CRAFT : ClusteR-specific Assorted Feature selecTion
Texte intégral
Figure
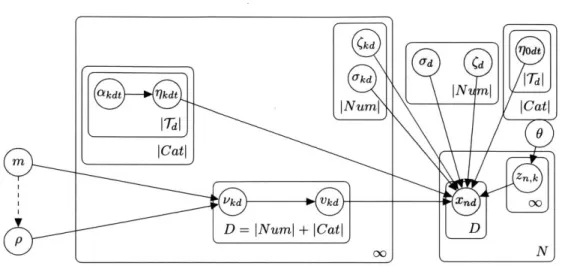
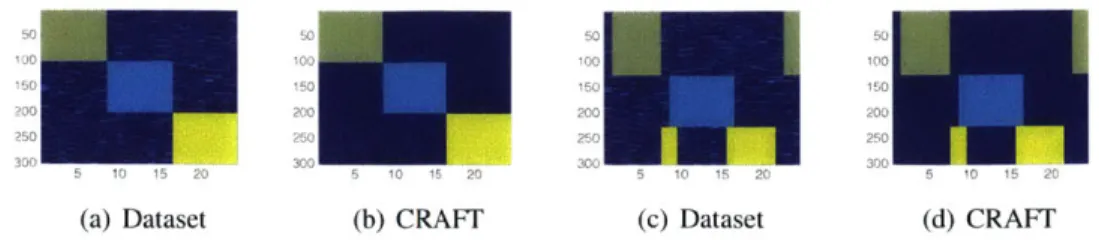

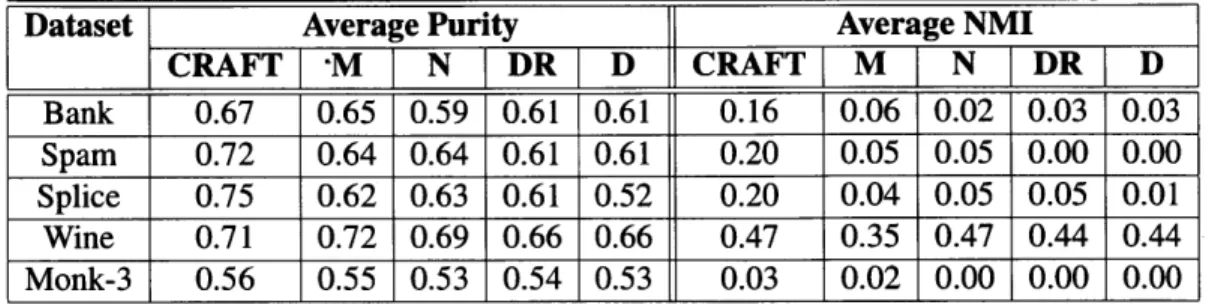

Documents relatifs
While tourists from all over the world may visit breweries in Newfoundland, the heart of this thesis is the brewers and business owners who started this industry, and all the
If we use a basic clustering algorithm based on the minimization of the empirical distortion (such as the k-means algorithm) when we deal with noisy data, the expected criterion
Show that the local ring O X,x is a discrete valuation ring.. Describe the valuation v and the uniformising
design; interaction design; experience design; highly interactive prototypes; programming; material; craft ACM Classification
Moreover, the paper describes a series of extensions and generalizations of this algorithm (for fuzzy clustering, maximum likelihood cluster- ing, convexity-based criteria,...)
Instead, start hoarding things that would normally end up in the bathroom trash.. That
Performance parameters (head and flow coefficients, head-loss and head ratios, void fractions, and system pressures) were correlated and plotted for data in the
Before joining Temple, Pilhofer was executive editor, digital, and interim chief digital officer at the Guardian in London. There, he led the Guardian’s product and technology teams
