Computer assisted design reflection : a web application to improve early stage product in startup companies
Texte intégral
Figure
![Table 2.1: The three types of design reflection as described by Reymen [22]](https://thumb-eu.123doks.com/thumbv2/123doknet/14441943.517092/18.918.140.768.298.476/table-types-design-reflection-described-reymen.webp)

![Figure 3-2: The priority queue algorithm for HAC, as presented in Manning [13].](https://thumb-eu.123doks.com/thumbv2/123doknet/14441943.517092/31.918.166.669.207.783/figure-priority-queue-algorithm-hac-presented-manning.webp)
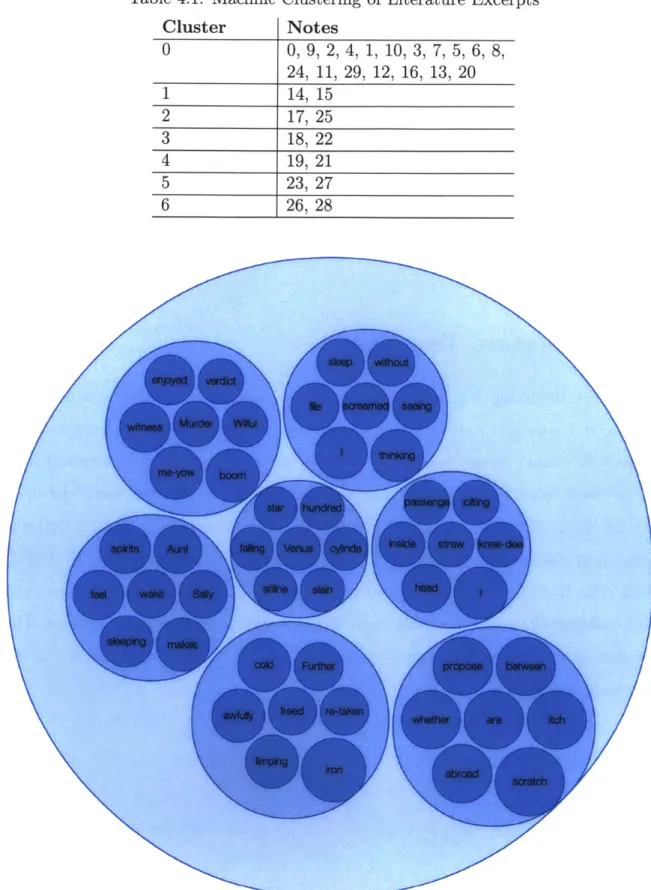

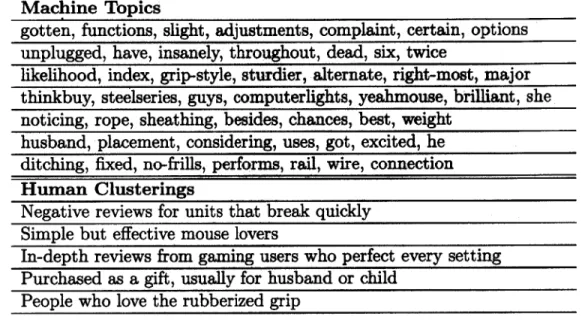

Documents relatifs
Moreover, at any point of E , we have df ^ 0 by Hopfs Lemma. So along E, 8p and 8f are proportional. In Definition 2, on then has to take wedges W^ with edge E. Then by the edge
6) What types of personal and partner’s markers (non-emotional/free, emotional/positive, emotional/negative) did learners use in their reports? 7) What kinds of reflection processes
We proposed a supervised symmetry detection method for multiple reflection axes inside an image in a global scale, in terms of voting representation and selection.. Our method is
The model in Figure 6 was obtained in the same way as the model in Figure 5 but with different weights: we increased weights associated with the velocity regularization and with
Natural language processing of incident and accident reports : application to risk management in civil aviation.. Université Toulouse le Mirail - Toulouse
from the size of the particles and generating diffusion mechanisms. Figure 9b shows the diffuse reflection spectrum of the same zeolite at 298 K, after activation for 10 h
In conclusion it can be said, that the business process management and organization development approaches explain how structures and processes can be adapted.. The organization
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
