i
République Algérienne Démocratique et Populaire
Ministère de l’enseignement supérieur et de la recherche scientifique
Université 8Mai 1945 – Guelma
Faculté des sciences et de la Technologie
Département d’Electronique et Télécommunications
Mémoire de fin d'étude
pour l’obtention du diplôme de Master Académique
Domaine : Sciences et Technologie
Filière : Télécommunications
Spécialité : Systèmes de Télécommunications
Régulation intelligente du trafic routier par des feux de
carrefours
Présenté par :
---
Chachoua Marwan Dhiya Eddine
---
Sous la direction de :
DR :Taba Mohamed Tahar
2019
ii
Remercîment:
First came first all the pleaser to ALLAH cause without his blessing and lessons giving to us in the time of need throw the Holy Quauran and his merci on people.
Secondly, I would like to thank my parents (med Abd Allah and Aicha) because this is the result of theme hard work and for my brother and sister (farouq and inas) for being by my side thanks a lot, for my man and my brother in blood Hamza for everything, for my uncles and aunties each by name and specially my uncles Lhadj Ahmed Mustapha,abd eldjalil for everything and I which that I will be able to return half what you did for me, to all my cousins and nieces to my grandmothers(lhadja fatna, fatim Zahra, lhadja Mbareka ) for theme prays end to my grandparent(lhadj Sliman, lhadj Allal) piece be on theme souls for theme priceless advices that draw my path throw a lot of difficult.to all my family chachoua and argillos time,to my brothers and my friends (Haouari a.k.a Yassin, Abd nour,Ilyas,Ghani,Marwan), to my brother in arme (Bilal, Abd elhalim) for being with each other in good and bad, for my friends back home to every one studied with us or still, to my special friend, nurse and the future writer behilil Rihab for all good and bad time.
To Siraj raval who helped me in an indirect way throws his online lessens to achieve this project to youcef Mégoura and Oussama Ati for theme help. To my teachers for pushing me to reach this point, and a special thanks to the research laboratory of 8 mai 1945 university in Guelma.
iii
Dédicace
To My family my friend and every one that help my in this travel to my beloved teacher Dr TABA and to the unknown
iv صيخلت ةلكشم يهو ةيمويلا انتايح يف اهعم لماعتلا انيلع نيعتي يتلا تلاكشملا ربكأ نم ةدحاو لح عورشملا اذه يف لواحنس يرورملا ماحدزلاا فرعنس "يب يريبسارلا " ةامسملا و عورشملا اذه يف ةلمعتسملا عطقلا مهأ دحأ شقاننس لاوأ م اهريضحت بجاولا روملاا ،اهعم لماعتن فيك،اهب ليغشتلا ماظن تيبثت لثم ةعطقلا هتاه لامعتسا لجأ ن "نايبسار" و اهريضحت بجاولا عطقلا ةجمربل يريبسارلا ىلا اهتفاضا اننكمي يتلا عطقلا نع ثدحتنس اذك ةريخلأا هتاه لجأ نم يب ةجمربلا ةغل نع لايلق لوانتنس امك عقاولا ضرأ ىلع عورشملا ديسجت نوثياب ورشملا يف ةلمعتسملا ع ركذ عم OpenCV ,tensorflow ك .ةجمربلا يف ةلمعتسملا تابتكملا يعانطصلاا ءاكذلا نع ثدحتنس ايناث ا تايمزراوخلا و ةللاا ميلعت لجأ نم ةلمعتسملا قرطلا ديدحتلاب و كلذ يف ةعبتمل .يرورملا ماحدزلاا ةلكشم لح يف تايمزراوخلا هتاه هبعلتس يذلا رودلا شقاننس امك دحنس اريخأو رعي ام نع ث و تلالاا ىلع فرعتلا يف ةلمعتسملا قرطلا ،اهتانوكم ،اهتيهام " ءايشلأا تنرتنا "ب ف ف ةريخلاا ةقلحلاك هتاه هبعلتس يذلا رودلا نع ي ا شقاننس مث عورشملا نم جذامن عم هنراقن و يحاون ةدع نم عورشمل عقاولا ضرأ Opencv, tensorflow, AI, Raspberry Pi :ةيحاتفملا تاملكلا summary
In this project we are going to try to solve one of the greatest problems that we have to deal with in our daily life which is the traffic problem.
We are going to Talk about the raspberry pi what to do with it, how to use it and the kit tool that can be plugged to it, also we will talk about how we can access and control those devices throw the Raspbian OS and throw a programming language which going to be python, and also we will discuss the role of raspberry pi in this project.
From another side we will treat one of the revolutionary science branches which is the Artificial intelligence in which we will see the methods the models and the algorithms used in this domain and the one that we need to realize our project.
And finally, we will see what is the IoT how it works and her characteristic which will be the missing ring for the final project in which we will discuss the project structure, components and they method used in order to solve the trafic problem followed with some examples of the methods.
Key word: Opencv, tensorflow, AI, Raspberry Pi
Résumé :
Dans ce mémoire nous allons proposer une solution pour le problème de congestion des carrefours aux niveau des villes.
Pour se faire sa nous avons utilisé la carte raspberry pi modèle B+ qui est le plus la plus important composant dans le projet. Les kits nécessaires à la programmation et le langage de programmation Python avec les Library utilisé come tensorflow opencv...etc
En second lieu, nous nous intéresse à l’apprentissage automatique, ces technique et le rôle d’apprentissage automatique dans notre projet.
Enfin, nous représentons l’internet des objets comme la partie réseau dans notre projet, pour contrôle le trafic routier.
v Puis on s’intéresse sur l’apprentissage automatique, sur quoi est basée, les
techniques d’apprentissage utilisé pour crée un modèle, puis le rôle de l’apprentissage automatique dans le projet final.
vi
List des abbreviation:
AI: Artificial IntelligentARM: Advanced RISC Machines BSD: Berkeley Software Distribution DL: Deep Learning
GPU: Graphics Processing Unit
HDMI: High-Definition Multimedia Interface IDE: Integrated Development Environment IdO : Internet Des Objets
IoT: Internet Of Thinghs LoRa: Long Range
LPWAN: Low Power Wide Area Network M2M: Machine TO Machine
ML: Machine Learning
OPENCV: Open Source Computer Vision Library OS: Operating System
RAM: Random Access Memory
RCNN: Recursive Convolutional Neural Network RFID: Radio-Frequency IDentification
SD: Secure Digital SOC: System On Chip
SVM: Support Vector Machines USB: Universal Serial Bus
UIT : Union International de Télécommunication VGA : Video Graphics Array
vii
Sommaire
Remercîment: ... ii
Dédicace ... iii
Résumé : ... iv
List des abréviation: ... vi
Introduction Générale : ... 7
Chapitre I ... 9
Généralité sur la Raspberry Pi ... 9
I.1 Introduction : ... 9
I.2 Raspberry Pi ... 9
I.3 Historique ... 9
I.4 Comparaison entre Raspberry Pi est Les autre circuit : ... 10
I.4.1 Les diffèrent modèle de raspberry Pi ... 11
I.5 installation de la Raspberry Pi B+ : ... 11
I.5.1 Carte mémoire MicroSD : ... 11
I.5.2 Chargeur : ... 12
I.5.3 Monitor ... 12
I.5.5 Câble HDMI : ... 13
I.5.6 Clavier et souris : ... 13
I.5.7 System d’opération : ... 14
I.6 OPENCV : ... 17
I.6.1 Historique : ... 17
I.8 Python : ... 18
I.9 Philosophie de python ... 19
I.10 Pour Quoi Python ... 19
Conclusion : ... 19
Chapitre II ... 22
L’apprentissage automatique ... 22
II.1 Introduction ... 22
II.2 Apprentissage automatique : ... 22
II.3 Historique ... 23
II.4 Principe ... 24
viii
II.5.1 Apprentissage supervisé ... 24
II.5.2 Apprentissage non supervisé... 24
II.5.3 Apprentissage semi-supervisé ... 25
II.5.4 Apprentissage partiellement supervisé ... 25
II.5.5 Apprentissage par renforcement ... 25
II.5.6 Apprentissage par transfert ... 25
II.6 Les modèles : ... 25
II.6.1 Arbre de décision : ... 25
II.6.2 Machine à vecteurs de support ... 26
II.6.3 Réseau de neurones ... 26
II.7 Application : ... 37
II.8 Classification des objets :... 38
II.9 Les Méthode de classification :... 38
II.9.1 Méthode de Viola et Jones avec Haar : ... 38
II.9.2 Tensorflow : ... 38
II.9.3 YOLO : ... 38
Conclusion : ... 39
Chapitre III ... 41
L’internet des Objet ... 41
III.1 Introduction ... 41
III.2 Internet des objets ... 41
III.3 Historique ... 42
III.4 L’architecture de IdO ... 42
III.4.1 Les Objets ... 42
III.4.2 Le réseau ... 43
III.4.2.1 Les diffèrent technologie pour les réseaux ... 44
III.5 Régulation intelligente du trafic routier par des feux de carrefours ... 45
III.5.1 Les carrefours ... 45
III.5.2 Système de régulation intelligent ... 45
III.5.1.2 Raspberry Pi ... 46
III.5.1.3 Serveur ... 47
III.5.1.4 Application mobile ... 47
III.5.2 Energétique : ... 48
ix
Chapitre IV ... 51
IV.1 Introduction ... 51
IV.2 simulations d’un Perceptron ... 51
IV.3 Perceptron multicouche ... 52
IV.4 Classification en temp réel avec YOLO ... 54
Reconnaissance et commande des LED avec raspberry :... 56
L’application Mobile ... 57
Conclusion ... 57
Conclusion Générale : ... 59
iv
Tableau de figure :
Figure I-1 : Raspberry Pi 3 model B+ ... 9
Figure I-2 : Raspberry Pi model A et Model zéro ... 10
Figure I-3 : image de carte mémoire de class 10 ... 11
Figure I-4 : Chargeur de V= 5V et I = 2 A ... 12
Figure I-5 : monitor Samsung avec desktop de Raspbian os ... 12
Figure I-6 : Câble HDMI ... 13
Figure I-7 : Adaptateur entre VGA et HDMI ... 13
Figure I-8 : clavier et souris ... 14
Figure I-9 : Bureau de Raspbian OS ... 14
Figure I-10 : capture d'écran prie de site lien précédent ... 15
Figure I-11 : capture d'écran de programme Etcher ... 15
Figure I-12 : bureau de Raspbian après l'installation ... 16
Figure I-13 : Symbole de Python ... 19
Figure II-1 : relation entre intelligence artificiel l'apprentissage automatique et l'apprentissage profond ... 23
Figure II-2 : exemple de l'arbre de décision ... 26
Figure II-3 neurones artificiels et biologique ... 27
Figure II-4 Neurone formel ... 28
Figure II-5 Exemple d’un Perceptron Multicouche ... 31
Figure II-6 Modèle de neurone j ... 32
Figure II-7 Variation de l’Erreur E en fonction des poids w ... 33
Figure II-8 collage de monalisa en plusieurs style ... 37
Figure II-9 exemple de classification des objets avec YOLO ... 38
Figure III-1 : schéma explicatif des diffèrent domaine qui utilise IdO ... 41
Figure III-2 : Evolution du nombre d’objet connecté de nos jours à 2020 ... 42
Figure III-3 : capteur de température ... 43
Figure III-4 : structure d'un system IoT ... 43
Figure III-5 : IP caméra sans fils avec un panneau solaire ... 46
Figure III-6 : moviduis myriad x développé par intel ... 46
Figure III-7 chronogramme de l'algorithme de détection de raspberry pi ... 47
Figure III-8 : chronogramme sur l'algorithme de projet ... 48
Figure III-9 : panneau solaire 45 watt avec ces kits ... 49
Figure IV-1 : relation entre les itérations et l'erreur ... 52
Figure IV-2 : le nombre des clicks par heure pendant un mois ... 53
Figure IV-3 : l'estimation avec des polynôme d'ordre 1,7 et 53 ... 54
Figure IV-4 : le principe de détection et reconnaissance de visage CNN ... 55
Figure IV-5 : Example de reconnaissance des objets avec YOLO ... 55
Figure IV-6 la 1ère image a gauche et 2eme a droite ... 56
Figure IV-7 : Schéma de montage ... 56
5
Liste des tableaux
Tableau I-1 comparaison entre les différentes cartes ... 10
Tableau I-2 : différent modèle et la date de réalisation de raspberry pi ... 11
Tableau I-3 : diffèrent Library composant OpenCV ... 18
Tableau III-1 : comparaison entre les diffèrent technologies ... 45
Tableau III-2 : nombre prix et la quantité des composant pour girer un carrefour ... 49
6
7
Introduction Générale :
L’être humain cherche toujours à trouver des solutions qu’il encontre dans la vie, l’un de ces problèmes et le trafic routier. Ce problème est dû au nombre croissant des voitures et au non flexibilité des systèmes qui gère les carrefours.
Dans notre projet nous allons utiliser l’intelligence artificielle pour la gestion des carrefours, Pour cela nous avons utilisé la carte raspberry dérnière génération (nevembre 2018) due vue sur cout et sa mise en œuvre.
Le travail demandé et de pouvoir gérer un carrefour par des carte raspberry Pi avec des caméra pour réguler le trafic urbain.
Dans le premier chapitre nous allons parler de la carte raspberry Pi et ces accessoires à savoir la souris, le clavier, le moniteur et la carte micro sd et son utilisation un mini-ordinateur.
Nous allons justifier le choix de cette carte rt non pas Arduino ou beagleboard et aussi nous parlons du système d’exploitation Raspbian, du python, et ces Library comme tensorflow et opencv…etc.
Dans le deuxième chapitre, nous exposons l’intelligence artificiel et plus précisément l’apprentissage automatique, les différentes méthodes d’apprentissage comme l’apprentissage supervisé, et les modèle d’apprentissage comme le réseau de neurone, la technique utiliser dans l’apprentissage et des exemples sur les domaines d’application de l’apprentissage automatique.
Le troisième chapitre contient une généralité sur l’internet des objets, la structure d’un réseau entre les objets et les différentes techniques utilisées pour la reconnaissance des objets dans le réseau puis nous assistants le projet final de point de vue des composant, Financial.
Dans le quatrième nous expose et interprété les résultats obtenus de l’application de raspberry pi, dans l’apprentissage automatique pour la reconnaissance des objets avec une démonstration sur une application mobile.
8
9
Chapitre I
Généralité sur la Raspberry Pi
I.1 Introduction :
Apres l’invention de premier transistor dans l’électronique ont a été capable à réduire et reproduire des machines en petit taille avec des performance très élevés comme l’ordinateur jusqu’au temp ou on a vue des micros et des nano ordinateur comme la raspberry pi.
Dans ce chapitre on va discuter un peu sur la raspberry pi avec ces composants et les technologies et le langage de programmation utilisé dans ce projet.
I.2 Raspberry Pi
Est un nano ordinateur mono-carte qui contient un processeur ARM crée par Pr Eben Upton est son équipe dans les laboratoires de recherche de l’université de Cambridge, elle comporte un processeur ARM, GPU, RAM, est d’autres ports comme HDMI, RG45(pas dans tous les modèles) est même des pins ou on accroche des autre composant comme une caméra, des détecteurs …etc.
Raspberry Pi utilise le model SOC ou System on chirp c’est-à-dire toute les composant précédant se trouve sur une seule carte ; ce nano ordinateur support Les system d’exploitation basé sur linux Debian est-elle confortable même avec Windows OS.
Figure I-1 : Raspberry Pi 3 model B+
I.3 Historique
L’idée de cette carte a été posé par Pr Eben Upton en 2006 au département d’informatique, comme une solution pour compenser le manque de compréhension et
10
maitrise de l’électronique pour les informaticiens. Enfin ils ont conclu qu’il faut crée des ordinateurs modifiables au côté d’électronique et avec un faible cout, de là l’idée de Raspberry a été créé, est après plusieurs essais ils ont été capable de lacer la première carte en 2012 qui été très petite en taille figure 1.2.
Figure I-2 : Raspberry Pi model A et Model zéro
I.4 Comparaison entre Raspberry Pi est Les autre circuit :
Le tableau ci dessue représente une comparaison entre les différentes cartes programmables dans le marché :
Nom Raspberry Pi BeagleBoard Arduino
Model B + X 15 R3
Prix 35$ 90-120$ 24$
Carte Soc ARM-cortex A58 ARM-cortex A8 ATMega 328
Vitesse 1.4GHz 1GHz 16-20MHz
RAM 1Gb 512Mb 12Kb
Mémoire Micro SD 2Gbit + Micro SD 32Kb
Tension 5v 5 V 5-17V
HDMI Oui Non Non
Langage de Programmation Supporté
Tous les langages qui peuvent compiler en Linux
Tous les langages qui peuvent compiler en Linux
Objective-C Embedded Scratch
11
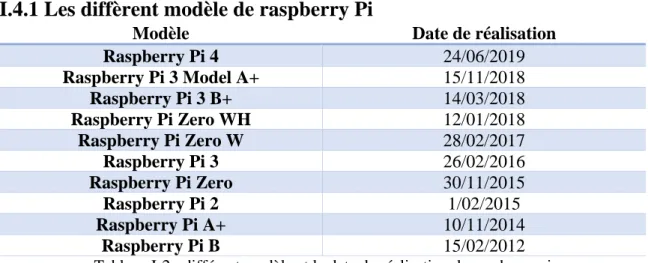
I.4.1 Les diffèrent modèle de raspberry Pi
Modèle Date de réalisation
Raspberry Pi 4 24/06/2019 Raspberry Pi 3 Model A+ 15/11/2018 Raspberry Pi 3 B+ 14/03/2018 Raspberry Pi Zero WH 12/01/2018 Raspberry Pi Zero W 28/02/2017 Raspberry Pi 3 26/02/2016 Raspberry Pi Zero 30/11/2015 Raspberry Pi 2 1/02/2015 Raspberry Pi A+ 10/11/2014 Raspberry Pi B 15/02/2012
Tableau I-2 : différent modèle et la date de réalisation de raspberry pi
I.5 installation de la Raspberry Pi B+ :
Pour démarrer une carte Raspberry Pi on est besoin de :
I.5.1 Carte mémoire MicroSD :
On utilise la carte mémoire puisqu’elle va contenir le System d’exploitation et les programmes que nous allons créer.
Il est préférable qu’elle soit avec une Capacité élevée (au minimum 16 GByte) et de bonne qualité puisque c’est dans cette carte mémoire va être utilisé comme disque dure où le système d’exploitation et les programmes crée vont être stocker et la vitesse de transmission de données entre la micro sd et le processeur doit être la plus rapide possible. Donc, il faut utilise une carte mémoire de classe élevée (minimum class 10).
12
I.5.2 Chargeur :
Comme on a vu dans Le Tableau précédent que la carte Raspberry Pi a besoin d’une alimentation de 5V/2A, avec un adaptateur micro USB
I = 2 A ; V = 5V
Figure I-4 : Chargeur de V= 5V et I = 2 A
I.5.3 Monitor
Pour afficher le desktop de la raspberry pi on utilise un monitor qui contient un port HDMI ou VGA.
13
I.5.5 Câble HDMI :
On cas où on veut utiliser la carte raspberry pi avec une télévision (LCD ou LED) il faut utiliser le câble HDMI car la carte raspberry contient un port pour ce type de câbles.
Figure I-6 : Câble HDMI
Pour les moniteurs avec port VGA, nous utilisons un adaptateur VGA et HDMI.
Figure I-7 : Adaptateur entre VGA et HDMI
I.5.6 Clavier et souris :
Pour la communication avec la carte raspberry Pi nous utilisons un clavier et une souris ordinaires avec entrer USB.
14
Figure I-8 : clavier et souris
I.5.7 System d’opération :
La carte raspberry pi nécessite un system d’exploitation pour sa gestion et qui permet d’accéder est gérer le côté matériel et les entrées sorties. Pour cela ce système est à base de linux qui s’appelle Raspbian [1]
Ce qui caractérise ce système c’est la capabilité de gérer le matériel raccorder à la carte d’une manière facile et il est open source.
Figure I-9 : Bureau de Raspbian OS
I.5.7.1 Préparation de Raspbian :
Après la préparation de tout le matériel présenter précédemment on peut passer à l’installation du system d’exploitation.
15
I.5.7.2 Téléchargement de system :
On accède à ce lien [1] d’où nous téléchargeons la dernière version de Raspbian la version NOOB est la plus complète.
Figure I-3 : capture d'écran prie de site lien précédent
I.5.7.3 Graver le OS sous la carte SD :
Le cas où nous voulons Installer une version différente de NOOB il faut graver l’OS sur la carte SD d’une manière spéciale. Pour cela nous insérons la carte sd dans le lecteur de carte du pc et nous utilisons un programme spécial comme Win32Image ou Etcher. On clique sur le bouton choisir une image est on choisit la version que nous avons télécharger sur le pc.
16
Quand cette opération est terminée nous insérons la carte SD sur la carte Raspberry Pi et nous connectons les autres périphériques (souris et clavier) et le câble HDMI enfin nous terminons par l’alimentation.
I.5.7.4 Installation du system :
Apres l’alimentation de la carte raspberry le system termine automatiquement la procédure de l’installation puis il affiche l’image du Bureau avec une petite plaque d’où on configure la langue d’affichage et le nom d’utilisateur.
Figure I-5 : bureau de Raspbian après l'installation
Raspbian desktop contient :
➢ Bar des taches comme dans Windows
➢ Un buton rassemble « démarrer » dans Windows qui contient une liste des listes des applications qui sont :
o List de programmation : qui contient des IDE pour aide à programmer dans plusieurs lagunages comme PYTHON, C/C++, JAVA.
o List d’office : qui contient des logiciels dédiés au traitement des donné de type texte.
o Liste des accessoires : d’où on Install les logiciels d’une manière graphique
17
une liste pour les navigateurs en internet.
➢ Elle a qu’un seul desktop (pas comme les autres versions de linux qui ont plusieurs).
I.5.7.5 Configuration :
C’est-à-dire l’activation ou la permission de gérer les périphériques est le port GPIO connecter avec la carte avec des programmes ou avec des codes implémenter à travers le terminal de Raspbian.
I.5.7.6 Mise à jour :
Il est nécessaire de faire une mise à jour chaque période pour l’OS pour s’assurer que tous les drivers marchent en bon état. Cela est exécuté comme suit :
sudo apt-get update sudo apt-get upgrade sudo apt-get dist-upgrade
I.6 OPENCV :
Puisque nous allons utiliser la carte raspberry pi B+ pour la reconnaissance des objets par une caméra cela nécessite un logiciel de capture et de pré traitement des images. Pour cela le meilleur programme le plus utilisé est OPENCV qui est doté d’une bibliothèque graphique réaliser sur la License BSD pour l’utilisation académique ou commercial, elle été développer par Intel au tour de 1999.
Nous l’utilisons le plus souvent pour le traitement d’image temp réel. Elle peut être utiliser sur n’importe quelle plateforme qui support C/C++, Java ou Python. [2]
I.6.1 Historique :
Intel a lancé le projet de OpenCV en 1999 pour crée un Library dédié au traitement des images, ce projet concerne les image 3D, traitement des images dans le temps réel …etc.
En 2000 la première version de OpenCV lancé au public sur le nom de ‘’ OpenCV Alpha’’ dans la conférence de IEEE, puis en 2006 OpenCV 1.0 a été lancé, puis on a vu plusieurs versions arrivant au 4.0.0 qui été publiée le 18.11.2018 sur toutes les platforms (Windows, Linux …etc.).
18
La Library Fonc(english) Fonctionnalité
Core Opencv core Noyau de OpenCV
imgproc Containe image
treatemente functions
Fonctions de traitement d’image
Imgcodecs Image input and output methodes
Les fonctions d’entrer et de sortie des images
Videoio Video reading and
writing
Fonctions capture de vidéos
Video Video treatement
methodes
Fonctions de traitement des vidéo
calib3 Image calibration and 3d object recognition
Calibration des caméras et la reconnaissance en 3D
features2d Features of 2d images Détermination des caractéristiques des image 2D. objdetect Object detection Détection des objets
Dnn Deep learning and
neurol network
L’apprentissage profond
ML Machine learning Apprentissage automatique
Flann Treatment of
multidimension image
Traitement
multi-dimensionnel
Photo Digital phtographie Photographie numérique stitching Stitching images Assemblage des images
Gapi Graph API Graphe api
Tableau I-3 : diffèrent Library composant OpenCV
I.8 Python :
Le Langage Python est utilisé dans notre projet par sa richesse en Library et sa souplesse de programmation. Il a été développer par Guido van Rossum au centre de recherche informatique et mathématique d’Amsterdam, Pays-Bas.
La première version de ce langage est apparue le 19 février 1991 qui peut être utiliser sur les différents OS comme Windows, Linux …etc.et il est possible de traduire le code de python dans plusieurs langages de programmation comme JAVA et C#,
La communité de ce langage et énorme due aux facilitées et la mobilité de ce langage.il est considéré comme le langage de programmation plus proche au langage humain. En 2018 Python a été considérer comme le langage de science due à ces Library qui permettent d’implémenter Python dans tous les domaines de science. Nous pouvons trouver python dans tous les domaines comme les logiciels les application Android, développement web …etc.
19
Figure I-13 : Symbole de Python
I.9 Philosophie de python
Après la création de python, Tim Peters qui un des développeurs de python à poster sur son compte Gmail ce que on appelle le « ZEN de python » ou la philosophie de python qui et un ensemble de lois utilisées pendant la création de python l’une de ces règles sont :
• Beau vaut mieux que moche. • Explicite est meilleur qu'implicite. • Simple c'est mieux que complexe.
• Les erreurs ne doivent jamais passer silencieusement.
• Si la mise en œuvre est difficile à expliquer, c'est une mauvaise idée. [3] Et autre règle qui détermine pour quoi python et un langage de programmation simple
I.10 Pour Quoi Python
Dans ce projet nous avons implémenté python car il est facile, ces codes ne sont pas très longs ou compliquer, il supporte les nouveaux domaines de recherche comme l’intelligence artificiel. La richesse en Library, et la capabilité d’exécuter les codes python sur les processeurs ARM.
Conclusion :
Comme on a vu la carte raspberry pi est un ordinateur crée pour donne la chance au n’importe qu’elle personne de réaliser ces projets et implémenter ces idées avec un bas cout.
La Library OpenCV est la plus utiliser dans le domaine de vision par ordinateur même en traitement d’image et qui sont utilisé surtout en Matlab(imshow,imread,imwrite).
20
Enfin, le choix de Python et du a sa simplicité d’implémentation sur une carte raspberry pi et que nous pouvons l’utiliser dans presque tous les domaines, due à sa richesse en librairies.
21
22
Chapitre II
L’apprentissage automatique
II.1 Introduction
L’invention des machines et des ordinateurs et faite pour faciliter la vie de l’être humain dans tous les domaines,
Malgré leur vitesse de calcule, les ordinateurs ne peuvent pas détecter et reconnaitre les objets dans une image et même prévoir le prix de quelque chose
L’avènement d’une nouvelle théorie appelée l’apprentissage automatique (en anglais machine learning) a permis de résoudre des problèmes tel que détection et reconnaissance des objets, réponse aux questions comme google assistance…etc.
Donc c’est quoi l’apprentissage automatique et quelles sont les méthodes utilisées ?
II.2 Apprentissage automatique :
L’apprentissage automatique (en anglais machine Learning, littéralement « l'apprentissage machine ») est un champ d’étude de l’intelligence artificielle, ce domaine utilise des Algorithmes basés sur les modèles statistiques utilisées à travers des ordinateurs pour performer un travail bien spécifique (classification, prédiction … etc.). On utilise des données fournies appelées « observations » qui sont disponible et en nombre fini.
On utilise ces modèles et la rapidité de calcule des ordinateurs avec les donné fournie pour estimer et prédire la fonction qui existe entre l’entrée et la sortie du système. Cela est dans le but d’avoir des réponses sur des nouveaux problèmes dans notre vie quotidienne comme la recherche dans GOOGLE, reconnaissance des personnes ou objets…etc.
23
Figure II-1 : relation entre intelligence artificiel l'apprentissage automatique et l'apprentissage profond
II.3 Historique
Le terme apprentissage automatique apparue pour la première fois dans les laboratoires de recherche de IBM entreprise par Arthur Samuel qui est un informaticien American pionnier dans le secteur de l’intelligence Artificiel et les jeux d’ordinateur en 1959 après qu’il a créé un jeu de Dames pour la même entreprise qui été capable a battre le 4e meilleur joueur aux États-Unis, mais avant ça l’idée d’apprentissage automatique a été présentée par Alan Turing dans son concept de la machine universel en 1936 puis en 1950 il a posé les bases de l'apprentissage automatique, avec son article [11] sur L'ordinateur et l'intelligence dans lequel il a développé le test de Turing qui consiste à mettre un humain en confrontation verbale à l’aveugle avec un ordinateur et un autre humain. D’où on considère que l’intelligence artificiel est bonne si il ne peut pas distinguer entre un homme ou machine.
En 1943, le neurophysiologiste Warren McCulloch et le mathématicien Walter Pitts publient un article [12] décrivant le fonctionnement des neurones en les représentant à l'aide de circuits électriques. Cette représentation sera la base théorique des réseaux neuronaux.
L’avance majeure a été faite par le super ordinateur Deep Blue développer par IBM en 1990 spécialiser sur le jeu d’échec qui est la première machine à vaincre le champion mondial d'échecs Garry Kasparov en 1997. Cette action représente l’étincelle qui lance un nouveau monde qui consiste à développer et entrainer les ordinateurs pour faire des actions qui ont été limitées exclusivement pour les êtres humains.
24
II.4 Principe
Les algorithmes utilisés permettent, dans une certaine mesure, à un système piloté par ordinateur, d’adapter ses analyses et ses comportements en réponse à l'analyse des données provenant d'une base de données ou de capteurs.
La difficulté réside dans le fait que l'ensemble de tous les comportements possibles compte tenu de toutes les entrées possibles devient rapidement trop complexe à décrire (on parle d'explosion combinatoire). On confie donc à des programmes le soin d'ajuster un modèle pour simplifier cette complexité et de l'utiliser de manière opérationnelle. Idéalement, l'apprentissage visera à être non supervisé, c'est-à-dire que la nature des données d'entrainement n'est pas connue.
Ces programmes, selon leur degré de perfectionnement, intègrent éventuellement des capacités de traitement probabiliste des données, d'analyse de données issues de capteurs, de reconnaissance (reconnaissance vocale, de forme, d'écriture…), de fouille de données, d'informatique théorique…
II.5 Types des Algorithme d’apprentissage :
Dans le domaine de l’intelligence artificiel il y a plusieurs méthodes qu’en peut utiliser pour permettre d’entrainer les ordinateurs, on peut distinguer quelques-unes comme :
II.5.1 Apprentissage supervisé
Si les classes sont prédéterminées et les exemples connus, le système apprend à classer selon un modèle de classification ou de classement ; on parle alors d'apprentissage supervisé. Un expert doit préalablement étiqueter des exemples. Le processus se passe en deux phases. Lors de la première phase, il s'agit de déterminer un modèle à partir des données étiquetées. La seconde phase consiste à prédire l'étiquette d'une nouvelle donnée, connaissant le modèle préalablement appris. Parfois il est préférable d'associer une donnée non pas à une classe unique, mais une probabilité d'appartenance à chacune des classes prédéterminées. Par exemple, en fonction de points communs détectés avec les symptômes d’autres patients connus, un système peut catégoriser de nouveaux patients au vu de leurs analyses médicales en risque estimé (ou la probabilité) de développer telle ou telle maladie. [4]
II.5.2 Apprentissage non supervisé
Quand un système ne dispose que d'exemples, mais non d'étiquettes, et que le nombre de classes et leur nature n'ont pas été prédéterminées, on parle d'apprentissage non supervisé ( clustering en anglais). Aucun expert n'est requis. L'algorithme doit découvrir par lui-même la structure plus ou moins cachée des données. Le partitionnement de données est un algorithme d'apprentissage non supervisé.
Le système doit cibler les données selon leurs attributs disponibles, pour les classer en groupe homogènes d'exemples. La similarité est généralement calculée selon une fonction
25
de distance entre paires d'exemples. C'est ensuite à l'opérateur d'associer ou déduire du sens pour chaque groupe et pour les motifs (patterns en anglais) d'apparition de groupes, dans leur espace. Divers outils mathématiques et logiciels peuvent l'aider. On parle aussi d'analyse des données en régression (ajustement d'un modèle par une procédure de type moindres carrés ou autre optimisation d'une fonction de coût). Si l'approche est probabiliste c'est-à-dire que chaque exemple, au lieu d'être classé dans une seule classe, est caractérisé par un jeu de probabilités d'appartenance à chacune des classes, on parle alors de « soft clustering ».
Cette méthode est souvent source de sérendipité. :Par exemple pour un épidémiologiste qui voudrait dans un ensemble assez large de victimes de cancer du foie tenter de faire émerger des hypothèses explicatives, l'ordinateur pourrait différencier différents groupes, que l'épidémiologiste chercherait ensuite à associer à divers facteurs explicatifs, origines géographique, génétique, habitudes ou pratiques de consommation, expositions à divers agents potentiellement ou effectivement toxiques [5].
II.5.3 Apprentissage semi-supervisé
Effectué de manière probabiliste ou non, il vise à faire apparaître la distribution sous-jacente des exemples dans leur espace de description. Il est mis en œuvre quand des données manquent. Le modèle doit utiliser des exemples non étiquetés pouvant néanmoins renseigner. Comme en médecine, il peut constituer une aide au diagnostic ou au choix des moyens les moins onéreux de tests de diagnostic [4].
II.5.4 Apprentissage partiellement supervisé
Probabiliste ou non, quand l'étiquetage des données est partiel. C'est le cas quand un modèle énonce qu'une donnée n'appartient pas à une classe A, mais peut-être à une classe B ou C telle que A, B et C étant 3 maladies par exemple évoquées dans le cadre d'un diagnostic différentiel [5].
II.5.5 Apprentissage par renforcement
L’algorithme apprend un comportement étant donné une observation. L'action de l'algorithme sur l'environnement produit une valeur de retour qui guide l'algorithme d'apprentissage [5].
II.5.6 Apprentissage par transfert
L’apprentissage par transfert peut être vu comme la capacité d’un système à reconnaître et appliquer des connaissances et des compétences, apprises à partir de tâches antérieures, sur de nouvelles tâches ou domaines partageant des similitudes [4]
II.6 Les modèles :
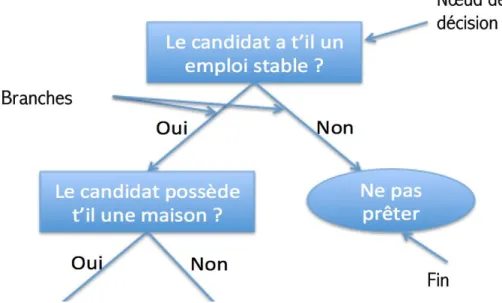
II.6.1 Arbre de décision :
Est un outil d'aide à la décision représentant un ensemble de choix sous la forme graphique d'un arbre. Les différentes décisions possibles sont situées aux extrémités des branches (les feuilles de l'arbre), et sont atteints en fonction de décisions prises à
26
chaque étape. L'arbre de décision est un outil utilisé dans des domaines variés tels que la sécurité, la fouille de données, la médecine, etc. Il a l'avantage d'être lisible et rapide à exécuter. Il s'agit de plus d'une représentation calculable automatiquement par des algorithmes d'apprentissage supervisé.
Figure II-2 : exemple de l'arbre de décision
II.6.2 Machine à vecteurs de support
Les Support Vecteur Machines souvent traduit par (SVM) sont une classe d’algorithmes d’apprentissage initialement définis pour la discrimination c’est-à-dire la prévision d’une variable qualitative binaire. Ils ont été ensuite généralisés à la prévision d’une variable quantitative. Dans le cas de la discrimination d’une variable dichotomique, ils sont basés sur la recherche de l’hyperplan de marge optimale qui, lorsque c’est possible, classe ou sépare correctement les données tout en étant le plus éloigné possible de toutes les observations. Le principe est donc de trouver un classifieur, ou une fonction de discrimination, dont la capacité de généralisation (qualité de prévision) est le plus grand possible. [4]
II.6.3 Réseau de neurones
Un réseau de neurones artificiels, ou réseau neuronal artificiel, est un système dont la conception est à l'origine schématiquement inspirée du fonctionnement des neurones biologiques, et qui par la suite s'est rapproché des méthodes statistiques.
Les réseaux de neurones sont généralement optimisés par des méthodes d’apprentissage de type probabiliste, en particulier bayésien. Ils sont placés d’une part dans la famille des applications statistiques, qu’ils enrichissent avec un ensemble de paradigmes permettant de créer des classifications rapides, et d’autre part dans la famille des méthodes de l’intelligence artificielle auxquelles ils fournissent un mécanisme perceptif indépendant des idées propres de l'implémenter, et fournissant des informations d'entrée au raisonnement logique formel
27
En modélisation des circuits biologiques, ils permettent de tester quelques hypothèses fonctionnelles issues de la neurophysiologie, ou encore les conséquences de ces hypothèses pour les comparer au réel [4] [6].
Figure II-3 neurones artificiels et biologique
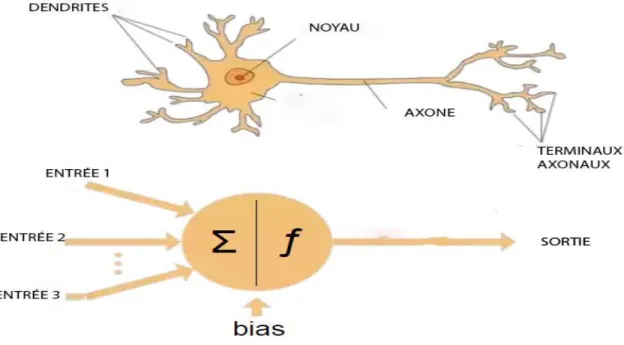
II.6.3.1 Neurone Formel
Un neurone formel est une représentation mathématique et informatique d'un neurone biologique. Le neurone formel possède généralement plusieurs entrées et une sortie qui correspondent respectivement aux dendrites et au cône d'émergence du neurone biologique. Les actions excitatrices et inhibitrices des synapses sont représentées, la plupart du temps, par des coefficients numériques associés aux entrées. Les valeurs numériques de ces coefficients sont ajustées dans une phase d'apprentissage. Dans sa version la plus simple, un neurone formel calcule la somme pondérée des entrées reçues, puis applique à cette valeur une fonction d'activation, généralement non linéaire. La valeur finale obtenue est la sortie du neurone [6].
Le neurone formel est l'unité élémentaire des réseaux de neurones artificiels dans lesquels il est associé à ses semblables pour calculer des fonctions arbitrairement complexes, utilisées pour diverses applications en intelligence artificielle.
Mathématiquement, le neurone formel est une fonction à plusieurs variables et à valeurs réelles.
28
Figure II-4 Neurone formel
II.6.3.2 Le neurone formel de McCulloch et Pitts
Le premier modèle mathématique et informatique du neurone biologique est proposé par Warren McCulloch et Walter Pitts en 1943. En s'appuyant sur les propriétés des neurones biologiques connues à cette époque, issues d'observations neurophysiologiques et anatomiques, McCulloch et Pitts proposent un modèle simple de neurone formel. Il s'agit d'un neurone binaire, c'est-à-dire dont la sortie vaut 0 ou 1. Pour calculer cette sortie, le neurone effectue une somme pondérée de ses entrées (qui, en tant que sorties d'autres neurones formels, valent aussi 0 ou 1) puis applique une fonction d'activation à seuil : si la somme pondérée dépasse une certaine valeur, la sortie du neurone est 1, sinon elle vaut 0 [4]
.McCulloch et Pitts étudiaient en fait l'analogie entre le cerveau humain et les machines informatiques universelles. Ils montrèrent en particulier qu'un réseau constitué des neurones formels de leur invention a la même puissance de calcul qu'une machine de Turing.
Malgré la simplicité de cette modélisation, ou peut-être grâce à elle, le neurone formel dit de McCulloch et Pitts reste aujourd’hui un élément de base des réseaux de neurones artificiels. De nombreuses variantes ont été proposées, plus ou moins biologiquement plausibles, mais s'appuyant généralement sur les concepts inventés par les deux auteurs. On sait néanmoins aujourd’hui que ce modèle n’est qu’une approximation des fonctions remplies par le neurone réel et, qu’en aucune façon, il ne peut servir pour une compréhension profonde du système nerveux [4].
II.6.3.3 Formulation mathématique
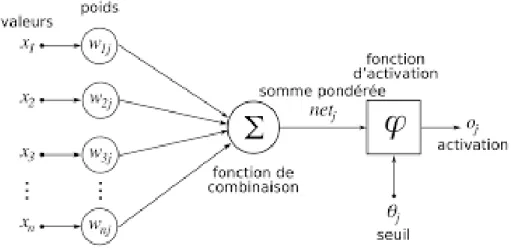
On considère le cas général d'un neurone formel à n entrée entrées, auquel on doit donc soumettre les n grandeurs numériques notées de x1 à xn Un modèle de neurone formel
est une règle de calcul qui permet d'associer aux n entrées une sortie, c’est donc une fonction à m variables et à n valeurs réelles.
29
𝑤
1𝑥
1+ 𝑤
2𝑥
2+ 𝑤
3𝑥
3+ ⋯ + 𝑤
𝑛𝑥
𝑛= ∑
𝑛𝑖=1𝑤
𝑖𝑥
𝑖(1)
À cette grandeur s'ajoute un seuil w0 Le résultat est alors transformé par une fonction
d'activation non linéaire ou fonction de sortie,
ᵩ
. La sortie associée aux entrées x1 à xn estainsi donnée par :
𝜑(
w
0+
∑
𝑛𝑖=1𝑤
𝑖𝑥
𝑖) (2)
Donc la relation devient :
𝜑(∑
𝑛𝑖=0𝑤
𝑖𝑥
𝑖) (3)
Ou la valeur de x0 égale à 1.
McCulloch et Pitts utilisent une fonction d’activation qui s’appelle heaviside qui compare la valeur de la somme avec le seuil w0 de tell sort :
𝜑(𝑥) = {
1 𝑠𝑖 ∑
𝑤
𝑖𝑥
𝑖−
w
0> 0
𝑛 𝑖=0
0 𝑐𝑎𝑠 𝑑
′𝑎𝑢𝑡𝑟𝑒
(4)
Donc la w0 est le seuil qui détermine est ce que la valeur de neurone que ça soit active ou éteindre.II.6.3.4 Perceptron
Les travaux de McCulloch et Pitts n’ont pas donné d’indication sur une méthode pour adapter les coefficients synaptiques. Ce travail a été fait par physiologiste canadien Donald Hebb en 1949 où il a proposé une règle simple qui permet de modifier la valeur des coefficients synaptiques en fonction de l’activité des unités qu’ils relient. Cette règle aujourd’hui connue sous le nom de règle de Hebb.
II.6.3.5 Règle de Hebb
Est une règle d'apprentissage des réseaux de neurones artificiels dans le contexte de l'étude d'assemblées de neurones. Cette règle suggère que lorsque deux neurones sont excités conjointement, il se crée ou renforce un lien les unissant.
30
Dans le cas d'un neurone artificiel seul utilisant la fonction signe comme fonction d'activation cela signifie que :
𝑤
𝑖,= 𝑤
𝑖+ 𝛼(𝑦 ∗ 𝑥
𝑖) (5)
Tell que 𝑤𝑖, représente le poids corriger est y est la sortie et α représente le pas d’apprentissage.A partir des résultats des étude précédent Frank Rosenblatt en 1957 a été capable de crée le premier system artificiel capable d’apprendre par expérience, y compris lorsque son instructeur commet quelques erreurs.
Dans ce système la règle de hebb a été développe sous la forme suivante :
𝑤
𝑖,= 𝑤
𝑖+ 𝛼(𝑦
𝑖∗ 𝑦′) 𝑥
𝑖(6)
Tell que𝑤
𝑖, = le poids𝑖 i corrigé𝑦
𝑖 = sortie attendue𝑦′
= sortie observée𝛼
= le pas d'apprentissage𝑥
𝑖 = l'entrée du poids 𝑖 pour la sortie attendue𝑤
𝑖 = le poids 𝑖 actuelEn 1969, Marvin Lee Minsky et Seymour Papert publièrent un ouvrage qui discute les limitations du perceptron [12 ouvrages name], qui est l’impossibilité de traiter des problèmes non linéaires. Ils étendirent implicitement ces limitations à tous modèles de réseaux de neurones artificiels. Jusqu’ 1982 ou le physicien John Joseph Hopfield introduit un nouveau modèle de réseau neurones complètement récurent qui rafraichie la recherche dans ce domaine qu’elle été arrêter pour plus que 10 ans, malgré qu’il ait les mêmes limitations des modèles des années 1960 [7].
II.6.3.6 Perceptron multicouche
Comme on a vu les perceptrons n’est pas capable de résoudre les problèmes non linéaires ce qui nécessite quelque chose qui prouve qu’il s’adapte avec ce type des problèmes.
31
Suivaient les recherches de Paul Werbos a été capable de supprime les limitations théoriquement utilisant la méthode de la rétropropagation du gradient de l'erreur dans un système multicouche, ce qui fait réaliser en 1986 par David Rumelhart.
Le perceptron multicouche est un réseau orienté de neurones artificiels organise en couches et où l’information voyage dans un seul sens, de la couche d’entrée vers la couche de sortie. Les neurones sont reliés entre eux par des connexions pondérées. Ce sont les poids de Ces connexions qui gouvernent le fonctionnement du réseau et “programment” une application de l’espace des entrées vers l’espace des sorties `à l’aide d’une transformation non linéaire.
Dans le perceptron multicouche à rétropropagation, les neurones d'une couche sont reliés à la totalité des neurones des couches adjacentes. Ces liaisons sont soumises à un coefficient altérant l'effet de l'information sur le neurone de destination. Ainsi, le poids de chacune de ces liaisons est l'élément clef du fonctionnement du réseau : la mise en place d'un Perceptron multicouche pour résoudre un problème passe donc par la détermination des meilleurs poids applicables à chacune des connexions inter-neuronales. Ici, cette détermination s'effectue au travers d'un algorithme de rétropropagation [7].
II.6.3.6 Algorithme de rétropropagation
Soit le couple (
𝑥
𝑖,𝑦
𝑖) désignant les données d’entrainement (les entrées et sortie désiré) du réseau où :𝑥
𝑖(𝑛) =< 𝑥
1, 𝑥
2, … , 𝑥
𝑞(𝑛) >
𝑦
𝑖(𝑛) =< 𝑦
1(𝑛), 𝑦
2(𝑛), … , 𝑦
𝑝(𝑛) >
Figure II-5 Exemple d’un Perceptron Multicouche Et la sortie obtenue
𝑦
𝑖′(𝑛) =< 𝑦
1′(𝑛), 𝑦
2′(𝑛), … , 𝑦
𝑞′(𝑛) >
.L’algorithme de rétropropagation procède l’adaptation des poids neurone par neurone en comme commencent par la couche de la sortie. Cette adaptation se fait à travers le calcul de l’errer e(n) pour décide le cas où on trouve le minimum valeur de l’erreur
32
𝑒
𝑖(𝑛) = 𝑦
𝑖(𝑛) − 𝑦
𝑖′(𝑛)
(7)
Tell que la sortie de la couche𝑦
𝑖𝑗′ égale aux sommes des valeur de couche j-1 multiplié par les poidsw
ji :𝑦
𝑖′(𝑛) = 𝜑(∑
𝑛𝑖=0𝑤
𝑖(𝑛)𝑥
𝑖(𝑛
)) (8)
Figure II-6 Modèle de neurone j
Généralement on utilise la sigmoïde(x) comme une fonction d’activation 𝜑 tell que
𝑠𝑖𝑔𝑚𝑜𝑖𝑑𝑒(𝑥) =
11+𝑒−𝑥
(9)
Le calcule de de différence n’est pas vraiment la valeur de l’erreur utilisé tous dépend au cas dans lequel on utilise le perceptron multicouche on peut distinguer 2 règles les plus utilisé :
II.6.3.6.1 L’Errer Quadratique
Cette équation est le plus utilisé𝐸(𝑛) =
12
∑ 𝑒
𝑘2
(𝑛)
𝑘
(10)
II.6.3.6.2 Cross-Entropie Erreur
On utilise cette formule dans le cas des classifier
𝐸(𝑛) = − ∑
𝑀𝑗=0𝑦
𝑖(𝑛) log(𝑦
𝑖′(𝑛))
(11)
Où :33
Donc pour trouver les bons résultats on minimise l’erreur observé c’est-à-dire on change les valeurs des poids
𝑤
𝑖𝑗(𝑛)
dans le sens opposé de gradient d’erreur 𝜕𝐸(𝑛)𝜕𝑤𝑗𝑖(𝑛) (voir figure 17)
Figure II-7 Variation de l’Erreur E en fonction des poids w On utilise la règle de chainage on peut écrire le gradient d’erreur sous la forme :
𝜕𝐸(𝑛) 𝜕𝑤𝑗,𝑖(𝑛)
=
𝜕𝐸(𝑛) 𝜕𝑒𝑗,𝑖(𝑛) 𝜕𝑒𝑗,𝑖(𝑛) 𝜕𝑦𝑗,𝑖′ (𝑛) 𝜕𝑦𝑗,𝑖′ (𝑛) 𝜕𝑦𝑗−1,𝑖′ (𝑛) 𝜕𝑦𝑗−1,𝑖′ (𝑛) 𝜕𝑤𝑗,𝑖(𝑛)(12)
De l’équation 12 on peut détermine la variation des poids ∆𝑤𝑗,𝑖(𝑛) :
∆𝑤
𝑗,𝑖(𝑛) = −𝜂
𝜕𝐸(𝑛)𝜕𝑤𝑗,𝑖(𝑛)
(13)
Avec 0 ≤ η ≤ 1 représente le taux d’apprentissage ou le gain d’algorithme.
On évolue chacun des termes de l’équation (12) dans la couche de sortie prenant l’équation de l’erreur quadratique (équation 10) comme
𝐸(𝑛)
:34
𝜕𝐸(𝑛)
𝜕𝑒
𝑗,𝑖(𝑛)
=
𝜕 (
1
2
∑ 𝑒
𝑘 𝑘2(𝑛)
)
𝜕𝑒
𝑗,𝑖(𝑛)
=
1 2 𝜕𝑒2𝑗,𝑖(𝑛) 𝜕𝑒𝑗,𝑖(𝑛)= 𝑒
𝑗,𝑖(𝑛
)(14)
𝜕𝑒𝑗,𝑖(𝑛) 𝜕𝑦𝑗,𝑖′ (𝑛)=
𝜕(𝑦𝑖(𝑛)− 𝑦𝑖′(𝑛)) 𝜕𝑦𝑗,𝑖′ (𝑛)= −1
(15)
𝜕𝑦
𝑗,𝑖′(𝑛)
𝜕𝑦
𝑗−1,𝑖′(𝑛)
=
𝜕(
1
1 + 𝑒
−𝑦𝑗−1,𝑖′ (𝑛))
𝜕𝑦
𝑗−1,𝑖′(𝑛)
=
𝑒
−𝑦𝑗−1,𝑖′ (𝑛)[1 + 𝑒
−𝑦𝑗−1,𝑖′ (𝑛)]
2= 𝑦
𝑗,𝑖′(𝑛) ∗ [
𝑒
−𝑦𝑗−1,𝑖′ (𝑛)+ 1
1 + 𝑒
−𝑦𝑗−1,𝑖′ (𝑛)−
1
1 + 𝑒
−𝑦𝑗−1,𝑖′ (𝑛)]
= 𝑦
𝑗,𝑖′(𝑛)(1 − 𝑦
𝑗,𝑖′(𝑛))
(16)
Et finalement𝜕𝑦𝑗−1,𝑖 ′ (𝑛) 𝜕𝑤𝑗,𝑖(𝑛)
=
𝜕(∑𝑘𝑙=0𝑤𝑗,𝑙(𝑛)𝑦𝑗−1,𝑙(𝑛)) 𝜕𝑤𝑗,𝑖(𝑛)=
𝜕(𝑤𝑗,𝑖(𝑛)∗ 𝑦𝑗,𝑖(𝑛)) 𝜕𝑤𝑗,𝑖(𝑛)= 𝑦
𝑗,𝑖(𝑛)
(17)
35
𝜕𝐸(𝑛)
𝜕𝑤𝑖(𝑛)
= −𝑒
𝑖(𝑛)𝑦
𝑖′
(𝑛)(1 − 𝑦
𝑖′
(𝑛))𝑦
𝑖(𝑛) (18)
On remplace l’équation 18 dans l’équation 13 pour obtenir ce que on appelle la règle de delta pour la sortie :
∆𝑤
𝑗,𝑖(𝑛) = −𝜂
𝜕𝐸(𝑛)𝜕𝑤𝑗,𝑖(𝑛)
= 𝜂𝛿
𝑗(𝑛)𝑦
𝑗,𝑖(𝑛) (19)
Tell que :
𝛿
𝑗(𝑛) = 𝑒
𝑖(𝑛)𝑦
𝑖′(𝑛)(1 − 𝑦
𝑖′(𝑛))𝑦
𝑖(𝑛) (20)
Pour le cas des autres couches le problème qui se pose c’est que dans la dérivée partielle de l’erreur les𝑒
𝑘(𝑛)
dans la somme dépend de𝑦
𝑖′(𝑛)
donc on ne peut pas se débarrasser la somme mais on peut écrire𝜕𝐸(𝑛)
𝜕𝑦
𝑗,𝑖(𝑛)
= ∑ [𝑒
𝑘(𝑛)
𝜕𝑒
𝑘(𝑛)
𝜕𝑦
𝑘′(𝑛)
]
𝑘= ∑ [𝑒
𝑘(𝑛)
𝜕𝑒
𝑘(𝑛)
𝜕𝑦
𝑗−1′(𝑛)
𝜕𝑦
𝑘′(𝑛)
𝜕𝑦
𝑗−1′(𝑛)
]
𝑘= ∑ [𝑒
𝑘(𝑛)
𝜕(𝑦
𝑖(𝑛) − 𝑦
𝑖 ′(𝑛))
𝜕𝑦
𝑗,𝑖′(𝑛)
𝜕(∑
𝑘𝑙=0𝑤
𝑗,𝑙(𝑛)𝑦
𝑗−1,𝑙(𝑛)
)
𝜕𝑤
𝑗,𝑖(𝑛)
]
𝑘= ∑ [𝑒
𝑘 𝑘(𝑛) (−𝑦
𝑘′(𝑛)[1 − 𝑦
𝑘′(𝑛)])𝑤
𝑗𝑖]
(21)
Donc :𝜕𝐸(𝑛) 𝜕𝑦𝑗,𝑖(𝑛)
= − ∑ 𝛿
𝑘 𝑘(𝑛)𝑤
𝑗𝑖(22)
Tell que𝛿
𝑘(𝑛) = 𝑒
𝑘(𝑛) (−𝑦
𝑘′(𝑛)[1 − 𝑦
𝑘′(𝑛)]) (23)
En remplace l’équation (22) dans l’équation (12) on obtient :𝜕𝐸(𝑛)
𝜕𝑤𝑖(𝑛)
= −𝑦
𝑖′
(𝑛)(1 − 𝑦
36 Ce qui implique que
∆𝑤
𝑗,𝑖(𝑛) = −𝜂
𝜕𝐸(𝑛)𝜕𝑤𝑗,𝑖(𝑛)
= 𝜂𝛿
𝑗(𝑛)𝑦
𝑗,𝑖(𝑛) (25)
Tell que :
𝛿
𝑗(𝑛) = 𝑦
𝑖′(𝑛)(1 − 𝑦
𝑖′(𝑛))[∑ 𝛿
𝑘 𝑘(𝑛)𝑤
𝑗𝑖] (26)
Donc on peut résumer les étapes de l’algorithme de rétropropagation comme suite :1) Initialiser tous les poids à de petites valeurs aléatoires dans l’intervalle [−0.5, 0.5] 2) Normaliser les données d’entrainement
3) Permuter aléatoirement les données d’entrainement ; 4) Pour chaque donnée d’entrainement n :
a) Calculer les sorties observées en propageant les entrées vers l’avant b) Ajuster les poids en retro propageant l’erreur observée :
𝑤
𝑗,𝑖(𝑛) = 𝑤
𝑗,𝑖(𝑛 − 1) + ∆𝑤
𝑗,𝑖(𝑛) = 𝑤
𝑗,𝑖(𝑛 − 1) + 𝜂𝛿
𝑗(𝑛)𝑦
𝑗,𝑖(𝑛) (27)
Ou le gradient local
𝛿
𝑗(𝑛)
est définie comme :𝛿
𝑗(𝑛) = {
𝛿
𝑗(𝑛) = 𝑒
𝑖(𝑛)𝑦
𝑖′(𝑛)(1 − 𝑦
𝑖′(𝑛))𝑦
𝑖(𝑛) j est la couche de sortie
𝛿
𝑗(𝑛) = 𝑦
𝑖′(𝑛)(1 − 𝑦
𝑖′(𝑛)) [∑ 𝛿
𝑘(𝑛)𝑤
𝑗𝑖𝑘
] ailleur (28)
5) Répéter les étapes 3 et 4 jusqu’à un nombre maximum d’itérations ou jusqu’à ce que la Racine de l’erreur quadratique moyenne (EQM) soit inferieure `a un certain seuil.
II.6.3.7 La règle de delta généralisé :
L’équation 27 s’appelle la règle de delta cette équation a été généralisé comme la forme suivante :
𝑤
𝑗,𝑖(𝑛) = 𝑤
𝑗,𝑖(𝑛 − 1) + 𝜂𝛿
𝑗(𝑛)𝑦
𝑗,𝑖(𝑛) + 𝛼∆𝑤
𝑗,𝑖(𝑛 − 1) (29)
Ou la α est pris de l’intervalle [0,1] est un paramètre qui s’appelle Momentum qui représente une espèce d’inertie dans le changement de poids.
37
II.7 Application :
On a vu que l’apprentissage automatique peut s’adapte avec n’importe quel problème est donne des prédictions parfaites, c’est pour cela nous rencontrons ces applications presque dans tous les domaines de la vie comme :
1-Détection des email spam : Ou les majeures compagnies comme Google, Yahoo …etc. ont développé des modèles qui peuvent détecter est reconnaitre ces types des
emails [8].
2- Détection des Maladies : aujourd’hui l’apprentissage automatique dans plusieurs domaines même dans la médecine ou plusieurs algorithmes ont été développé qui peuvent détecter certains types de maladies comme le cancer à partir des photos traitées par ces algorithme [9].
3-L’ART : avec le développement que l’on note dans le domaine l’apprentissage automatique, certains laboratoires de recherche ont développé quelques algorithmes qui peuvent copier les styles de quelques artistes comme Van Gog et modifie des images données de telle sorte il adapte le style de Peinture de l’artiste, même dans la music il y’a pas mal d’algorithmes qui produisent des musiques, qui ont le même rythme que le JAZZ…etc [10].
38
II.8 Classification des objets :
Comme on a vue l’apprentissage automatique et presque utiliser dans tous les domaines de la vie. Dans notre projet nous allons nous intéresser sur l’une des applications qui est la classification des objets où nous utilisons des algorithmes qui peuvent reconnaitre des objets dans des images ou des vidéos et même en temps réel avec l’implémentation de Opencv.
II.9 Les Méthode de classification :
Pour la détection des objets on peut distinguer pas male des méthodes comme :
II.9.1 Méthode de Viola et Jones avec Haar :
Qui était la première méthode efficace capable de détecter en temp réel les objets. Au début, elle a été développer pour la détection des visages puis elle été appliquer aux autres objets,Cette méthode bénéficie d'une implémentation sous licence
BSD dans OpenCV.
II.9.2 Tensorflow :
Tensorflow c’est la plus efficace Library développée par google pour simplifier et facilité l’implémentation de l’apprentissage automatique. Cette Library nous permet d’entrainer nous mème nos modèles ou utiliser un modèle pré-trainé fournis par google.
II.9.3 YOLO :
YOLO (You Only Look Once en anglais) c’est la méthode la plus rapide pour la détection des objets en temp réel. Elle utilise des algorithmes comme « fast RCNN : Recursive Convolutional Neural Network » pour détecte et reconnaitre les objets, et les modèles obtenue par cette méthode peut s’adapte avec tensorflow aussi.
39
Conclusion :
Dans ce chapitre nous avons développé les méthodes d’apprentissage automatique qui est un domaine vaste qui consiste à permettre aux ordinateurs à simuler quelques tâches de l’être humain.
L’apprentissage automatique combine les relations mathématiques comme les réseaux de neurones avec les codes informatique comme python et les librairies comme tensorflow,keras…etc.
40
41
Chapitre III
L’internet des Objet
III.1 Introduction
Pour la transmission des donnés et la communication entre objets, la notion de réseau apparue comme la structure et l’acheminement des données d’une part vers l’autre Donc quel type des réseaux, ces composant et méthode de transmission utilisé dans ce réseau.
III.2 Internet des objets
L’internet des Objets ou IdO (the internet of things ou IoT en anglais) est l’extension de la connectivité à travers l’interne vers les objets physique comme (serveur, capteur …etc.) a travers l’internet, ou elle permet ces objets de communiquer et même permet de monitorer et commander ces objets à travers l’internet. L’IdO est considérer comme la troisième évolution de l’internet.
L’IdO a plusieurs définitions souvent les aspects utilisés, l’une de ces définitions est donnée par l’UIT (Union International de Télécommunication) ou elle décrit l’IdO comme infrastructure mondiale pour la société de l'information, qui permet de disposer de services évolués en interconnectant des objets (physiques ou virtuels) grâce aux technologies de l'information et de la communication interopérables existantes ou en évolution [11].
42
III.3 Historique
L’idée de IdO apparu aux États-Unis dès 1982 avec un projet de raccorder des distributeurs avec un serveur au niveau de l’université de Carnegie Mellon, ou les machine indique leurs états au serveur pour pouvez suivre charge et réparer ces machines, ce réseau a été nommé réseau des machines.
Peu à peu les chose ont été développé et aussi les protocoles utiliser pour transmettre et guider les informations comme IP, les machine ont été capables de communiquer entre eux ou avec des réseaux de serveurs et divers acteurs, d'une manière de moins en moins centralisée.
En 1999 le terme internet des objets apparue par le chercheur dans MIT Kevin Ashton qui travaille sur la technologie RFID.
Figure III-2 : Evolution du nombre d’objet connecté de nos jours à 2020
III.4 L’architecture de IdO
Pour installer un système pour girer une application utilisent IdO il faut qu’il comporte ces 3 choses principaux :
III.4.1 Les Objets
Les objets sont, selon nous, tous les équipements actifs ou passifs pouvant générer de la donnée exploitable et créatrice de valeur pour les utilisateurs. Cette donnée peut être température, humidité, de positionnement, de temps de fonctionnement, de niveau, d’alerte…etc.
43
Figure III-3 : capteur de température
III.4.2 Le réseau
On utilise le réseau pour transmettre les données générer par les objets vers les serveurs pour le traiter et extracteur les informations cherchées, comme le nombre des nombres des objets peut être énorme il est nécessaire des équipements de stockages des donné.
44
III.4.2.1 Les diffèrent technologie pour les réseaux
Pour crée un réseau dans IdO il’ y a plusieurs des technologies que on peut l’utilise pour raccorder les objets comme :
III.4.2.1.1 Les LPWAN
Les LPWAN comporte 2 technologies SIGFOX et LoRaWAN qui consiste à transmettre les données pour long distance avec une faible consommation signifie longue portée et faible consommation, ces deux techniques utilise la même bande de transmission 868 MHz en Europe et 915 MHz en Amérique.
III.4.2.1.2 Le M2M
Le M2M ou machine to machine en anglais consiste à utiliser un réseau mobile de 2G jusqu’au 4G. Majoritairement, il s’agit d’abonnements souscrits auprès des opérateurs de téléphonie pouvant donner accès uniquement à des volumes de données.
III.4.2.1.3 La RFID
Ou on utilise l’une des deux technologies de RFID (active ou passive) pour transmettre les données obtenues des capteurs ou des éléments de Stockage.
III.4.2.1.4 Le Bluetooth
Est une technologie connue et maitrisée par tous depuis maintenant une dizaine d’années, il partage les données avec une faible porté (~ 10m) utilise une bande
fréquentielle au tour de 2. 4GHz.cette technologie nos permet de partager des données avec des grand taille est un débit élevé.
Technologie Points forts Points Faibles Type de cas d’usage LoRa Faible consommation
énergétique Longue portée Un standard opérable Couverture mondiale encore faible Taille et volume de données Relève de compteurs d’énergie Envoi d’informations ponctuelles (géolocalisation, Sigfox Faible consommation
énergétique Longue portée Un opérateur unique Couverture mondiale encore faible Taille et volume de données Relève de compteurs d’énergie Envoi d’informations ponctuelles (géolocalisation, M2M Couverture mondiale importante Consommation d’énergie Portée Terminaux de paiement Application avec de gros volumes de données ou d’envoi de données sur incident RFID Pas d’émission
d’ondes
Faible portée Géolocalisation de zone