Ontology Enrichment by Discovering Multi-Relational Association Rules from Ontological Knowledge Bases
Texte intégral
Figure

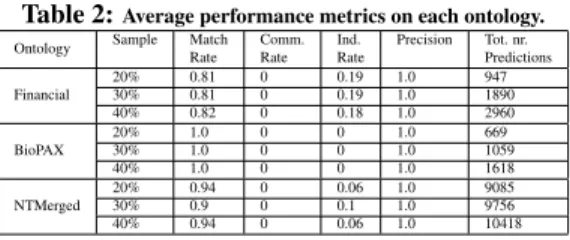
Documents relatifs
The proposed approach consists in using the association rules for the enrichment of an existing ontology, by applying the Apriori algorithm.. Our approach goes through the
In Section 4, we de- scribe our approach, named Videam platform (VIsual DrivEn dAta Miner), and we explain how the visualization can drive the different steps of the data mining
Document 3 : Évolution de la concentration en dioxygène en fonction du temps dans une suspension de mitochondries.. 400
Accès aux données. L’un des objectifs du service de partage de données est de garantir la cohérence des accès concurrents, alors que de manière interne la donnée est
Under idealized assumptions such as negligible node to node communication cost and uniform data item size, we have developed a framework for data redistribution across
Negotiations to remove tariffs on Environmental Goods (EGs) and Environmental Services (ESs) at the Doha Round, followed by negotiations towards an Environmental Goods Agreement
Standard approach is that we perform granulation of the chosen data set looking for the optimal granulation radius and at the end we generate new decision rules, where on the
Then, the key discovery tools VICKEY [3] and LinkEx are applied for the discovery of simple keys, conditional keys, and link keys from the instances of O 1 and O 2 , exploiting
