Mesure de similarité dans une ontologie pour l'indexation sémantique de documents XML
Texte intégral
Figure


Documents relatifs
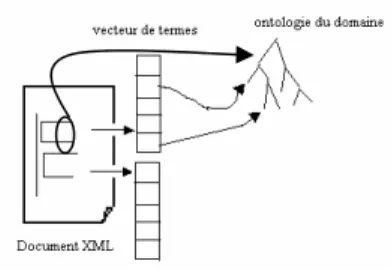
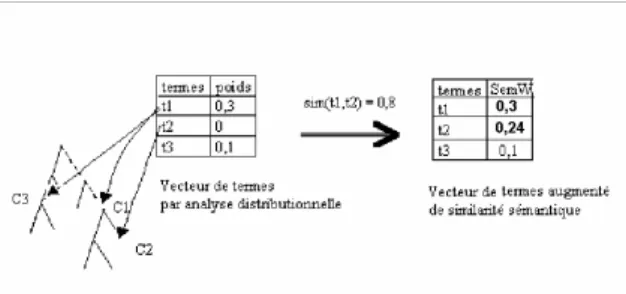
Cette phase de traitement sémantique par enrichissement du document, désormais partie intégrante du processus d’indexation sémantico linguistico statistique que nous noterons
D’autre part, l’idée principale de la métrique TagLink (Camacho et Salhi, 2006) est de considérer le pro- blème de comparaison de chaînes comme étant celui d’affectation,
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Or si ces derniers sont efficaces dans certaines requˆetes comme trouver une recette de cuisine ou le site Web d’une entreprise, ces outils ont plus de difficult´es avec des
Hence, when the two similarity matrices are built, each of them contains all the information needed to do a ‘separate’ co-clustering of the data (documents and words) by using
Ce sont des supports de cours mis à votre disposition pour vos études sous la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes
point un algorithme très eae de reherhe dans une base de données sonores.. qui démontre à la fois la ompatibilité des strutures salables ave
The discovery of frequent tree patterns from a huge collection of labelled trees is costly but has multiple applications, such as schema extraction from the web (or from frequent user
