Analyse de comportement de pare-feu par
marquage de données
Olivier Paul
([email protected])
*Abstract: Dans cet article nous présentons les résultats préliminaires de l’utilisation d’un outil d’analyse de comportement des systèmes de filtrage. Celui-ci fonctionne en utilisant un mécanisme de marquage de données qui permet distinguer de manière plus ou moins grossière quelles parties d'un paquet sont examinées par un pare feu en fonction de la configuration de celui-ci.
Keywords: filtrage, virtualisation, marquage de données.
1 Introduction
Les fonctions de filtrage sont aujourd'hui particulièrement répandues. On les trouve aussi bien dans les équipements destinés à une utilisation personnelle (routeurs personnels, routeurs-modems/cable-adsl) que professionnelle (pare-feu dédiés, IPS, routeurs d'entreprise), aussi bien dans des équipements dédiés que dans des équipements dont ils viennent complémenter les fonctions. Par ailleurs leur déploiement s'est accompagné d'une complexification croissante. Aux fonctions de filtrage traditionnelles, se sont ajoutées au fil du temps des fonctions liées à la détection d'intrusion, à la détection d'attaques de dénis de service. Malheureusement, comme nous le montrons dans la section suivante, il n'est pas évident pour un utilisateur potentiel de déterminer quelles fonctions sont réellement implantées par un pare-feu, ni si une configuration donnée fonctionne de manière attendue. Dans cet article nous décrivons une ébauche de solution pour résoudre ce problème. Nous espérons dans le futur combiner cette ébauche avec d'autres techniques afin de permettre l'analyse de systèmes de filtrage de manière automatique. Notre proposition est pour le moment manuelle, et permet à l'utilisateur d'un système de filtrage de déterminer quelles données sont utilisées par un système de filtrage pour une configuration de filtrage bien définie. Dans la suite de cet article nous présentons l'architecture que nous proposons ainsi que des résultats de tests préliminaires.
2 Etat de l’art
2.1 Utilisation de manuels et de standards
La méthode la plus évidente pour déterminer les fonctionnalités de filtrage implantées par un outil est de lire le manuel qui lui est associé. Cependant cette méthode est rarement suffisante pour plusieurs raisons. D'une part certains outils ne possèdent pas de manuel. C'est par exemple le cas de nombreux routeurs/modems personnels qui possèdent uniquement un manuel de mise en route bien qu'ils implémentent des fonctions de filtrage [Pa07]. D'autres outils possèdent un manuel mais celui-ci n'est pas en phase avec les fonctionnalités réellement implantées par l'outil décrit. Dans certains cas, le manuel peut être optimiste vis à vis des fonctionnalités fournies
* Institut Telecom Sud Paris, 9 rue Charles Fourier, 91000 Evry Cedex
[Pa07]. Il est à noter que cette absence d'information n'est pas toujours dans le mauvais sens. Ainsi il arrive parfois que certains outils fournissent des fonctionnalités plus perfectionnées que celles annoncées par le manuel correspondant [Pa07]. Ce cas se produit fréquemment dans les projets open-source ou l'objectif des développeurs est principalement l'avancement du code mais également pour certains outils commerciaux. Une solution fréquemment utilisée par les
utilisateurs de systèmes open source pour palier ces problèmes est d'aller directement lire le code source des outils afin de comprendre leur fonctionnement. Cette solution même si elle ne peut qu'être bénéfique d'un point de vue de la sécurité est cependant assez fastidieuse et ne s'applique de toute façon qu'à une catégorie limitée d'outils.
Une façon de remédier à ce manque d'information peut être l'utilisation de certifications. Au cours des dix dernières années, plusieurs spécifications de critères de certifications pour les outils de filtrage ont été réalisées par divers organismes tels que le CERT ou la NSA [CC]. Ces critères de certifications appelés profils de protection (PP) décrivent les fonctionnalités minimales qui doivent être implantées par un outil afin que celui-ci puisse être évalué. Cependant, dans la pratique, la majorité des équipements ne sont pas certifiés vis à vis de PPs standardisés parce que les constructeurs préfèrent faire valider leur produit vis à vis d'une description des fonctionnalités adaptée à leur produit qu'ils fournissent alors eux même. Dans ce cas la procédure de certification ne peut couvrir qu'une partie du PP, Une autre raison est tout simplement qu'aujourd'hui, de nombreux produits ne sont pas certifiés. Ainsi fin 2007, moins de 90 produits étaient certifiés et parmi ceux-ci seulement 5 étaient certifiés vis à vis d'un PP existant. Enfin les procédures de certification et de création de PPs étant relativement longues, les produits sont souvent certifiés par rapport à des fonctionnalités qui ne sont plus en rapport avec leurs véritables capacités.
2.2 Analyse par l'utilisation de batteries de tests
Afin de faciliter le travail des développeurs, la plupart des outils de filtrage possèdent une batterie de tests permettant de déterminer si un outil de filtrage se comporte de manière similaire au comportement qu'il avait avant l'introduction de nouvelles fonctionnalités (tests de non régression). Ces tests se concentrent souvent sur la syntaxe des règles de configuration et fonctionnent dans un cadre local, sans mettre en œuvre de fonction réseau par exemple en utilisant une interface spécifique de test [Ipf]. Si ces tests permettent de s'assurer dans une certaine mesure de la cohérence du fonctionnement d'un outil dans le temps, ils ne permettent cependant pas à un utilisateur de comprendre la sémantique des règles de configuration. D'autre part, ils testent un nombre de points précis et ne permettent en aucun cas de garantir la stabilité du fonctionnement global de l'outil.
De nombreux outils permettent la génération de trafic afin de tester le fonctionnement d'un outil de filtrage [hping]. Ils permettent au travers d'une description du trafic à générer de construire les unités de données ayant les caractéristiques désirées. Le test de l'outil de filtrage se fait alors une fois sa configuration réalisée en examinant les unités de données après traitement ainsi que les logs produits par l'outil. Cependant ces tests demandent une connaissance préalable de la sémantique des options de configuration et d'autre part l'analyse des logs et des unités de données non bloquées ne fournissent qu'une vision partielle des opérations réellement réalisées par un outil. Ainsi une règle de filtrage peut être examinée sans être appliquée, d'autre part des fonctions sont souvent mises en œuvre par défaut sans nécessiter de configuration explicite. Le problème de sémantique pourrait être réglé s'il existait une base publique de tests permettant de distinguer les cas de fonctionnement les plus courants. Ainsi une solution approchante
concernant les NAT est proposée dans [Gu05]. Cependant les NATs sont des outils simples dont le comportement est relativement homogène. A notre connaissance il n'existe pas d'outil
similaire pour les pare-feu.
Un certain nombre de travaux ont été réalisés afin de tester des points spécifiques des pare-feu pour lesquels le comportement attendu est bien défini et connu à l’avance. Par exemple [Senn05] présente une méthode permettant de tester les caractéristiques d’un automate de filtre à état TCP pour ce protocole à partir de la définition formelle de TCP. Cependant ce type d'outil, en dehors du fait qu'il se limite à une petite partie du fonctionnement d’un outil de filtrage (les problèmes de temporisation ou de vérification de numéros de séquence sont par exemple ignorés)
présuppose comme dans les cas précédent la connaissance de la sémantique des commandes de configuration.
2.3 Analyse de traces d'exécution
Au cours des cinq dernières années, de nombreuses propositions ont été faites concernant l'analyse de comportement d'outils réseaux au travers de l'analyse de leurs traces d'exécution lors de la réception/émission de données. Ainsi [Mut05] présente l'une des seules analyses à notre connaissance d’un outil de sécurité. Celle-ci est réalisée à partir de traces d’exécution d’outils de détection d’intrusion. Les auteurs se basent sur l’outil ptrace afin d’obtenir celles-ci. Les auteurs montrent par la suite comment ces traces peuvent être utilisées pour déterminer les signatures utilisées par des outils de détection d’intrusion. La limitation principale de cette approche est qu’elle est limitée à l’étude de processus utilisateurs du fait de l’utilisation de ptrace et cela dans un environnement d’exécution bien connu afin de pouvoir disposer de cette fonctionnalité. D’autre part les auteurs donnent peu d’information sur la façon dont l’analyse des traces est réalisée.
Plus récemment, un grand nombre de travaux se sont intéressés à caractériser le comportement des logiciels réseaux par la construction de modèles de l’exécution d’un programme de manière automatique et à partir de traces d’exécution. Ainsi [Bru07] présente une architecture qui à partir de la trace d’exécution d’un programme et de son état final produit une formule symbolique de son exécution appelée pré condition la plus faible. Celle-ci permet de définir quelles données en entrée peuvent amener le programme à un état donné. Cet état est défini par les données produites. Les auteurs utilisent cette approche pour réaliser la prise d’empreinte de logiciels. Une limitation actuelle de cette approche est qu’elle semble pour le moment limitée à des logiciels de petite taille dans lesquels les entrées-sorties sont bien définies.
[Yin07] présente une architecture associant un mécanisme de marquage de données au travers d’un émulateur et un ensemble d’outils systèmes permettant de lier ces données teintées à leur utilisation par un processus, une librairie ou un fichier particulier. Cette architecture permet de détecter des attaques en repérant des anomalies dans le cheminement des données au travers d’un système. Un des inconvénients de cette approche est qu’elle nécessite d’installer un ensemble d’outils sur le système à surveiller. Ceci n’est pas toujours possible le cas dans le cadre d’environnements propriétaires.
3 Architecture proposée
Dans cette partie, nous essayons de montrer l’utilité de utilisation du marquage de donnée dans la compréhension d’un processus de filtrage. Dans le cas de produits commerciaux, l’accès aux sources et au code exécutable du processus de filtrage est souvent impossible. De plus, parmi les produits commerciaux, il est assez fréquent de ne pas pouvoir modifier le système d’exploitation ou d’y introduire de nouvelles fonctions qui permettraient de comprendre le lien entre le
processus de filtrage et le reste du système. Un autre problème dans la compréhension du comportement de ces processus est qu’ils sont souvent implantés comme une partie du système d’exploitation. Il est donc difficile de distinguer leur comportement du reste du système que l’on
peut être alors contraint d’analyser dans sa globalité. Celui-ci étant souvent d’un degré de complexité bien supérieur à celui d’un simple programme, cette tache n’est pas aisée. Enfin les systèmes implantant ces fonctions étant multi-tâches, l’analyse du système peut se révéler plus complexe que celle d’un simple programme dont l’exécution, du point de vue utilisateur, est sans interruptions. Afin de résoudre ces problèmes nous proposons d’utiliser un émulateur afin de réaliser les opérations de base de surveillance. Nous présentons par la suite Argos, l’outil sur lequel se base notre système puis les extensions qui s’y rattachent. Celles-ci ont pour objectif de présenter à l’utilisateur d’un système de filtrage la vision la plus synthétique des opérations réalisées pour une configuration et un trafic de test donnés.
3.1 Argos
Notre architecture se base sur Argos [Por06]. Argos est un outil d'analyse d'exécutables qui permet de repérer la mise en œuvre d'attaques au travers de l'analyse dynamique du code exécuté. Argos est lui même basé sur un outil appelé Qemu [Bel05]. Qemu est un outil de virtualisation qui permet l'émulation de différents types de machines (x86, Sparc, Mips, ARM, PPC, Alpha,...). Dans ce cadre il permet l'exécution de code natif pour ces machine sur un système cible au travers de machines virtuelles.
Lors de son exécution le code natif est traduit de manière dynamique pour pouvoir être exécuté sur le système cible. L’unité de traduction dans Qemu est le bloc de traduction (Translation block), une suite d’instructions terminée par une fonction modifiant le contrôle de l’exécution du programme (saut, appel de fonction, ...). L’utilisation de tels blocs permet de limiter le coût de la traduction en conservant un cache des blocs récemment utilisés et donc de conserver de bonnes performances d'émulation. La traduction en elle-même est réalisée au travers d’un langage intermédiaire comprenant un nombre réduit de fonctions simples. Il permet une portabilité plus importante du traducteur ainsi qu’une modification plus aisées de ces fonctions. Les fonctions de ce langage intermédiaire sont compilées préalablement à l’utilisation de l’émulateur. Celui-ci se charge par la suite de composer le code cible associé à ces fonctions en fonction du code natif à traduire à la manière d’un compilateur.
La capacité de traduction de Qemu est utilisée par Argos pour associer des fonctions de marquage de données aux instructions traduites afin permettre à la machine virtuelle de distinguer la provenance des données traitées. Argos étant construit pour la reconnaissance d’attaques réseau, la seule source de données teintée dans Argos est l’interface réseau. Notre intérêt pour Argos est lié à plusieurs de ses caractéristiques:
- C’est à notre connaissance le seul système de virtualisation supportant le marquage de données dont le code source soit disponible publiquement.
- Il permet d’obtenir des informations d’exécution d’un système de filtrage sans avoir à instrumenter celui-ci sous quelque forme que ce soit (code source, appels système, code binaire).
- Il permet l’exécution d’une grande variété de systèmes de filtrage par le fait que Qemu supporte l’émulation d’un grand nombre de systèmes. Ainsi des systèmes aussi divers que JunOS ou QNX sont au moins partiellement supportés.
- Il permet d’associer les instructions exécutées à leur provenance des données qu'elles manipulent.
3.2 Extensions d’Argos
Malgré toutes ses qualités, Argos ne répond pas totalement à nos besoins. En effet Argos est conçu pour suivre le cheminement des données. Il utilise pour cela deux outils principaux :
espace mémoire (au sens large, c'est-à-dire mémoire principale, registres, ...) pour suivre leur cheminement. Ceci est réalisé en modifiant la sémantique des fonctions du langage intermédiaire utilisé par Qemu.
- La gestion d’un espace mémoire associé à la mémoire disponible pour la machine virtuelle qui contient des étiquettes indiquant la provenance des données. Ces étiquettes sont utilisées par les fonctions instrumentées pour propager cette information de provenance lorsque cela est nécessaire et d’autre part pour rendre les services de détection d’attaques fournis par Argos.
Cependant ces outils ne permettent pas de détecter l’utilisation, par d’autres fonctions, de données teintées. D’autre part Argos n’a pas pour objectif de signaler l’utilisation de données teintées d’une manière générale. Nous avons donc étendu d’une part les autres fonctions du langage intermédiaire afin de pouvoir repérer l’utilisation de données teintées dans des fonctions autres que celles liées au mouvement des données. D’autre part, nous avons muni Argos d’un système permettant de mémoriser l’utilisation de ces données et de fournir à la demande une trace d’utilisation.
Une autre limitation d’Argos est qu’il est conçu afin d’associer à chaque donnée, son origine, c'est-à-dire si il provient du réseau ainsi qu’une approximation de sa localisation dans le flux de données reçu par la carte réseau. Une telle information peut être stockée de manière économe mais n’est cependant pas suffisamment précise pour nos besoins. Nous avons donc étendu Argos afin de pouvoir conserver la position précise de chaque octet dans un paquet ainsi que l’identité du paquet d’origine. L’utilisation dans Argos du système de pagination des informations de marquage permet de limiter le coût d’une telle mesure. Cette information n'est cependant utile que si l'on peut par la suite associer un type à chaque marque. Pour cela nous avons étendu le système de sauvegarde de données présent dans Argos afin de sauver les trames reçues par les cartes réseau sous une forme facilement analysable (format pcap).
Au cours de l’utilisation de notre version modifiée il est rapidement apparu que les informations de marquage n’auraient d’intérêt qu’accompagnées d’informations liées aux instructions
exécutées. Fournir une telle information n’est pas possible au travers du système de conservation des marques car celui-ci se place au niveau du langage intermédiaire et n’a donc pas accès au code natif à traduire. Nous avons donc étendu les fonctions de conservation de logs présentes dans Qemu afin de pouvoir conserver une trace exhaustive de l’exécution de toutes les instructions. Afin de limiter l’impact en terme de performance d’un telle conservation, nous avons développé un système d’automatisation du déclenchement des opérations de prise de log en fonction des évènements se produisant dans la machine virtuelle (arrivée/départ de trames, exécution de séquences d’instructions natives particulières, ...). Celui-ci permet par ailleurs l’exécution de scripts dans le moniteur Qemu ainsi que sur la machine hôte. Cette interface entre la machine virtuelle et la machine hôte permet de synchroniser l'utilisation des outils de
configuration d'outils de filtrage, de génération de trafic de test, de configuration des opérations de capture de trace et d'analyse de ces traces. Enfin nous avons modifié Qemu afin qu’il conserve une valeur de compteur programme (pc) valide lors de l’exécution de blocs (Dans Qemu, le pc est uniquement mis à jour en fin d’exécution de bloc pour des raisons de performance).
Au final, le système modifié fournit donc trois types de traces:
• Trace 1: la liste de toutes les instructions exécutées pendant un test.
• Trace 2: la position des instructions utilisant des données marquées et les marques associées.
3.3 Analyse des traces obtenues
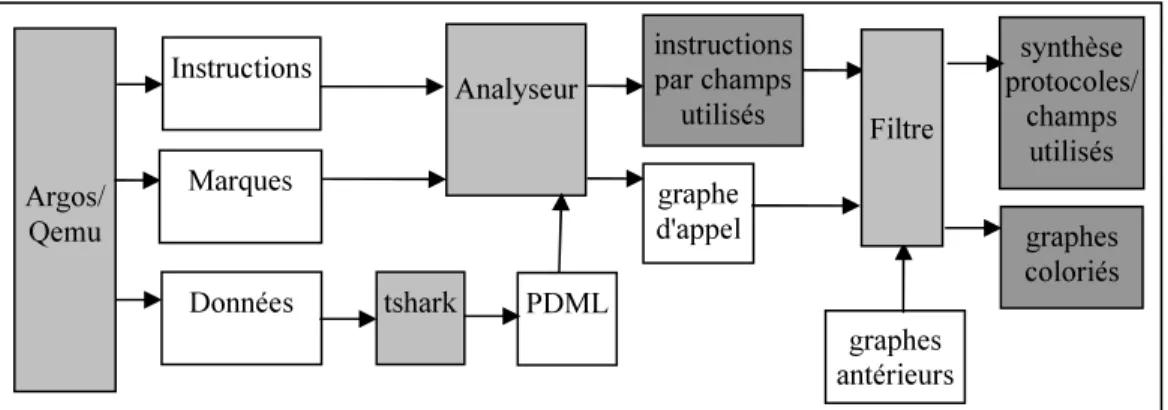
Les modifications présentées dans la section précédente permettent d’associer à chaque
utilisation de donnée provenant d’une trame, l’instruction ayant utilisé cette donnée et le bloc de traduction associé. Cette correspondance nous permet de faire plusieurs types d’opérations de simplification sur les informations présentées à l’utilisateur. Ces opérations sont présentées Fig 1. Dans cette figure, les informations présentées à l'utilisateur à la fin de l'analyse sont indiquées en gris foncé alors que les outils réalisant les opérations de simplification sont présentés en gris clair. Ces opérations sont nécessaires car la quantité d’instructions exécutées lors d’un test même simple est assez importante. Ainsi lors de nos tests, pour une seule règle de filtrage et un seul paquet de test, le nombre d’instructions exécutées entre la réception du paquet et sa réémission variait entre 1 et 2 millions. Même si une partie de ces instructions est due au ralentissement engendré par les mécanismes de log (exécution d'interruptions supplémentaires par exemple), il est nécessaire de distinguer ce qui provient du mécanisme de filtrage des autres fonctions mises en œuvre par le système dans lequel il se place.
Un premier moyen de faire cette distinction est de limiter l’analyse dans le temps en déclenchent les opérations de log lors d’évènements particuliers. Dans notre cas l’instrumentation des fonctions de réception et d’émission des cartes réseau virtuelles permet de rendre cette fonction étant donné que les filtres agissent principalement lorsque du trafic est présent dans le système étudié.
Le marquage des données est un second moyen qui nous permet de distinguer les instructions intéressantes. Le marquage par type utilise les traces 2 et 3 et permet de faire le lien entre les données contenues dans les trames reçues, la position de ces données dans les trames et le type des champs correspondants au travers d'un logiciel d'analyse réseau tel que tshark [tshark]. Celui-ci produit une description au format PDML (Packet Details Markup Language) [Bal05] associant à chaque champ de chaque paquet son type (protocole, sémantique du champ) et sa valeur. Cette description peut être par la suite utilisée par un utilisateur afin de limiter la présentation des fonctions et instructions exécutées en fonction du type de donnée qu'il pense être utilisé par la configuration de filtrage.
Cependant un grand nombre de fonctions manipulent les données réseau. Par exemple, en environnement x86, les entrées-sorties dans Qemu se font en utilisant les instructions in et out. Dans le cas de données provenant du réseau, ces instructions manipulent donc toutes les données. La simplification réalisée par le marquage devrait donc être complété par d’autres types de simplification se basant par exemple sur le type d’instructions.
Fig 1. Opérations réalisées à partir des traces. Argos/ Qemu Instructions Marques Données tshark Analyseur graphe d'appel graphes antérieurs instructions par champs utilisés synthèse protocoles/ champs utilisés PDML graphes coloriés Filtre
Un autre moyen de réduire l’information présentée à l’utilisateur est d’utiliser les différences entre traces provenant de tests différents afin d’isoler de nouvelles instructions ou fonctions. Afin de réaliser cette opération nous construisons lors de chaque test un graphe d’appel. Les blocs d’instructions sont assemblés en fonction des instructions de contrôle de flux qui les terminent de telle sorte à représenter les appels de fonctions pouvant exister dans le code natif original. Chaque instruction de contrôle de flux est analysée de telle sorte à déterminer les transitions possibles entre le bloc courant et les blocs suivants. Il est à noter que certaines instructions ne permettent pas de déterminer la transition à réaliser à partir d’une trace
d’instruction seule (e.g. appel du contenu d’un espace mémoire). Dans ce cas nous estimons le saut le plus probable en fonction des blocs apparaissant par la suite. La construction du graphe d’appel par le fait qu’elle se base sur une trace d’exécution peut ne pas être complète. Cependant en choisissant de manière appropriée les configurations de filtrage testées, il est possible de construire des graphes croissants de manière incrémentale. Il est alors possible de calculer les recouvrements entre graphes et d’extraire les fonctions non représentées dans le graphe original.
4 Résultats préliminaires
Dans cette partie nous décrivons un ensemble de tests réalisés sur l’outil de filtrage IPfilter 4.1.28 [ipf] sous FreeBSD 6.3. Nous montrons comment les outils présentés dans la section précédente permettent de fournir à l’utilisateur une vision assez synthétique du processus de filtrage. Nous utilisons IPfilter car il est à la fois assez complexe (le code source du filtre seul sans les outils de configuration comprend environ 50 000 lignes de code) et son code source est disponible ce qui nous permet de vérifier les informations fournies par nos outils.
4.1 Architecture de test
Lors des tests nous utilisons deux machines virtuelles communiquant au travers d’un VLAN fourni par Qemu. Afin de synchroniser les opérations de configuration et de test entre les deux systèmes sans utiliser les fonctions réseau nous utilisons deux disques virtuels partagés entre les deux machines.
L’utilisateur du système possède un écran de configuration qui permet de saisir une série de test à réaliser. Chacun est constitué des opérations de configuration du filtre, des commandes permettant de tester le fonctionnement de celui-ci et d'une indication que le résultat du test en question peut être utilisé comme base de comparaison avec les tests suivants pour la construction des graphes. Une fois les tests sélectionnés, la configuration du filtre est réalisée et les
commandes de génération de trafic exécutées automatiquement.
A la réception de trafic, la carte réseau virtuelle du système de filtrage déclenche un évènement qui met en route les fonctions de log et à l’émission de celui-ci déclenche un autre évènement qui arrête les fonctions de log et exécute un script sur la machine hôte qui analyse les logs obtenus en utilisant les mécanismes décrits dans la section précédente. Pour chaque type de champ présent dans le trafic généré, une vue de la trace d’exécution est crée qui présente les instructions assembleur utilisées, la fonction auquel appartient le bloc ainsi que les
caractéristiques du champ marqué (paquet, sémantique, provenance). L’utilisateur du système peut par la suite consulter ces vues en fonction du type de champ qu’il pense être affecté par la configuration de filtrage.
En dehors des analyses présentées ci-dessus, le script produit une description graphique des résultats au format GXL (Graph Exchange Language) [Win01]. Ce graphe peut par la suite être visualisé après transformation au travers d’un outil tel que Graphviz [Graphviz].
4.2 Exemple de résultats
Notre outil fournit une vision synthétique des champs utilisés dans le processus de filtrage. La Fig 2 fournit ainsi la liste des champs manipulés par IPfilter lors de l’utilisation de la
configuration suivante. Celle-ci autorise un paquet ICMP de type echo et provenant de l’interface ed0 à traverser le filtre en provenance de n’importe quelle adresse source vers n’importe quelle destination.
pass in quick on ed0 proto icmp from any to any icmp-type echo La sémantique des champs est obtenue à partir de la description PDML fournie par tshark alors que l'utilisation est calculée à partir de la trace contenant les marques. Il est intéressant de noter que le champ IP checksum n’est pas utilisé par IPfilter dans notre installation. Les adresses IP sont vérifiées bien que la règle ne spécifie pas de condition à leur sujet. Le champ ICMP ident semble être utilisé. Cependant une vérification rapide du code obtenu montre que ce champ est copié en mémoire mais n’est pas utilisé pas la suite dans le processus de filtrage.
Field Used eth.dst eth.src eth.type ip.version X ip.hdr_len X ip.dsfield X ip.len X ip.id X ip.flags X ip.frag_offset X ip.ttl X ip.proto X ip.checksum ip.src X ip.dst X icmp.type X icmp.code X icmp.checksum icmp.ident X icmp.seq data
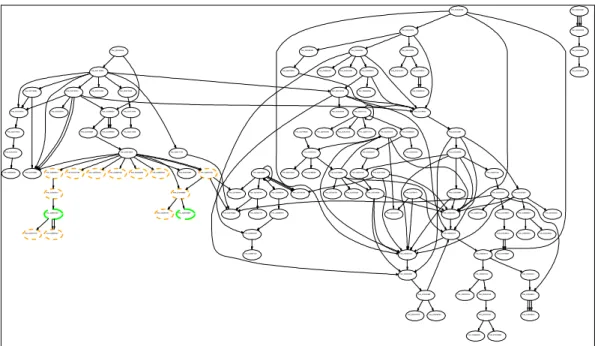
Fig 2. Graphe d’appel présentant l’exécution du traitement d’un paquet. La Fig 3 présente un exemple de graphe d’appel de fonctions obtenu au travers de notre outil lors de l’utilisation d’IPfilter pour la configuration précédente.
Chaque cercle représente une fonction utilisée lors du test. Les arcs entre cercles représentent les appels de fonction. Lorsque plusieurs arcs existent entre deux cercles, ils indiquent que plusieurs appels ont été réalisés à partir de positions différentes dans la fonction d'origine. La couleur associée à chaque fonction est calculée automatiquement de la manière suivante. Parmi ces cercles, les cercles orange indiquent les fonctions provenant de l’utilisation d’IPfilter. Ceux-ci sont obtenus en calculant la différence entre le graphe d’exécution lorsqu'IPfilter est désactivé et celui lorsque la commande présentée ci-dessus est configurée. Les cercles verts représentent
parmi ces fonctions, les fonctions manipulant le champ type ICMP dans le paquet IP traité par le filtre. Ceux-ci sont obtenus au moyen des informations de marquage fournies par notre version modifiée d’Argos. Après vérification du code source du filtre les procédures indiquées
(représentées dans le graphe par leur adresse) sont bien les seules dans IPfilter à manipuler ce champ.
Fig 3. Graphe d’appel présentant l’exécution du traitement d’un paquet. La Fig 4 présente un exemple de vue telle qu’elle est fournie à l’utilisateur lorsqu’il désire obtenir les informations associées à un champ particulier. Notre exemple représente les fonctions liées à la manipulation du champ Type ICMP pour la règle présentée ci-dessus. Elle indique que les instructions movzbl, cmp et ja utilisent le champ type ICMP du paquet 54 (0x0036).
block[0xc043549a;0x00054d7f]={IN: 0xc043549a mov 0x4(%edx),%ax 0xc043549e mov %ax,0x3e(%ebx) 0xc04354a2 movzbl (%edx),%eax
from 0x02650e54 [0x0036 icmp.type] 0xc04354a5 cmp $0x12,%eax
from 0x02650e54 [0x0036 icmp.type] 0xc04354a8 ja 0xc0435530
from 0x02650e54 [0x0036 icmp.type] }
Fig 4. Trace présentée à l’utilisateur.
4.3 Estimation de l’importance des opérations de simplification
Lors des tests nous nous sommes intéressés à deux aspects. Le premier concerne la justesse de la simplification présentée à l’utilisateur. L’autre concerne le nombre d’instructions présentées à l’utilisateur en fonction des techniques de simplification utilisées. Le tableau ci-dessous présente
Proc_3226937336 Proc_3226051120 Proc_3226045876 Proc_3226045996 Proc_3226966248 Proc_3227021736 Proc_3227034444 Proc_3227856020 Proc_3226970004 Proc_3227856948 Proc_3227856100 Proc_3227800796 Proc_3225699576 Proc_3227103976 Proc_3227789568 Proc_3227005200 Proc_3227014792 Proc_3227855824 Proc_3227812684 Proc_3227090828 Proc_3225666808 Proc_3227015032 Proc_3226583248 Proc_3226582868 Proc_3226331068 Proc_3226330340 Proc_3225642900 Proc_3227056476 Proc_3226734748 Proc_3226741520 Proc_3226741780 Proc_3226733548 Proc_3227008508 Proc_3227101904 Proc_3227041336 Proc_3227102520 Proc_3227535156 Proc_3226466968 Proc_3227824316 Proc_3226536172 Proc_3226581680 Proc_3225651988 Proc_3225644994 Proc_3225640088 Proc_3225640680 Proc_3225751188 Proc_3225701268 Proc_3225661428 Proc_3225641756
Proc_3226474020 Proc_3225671740 Proc_3225637824 Proc_3225637960 Proc_3225638916 Proc_3225639612 Proc_3227096396 Proc_3227000024 Proc_3227000448 Proc_3227804172 Proc_3227824360 Proc_3227803952 Proc_3229191416 Proc_3229338744 Proc_3229338824 Proc_3229224248 Proc_3229224407 Proc_3229224352 Proc_3229190216 Proc_3229197556 Proc_3226043356 Proc_3226999720 Proc_3226419480 Proc_3226419096 Proc_3226966352 Proc_3227000200 Proc_3227061000 Proc_3226735416 Proc_3226173704 Proc_3226171344 Proc_3226580392 Proc_3226580324 Proc_3226972112 Proc_3226581264 Proc_3226544412 Proc_3226579520 Proc_3226583700 Proc_3226049864 Proc_3226050396 Proc_3226043456 Proc_3227569332 Proc_3226580668 Proc_3226047656 Proc_3226419576 Proc_3226420100
Proc_3227857264 Proc_3226582168 Proc_3229298672
Proc_3226583932 Proc_3226583856 Proc_3226581844 Proc_3229298276 Proc_3227804316 Proc_3227812616 Proc_3227802928 Proc_3227802608 Proc_3227813636 Proc_3227805136 Proc_3226583220 Proc_3227789008 Proc_3227898308 Proc_3227898412 Proc_3227899548 Proc_3226545876 Proc_3226547668 Proc_3226330088
plusieurs combinaisons. La simplification temporelle correspond au fait de ne conserver une trace que lorsque un paquet est présent à l’intérieur du système de filtrage. Le marquage sans type considère toutes les instructions manipulant les données d’un paquet. Le marquage avec type considère les instructions manipulant le type donné en tête de colonne. L'utilisation du graphe d'appel consiste à ne présenter que les instructions qui appartiennent à des fonctions qui ne sont pas présentes dans un graphe original (ici le graphe original est obtenu lors d'une exécution dans laquelle le module de filtrage n'est pas activé). Enfin la simplification par type d’instruction supprime les instructions (utilisation de la pile, entrée/sorties, ...) dont la présence n’est pas indispensable à la compréhension du code assembleur.
Type de simplification Instructions
(Addr IP DST) Instructions (Type ICMP)
Aucun 2.5.109 2.5.109
Temporel 1.9.106 1.8.106
Temporel, marquage sans type 32.103 31.103
Temporel, marquage avec type 6825 87
Temporel, marquage, graphe d’appel 180 67 Temporel, marquage, graphe d’appel, type
d’instruction 87 41
Le tableau montre les résultats pour deux configurations de filtrage différentes. Vis à vis de traces brutes, les différentes techniques de simplification permettent d’affiner considérablement la vision fournie à l’utilisateur.
5 Conclusion
Dans cet article nous avons montré comment au travers de processus d’analyse automatique il était possible pour l’utilisateur d’un système de filtrage de simplifier la vision qu’il pouvait obtenir vis-à-vis d’une trace d’exécution brute. Cette simplification n’est pour le moment pas directement utilisable dans la mesure où elle permet principalement d’indiquer à l’utilisateur dans comment une configuration provoque un fonctionnement différent d’une autre
configuration de filtrage. Celui-ci a donc toujours besoin de comprendre la syntaxe des règles de configuration et au moins une partie de leur sémantique afin de construire un trafic de test approprié. Notre objectif est donc d’utiliser comme base ces outils afin de pouvoir construire un modèle formel des opérations réalisées par un filtre à la manière de [Bru07] sans que celui-ci ne soit de taille trop importante. Une telle approche nous permettrait de construire de manière automatique des unités de données validant (ou ne validant pas) une configuration du pare-feu. Cependant en l’état actuel notre outil permet déjà d’améliorer la compréhension que l’on peut avoir d’un outil de filtrage sans se reposer sur la lecture de son code source.
References
[Pa07] Olivier Paul. There’s nothing like a firewall. Présentation au Workshop IEEE Monam 07. 2007.
[Gu05] Saikat Guha et Paul Francis. Characterization and Measurement of TCP Traversal through NATs and Firewalls, Dans ACM Internet Measurement Conference, 2005.
[Mut05] Darren Mutz, Christopher Kruegel,, William Robertson, Giovanni Vigna, et Richard Kemmerer. Reverse Engineering of Network Signatures. Dans Information Technology Security Conference (AusCERT). Mai 2005.
[Senn05] Senn Diana, Basin David et Caronni Germano. Firewall Conformance Testing. Dans IFIP TestCom 2005. LNCS 3502. 2005.
[Yin07] Heng Yin, Dawn Song, Manuel Egele, Christopher Kruegel, et Engin Kirda. Panorama: Capturing System-wide Information Flow for Malware Detection and Analysis. Dans ACM CCS 2007.
[Cab07] Juan Caballero, Heng Yin, Zhenkai Liang, Dawn Song. Polyglot: Automatic Extraction of Protocol Message Format using Dynamic Binary Analysis. Dans ACM CCS 2007. [Bel05]F. Bellard. Qemu, a fast and portable dynamic translator. Dans USENIX Annual
Technical Conference, FREENIX Track, 2005.
[Por06] Georgios Portokalidis, Asia Slowinska et Herbert Bos. Argos: an Emulator for Fingerprinting Zero-Day Attacks ACM EuroSys 2006. 2006.
[Bru07] David Brumley, Juan Caballero, Zhenkai Liang, James Newsome, Dawn Song. Towards Automatic Discovery of Deviations in Binary Implementations with Applications to Error Detection and Fingerprint Generation. Dans Usenix Security 07. 2007. [ipf] IP Filter - TCP/IP Firewall/NAT Software. Disponible à coombs.anu.edu.au/~avalon/. [hping] Hping - Active Network Security Tool. Disponible à www.hping.org.
[CC] Common criteria Protection Profiles. Disponible à www.commoncriteriaportal.org. [Win01] A. Winter, B. Kullbach, V. Riediger. An Overview of the GXL Graph Exchange
Language. Software Visualization, International Seminar Dagstuhl Castle. 2001. [Graphviz] Graphfiz, Graph Visualization Software. Disponible à www.graphviz.org [tshark] tshark, the wireshark network analyzer. Disponible à
www.wireshark.org/docs/man-pages/tshark.html
[Bal05] M. Baldi et F. Risso Using XML for Efficient and Modular Packet Processing. Dans IEEE Globecom 05. 2005.