Static and Dynamic Methods of Polyhedral Compilation for an Efficient Execution in Multicore Environments
Texte intégral
Figure
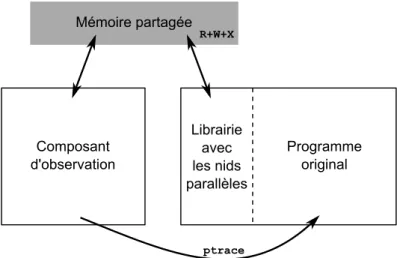
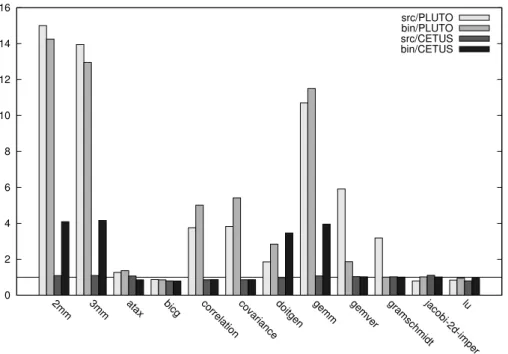
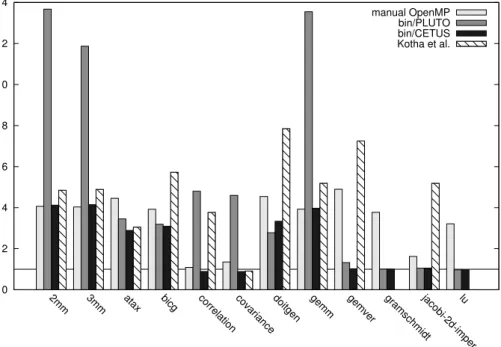




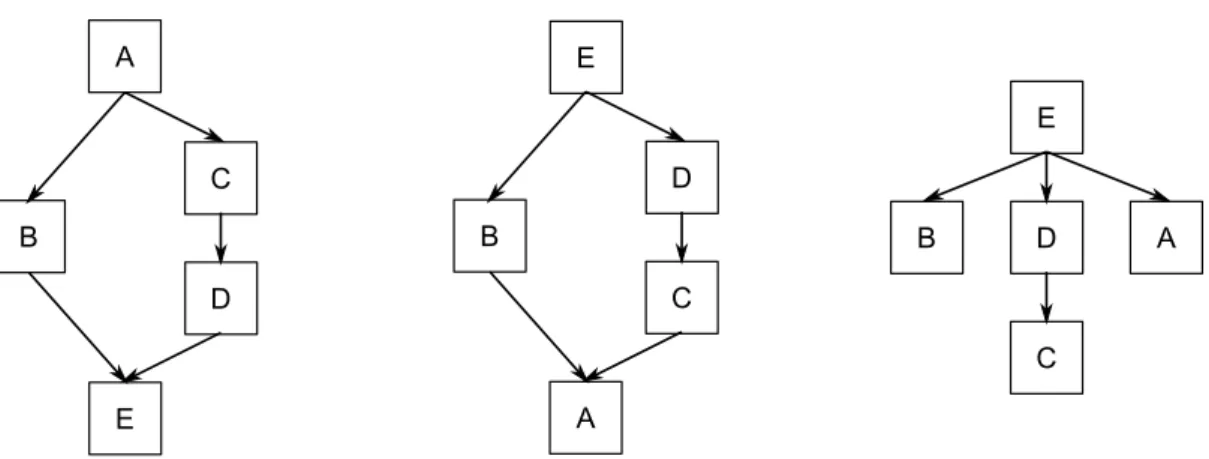

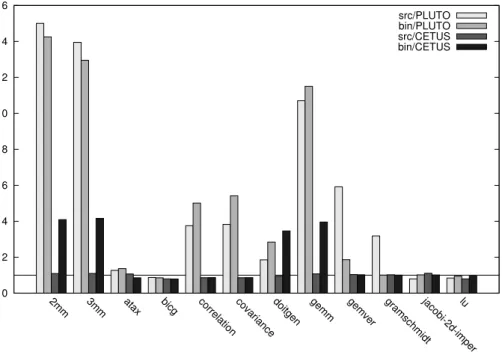
Documents relatifs
One important characteristic of image processing kernels is that they contain non static- affine code: non static-affine array accesses, non static-affine if conditionals and
The current approaches to automatic transformation in the polyhedral model are based either on linear programming (one-shot, best-effort heuristics of Feautrier [67] and
Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of
The key contributions are: separated specification of relations for semantics preservation, lo- cality and parallelism; schedule search space supporting arbitrarily large positive
In this paper, a refined Sinus beam finite element is evaluated for static bending, free vibration and transient dynamic response of FGPM beams.. This element is based on the Sinus
Anchored Nash inequalities and heat kernel bounds for static and dynamic degenerate environments.. Jean-Christophe Mourrat,
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
The translation of PCP to the polyhedral model requires computing the iteration domain and the schedule for each statement in a SCoP..
