A Discrepancy-Based Framework to Compare Robustness Between Multi-attribute Evaluations
Texte intégral
Figure
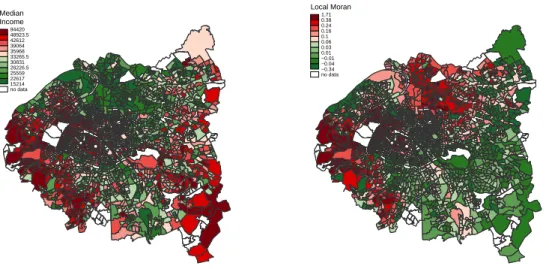
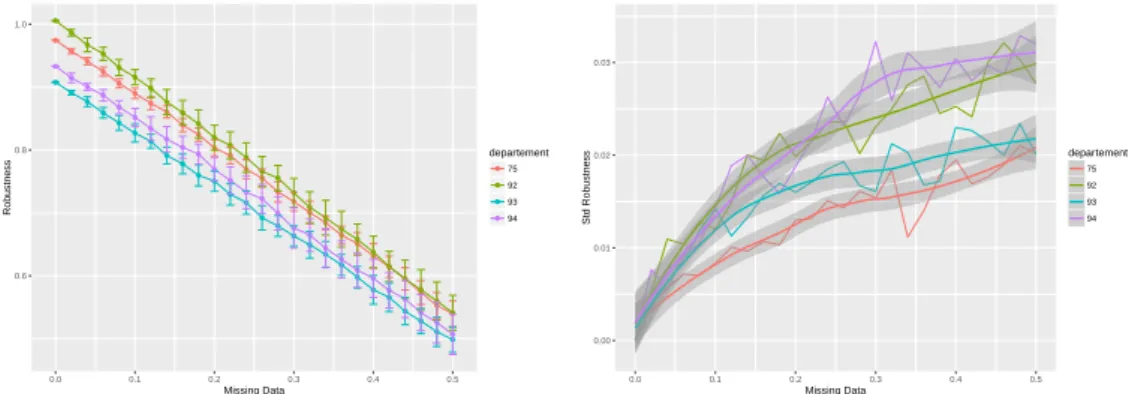
Documents relatifs
Abstract – This paper presents a new Time-frequency interleaving in a Multi-code Multicarrier CDMA MCMC-CDMA system, which allows two-dimensional spreading in both time and
As a consequence, in order to improve heat flux computation linked to soil water content, urban climate models are on one hand improving vegetation representation in cities
proposed a formalism based on hypergraphs to represent directed SoSs [14] but they did not provide generic mechanisms to ensure that the constitutive SoS characteristics are
Private involvement started when the 1959 law transformed water supply and sewerage services into utilities (service public industriel et commercial, SPIC) with
But the term cannot be accu- rately applied to the situation in the greater Paris metropolitan area, where, at the same scale, only 40% of immigrants from North Africa or
After all calculations are done main script automatically turns off C# script and then calls Python script, which creates statistics of processed data written in an output files to
A key issue of this analysis is the so–called FHA (Functional Hazard Analysis), which was performed in the test case first at the aircraft level, then applied to the
While the use of DSMLs is promising to model domains of this kind, traditional language architectures with one classification level only are confronted with serious problems, both
