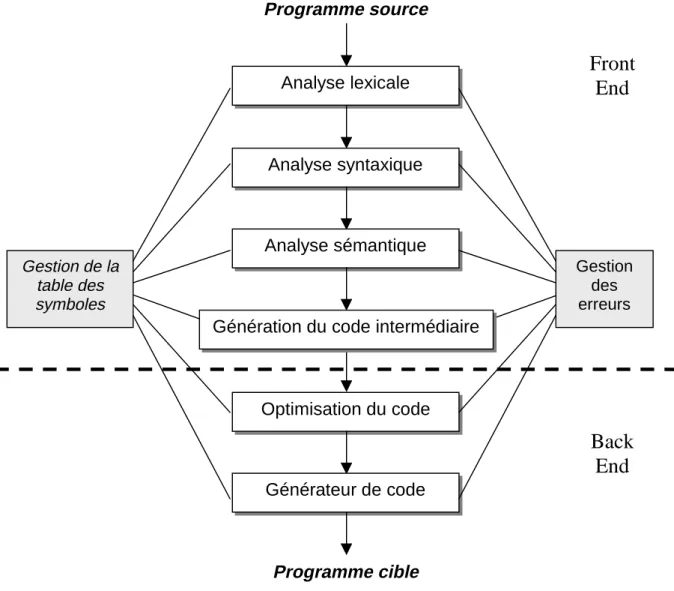
Méthode d'estimation de performance logicielle : application au développement rapide de code optimise pour une classe de processeurs dsp
Texte intégral
Figure
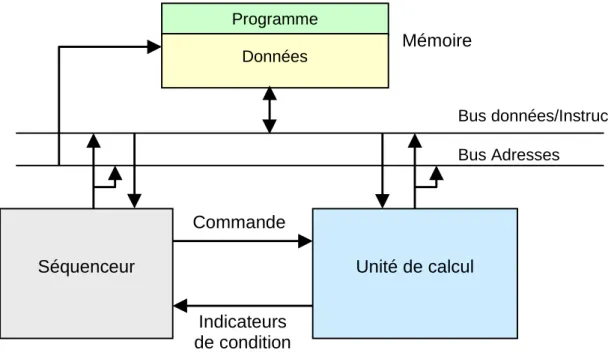
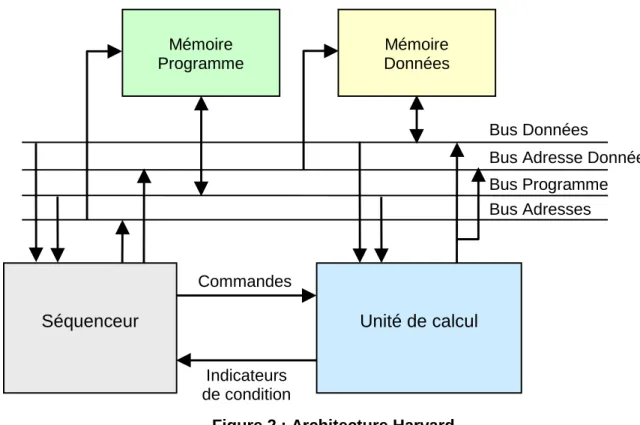
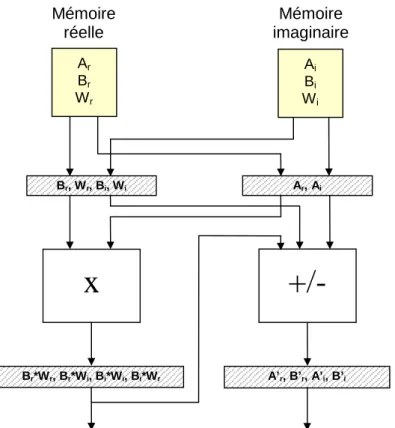
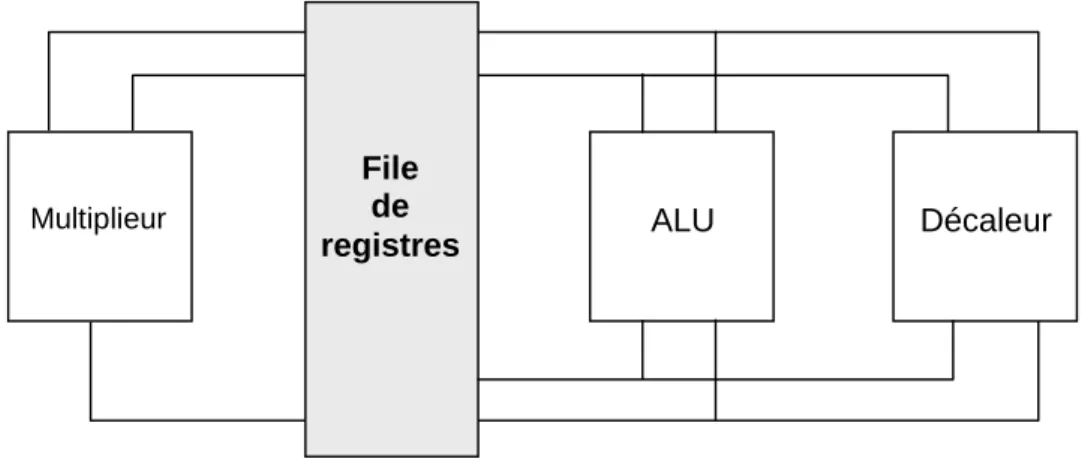
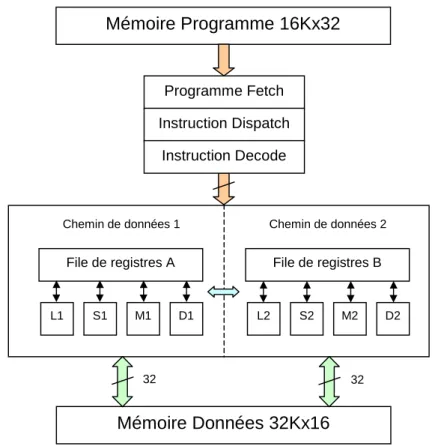
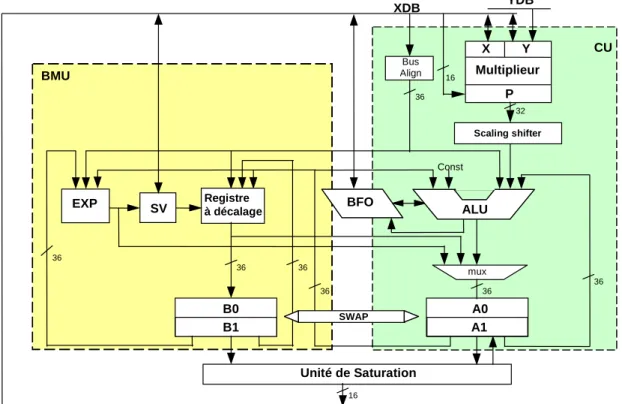
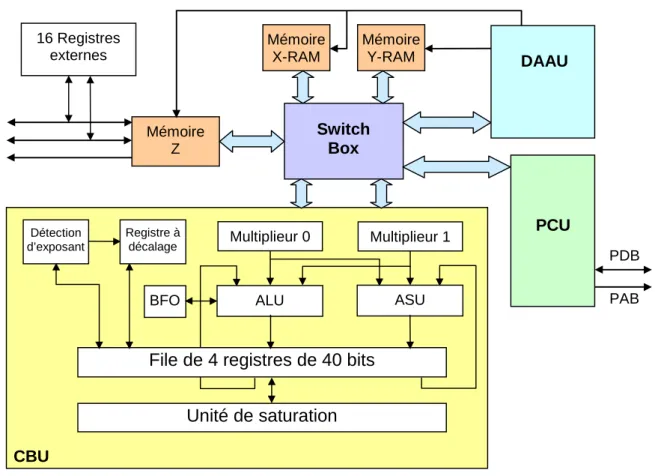
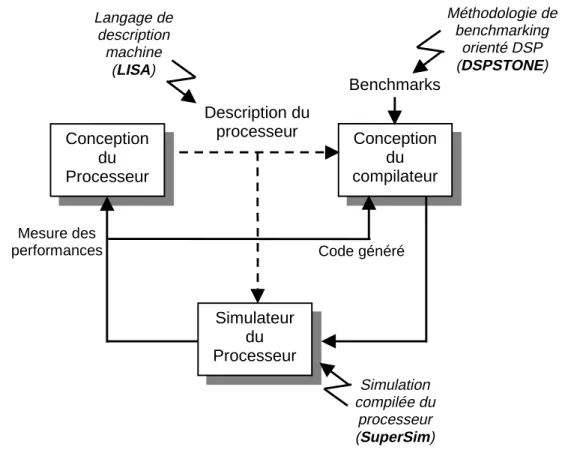
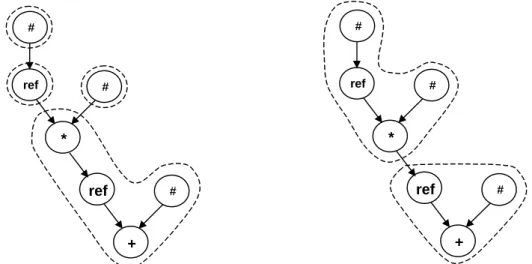
Documents relatifs
Il renseigne sur les caractéristiques démographiques et socioéconomiques des patients drainés dans le service et surtout de la prise en charge entreprise chez ces patients. Ainsi
code Java et code natif, propose également une nouvelle interface appelée Foreign Function Interface (FFI) [129] dont les principes de base an d'améliorer les performances sont
Diverses méthodes permettent d’estimer les paramètres y et a de la courbe de réponse et, parmi elles, la méthode de l’escalier (Stair-Case) dont on se propose de
En conclusion, cette étude a permis de faire des calculs tridimensionnels sur la chambre de combustion à haute température, en prenant en compte le phénomène de transfert de chaleur
Pour cette raison, le module de déformation de maillage existant dans NSMB a été intégré au code implémenté afin de pouvoir simuler le givrage par une méthode traditionnelle.
- Il existe plusieurs versions de Code::Blocks : préférez la version incluant MINGW (qui est le compilateur GCC pour Windows).. Choisir le langage C,
Parmi les présents, nombre de résidents différents ayant chuté au moins une fois au cours de l’année écoulée: 36 Nombre de chutes au cours de l’année écoulée : 133. Nombre
Ecrire une méthode boolean passage() qui renvoie true si l’élève peut passer dans la classe supérieure, c’est-à-dire si sa note est supérieure ou égale à
