Adaptive robust model predictive control for nonlinear systems
Texte intégral
Figure
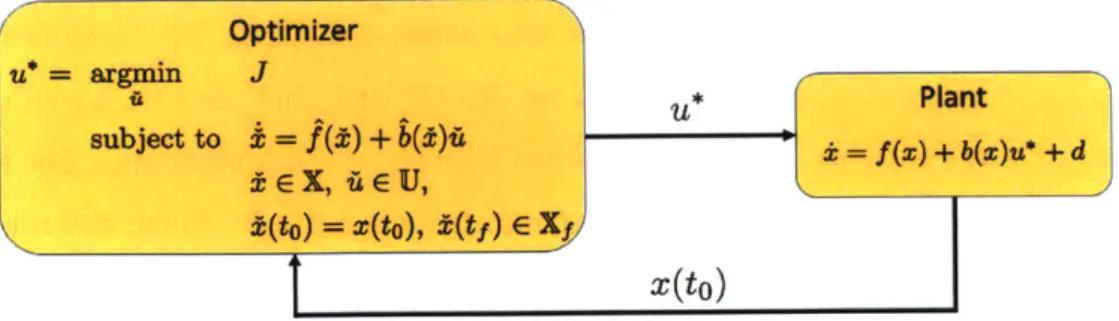

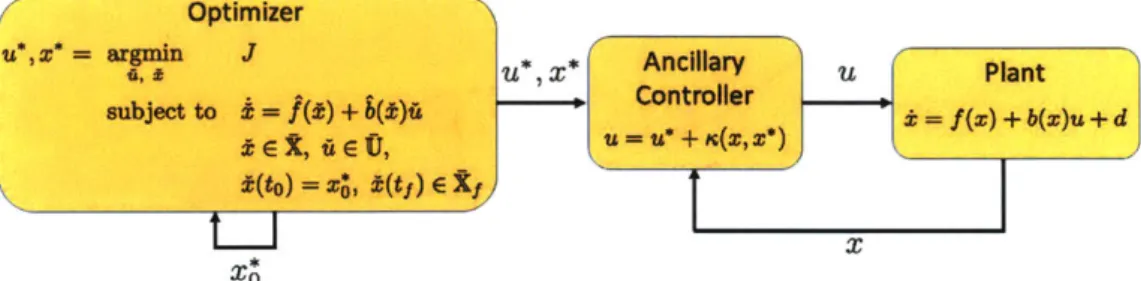
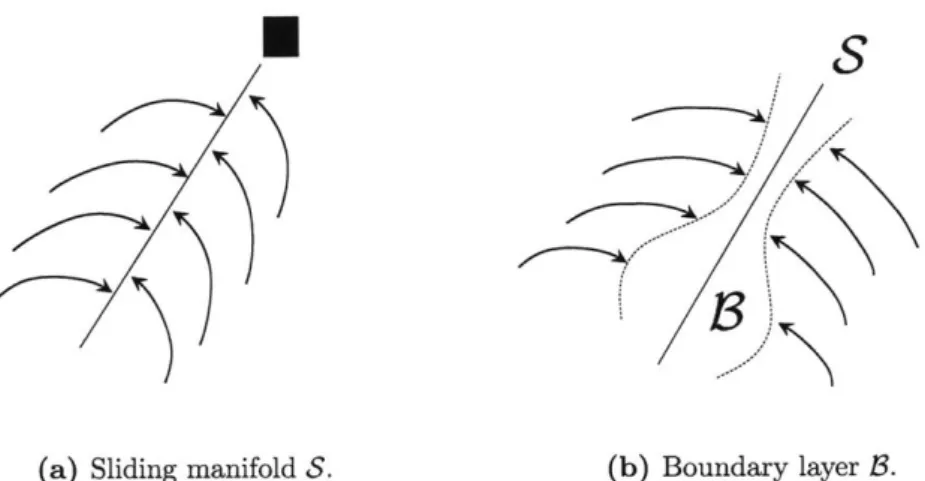
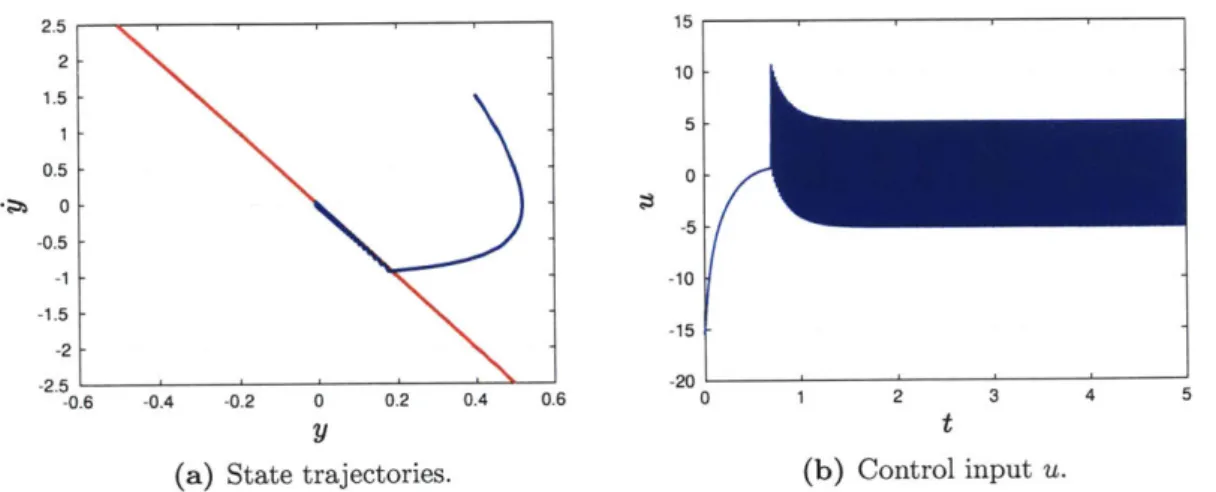
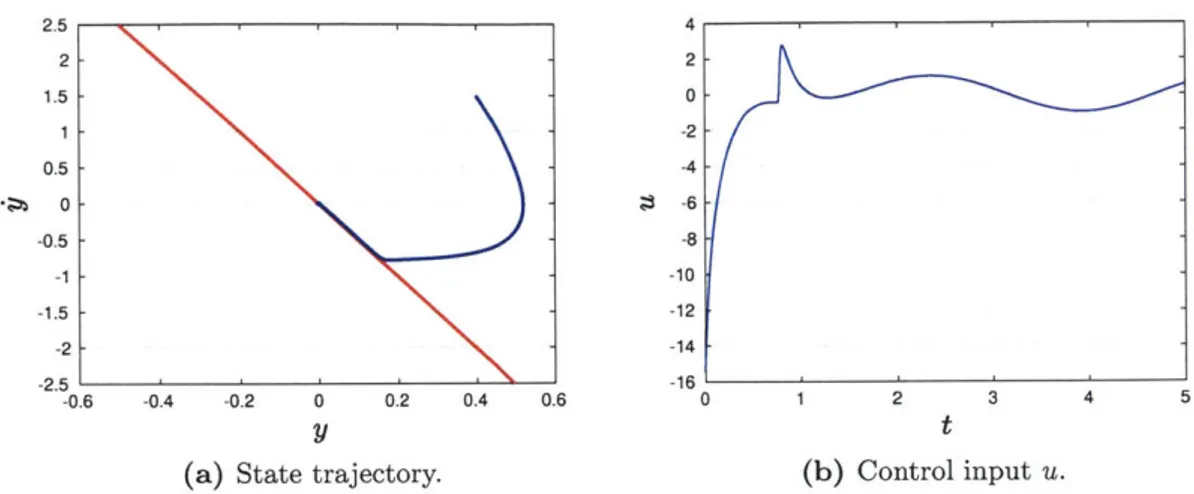
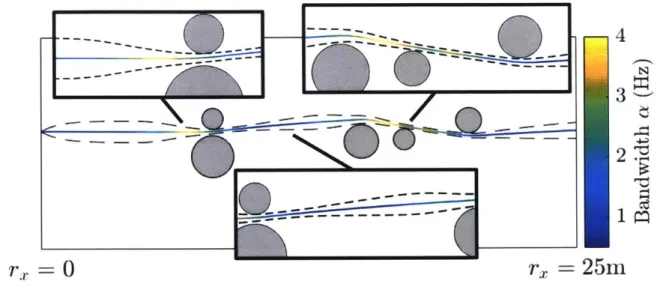
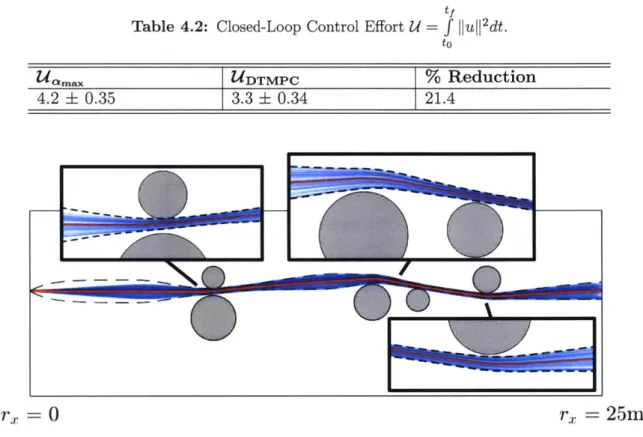

Documents relatifs
Perimeter gating control scheme using the Nonlinear Model Predictive Controller (NMPC) is developed to track the optimal green routing coefficient which will indirectly track
shown: (i) There is no advantage to be gained by using N > n in terms of the size of the domain of attraction; (ii) The maximal invariant ellipsoidal approximation of the domain
In this paper we explain the basic idea of NMPC together with some implementational details and illustrate its ability to solve dynamic decision problems in economics by means
5, we compare the performances obtained with the classical approach (i.e. tracking both compressor outlet and inlet manifold pressures reference trajectories) and
This system determines proper ecological velocity profile to improve safety and the cruising range based on the road geometry, traffic speed limit zones, and the preceding ve-
The accelerator and brake pedal positions are the inputs of the system, while the driving speed and the energy consumption are the outputs given by a dynamic vehicle model (based
A real-time nonlinear receding horizon optimal controller with approximate deadzone-quadratic penalty function was proposed to plan online the cost-effective velocity profile based
To validate this computa- tional efficiency, the computation time of the proposed modular control approach is compared with a standard nonmodular implementation in a pursuit scenario
