Quantitative homogenization on percolation clusters and interacting particle systems
Texte intégral
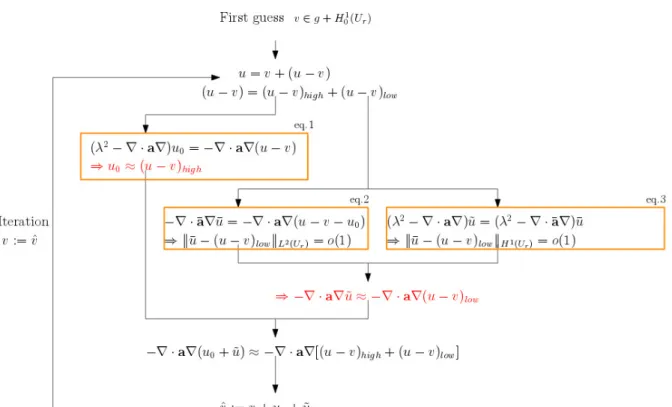
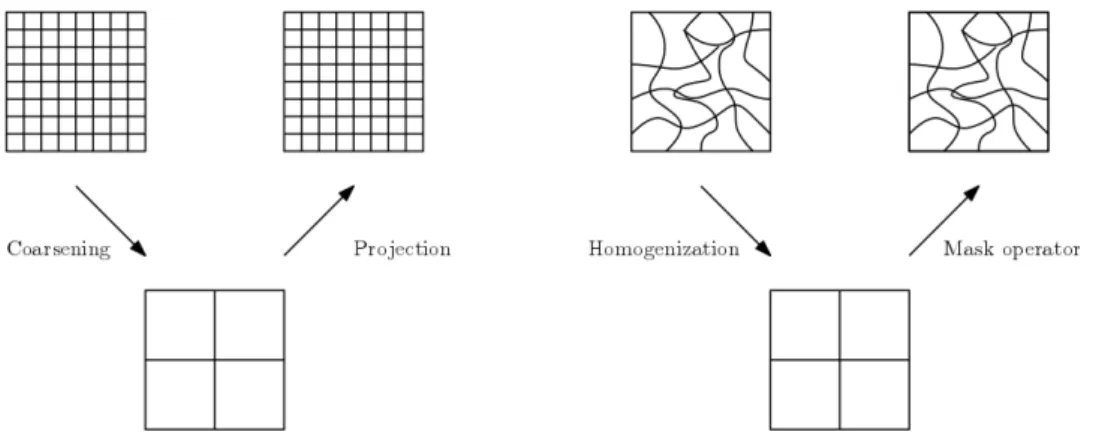
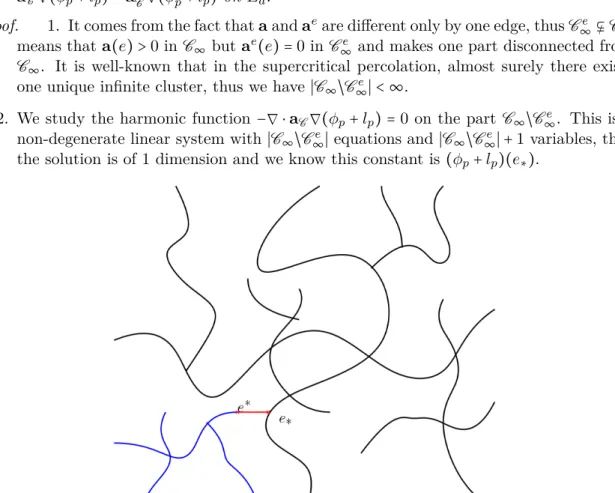
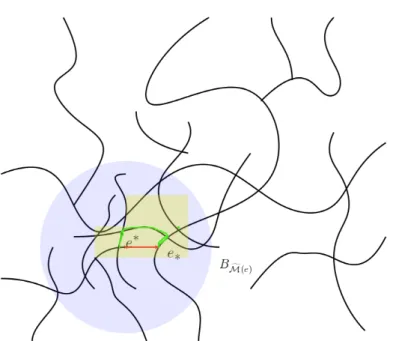
Figure


Documents relatifs
of a square lattice the frontier is made of those A atoms which are connected through nearest neighbours with the diffusion source and have an empty first or second
The motivation of the present work stems from the feature that the giant cluster resulting from supercritical bond percolation on a large random recursive tree has a much
The determination of an upper approximation of the mean-field swelling radius under partial consideration of the quenched topological structure for percolation clusters is possible
In [9], Narayanan showed that if the edges of any fixed graph are randomly and independently oriented, then writing {S i} to indicate that there is an oriented path going from a
For the Cross Model, for each K, n, there exists a path from (0, 0) to (n, 0) of minimal length that only goes through horizontal and diagonal edges, except possibly through
The aim of the Self-organized Gradient Percolation model is to predict the capillary pressure curve at any time using a proposed capillary pressure curve at initial step time (Figure
Lemma 1.2 also extends to Lemma 2.13 in connection with Theorem 2.9 (critical case s = q N ∗ −1 ), and to Lemma 2.14 (case q = N −1, with a uniform convergence result) in
THEOREM 1.8.— Let D CC C 71 be a pseudoconvex domain admit- ting a bounded uniformly Holder continuous plurisubharmonic exhaustion function and having the property, that any point q
![Band offsets of n-type electron-selective contacts on cuprous oxide (Cu[subscript 2]O) for photovoltaics](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)