(s) (avec l’heure) à la balise # DtDerObs pour les fichiers CSV Scores ou <ComSimul>{DtDerObs}…{/DtDerObs}</ComSimul> pour les fichiers XML, sans quoi OTAMIN ne pourra déterminer l’horizon de prévision.
4.2.1. Format CSV Scores
Débits prévus au pas de temps horairesFormat du nom de fichier : MODELE_B_DATEDIFFUSION.prv Format du fichier :
4 Lignes d’entête débutant par « # » et comprenant : La définition du fichier
La zone temporelle de référence TZ L’unité des données de débits Q L’unité des données de hauteur H 3 Lignes d’entête comprenant :
Le(s) site(s) hydrologique(s) pour les prévisions de débit AAAAAAAA ou la(les) station(s) hydrologique(s) pour les donnée(s) de hauteur AAAAAAAAAA (séparés par des points-virgules)
Le(s) type(s) de donnée Grandeurs : A (séparés par des points-virgules)
L’(Les) identifiant(s) modèle + scénario IdSeries (séparés par des points-virgules) 3 Ligne d’entête débutant par « # » et comprenant :
Le(s) modèle(s) # Modeles: AAAAAA… (séparés par des points-virgules)
Le(s) numéro(s) du (des) scénario # Scenario : AAA… (séparés par des points-virgules) La(Les) date(s) de(s) la dernière(s) donnée(s) observée(s) DtDerObs
4.2.2. Format XML
Débits prévus au pas de temps horaires
Format du nom de fichier : MODELE_B_DATEDIFFUSION.xml Format du fichier :
Nous ne détaillerons pas le format des fichiers XML ici puisque celui-ci correspond au format XML Sandre déjà utilisé par le SCHAPI (Voir Annexe 3 : Spécifications de formats pour les entrées et sorties de l’utilitaire temps réel).
4.3. Programme R/INC_TR.R et R/INC_TR/*.R
1. Chargement des données de configuration du fichier _03_TR/_config/config_tr.txt 2. Chargement de la liste des fichiers d’entrée
3. Chargement du paquet XML si le format est XML
4. Pour chaque fichier d’entrée : création d’une liste de listes contenant les données et infos pour chaque station
5. Pour chaque bassin :
a. Vérification des unités et conversion si nécessaire b. Chargement des abaques du dossier _03_TR/_tr
c. On ne garde des données d’entrées que les stations pour lesquelles on a des abaques et pour ces stations, on ne garde que les horizons de prévision pour lesquels on a des informations dans les fichiers abaques.
d. Pour chaque horizon de prévision :
i. On récupère les données d’entrée (temp_val) et les incertitudes disponibles en abaques (temp_inc).
ii. On détecte si le débit prévu est en dehors des bornes min et max des débits simulés, ou s’il est « dedans ». S’il est en dehors, on extrapole les quantiles des erreurs relatives de la 1ère et de la dernière donnée pour trouver les erreurs relatives de ce débit ; s’il est « dedans », on interpole entre les 101 points référence.
iii. On regroupe dans une matrice (Mout) la prévision et les incertitudes associées (en général, la plus basse, la médiane et la plus haute).
4.4. Fichiers de sortie _03_TR/_out
Les fichiers de sorties de l’utilitaire temps réel donnent pour chaque station/modèle/scenario, le débit prévu et les incertitudes associées (la plus basse, la médiane et la plus haute). Lorsque les abaques ne sont pas disponibles, seuls les prévisions déterministes sont affichées.
4.4.1. Format CSV Scores
Format du nom de fichier : MODELE_B_DATEDIFFUSION.prv Format du fichier :
4 Lignes d’entête débutant par « # » et comprenant : La définition du fichier
La zone temporelle de référence TZ L’unité des données de débits Q L’unité des données de hauteur H 3 Lignes d’entête comprenant :
Le(s) site(s) hydrologique(s) pour les prévisions de débit AAAAAAAA ou la(les) station(s) hydrologique(s) pour les donnée(s) de hauteur AAAAAAAAAA (séparés par des points-virgules)
Le(s) type(s) de donnée Grandeurs : A (séparés par des points-virgules)
L’(Les) identifiant(s) modèle + scénario + probas IdSeries (séparés par des points-virgules) 3 Ligne d’entête débutant par « # » et comprenant :
Le(s) modèle(s) # Modeles: AAAAAA… (séparés par des points-virgules)
Le(s) numéro(s) du (des) scénario # Scenario : AAA… (séparés par des points-virgules) La(Les) date(s) de(s) la dernière(s) donnée(s) observée(s) DtDerObs
Les données : JJ-MM-AAAA HH:MM;PREV;…
Le format est assez similaire à celui d’entrée à la différence que sont également affichées les incertitudes (basse, médiane et haute) sous forme de colonnes suivant la prévision déterministe. Les données manquantes sont affichées au format « -999.999 ».
4.4.2. Format XML
Format du nom de fichier : MODELE_B_DATEDIFFUSION.xml Format du fichier :
Nous ne détaillerons pas le format des fichiers XML ici puisque celui-ci correspond au format XML Sandre déjà utilisé par le SCHAPI (Voir Annexe 3 : Spécifications de formats pour les entrées et sorties de l’utilitaire temps réel).
Le format est assez similaire à celui d’entrée à la différence que sont également affichées les incertitudes (basse, médiane et haute) dans une nouvelle balise suivant la prévision déterministe (voir encadré rouge sur l’image ci-après). Les données manquantes ne sont pas affichées.
5 Mise en œuvre pas-à-pas
L’architecture d’OTAMIN est celle indiquée dans le graphique ci-contre. La marche à suivre pour l’utilisation de l’outil suit la structure du dossier. Ainsi, l’utilisateur devra donner les informations suivantes dans l’ordre suivant :
- _00_CONFIG contient le fichier configR.txt dans lequel il est demandé à l’utilisateur d’entrer l’adresse de son exécutable Rscript.exe
- _01_ANA contient des sous-dossiers _config et _in. L’utilisateur déposera les fichiers des données de débits observés et simulés dans le dossier _in. Il lui est demandé de compléter le fichier config_ana.txt du dossier _config (voir détails du fichier dans 2.1 Configuration)
- De la manière que pour le dossier _01_ANA, l’utilisateur doit compléter le dossier _02_CAL.
- Enfin, dans le dossier _03_TR, on demande également de compléter le fichier config_tr.txt du dossier _config, et de déposer des fichiers de prévisions au pas de temps horaire dans le dossier _in. Attention, l’adresse donnée à la balise #03# du fichier config_tr.txt doit être la même que celle donnée à la balise #03# du fichier config_cal.txt.
Une fois toutes les configurations faites et tous les fichiers d’entrées déposés. L’utilisateur n’a plus qu’à lancer chacun des 3 exécutables correspondant aux 3 utilitaires de l’outil OTAMIN dans l’ordre suivant :
- exe_ana.bat pour l’utilitaire d’analyse des séries passées
- exe_cal.bat pour l’utilitaire de calage des abaques, à lancer si l’étape d’analyse ne montre pas de difficultés particulières. Les résultats de l’étape d’analyse sont visibles dans le dossier _01_ANA\_out
- exe_tr.bat pour l’utilitaire temps réel
Les résultats de chacun des utilitaires sont visibles dans les sous-dossiers « _out » des dossiers principaux de chaque utilitaire (_01_ANA, _02_CAL et _03_TR)
Références
BOURGIN, F. : Comment quantifier l’incertitude prédictive en modélisation hydrologique ? Thèse de doctorat, AgroParisTech/ENGREF, Paris, 2014, 208 pp.
BOURGIN, F., RAMOS, M.-H., THIREL, G. et ANDRÉASSIAN, V. : Investigating the interactions between data assimilation and post-processing in hydrological ensemble forecasting. Journal of Hydrology, Article in press. XXX: XXX – XXX, XXXX.
Annexe 1 : Architecture d’OTAMIN
_00_CONFIG configR.txt _01_ANA _config config_ana.txt _in fichiers *.csv _out INC_ABA STATION_MODELE_PERIODE_HORIZON_METHODE_EA_S.PNG STATION_MODELE_PERIODE_HORIZON_METHODE_EM_S.PNG STATION_MODELE_PERIODE_HORIZON_METHODE_O_S.PNG INC_EVAL STATION_MODELE_METHODE_HORIZON.png STATION_MODELE_METHODE_EVAL.txt INC_TAB STATION_MODELE_METHODE_TAB.csv _02_CAL _config config_cal.txt _in fichiers *.csv _out INC_ABA STATION_MODELE_PERIODE_HORIZON_METHODE_EA_S.PNG STATION_MODELE_PERIODE_HORIZON_METHODE_EM_S.PNG STATION_MODELE_PERIODE_HORIZON_METHODE_O_S.PNG INC_EVAL STATION_MODELE_METHODE_EVAL.txt INC_TAB STATION_MODELE_METHODE_TAB.csv _03_TR _config config_tr.txt _in fichiers *.prv fichiers *.xml _out fichiers *.prv fichiers *.xml _tr STATION_MODELE_METHODE_INC_TAB.RData R INC_ANA INC_CAL INC_TR INC_ANA.R INC_CAL.R INC_TR.RAnnexe 2 : Détails sur la fonction uncertainty_cema_base (Méthode QuoiQue)
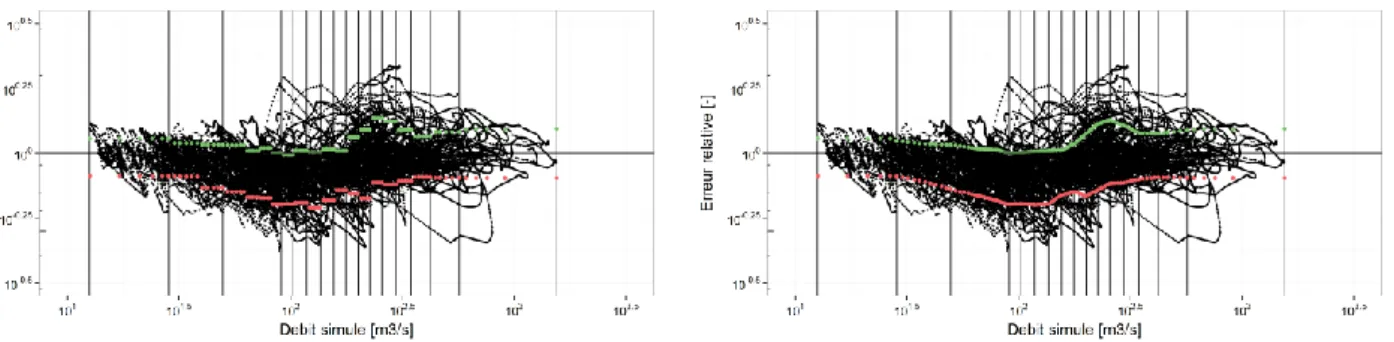
Dans cette fonction, on commence par créer 20 groupes de débits simulés classés (df_g). Pour chacun de ces 20 groupes, sont calculés les quantiles des erreurs relatives (Qobs/Qsim) 10, 25, 50, 75 et 90 (df_stat), de sorte à obtenir un intervalle à 80% des erreurs relatives pour chaque classe de débit.Figure 1: Erreurs relatives en fonction des débits simulés classés
On calcule également pour chaque groupe, les valeurs min et max des débits simulés. Les valeurs des quantiles sont ensuite interpolées sur 101 points auxquels on applique une moyenne mobile : ces 101 points correspondent aux centiles et aux min et max des débits simulés.
Figure 2: Intervalle de confiance à 80% sur les erreurs relatives en fonctions de débits simulés classés
Pour les 101 points, nous avons donc l’intervalle de confiance à 80% (l_out) : c’est-à-dire que pour un débit prévu, on pourrait connaître l’intervalle de confiance de l’erreur relative.
Annexe 3 : Spécifications de formats pour les entrées et sorties de l’utilitaire
temps réel
csv Scores (.prv) XML Sandre (.xml) 1 – Organisation générale
Les fichiers .prv sont des fichiers textes de type csv composés d’un en-tête général libre comptant un nombre quelconque de lignes (débutant par le caractère #) et d’un corps.
Le corps contient les prévisions organisées en colonnes (en-tête caractérisant chaque série de prévision, suivi des données) : la première colonne donne la date au format jj-mm-AAAA HH:MM et les autres colonnes les valeurs prévues pour chaque série.
L’en-tête du corps comporte trois lignes obligatoires, écrites dans l’ordre suivant, qui indiquent a) le lieu de la prévision (code HYDRO du site hydrologique ou de la station hydrologique) ;
b) la grandeur prévue (hauteur ou débit) ;
c) la série de prévision (par exemple, le modèle et son scénario).
Les noms de ces lignes (première information renseignée) sont les mots clefs Stations, Grandeurs et IdSeries.
Il peut en outre apporter des informations complémentaires mais toutes les lignes supplémentaires doivent débuter par le caractère # suivi d’un espace. Pour l’estimation des incertitudes de prévision et l’expertise des prévisions, plusieurs champs supplémentaires sont nécessaires (# Modeles, # Scenarios et # Probas, cf. infra).
Les fichiers XML suivent les prescriptions du référentiel Sandre. Ils peuvent être produits ou lus par la bibliothèque Python libhydro (développée par Philippe Gouin, SCHAPI). Certains champs nécessaires à l’identification et à la caractérisation des prévisions n’étant pas prévus par le référentiel Sandre, ils sont ajoutés entre les balises <ComSimul> et </ComSimul> de façon structurée : des balises encadrées par des accolades {…} sont employées (cf. infra).
2 – Nommage des fichiers
Le nommage des fichiers csv répond à trois contraintes : - le suffixe est .prv ;
- les caractères N° 4 à 6 sont _B_ pour les prévisions non expertisées par un prévisionniste humain (prévisions brutes) ou _E_ pour des prévisions expertisées ;
- ils sont suivis de la date de production des prévisions au format AAAAmmjj_HHMM ;
- les noms des fichiers de prévisions expertisées sont complétés par la date de l’expertise au même format.
Non défini à ce stade
3 – Identification des sites et stations
Le lieu pour lequel les prévisions sont établies est identifié conformément aux prescriptions du référentiel Sandre : - les prévisions de débit sont établies pour des sites hydrologiques dont les codes comptent 8 caractères ;
Les lieux de prévision sont indiqués par les codes (stations ou sites) au niveau de la ligne Stations de l’en-tête.
Ainsi la ligne Stations contient des codes de stations hydrologiques ou de sites hydrologiques.
Les lieux de prévision de débit sont indiqués entre les balises <CdSiteHydro> et </CdSiteHydro> tandis que les lieux de prévision de hauteur sont indiqués entre les balises <CdStationHydro> et </CdStationHydro>.
4 – Identification des modèles
Un modèle correspond à l’outil mis en œuvre par le prévisionniste. Il est nommé sur 10 caractères selon les règles définies pour la POM et compatibles avec les échanges par XML Sandre vers la PhyC (SCHAPI, 2014, section 4.5.7.2.5). En complément, le premier des 4 caractères libres indique le type de sorties (NB : aucun de ces 4 derniers caractères ne peut être le caractère ‘_’).
Ainsi les codes se décomposent de la façon suivante :
- 2 caractères pour le SPC producteur de la prévision (exemple : LC pour le SPC Loire – Cher – Indre) ; - 1 caractère pour la famille de modélisation (exemple : g pour une modélisation hydrologique globale) ; - 3 caractères identifiant la plate-forme de modélisation (exemple : GRP) ;
- 1 caractère identifiant la nature de la sortie du modèle (d pour des sorties déterministes, e pour des sorties ensemblistes, p pour des sorties probabilistes et t pour des tendances de prévision) ;
- 3 caractères libres (000 par défaut) qui peuvent être utilisés pour distinguer deux configurations internes différents, par exemple deux calages distincts d’un modèle hydrologique.
Note pour le suivi lors d’une expertise d’un modèle déterministe identifié par un code XXyZZZdiii : - l’outil d’estimation automatique des incertitudes (OTAMIN) renverra des prévisions enrichies pour des modèles XXyZZZpiii (avec un identifiant pour les probabilités, cf. infra) ;
- l’outil d’expertise des prévisions prendra en entrée les sorties déterministes ou probabilistes précédentes pour renvoyer les prévisions pour le modèle XXhPPPtiii où h indique qu’il s’agit d’une prévision humaine et PPP correspondra à la plate-forme d’analyse (SUP ou EAO par exemple).
Référence
SCHAPI (20014). Spécifications fonctionnelles détaillées de la plate-forme opérationnelle de modélisation (POM). 4.5.7.2.5 Codification des modèles.
http://extranet.schapi.i2/spip/IMG/pdf/SCHAPI-POM-DS-Specifications-16.02.pdf Les codes des modèles sont indiqués dans la ligne
#Modeles.
Les codes des modèles sont indiqués entre les balises <CdModelePrevision> et </CdModelePrevision>.
Un modèle déterministe peut être exécuté avec différents scénarios qu’il est nécessaire de pouvoir identifier. Un scénario décrit uniquement les données d’entrée fournies au modèle. Un même « modèle » dans deux configurations différentes sera par contre décrit par deux codes Modèles différents. Par exemple, un modèle Pluie – Débit peut prendre différents scénarios de pluie future en compte. Mais le même code GRP utilisé avec deux jeux de paramètres différents (par exemple, un jeu de paramètres pour la vigilance sur 24 h et un jeu de paramètres pour la prévision à 6 h) sera décrit par deux codes Modèles différents.
Un modèle ensembliste renvoie un ensemble de membres. S’il n’est pas forcément nécessaire pour l’utilisateur final d’identifier les membres, il faut tout de même les numéroter pour permettre une utilisation (statistique) des membres. En effet, ces membres doivent souvent être traités de façon « indifférenciée » pour fournir une moyenne, une médiane ou un autre quantile...
Un modèle probabiliste renvoie une ou plusieurs sorties associées à une probabilité (de réalisation, de dépassement...) qu’il est nécessaire de fournir à l’utilisateur.
Enfin, un modèle peut fournir des tendances « qualitatives » (tendance basse ou optimiste, tendance centrale, tendance haute...) qu’il faut nommer.
Ainsi quel que soit le type des sorties que fournit un modèle, le code modèle seul ne suffit pas (dans la plupart des cas) : une information complémentaire est nécessaire. Pour un traitement automatisé (du type du calcul d’une incertitude associée), il est nécessaire d’identifier le couple (modèle, information complémentaire).
La ou les informations complémentaires utiles sont indiquées dans les lignes optionnelles suivantes : - # Scenarios ;
- # Numeros ; - # Probas ; - # Tendances.
Les informations complémentaires sont transmises dans le bloc encadré par les balises <ComSimul> et </ComSimul> à l’aide des balises additionnelles :
- {Scenario} … {/Scenario} pour les sorties d’un modèle déterministe ;
- {Numero} … {/Numero} pour les membres d’une sortie d’un modèle ensembliste ;
- {Tendance} … {/Tendance} pour les sorties d’un modèle déterministe.
Les prévisions probabilistes sont transmises à l’aide des balises <ProbPrev> et <ResProbPrev> (il n’y a donc pas de besoin d’une balise additionnelle).
Nota. Plusieurs informations peuvent être fournies. Ainsi, une prévision probabilisée construite à partir de la prévision déterministe du scénario N° 2004 du modèle GRP contiendra les balises {Scenario}2004 {/Scenario} et <PProbPrev>... (fichier XML) ou deux lignes #Scenarios et #Probas (fichier Scores).
6 – Date de la dernière observation
La date de la dernière observation disponible (employée par le modèle) est nécessaire pour calculer l’horizon « réel » du modèle (à des fins d’expertise en temps réel par le prévisionniste ou d’évaluation a posteriori, ou encore d’estimation des incertitudes par exemple).
Cette information unique pour tout le fichier est mentionnée dans l’en-tête du fichier au niveau de la ligne démarrant par #DtDerObs.Le format de la date requis est similaire aux autres lignes :
jj-mm-AAAA HH:MM.
Exemple : #DtDerObs ; 11-10-2013 12:00
Cette information est fournie entre les balises additionnelles {DtDerObs} et {/DtDerObs} dans le bloc encadré par les balises <ComSimul> et </ComSimul>. La date est fournie dans le référentiel UTC au format AAAA-mm-jjTHH:MM:SS où T est le caractère séparant le jour de l’heure (format du Sandre).
L’unité ou les unités doivent être spécifiées dans l’en-tête du fichier par deux lignes :
# Q ; suivi de l’indication de l’unité de débit si le fichier comporte des prévisions en débit ;
# H ; suivi de l’indication de l’unité de hauteur si le fichier comporte des prévisions en hauteur.
Si ces éléments sont manquants, les unités prises en compte par défaut seront le m3/s pour les débits et le m pour les hauteurs.
Les débits sont donnés en L/s et les hauteurs en mm. [la nature obligatoire de cette spécification est en attente de confirmation]
8 – Informations complémentaires
L’en-tête du fichier est libre et composé de lignes démarrant par le caractère #. La ligne suivante est attendues :
# TZ ; UTC, indication de la zone temporelle de référence (obligatoirement UTC) ;
La date de production du fichier doit être indiquée lors de sa création dans son nom (cf. supra).
Les informations nécessaires à l’envoi du fichier sont prévues dans le format XML Sandre. On notera en particulier : - les informations pour identifier l’émetteur et le destinataire du fichier de prévisions ;
- la date de production du fichier de prévisions ; - le statut de la prévision (brute ou expertisée) ; - l’autorisation de publier ou non la prévision.
9 – Publication des fichiers
Sans objet Seules des prévisions expertisées par un prévisionniste sont
publiables sous Vigicrues (<ComSimul>true<ComSimul>). En conséquence, aucune prévision en sortie d’OTAMIN ne portera un attribut autorisant la publication.
Dans les fichiers XML produits par l’EAO, seules les prévisions tendancielles (le 7e caractère du code du modèle est égal à « t ») seront autorisées à la publication.
Notes pour le projet OTAMIN
Dans ce cadre, seuls les modèles déterministes doivent être pris en compte (7e caractère du code du modèle égal à d). L’abaque à sélectionner est déterminé par la combinaison :
- du code du modèle,
- de la valeur du champ Scenario,
- du code de la station ou du site hydrologique, - de la nature de la variable prévue,
L’horizon de prévision est calculé par soustraction de la date de la prévision et de la date de la dernière observation disponible.
Les codes des modèles dans le fichier de sortie sont identiques à ceux du fichier d’entrée à la 7e lettre près (qui devient p). Le fichier de sortie rappellera le scénario déterministe employé (pour pouvoir analyser la prévision en retour d’expérience) :
- les fichiers au format Scores indiqueront donc deux lignes complémentaires : #Scenario et #Proba ;
- les fichiers au format XML utiliseront la balise additionnelle {Scenario} … {/Scenario} et fourniront des prévisions probabilisées : <PProbPrev> … </PProbPrev><ResProbPrev> … </ResProbPrev>.
Irstea – centre d’Antony 1, rue Pierre-Gilles de Gennes CS 10030
92761Antony Cedex tél. +33 (0)140966121 fax +33 (0)140966225 www.irstea.fr