P2P storage systems modeling, analysis and evaluation
Texte intégral
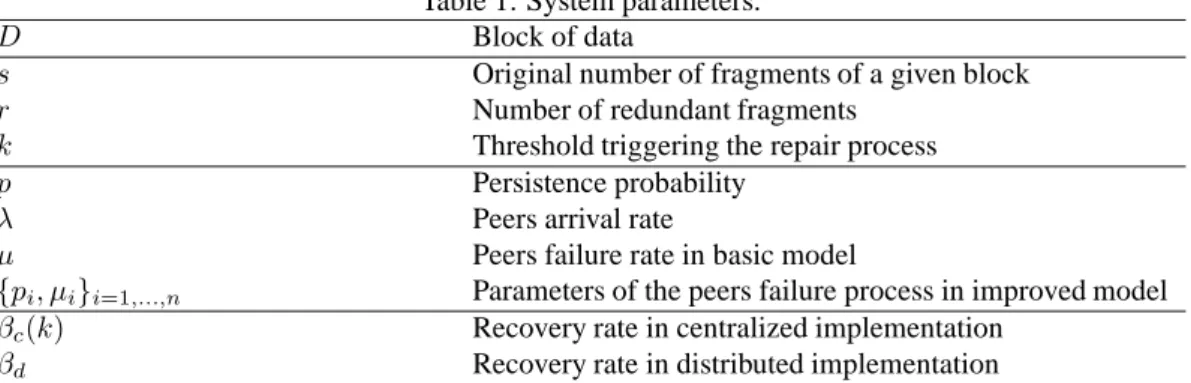
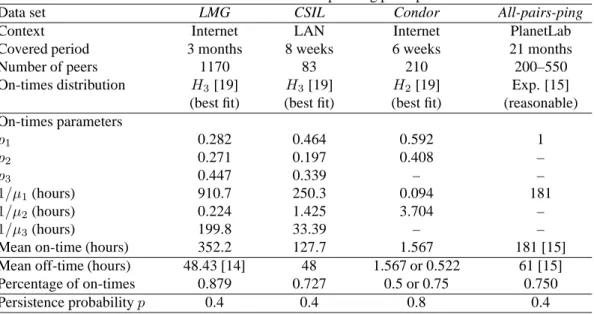
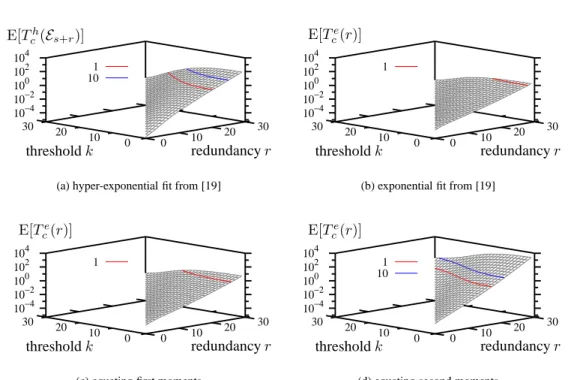
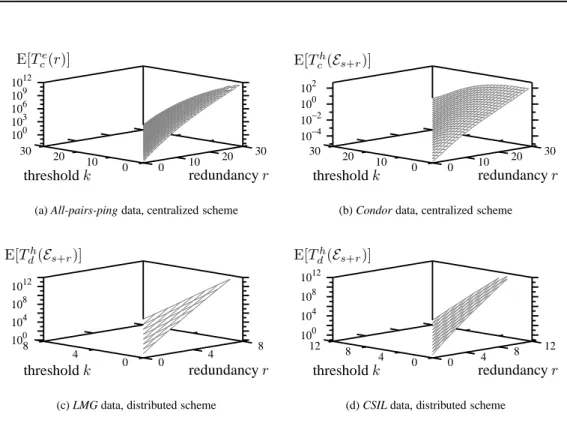
Figure


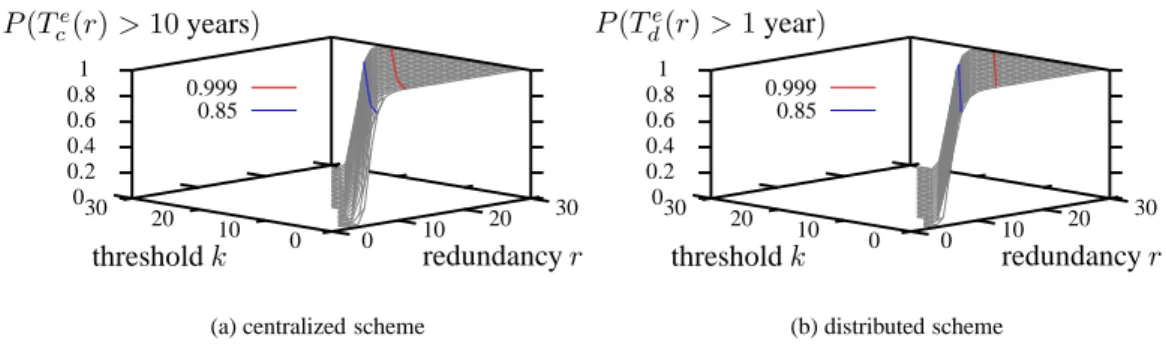
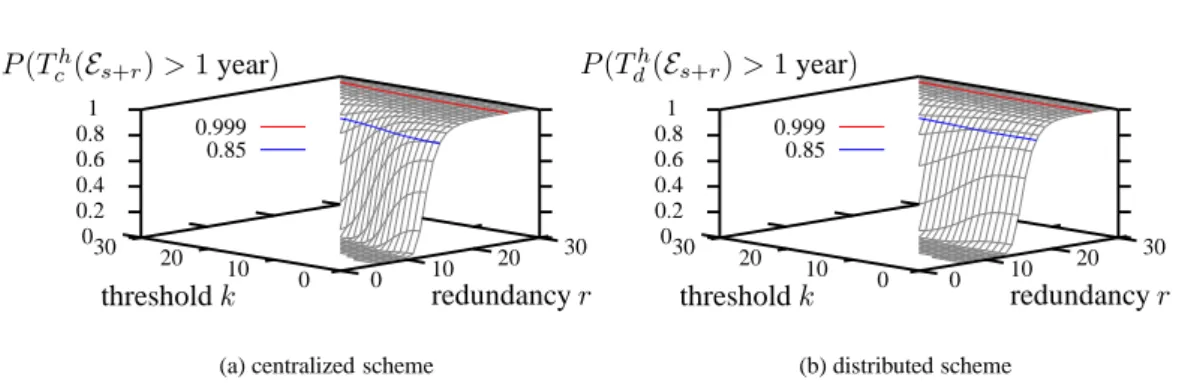
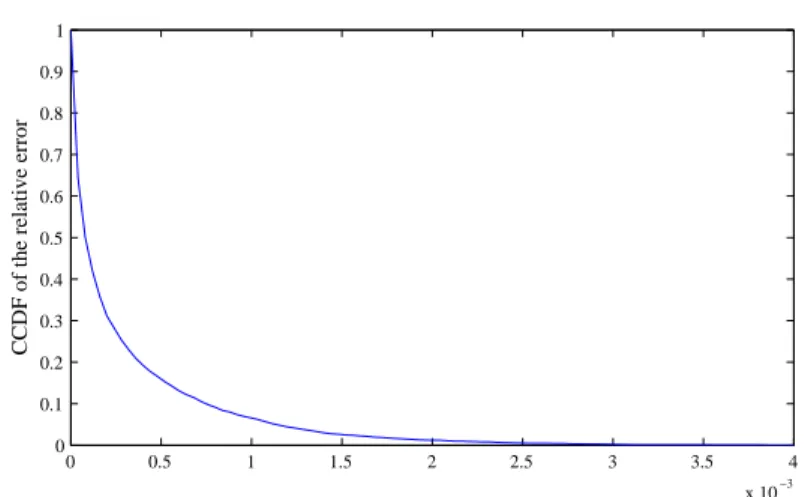
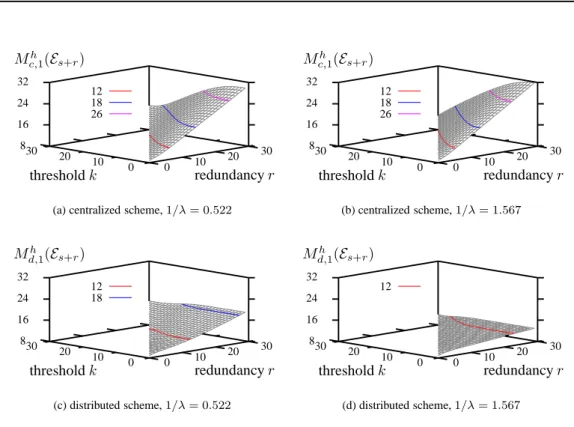
Documents relatifs
An insulator element and condensed chromatin region separate the chicken beta-globin locus from an independently regulated ery- throid-specific folate receptor gene.
ﻲﻫ ﺔﻴﺠﻴﺗاﱰﺳﻹا ةرادﻹا نأ ﻰﻠﻋ " ﱵﻟا ﺔﻴﻠﻤﻌﻟا ضﺮﻐﻟ تﺎﻴﺠﻴﺗاﱰﺳﻹا ﺮﻳﻮﻄﺗو ﺎﻬﻓاﺪﻫأ ﺪﻳﺪﲢو ،ﺔﺴﺳﺆﻤﻠﻟ ﺪﻣﻷا ﻞﻳﻮﻃ ﻩﺎﲡا ﺲﻴﺳﺄﺗ ﻦﻣ ءارﺪﳌا ﻦﻜﻤﺘﻳ ﺎﻬﺘﻄﺳاﻮﺑ ﺔﻴﻠﺧاﺪﻟا
In contrast, we prove that a dichotomy theorem for ec-homomorphism problems (even when restricted to bipartite target signed graphs) would settle the dichotomy conjecture of Feder
(C.1) We propose a unified MDP framework to minimize the expected caching cost over a random session of arbitrary length, while suggesting the user high quality content.. Our
However, due to the confinement of the first level (e 1 ) to a triangular well that is defined almost entirely by the internal electric field, the device would not be
In Pochoir, the user only specifies a stencil (computation kernel and access pattern), boundary conditions and a space-time domain while all optimizations are handled by a
Ainsi, il apparaît comme évident que pour obtenir un résultat exact lors de l’évaluation de telles fonctions dans les clauses HAVING et SELECT, il est
In the second part of the chapter, it will be seen that these same strategies, apart from affecting the fight against interstate fiscal dumping, affect the United States and the
