Empirical Bernstein Inequalities for U-Statistics
Texte intégral
Figure

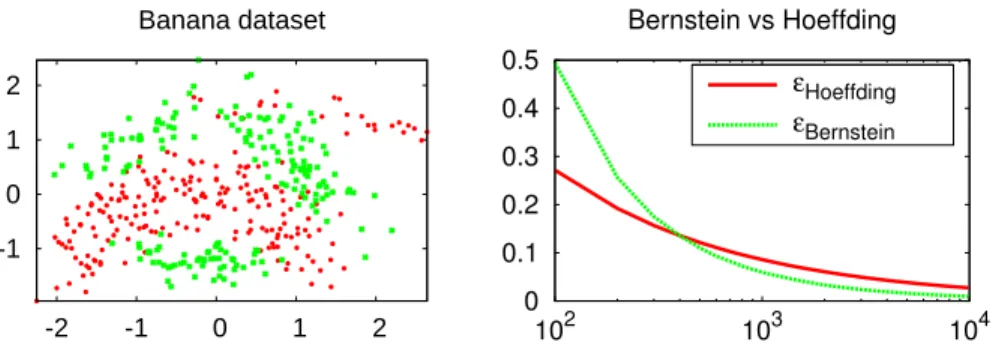
Documents relatifs
This paper is devoted to the study of the deviation of the (random) average L 2 −error associated to the least–squares regressor over a family of functions F n (with
/ La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur. Access
À cause de leur bonne résistance aux produits chimiques, les tuyaux de résines époxydes ayant un revêtement intérieur renforcé avec mat de fibre de verre C sont devenus très
Mit ruhiger Sprache und in abwägender Argumentation wird die zentrale These entfaltet: Der römische Bischof begründete seinen Primat in der Alten Kirche durch die sukzessive
Dessinez ou ecrivez le prochain objet qui devrait apparaˆıtre dans la suite.. Joyeuse Saint Valentin de la part
Hardy inequalities, Sobolev spaces, fractional Sobolev spaces, Sobolev and Morrey embeddings, Nemitzkii operators, maps with valued into manifolds, differential forms, pullback..
Moreover, we also suggest a sufficient condition on the parameters and firing distribution in the limiting conductance equation under which we are able to obtain a unique
5 In survey data, either the information about wealth is available at the household level only (in the Survey of.. Our results show that wealth became more individualized in
