Top-k search over rich web content
Texte intégral
Figure
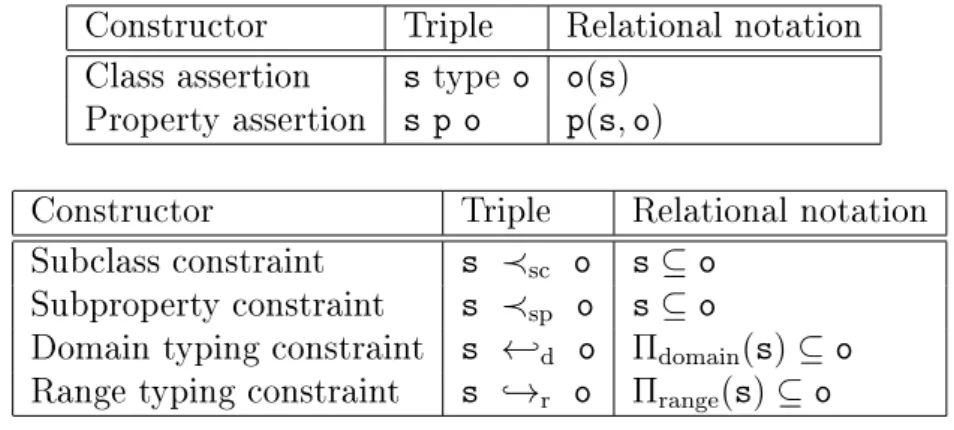
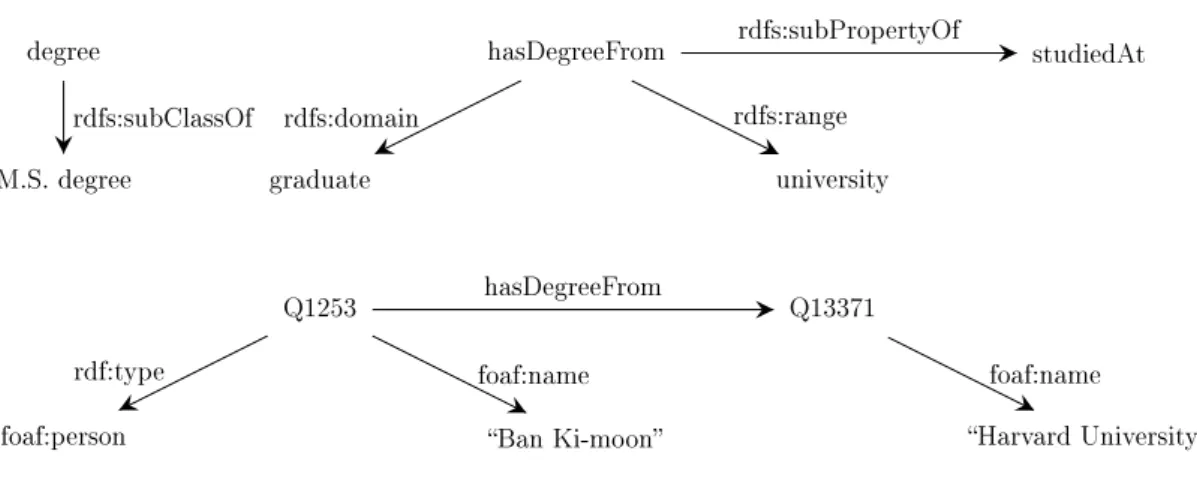

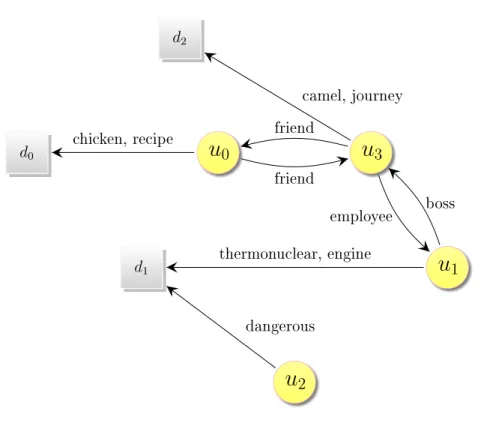
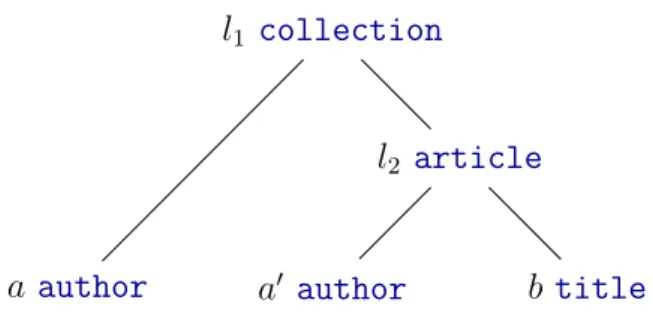
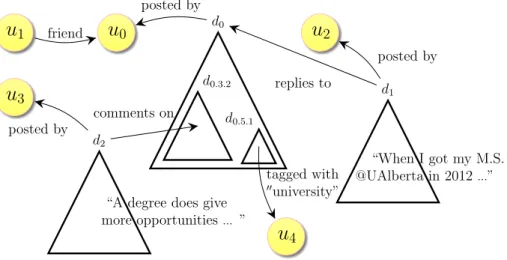

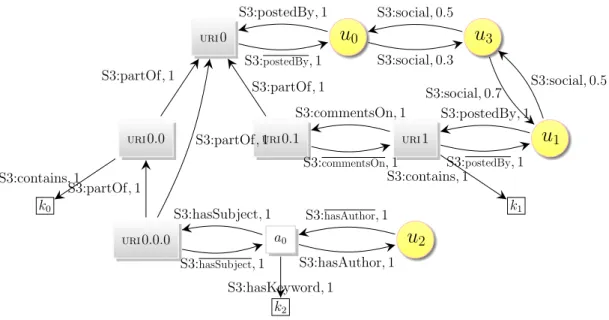
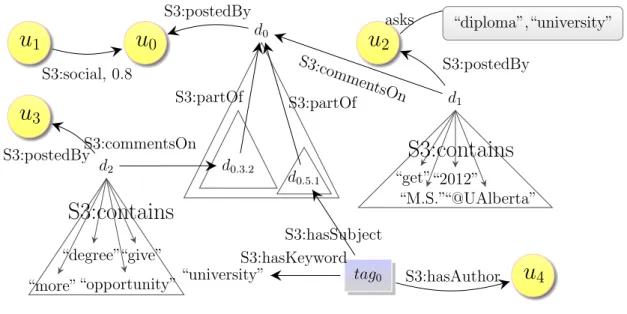
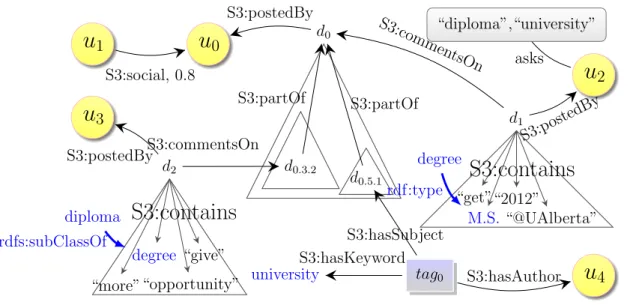
Documents relatifs
ICPSR). Institutions interested in understanding their output in terms of data thus face a challenging proposition: they need to be able to discover datasets across all
Next we demonstrate close and loose connections at the database level and their effects on keyword search in relational databases.. ASSOCIATIONS IN
Using input from [3], the current work focuses on integration and searching multiple open drug Linked Data sources for general information needs proposed by at least 25% of
For example the first attribute can be price represented by decimal numbers while the second attribute can be a manufacturer represented by strings (with
Data graph, keyword search, query, ranking, answer prior, virtual
This paper describes preprocessing workflow of the analysis system called Formal Concept Analysis Research Toolbox (FCART) and experiment of searching and
In order to avoid the need for users to specify a complex structured query upfront [2, 4] or for local free-text indexes to be built [5, 6], we propose an approach that combines
I wish you all a successful consultative meeting and look forward to receiving your recommendations to the national governments and the World Health Organization which will
