VI-Net: View-Invariant Quality of Human Movement Assessment
Texte intégral
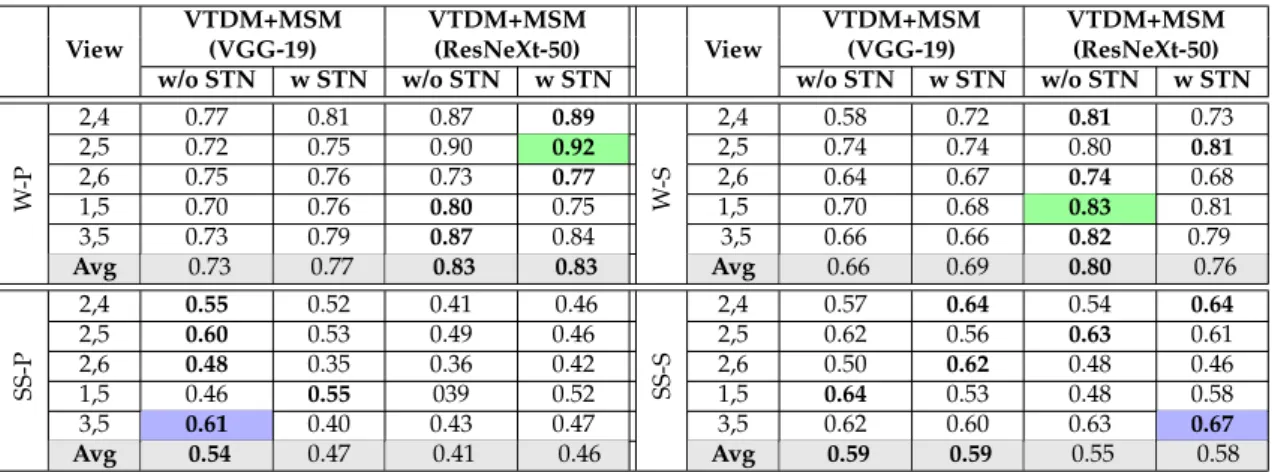
Figure
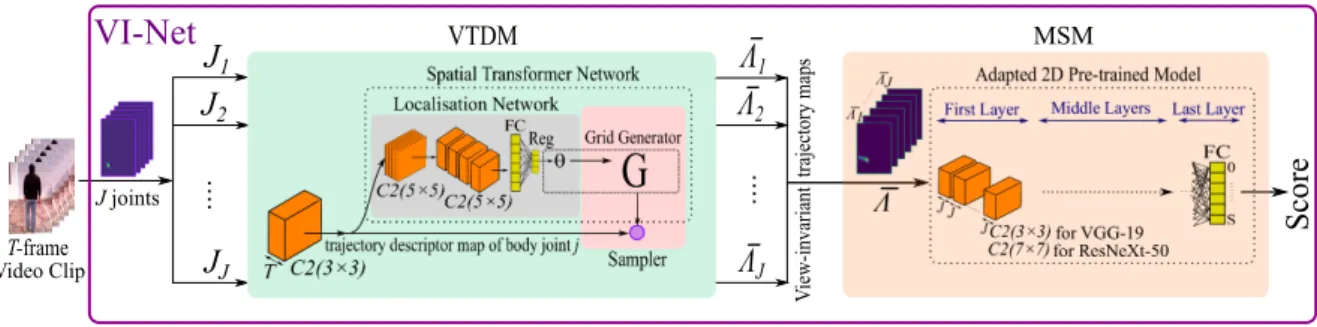
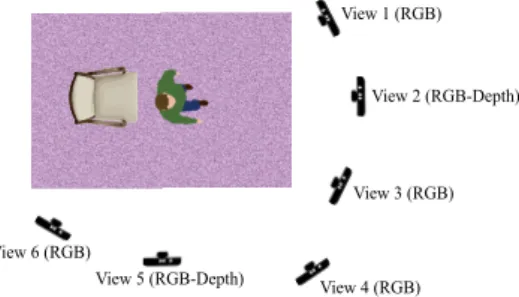



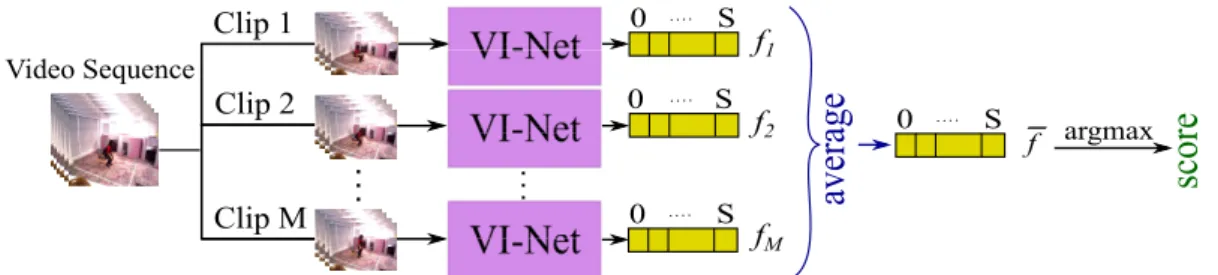
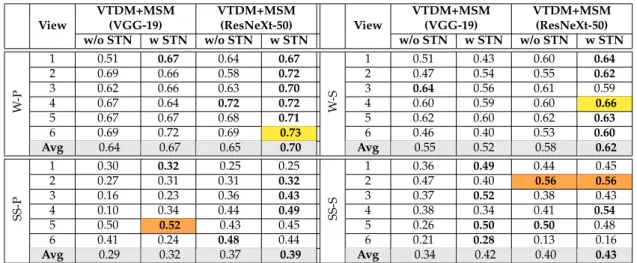
Documents relatifs
Kyu Park, “Robust Light Field Depth Estimation for Noisy Scene With Occlusion,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp..
Yang, “Robust object tracking via sparsity-based collaborative model,” in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,
Aggarwal, “View invariant human action recognition using histograms of 3D joints,” in Conference on Computer Vision and Pattern Recognition Workshops, IEEE, 2012, pp. Liu,
In this paper, they show that recent advances in computer vision have given rise to a robust and invariant visual pattern recognition technology based on extracting a set
Aggarwal, “View invariant human action recognition using histograms of 3d joints,” in Computer Vision and Pattern Recognition Workshops (CVPRW), 2012 IEEE Computer Society
Wang, “Hierarchical recurrent neural network for skeleton based action recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp..
Testing models for structural identiability is particularly.. important for
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
