HAL Id: hal-03197079
https://hal.archives-ouvertes.fr/hal-03197079
Preprint submitted on 13 Apr 2021
HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires
Integrating and reporting full multi-view supervised
learning experiments using SuMMIT
Baptiste Bauvin, Dominique Benielli, Cécile Capponi, François Laviolette
To cite this version:
Baptiste Bauvin, Dominique Benielli, Cécile Capponi, François Laviolette. Integrating and reporting full multi-view supervised learning experiments using SuMMIT. 2021. �hal-03197079�
Integrating and reporting full multi-view supervised
learning experiments using SuMMIT
Baptiste Bauvin, Dominique Benielli, Cecile Capponi, Fran¸cois Laviolette
April 13, 2021
Abstract
This paper introduces the first stable release of SuMMIT, a software offering many facilities for running, tuning, and analyzing experiments of supervised classification tasks on multi-view datasets. We present the main supported use cases of SuMMIT – including hyper-parameters optimization –, demonstrating the usefulness of such a platform for deal-ing with the complexity of multi-view benchmarkdeal-ing which has not been addressed so far. SuMMIT is powered by python3 and scikit-learn, making it easy to use and extend by adding new algorithms, score functions and new features1.
1
Introduction
The software presented in this paper deals with learning the best multi-view supervised model h from a dataset S = {xi, yi}ni=1, xi ∈ X , yi ∈ Y, i.i.d.
from an unknown distribution D over X × Y. In Python’s world, there exists many valuable libraries for handling experimental studies in supervised classification [6] with mono-view dataset, where each sample x must range in one description space x ∈ X (mono-view setting). These libraries come with facilities for performing wide range model selection through dedicated pipelines. In the multi-view setting, X is actually divided in V ≥ 2 description spaces (or views, or modalities): X = X(1)× · · · × X(v). Because of their
heterogeneity, or of the underlying view’s joint distributions X(v)× Y are different (v = 1..V ), a simple merging of the views before learning the model might lead to inaccurate models, even if pre-processed. That simple merging
1
The full documentation is available at https://baptiste.bauvin.pages.lis-lab.fr/ summit/
is the early fusion approach to deal with multi-view learning problems. On the opposite, one may perform late fusion: one model h(v) is learned from each view v, afterwards the V models are somehow merged, usually through majority vote or linear combination. Alternatively to early and late fusion, the last decades have produced multi-view supervised learning algorithms for taking advantages of diversity and complementarity among views. Many of them build a set of T base classifiers and the parameters of their combinations, such as kernel-based MKL [1]), Multi-view Machines [2] or MVML [4], boosting-based Mumbo [5], SharedBoost [7], etc. The more views one considers, the more hyper-parameters she has to tune because of the base classifier hyper-parameters which are not shared among the views.
Choosing the right model with the right hyper-parameters for a task is crucial to obtain relevant results. Indeed, some tasks require specific multiview algorithms, while others are well handled by naive early or late fusion. Moreover, depending on the data, some of the available views can in fact lower the performance of the models. SuMMIT is the first integration tool that allows investigators to fine tune and run many multi-view models at once, together with first-level hyper-parameter optimization, and visual comparison of user-selected performance measures. Moreover, if the right model is not in the available pool, SuMMIT has been developed to easily allow to add one’s own algorithms to its workflow.
This paper first focuses on the main functionalities of SuMMIT by covering its basic usage and more complex features. Then it concentrates on the technical aspects of SuMMIT’s implementation and opens up to promising future work and collaborative development.
2
Discovering SuMMIT functionalities
This section is a journey of discovery on the functionalities of SuMMIT. For illustration purpose, the well-known MNIST supervised classification task is considered [3], where images of digits from 0 to 9 are all splitted in three views: each view being 4 random orientations of a 12-orientations HOG on the images. SuMMIT is coded in Python3 over the scikit-learn machine learning library, thus integrates many supervised algorithms and metrics of it through a mapping table.
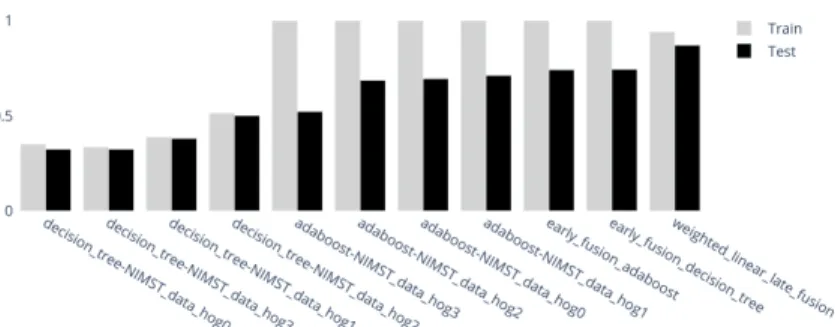
Figure 1: A .png version of the interactive accuracy scores bar plot for Adaboost, Decision Tree (on each view and on their early fusion), late fusion of the mono-view classifiers, for solving the now multiview MNIST multi-class learning task.
2.1 Launching a simple multi-view experimental protocol for
classification
Given a supervised classification task over a multi-view dataset, the first trivial usage of SuMMIT is to set up, run, then compare the accuracies of several learning processes using various on-the-shelf algorithms on each view, together with these algorithms in the early fusion setting, and eventually with the resulting late fusions of possible combinations. It is a way to get a first insight in the information carried by each view for solving the learning problem. The setting up is easily specified in a yaml configuration text file, the runs are executed locally, and the results are saved. SuMMIT also outputs an interactive bar plot 2 showing the requested scores of each algorithm in ascending order.
As an illustration on MNIST, the investigator wants to compare the accuracy of (1) decision tree and adaboost classifiers on each view and on their early fusion with default hyper-parameters, and (2) the weighted linear late fusion of the mono-view predictors. This can be encoded as:
n a m e : [" m u l t i v i e w _ m n i s t "] # Name of the dataset file t y p e : [" m u l t i v i e w " , " m o n o v i e w "] # Type of analysis a l g o s _ m o n o v i e w : [" d e c i s i o n _ t r e e " ," a d a b o o s t "] # Monoview algorithms a l g o s _ m u l t i v i e w : [" e a r l y _ f u s i o n _ a d a b o o s t " , # Multiview algorithms " e a r l y _ f u s i o n _ d e c i s i o n _ t r e e " , " w e i g h t e d _ l i n e a r _ l a t e _ f u s i o n "] 2 http://baptiste.bauvin.pages.lis-lab.fr/summit/tutorials/example1.html# accuracy-score-html-accuracy-score-png-and-accuracy-score-csv
Figure 1 is one of multiple outputs from SuMMIT execution on the con-figuration file above. The concon-figuration file allows the user to indicate the performance measures to be considered, among the main scalar classification metrics.
Stepping further in the integration facilities of SuMMIT, several multi-view algorithms other than early and late fusion can in turn be specified either as algos multiview. That way, the relevance of these multi-view algorithms on the dataset can be compared to more traditional approaches. The following configuration file indicates that early and late fusion of Adaboost must be compared with the Mumbo algorithm [5] according to scikit-learn’s accuracy and F1 scores.
t y p e : [" m u l t i v i e w " , " m o n o v i e w "] a l g o s _ m o n o v i e w : [" a d a b o o s t "]
a l g o s _ m u l t i v i e w : [" e a r l y _ f u s i o n _ a d a b o o s t " , " l a t e _ f u s i o n " , " m u m b o "]
m e t r i c s : # The metrics configuration
a c c u r a c y _ s c o r e : {} # Accuracy with default configuration
f 1 _ s c o r e : {} # F1-score with default configuration
SuMMIT also allows an interpretation of the decision processes, through a summary file for each classifier, and a graphical representation.
2.2 Optimizing hyper-parameters and reproducible results
As SuMMIT main use is to set baselines on new tasks, it includes two hyper-parameter optimization methods: a grid search and a randomized search (attribute hps type of the configuration file), based on prior hyper-parameter distributions. Both methods are combined with k-fold cross-validation to validate the hyper-parameters. As this process can be costly for big datasets or time-consuming learning algorithms, SuMMIT outputs a report for each classifier, giving the best hyper-parameter’s set, so one can re-use it without the optimization process in future benchmarks. These features are adaptations of the existing code from scikit-learn. The hyper-parameters available for tuning are predefined for each integrated mono and multiview algorithm but can be overwritten in the configuration file.
SuMMIT is configured thanks to an easily shareable file which is saved in each result directory and all the random number generators are controlled by a seed given in the configuration. As a consequence, SuMMIT allows to reproduce any benchmark by simply sharing the result directory.
The following configuration calls a randomized search with 30 draws for each classifier with 5 folds cross-validation and a random seed of 42.
h p s _ t y p e : " R a n d o m " # Type of hyper-parameter optimization method
n b _ f o l d s : 5 # Number of cross-validation folds
h p s _ a r g s : # Hyper-parameter method configuration
n _ i t e r : 30 # Number of random draws for the random search
2.3 Plugging a new multi-view algorithm
Finally, it is simple to add algorithms to SuMMIT, allowing to challenge the baseline with one’s own algorithm(s). Indeed, the provided classifier pool in the master branch is generic, but specific algorithms can be added to solve peculiar tasks (sparse decision functions, imbalanced datasets, etc.). To add a new multiview algorithm to SuMMIT the user must add a python file named after the classifier to the summit/multiview/multiview classifier, in
which he has to implement an adaptation class that inherits the BaseMultiviewClassifier class, and that provides fit and predict methods and the hyper-parameter
distributions for the classifier. An example of an hypothetical new classifier is given in Appendix A, similarly for a monoview classifier in Appendix B. We strongly encourage sharing your implementations, to durably include them in SuMMIT.
2.4 Use case
A user of SuMMIT wants to process a supervised classification learning task over a highly imbalanced multi-class 7-views dataset saved in the imba dataset.hdf5 file. She/he has in hand an implementation of µMumbo algorithm where yyy is one hyper-parameter to be tuned, and wants to compare its raw performances with methods provided with SuMMIT, where the accuracy score is to be optimized. After adding µMumbo to the multiview classifier pool, she/he writes the following configuration file, that will run one random forest for each of the seven views and its early fusion and late fusion derivates alongside MVML and µMumbo over the entire multiview dataset. n a m e : i m b a _ d a t a s e t t y p e : [" m u l t i v i e w " , " m o n o v i e w "] a l g o s _ m o n o v i e w : [" r a n d o m _ f o r e s t "] a l g o s _ m u l t i v i e w : [" r a n d o m _ f o r e s t _ e a r l y _ f u s i o n " , " l a t e _ f u s i o n " , " m u m u m b o "] m e t r i c s : a c c u r a c y _ s c o r e : {} r a n d o m _ s t a t e : 1 0 0 2
h p s _ t y p e : " G r i d " # Use a grid search to optimize the hyper-parameters
m u m u m b o : # Concerning µMumbo yyy : [0 ,1 ,2 ,3 ,4 ,5] # Explore these values for param "yyy"
2.5 Implementation of collaborative SuMMIT
SuMMIT development has been performed using continuous integration with Docker and automated tests, covering 93% 3 of the code. It is available under MIT license on Gitlab4 to allow collaborative development and hosting the automated Sphinx documentation and examples5. The installation of the platform and its requirements is done thanks to the following lines in a terminal
$ git clone https :// gitlab .lis - lab .fr/ baptiste . bauvin / summit . git
$ cd s u m m i t
$ pip install -e .
2.6 Towards additional functionalities
This paper presents the first release of SuMMIT. As a consequence, it comes with some limitations that could be alleviated through a deeper coupling with scikit-learn or other data science libraries. Firstly, SuMMIT can be used with multiple purposes, but one has to be aware that running multiple algorithms with cross-validated hyper-parameters optimization on very high dimensional data can take sizable resources. Indeed, a mono-view algorithm on a dataset with V views, and with k-folds cross-validation will be fitted V × (k + 1) times for each train/test split. Next, HDF5 is a very interesting input format as it allows to save memory by loading the views dynamically from the hard drive disk, but it lacks interactivity and we aim at authorizing pandas DataFrame as input, considering their growth in popularity. Finally, SuMMIT is currently dedicated to supervised classification. An upgrade for handling regression tasks is easy to produce for it would only require to add relevant performance measures and algorithms in the mapping tables.
The best way to improve SuMMIT is to build a user community that will be able to add functionalities based on their needs in order to collaboratively develop the project in the most interesting direction.
3 http://baptiste.bauvin.pages.lis-lab.fr/summit/coverage/index.html 4 https://gitlab.lis-lab.fr/baptiste.bauvin/summit 5 http://baptiste.bauvin.pages.lis-lab.fr/summit/
3
Conclusion and future work
SuMMIT is an easy handling platform that allows first insights in model selection for multiview problems. Thanks to its plug and play architecture, it can be used to assess the relevance of innovative multiview algorithms compared to usual approaches. Moreover, it is built on the robust sklearn framework and thanks to its public availability on Gitlab and its continuous integration with Docker, it can be easily collaboratively developed with very small risk.
We are currently working to improve SuMMIT on several levels, as parallelization and GPU interface to accelerate the benchmarks. To be more broadly used, it also might need a graphical interface, and basic and advanced data pre-processing, to be compatible with missing data, for example. Finally, we aim at providing a multiview generator compatible with SuMMIT to simulate specific problems.
References
[1] F. Bach, G. Lanckriet, and M. Jordan. Multiple kernel learning, conic duality, and the SMO algorithm. In International Conference on Machine Learning (ICML), pages 41–48, 2004.
[2] B. Cao, H. Zhou, G. Li, and P. S. Yu. Multi-view machines. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, WSDM ’16, page 427–436, New York, NY, USA, 2016. Association for Computing Machinery.
[3] D. Dua and C. Graff. UCI machine learning repository, 2017.
[4] R. Huusari, H. Kadri, and C. Capponi. Multi-view metric learning in vector-valued kernel spaces. In A. Storkey and F. Perez-Cruz, editors, Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine Learning Research, pages 415–424, Playa Blanca, Lanzarote, Canary Islands, 09–11 Apr 2018. PMLR.
[5] S. Ko¸co and C. Capponi. A boosting approach to multiview classification with cooperation. volume 6912, pages 209–228, 09 2011.
[6] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vander-plas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay.
Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
[7] J. Peng, C. Barbu, G. Seetharaman, W. Fan, X. Wu, and K. Palaniappan. Shareboost: Boosting for multi-view learning with performance guaran-tees. In D. Gunopulos, T. Hofmann, D. Malerba, and M. Vazirgiannis, editors, Machine Learning and Knowledge Discovery in Databases, pages 597–612, Berlin, Heidelberg, 2011. Springer Berlin Heidelberg.
A
Adding a multiview classifier
1 f r o m n e w _ m v _ a l g o _ m o d u l e i m p o r t N e w M V A l g o 2 f r o m .. m u l t i v i e w . m u l t i v i e w _ u t i l s i m p o r t B a s e M u l t i v i e w C l a s s i f i e r 3 4 f r o m .. u t i l s . h y p e r _ p a r a m e t e r _ s e a r c h i m p o r t C u s t o m R a n d i n t 5 6 c l a s s i f i e r _ c l a s s _ n a m e = " N e w M V A l g o C l a s s i f i e r " 7 8 c l a s s N e w M V A l g o C l a s s i f i e r ( B a s e M u l t i v i e w C l a s s i f i e r , N e w M V A l g o ) : 9 10 def _ _ i n i t _ _ ( self , p a r a m _ 1 =50 , 11 r a n d o m _ s t a t e = None , 12 p a r a m _ 2 =" e d g e ") : 13 B a s e M u l t i v i e w C l a s s i f i e r . _ _ i n i t _ _ ( self , r a n d o m _ s t a t e ) 14 N e w M V A l g o . _ _ i n i t _ _ ( self , p a r a m _ 1 = param_1 , 15 r a n d o m _ s t a t e = r a n d o m _ s t a t e , 16 p a r a m _ 2 = p a r a m _ 2 ) 17 s e l f . p a r a m _ n a m e s = [" p a r a m _ 1 ", " r a n d o m _ s t a t e ", " p a r a m _ 2 "] 18 s e l f . d i s t r i b s = [ C u s t o m R a n d i n t (5 ,200) , [ r a n d o m _ s t a t e ] , [" v a l _ 1 ", " v a l _ 2 "]] 1920 def fit ( self , X , y , t r a i n _ i n d i c e s = None , v i e w _ i n d i c e s = N o n e ) :
21 # T h i s f u n c t i o n is u s e d to i n i t i a l i z e the s a m p l e and v i e w indices , in c a s e t h e y are None , it t r a n s f o r m s t h e m in the c o r r e c t v a l u e s 22 t r a i n _ i n d i c e s , v i e w _ i n d i c e s = g e t _ s a m p l e s _ v i e w s _ i n d i c e s ( X , 23 t r a i n _ i n d i c e s , 24 v i e w _ i n d i c e s ) 25 n e e d e d _ i n p u t = t r a n s f o r m _ d a t a _ i f _ n e e d e d ( X , t r a i n _ i n d i c e s , v i e w _ i n d i c e s ) 26 r e t u r n N e w M V A l g o . fit ( self , n e e d e d _ i n p u t , y [ t r a i n _ i n d i c e s ]) 27
28 def p r e d i c t ( self , X , s a m p l e _ i n d i c e s = None , v i e w _ i n d i c e s = N o n e ) : 29 s a m p l e _ i n d i c e s , v i e w _ i n d i c e s = g e t _ s a m p l e s _ v i e w s _ i n d i c e s ( X , 30 s a m p l e _ i n d i c e s , 31 v i e w _ i n d i c e s ) 32 n e e d e d _ i n p u t = t r a n s f o r m _ d a t a _ i f _ n e e d e d ( X , s a m p l e _ i n d i c e s , v i e w _ i n d i c e s ) 33 r e t u r n N e w M V A l g o . p r e d i c t ( self , n e e d e d _ i n p u t )