Learning to be attractive: probabilistic computation with dynamic attractor networks
Texte intégral
Figure
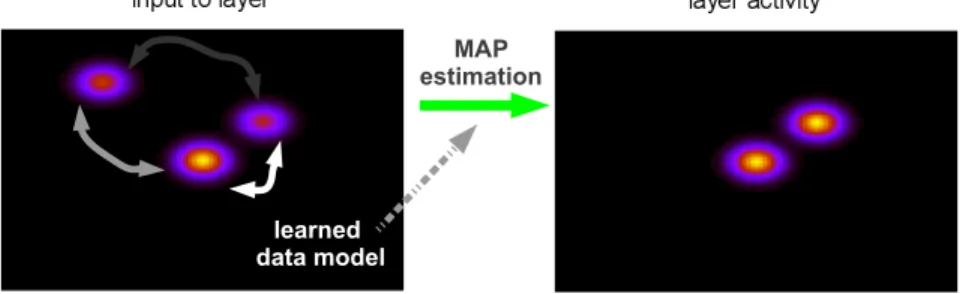
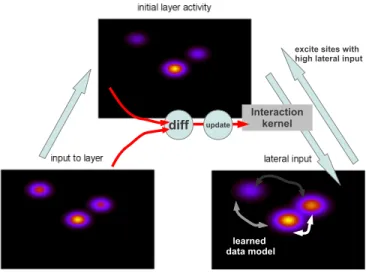
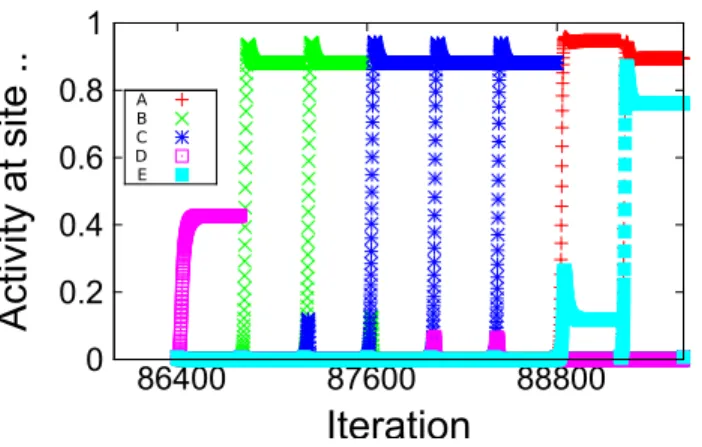
Documents relatifs
Finally, the condition numbers for the hidden representations and weights of the models are computed using the ratio of the maximum singular value to the minimum singular value..
Lu, QF, Cao, ZT & Ritchie, E 2004, ‘Model of Stator Inter-turn Short Circuit Fault in Doubly-fed Induction Generators for Wind Turbine’, 35th Annual IEEE Power
With our proposal, we hope that researchers in the swarm intelligence field will con- sider the possibility of an incremental deployment of agents in the design of new
Une fois la détection des dé- fauts effectuée, l’étape suivante, dans notre processus de restauration de films, est la correction de ces défauts par inpainting vidéo, qui, comme
Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of
These terrestrial data are of great value to understand and model the spatial distribution of various forest properties, among which the Carbon stock. They can also make a great tool
Figure 5: Repartition on heat exchanger with real com- ponent model and fins.. Figure 6: Repartition on heat exchanger with equivalent RC network and
As an application, from the universal approximation property of neural networks (NN), we de- velop a learning theory for the NN-based autoregressive functions of the model, where
