AirGuardian: A Parallel Autonomy Approach to
Self-Flying Planes
by
Alexander W. Knapp
B.S. Aerospace Engineering, B.S. Electrical Engineering and Computer
Science Massachusetts Institute of Technology (2019)
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
May 2020
c
○ Massachusetts Institute of Technology 2020. All rights reserved.
Author . . . .
Department of Electrical Engineering and Computer Science
May 12, 2020
Certified by . . . .
Daniela Rus
Deputy Dean of Research/CSAIL Dir./Viterbi Prof.
Thesis Supervisor
Accepted by . . . .
Katrina LaCurts
Chair, Master of Engineering Thesis Committee
AirGuardian: A Parallel Autonomy Approach to Self-Flying
Planes
by
Alexander W. Knapp
Submitted to the Department of Electrical Engineering and Computer Science on May 12, 2020, in partial fulfillment of the
requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
Abstract
In this paper we lay the foundation for a fixed-wing parallel autonomy aircraft sys-tem in which both the autonomous component of the aircraft and the pilot jointly fly the plane resulting in an overall safer and more effective flying experience. Experi-menting with both imitation learning and reinforcement learning we develop the fully autonomous flight component of this system through the case study of flight within a canyon. Our strategy includes vision-based learning with both camera and depth map inputs to create an end-to-end learning platform for aircraft control. Using a yaw based controller and reinforcement learning, we are able to demonstrate stable flight in a unknown canyon environments that exhibit unexpected hazards such as wind gusts and terrain changes.
Thesis Supervisor: Daniela Rus
Acknowledgments
The author of this paper would like to thank Professor Daniela Rus and the Dis-tributed Robotics Lab at MIT for guiding this project and thesis. Additionally, the contributions of Alexander Amini, Hosea Siu, Ross Allen, and Kyle Palko were in-strumental to the results and timely completion of this thesis. Finally, a huge thanks is owed to the US Air Force for funding this program and the Air Force/MIT AI Accelerator for initiating the research.
Contents
1 Introduction 11
1.1 What is Parallel Autonomy? . . . 13
1.2 Project Objectives . . . 14 1.3 Project Schedule . . . 15 1.4 Personal Contributions . . . 16 1.5 Thesis Outline . . . 17 2 Related Work 19 2.1 Guardian Autonomy . . . 19 2.2 End-to-End Learning . . . 19 2.3 Imitation Learning . . . 21 2.4 Reinforcement Learning . . . 21
3 Learning for Autonomous Flight 23 3.1 Overview . . . 23 3.2 Assumptions . . . 24 3.3 Imitation Learning . . . 25 3.4 Reinforcement Learning . . . 26 4 Experiments 29 4.1 Simulation Platform . . . 29 4.2 Experimental Setup . . . 32 4.2.1 Overall Strategy . . . 32
4.2.2 Neural Network Design . . . 32
4.2.3 Machine Learning Techniques . . . 33
4.2.4 Training Environments . . . 35
4.2.5 Evaluation Strategies . . . 37
4.3 Results and Discussion . . . 38
4.3.1 Imitation Learning . . . 38 4.3.2 Reinforcement Learning . . . 40 4.3.3 Results Summary . . . 46 4.3.4 Comparison of models . . . 52 5 Conclusions 55 5.1 Future Work . . . 55 5.2 Lessons Learned . . . 56 5.3 Conclusion . . . 57 A Simple Model 59 B Reinforcement Learning 65 C Auto Flight 79 D Terrain Generation 85 E Videos Link 93
List of Figures
1-1 Proposed schedule for AirGuardian project. . . 16
2-1 A comparison of classical autonomous driving vs. end-to-end learning. 20 3-1 Overview of autonomous flight strategy. . . 24
3-2 Imitation learning pseudo-code. . . 26
3-3 Augmented reward calculations. . . 28
3-4 Loss calculations for reinforcement learning. . . 28
4-1 A generic mountaintop scene in our flight simulator. . . 30
4-2 Two different types of randomly generated maps. . . 30
4-3 RGB camera view and depth map view of the same scene. . . 31
4-4 Simple CNN model used for initial training. . . 34
4-5 Sub-components that make up our standard canyon environments. . . 36
4-6 Our plane flying in a canyon with adversary planes patrolling above. . 41
4-7 CNN activations for the cave scenario (left) and the enemy planes scenario. The network is very effectively able to find the spaces that have the longest range of open space. This works well in the cave but although the adversary planes are detected, the model is still interested in the open space between them. . . 42
4-8 Our plane flying sideways in the straight canyon. The orange above represents a no-fly zone. . . 44
4-9 An image sequence of our aircraft avoiding two consecutive random obstacles as they appear. . . 47
4-10 Flying through challenge environments. Note that although the canyon is a similar color as before, the model is operating using only depth map sensors and the shape of the canyons are very different than before. 48 4-11 Flight times. Note that testing runs were cut off after 5000 iterations,
so both the reinforcement learning setup in the simple environment and with added wind flew indefinitely. The two obstacles flights were run with varying frequency of obstacle appearance with obstacles having either a 1 in 50 or a 1 in 250 chance of appearing every frame. . . 52
Chapter 1
Introduction
Imagine you’re a pilot flying in a one-seater fighter jet. You’re in full control of a multi-million-dollar piece of metal hurtling through the sky at over 600 MPH, close to the speed of sound. Of course, you’re well trained for this job, having spent hundreds of hours in the classroom, training in simulators, and flying training missions. However, this is no longer just a training mission, and the aircraft on your tail shoots real guns and missiles. You did a pretty good job of performing evasive maneuvers and are in the clear for now, but the threat still exists. To make matters worse, one of the gauges in your cockpit is indicating that the aircraft is experiencing a problem of some sort, and the fog that you have been flying through has thickened considerably. Not to mention the fact that you have to think about navigation and returning to base before the aircraft runs out of fuel. As you diagnose the minor issue that you noticed, you continue to fly, operating the plane on feel, confident that despite everything that is going on, you are handling the situation rather well. Except that you’re not. In the heat of the moment, with all of the flipping and turning, you have actually gotten yourself turned upside-down. With no visual cues available due to the fog and your attention focused elsewhere due to the minor problem and everything else on your mind, you fail to notice other indicators and gauges in the cockpit passively notifying you of this fact. The feeling of what you assumed was gravity pushing you down into your seat is actually the feeling of your aircraft accelerating toward the ground at twice the rate of normal gravity. You’re in a pretty sticky situation, and chances
are, you might not even realize it before it’s too late to recover. But what if your plane made this situation easier to manage? This is where parallel autonomy in an aircraft can mean the difference between life and death. This system has allowed you to perform the necessary evasive maneuvers to avoid the trailing aircraft, but it now realizes that you are inverted, plummeting towards the ground and doing nothing about it. The system may warn you that you are flying inverted before the situation gets out of hand, effectively helping you manage the many different stimuli that you are trying to focus on all at once, or maybe it will simply take over and prevent you from crashing into the ground. Maybe the system will even help you with the evasive maneuvers from earlier, performing them more optimally and preventing the minor issue that you noticed altogether. Regardless of how, with the assistance of a parallel-autonomous system, you are now able to complete the mission and return home safely.
This is just one example of why autonomy in aircraft can be useful as there are plenty more dangerous tasks that pilots frequently have to accomplish. For example, aerial refueling is not only an extremely precise maneuver, if the aircraft getting refueled exits the air refueling envelope there is a possibility of collision with the other aircraft or breaking of the fuel hose, it can also be quite a long and boring procedure; some larger aircraft require over a half an hour of refueling to fill up. That would be like if slightly deviating from a highway lane at any point during a long trip resulted in catastrophic failure. Instead, an autonomous system can ensure that the aircraft maintains the correct position, allowing the pilot to focus on his next task instead of precisely maneuvering his plane.
Another example is a potential dogfight situation where the pilot flies into a canyon system to try to lose the trailing aircraft and now needs to stay within the canyon walls to avoid detection. Flying in a canyon can also be quite tricky depending on how close the walls are and how quickly it turns. Maybe there are even unexpected wind gusts that will push the plane in an unplanned direction. Having some amount of autonomy on the plane to help the pilot from accidentally clipping the walls could be the difference between escaping the situation and losing control of the aircraft. In
this thesis, this is the main scenario that we focus on as a preliminary thrust into the problem of autonomous flight. However, having a working framework for this problem doesn’t mean that exclusively this situation can be handled and instead allows for quick transitions to other potential situations that an autonomous aircraft system could be used.
1.1
What is Parallel Autonomy?
Having a plane that could do these things for you would be amazing; pilots would not only be much safer in the air, but they would also be much better at completing their missions. However, what does it mean for a machine to be using parallel autonomy, and how does one use a parallel autonomy system on an aircraft? With parallel au-tonomy, the human user is still in control of the vehicle, but an autonomous system makes decisions based on the state of the world at the same time. If the autonomous system determines that the human is about to make a mistake for whatever reason, it will correct the human behavior to avoid whatever hazard the human may have oth-erwise encountered. In situations where the pilot is less experienced, the autonomous system can guide the pilot towards making the correct decisions or even take over control completely. With this system human operators can handle their vehicles much more safely and importantly, are now able to interact with their AI counterparts in a safe way that creates a smooth stepping-stone to fully autonomous and safe systems. Excitingly, systems such as this already exist in autonomous car contexts. In the Guardian Autonomy project accomplished by MIT’s Distributed Robotics laboratory [20], parallel autonomy is introduced and used with autonomous cars. In this project among others, end-to-end learning techniques have allowed autonomous cars to drive effectively simply from observing expert humans drive. Unfortunately transferring the results of these projects into the autonomous aircraft domain isn’t quite as straight-forward as running the same system on a different vehicle. Simply put, there are quite a few differences between the domain a car has to deal with compared to that of an aircraft. There are some scenarios that cars often have to deal with that are not nearly
as commonplace for aircraft, such as lots of traffic and pedestrians. Depending on the specific aircraft scenario, there are many more open spaces and far fewer additional objects to worry about. On the other hand, autonomous aircraft bring a lot of their own challenges too, such as maneuvering in three-dimensional space as opposed to two. Making control decisions and navigating in this environment suddenly becomes a lot more challenging. Additionally, with the high risk environment that comes with acrobatic flying, a method to effectively mitigate this risk needs to used. This results in the need for the development of a high fidelity simulator for testing and verifying results before live testing can begin. Accordingly, this need helps shape the direction of this thesis, which is discussed in more detail in section 1.3.
1.2
Project Objectives
As a whole, the planned approach for this project is to follow the pathway set by the Guardian Autonomy project for self-driving cars. It is planned to be a multi-year project; however, this thesis only encompasses the first multi-year of the project. The objectives of the project all stem from the goal of creating a parallel autonomous system that will assist pilots during flight; a system that effectively manages cognitive overload, reduces stress in high pressure situations, and helps deal with uncertain and unexpected circumstances. Using this system, if fully implemented, every pilot will be able to fly as if they’ve had years of experience, and unexpected events will cease to be nearly as dangerous as they currently are.
With that in mind, the specific objectives that will allow for the successful comple-tion of this project are as follows. First, develop an end-to-end vision-based learning platform for fixed-wing aircraft maneuver execution using imitation and reinforcement machine learning techniques. This results in the ability of the autonomous system to fly in unknown environments without the help of a human pilot. Next, integrate the human control aspects of flight into the system, creating a similar result to the Guardian Autonomy project. This will allow pilots to maintain control over the plane but get corrected in situations where they may have otherwise made a mistake, such
as surprise events or situations where the pilot experiences cognitive overload. This thesis focused on the first objective, setting up the framework for the machine learn-ing platform and trainlearn-ing the system on a specific use case of flylearn-ing autonomously through a randomly generated canyon. The goal that we set out to achieve with this system was the ability to fly in previously unseen canyon environments with potentially unexpected weather conditions and/or obstacles.
This thesis research and corresponding paper set up the framework to continue ex-ploring the possibilities of fixed-wing autonomous flight and attempt to fully automate an aircraft to handle the specific task of flying through a canyon. Using a combination of imitation learning and reinforcement learning, the aircraft will be trained to avoid canyon walls while dealing with unexpected weather conditions and terrain changes. In future research applications, we hope to demonstrate novel techniques for avoiding dynamic obstacles and coordinated multi-agent flight with autonomous fixed-wing aircraft.
1.3
Project Schedule
The timeline for the entirety of the AirGuardian project is detailed in Figure 1-1. This thesis breaks up the first portion of the AirGuardian project goals, namely developing a vision based end-to-end learning framework for autonomous flight train-ing. The steps that were taken to achieve this goal consisted of choosing a platform to host our system, developing a flight simulator that would be able to handle the training and evaluating tasks as we desired, creating an interface to allow for open communication between machine learning models and the developed flight simulator, creating and training the machine learning models, and finally, testing the models in various environments and conditions to ensure robust execution of flight objectives.
Figure 1-1: Proposed schedule for AirGuardian project.
1.4
Personal Contributions
As the author of this thesis and one of the main contributors to this project’s code base, it is important to differentiate which portions of the project were contributed by myself as opposed to the other members of this project. Most of the programs written for this project were written by me with guidance from my mentor Alexander Amini, a member of the Guardian Autonomy team. Accordingly, he provided assistance with overall strategy for much of the code base organization and added crucial knowledge of what information would be needed to train our system similarly to the Guardian Autonomy system that he had previously worked on. Programs that I wrote with this assistance include all of the flight simulator programs and the python API that was used to interface with this simulator. Most of the features in the simulator were written by myself, and likewise, I solely developed the terrain generation program for our main procedurally generated canyon scenario. For neural network design, Alexan-der provided the initial model and various iterations of this model were developed in coordination by both of us. Furthermore, the programs for imitation learning and reinforcement learning training were written jointly. All programs for aircraft flight using these neural network models were written by myself as well as any test scripts for the aircraft performance. Finally, scripts that were not written by me include our alternate canyon generator script, written by team member Hosea Siu, a script that was written to improve the dynamics of the aircraft in our simulator, also written by Hosea, and the program that was written that allowed us to label data as useful or not, which was written by Alexander.
1.5
Thesis Outline
This thesis paper is structured as follows. Following the introduction to the paper and the subject, related works to the subject will be discussed. This includes the different types of techniques that have been used in this paper as well as a few of the applications that those techniques have had in autonomy thus far. Subsequently, assumptions and algorithm details will be described. This section will guide the reader through the setup for our project and how we went about preparing to run experiments. After that, the paper runs through the experiments that we actually ran on these systems, noting the variations to the different techniques that were used. Finally, the conclusions and lessons learned from these experiments will be discussed as well as future directions that this project can be taken.
Chapter 2
Related Work
2.1
Guardian Autonomy
The most significant works related to this project come from the Guardian Autonomy project being performed in MIT’s Distributed Robotics Laboratory [20]. In this project, parallel autonomy is described and used to control a car in various levels of autonomous function. The Guardian Autonomy project was the inspiration for this AirGuardian project and consequently consisted of many of the same features of parallel autonomy. Specifically, these types of autonomous systems maintain human control, but also run an autonomous system at all times in the background. This allows for the autonomous system to intervene when it is determined that the human is making an error or getting into a dangerous situation. It can also help out the user during high stress and high cognitive load situations.
2.2
End-to-End Learning
Additionally, this project includes an end-to-end learning framework for autonomous execution. In Bojarski et al.’s paper, [7], the authors show that using a convolutional neural network they can go directly from input images from a camera at the front of the car to steering commands. Amini et al.’s papers, [2] and [3], also demonstrate use of end-to-end learning and apply this technique to a parallel autonomous system.
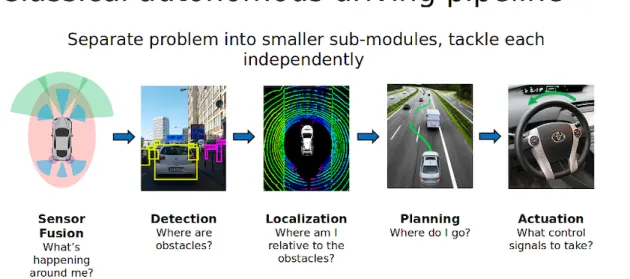
End-to-end learning and how it differs from classical approaches for autonomous nav-igation is described in Figure 2-1. End-to-end learning techniques have been shown to have many applications, with some authors even using it in agricultural domains [5]. And similar to our approach, some papers use end-to-end learning techniques to navigate autonomous aircraft [1], [16], though in these papers, the autonomous aircraft are quadrotors.
2.3
Imitation Learning
Imitation learning, also known as learning from demonstration, is a useful technique for machine learning when exact rules for how to control a system are not easy to articulate. It is particularly useful in this project. In Argall et al.’s paper, [4], the basic concepts of imitation learning are described; the neural network system is trained to imitate behavior from of an expert at whatever task is being performed. The paper also describes many of the different forms of it that can be used. Imitation learning has already been shown to be useful in many driving applications [21, 17, 10, 8, 26, 12] and quadrotor flying environments [24, 19, 18]. There are even some papers in which the authors use imitation learning for the task of fixed wing flight, such as the paper by Baomar and Bentley [6], in which takeoff procedures are learned in various weather conditions. Many of these imitation learning-based systems utilize end-to-end learning as the method by which they control their vehicles [21, 8, 26, 12], though some use other techniques such as a pre-designed control system to control the vehicle based on inputs from a convolutional network [18].
2.4
Reinforcement Learning
Finally, a large portion of this project relies on reinforcement learning. This unsuper-vised machine learning technique allows the agent to interact with the environment around it, earning previously defined rewards or penalties based on which actions it takes. Kober et al.’s paper [15] surveys the use of reinforcement learning in robotics
and discusses some of the different strategies for using reinforcement learning effec-tively. In this paper, REINFORCE, is described. This technique, which we use in our project, allows for the neural network to directly learn a polity for the agent to follow rather than a value function from which the policy can be derived. Reinforce-ment learning has also been quite useful in many autonomous robotics applications, so much so in the field of autonomous driving that it is simpler to cite Kiran et al.’s review of reinforcement learning and it’s various applications within autonomous driving [14] rather than the multitude of articles that have been written. And simi-larly to imitation learning, reinforcement learning has been used in many quadrotor environments [23, 13, 22, 25] as well as some fixed wing scenarios [9, 11]. However, many of these cases deal with performing specific maneuvers instead of generic flight situations.
Chapter 3
Learning for Autonomous Flight
In this section, we will explain how our algorithms for autonomous flight work, includ-ing the assumptions that we have made when creatinclud-ing these systems. The reasoninclud-ing for the overarching strategy is also discussed.
3.1
Overview
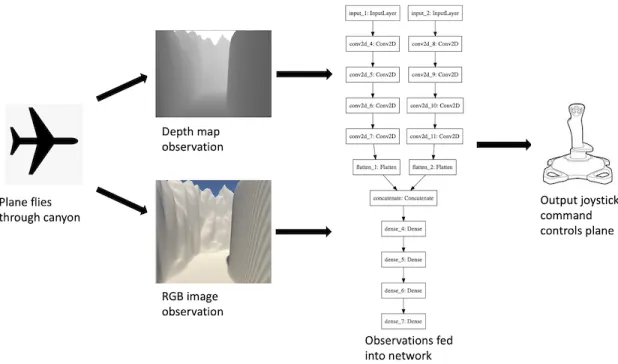
The main objective for these experiments was to have the aircraft fly for as long as possible in randomly generated canyon environments. On top of that, training a model that could handle disturbances such as changing weather or unexpected obstacles was desired. An architecture diagram outlining our strategy for flying the plane via neural network is displayed in Figure 3-1.
Since flying an aircraft in a canyon is not a particularly straightforward task, we decided to first use imitation learning to train it. That way, all we had to do was have a human pilot fly in our environment and record relevant data from the flight. From there, we could directly train the neural network model to mimic the pilot. After experimenting with imitation learning for a little while, we decided to try a different method of training. One reason for this was the desire to potentially get solutions to scenarios that our human pilot might not have come up with on his/her own. Another reason was to allow for easier and broader data collection. Both of these objectives could be accounted for by using reinforcement learning for training the aircraft, so
Figure 3-1: Overview of autonomous flight strategy.
this was the next approach that we used.
3.2
Assumptions
A lot of the major assumptions that we decided upon showed up in our flight simulator design. The most striking of these assumptions relate to the flight dynamics of our aircraft. In this situation we pressed forward with the assumption that training a system on a simulated aircraft with somewhat unrealistic dynamics would still transfer over to useful results in real world tests. While we don’t necessarily expect live demo tests with real aircraft to function the exact same way as they did in our simulator, we do believe that demonstrating functionality in the simulator as a proof or concept will allow us to quickly transfer over results to the real world. At the time of writing, we have not been able to test this assumption, however we intend to in the near future.
In addition, we relied a lot on using a depth sensor for our training in our simulator. This makes the assumption that a real-world depth sensor would be able to achieve
comparable amounts of range and accuracy as the sensor we used in our simulator. In a different vein, we also assumed that this scenario that we tested on could potentially be useful in real life and that our framework, beyond that, could allow for quick transfer to more scenarios and capabilities. This canyon flying scenario is far from the only situation we want our autonomous system to be able to handle, so in the future we plan on using the framework that we have set up to continue to develop this autonomous system to handle many different types of situations.
3.3
Imitation Learning
At its core, imitation learning in our case is having a pilot fly a plane in an environment and then asking a neural network model to learn effective equation weights so that it can output controls to replicate the behavior our pilot exhibited. The steps to completing this are as follows.
First, have the pilot fly in an environment and record everything he sees and does from a control standpoint. This means recording the RGB image view from the plane’s cockpit and the control inputs that the pilot gives using the joystick lever. In addition, it is helpful to record a depth map representation of the same RGB cockpit view.
Next, ensure that all control commands are properly synced with the image and depth views that correspond to the same time step and filter out any useless or detrimental image command pairs where the pilot made a mistake in judgement.
Once the data has been properly filtered, train the neural network using gradi-ent descgradi-ent. To do this, pass in a batch of image and depth map inputs from the recorded flight data into the neural network and receive corresponding control outputs for each input. Then compare these outputs to the control actions that the pilot took by calculating the mean difference squared between the values. This is the loss of the network for that specific input and is a measure of how well the network mimicked what the pilot did in that scenario. Using the loss, gradient descent can be performed to update the model’s equation weights in the direction that will most help the model
Figure 3-2: Imitation learning pseudo-code.
better perform that scenario. Training the model on multiple scenarios at the same time helps ensure that the model doesn’t too heavily rely on any one scene at a time and ends up helping push the model towards a better generalized solution. These gradient descent updates were done using TensorFlow’s Keras library, which auto-matically takes gradients of each equation in the neural network and then applies the result to update the weights of each equation. Pseudo-code describing this algorithm is seen in Figure 3-2. The learning rate parameter of each update was determined using TensorFlow’s Adam optimizer.
3.4
Reinforcement Learning
The reinforcement learning algorithm shares a few similarities to the imitation learn-ing algorithm. The gradients are calculated the same way, and the weight update equation remains the same. However, the loss function is calculated differently, the way the algorithm is run is different, and even the model itself changes slightly. Our full reinforcement learning code can be seen in Appendix B.
Instead of already having the data that the model will be trained on, data is collected during training time. To do this, we set the plane up in the environment and have it fly based on the current state of the model. Each time step that the plane flies, it is either given a reward for not crashing or no reward if it does crash in that time step. Once the plane crashes, it starts over in a safe location. The data for training now becomes what the plane saw at a given timestep, which consists of RGB image and depth map image, as well as the augmented reward that corresponds with that timestep.
There are two things that need to be clarified with how the data collection works. First, having the plane fly based on the current state of the model no longer means having the model output what it thinks the best possible output is and then per-forming that action. If this was the method that was used, it would be very easy for the model to find a non-optimal local best solution and get stuck using that solution repeatedly without ever updating to find a better solution. Instead, it is important to have the algorithm not only pick solutions that it thinks are good, but also ex-plore other possible solutions in an attempt to eventually find a better solution. This is one of the most important tenants of reinforcement learning known as the explo-ration versus exploitation trade-off. In order to do this, we treat the best possible output from our network model as a mean term, and we add an additional output to the network that gets used as a standard deviation term. Using these two terms, we can sample from a Gaussian distribution with our specified means and standard deviations to obtain a semi-random control to give the plane that is still centered about our model’s current best possible solution. The benefit of having the standard deviation term defined by the model itself is that as the model starts to learn that a particular part of the solution is good due to consistent large rewards, it will decrease the standard deviation so as to continue to use similar solutions, or in other words, exploit positive results. When the model learns that a particular solution is not very good due to lack of large rewards, the standard deviation will increase, allowing the model to explore more solutions farther away from the current best solution.
The second point of clarification is the method by which rewards get converted into augmented rewards. Each timestep, the aircraft potentially gets a reward, but it makes sense to give larger rewards to actions that increase the total flight length than to actions that decrease it. For example, if a plane hasn’t crashed yet but is very close to the wall, a larger reward should be given for turning away from the wall than from turning towards it. The way this augmented reward is calculated for a particular step is by adding that step’s reward to the augmented reward of the step after it multiplied by some discounting factor. In order to be able to calculate these, all augmented rewards are calculated after a flight has terminated. Then, the rewards
Figure 3-3: Augmented reward calculations.
Figure 3-4: Loss calculations for reinforcement learning.
are all normalized to account for differences between training flights. The augmented reward calculation is shown in Figure 3-3.
Once data has been collected for a particular flight, the model is trained using gradient descent as before. Then the new model is used to control the aircraft during the next flight. The loss for this training is determined as a combination of how likely it was that the model took a given action, using the negative log likelihood of the Gaussian from earlier, and the discounted reward for that action. The equations for computing the loss at a given time step are shown in Figure 3-4. Once the loss is calculated, the rest of the update algorithm is the same as the one for imitation learning.
Chapter 4
Experiments
In this section we perform experiments on the environments that we set up in our aircraft simulator. For each test that we run, we have the option to generate a new terrain or use one that we have already done testing on. We can also decide whether or not to add wind disturbances and to have random obstacles appear as the aircraft flies. As we test the aircraft in these environments we want to see the planes fly for as long as possible before crashing, which can simply be tested by recording how long each flight goes before crashing.
4.1
Simulation Platform
Much of the research in this project hinged on the successful use of a pre-existing environment or the creation of a new environment in which the behavior of the au-tonomous system could be observed. Since the goal of this step of the project was to create an autonomous system that flew based on visual input clues, it was paramount to use a flight simulator that allowed for real time access of cockpit views that could be manipulated by the program as the plane flew. Additionally, the simulator had to support fixed wing flight as our project was focused on fixed wing flight. After a bit of searching, no suitable pre-existing flight simulation environment existed, so we decided to develop our own which would allow us to interact with all aspects of the environment in whatever ways we desired.
Figure 4-1: A generic mountaintop scene in our flight simulator.
Figure 4-2: Two different types of randomly generated maps.
We chose to construct this aircraft simulator on a game and simulator development platform called Unity. Using this platform, we are able to create unique environments and maps for our aircraft to fly through. An example of a generic scene created in our flight simulator is shown in Figure 4-1. Adding on to this functionality we were able to create procedurally generated loops for the aircraft to fly in, allowing us to train our autonomous system on a variety of different maps. Examples of two different types of these generated maps are shown in Figure 4-2. The terrain generation program for our main canyon setup can be referenced in Appendix D.
Figure 4-3: RGB camera view and depth map view of the same scene.
needed and access all relevant information about those planes as they flew through the generated environment. This information included world location, orientation, and velocity values as well as real time video feeds of the plane’s cockpit view of the world and a depth sensor view of the same scene. The plane’s RGB cockpit view and the corresponding depth sensor view of a scene are shown in Figure 4-3. All of these values were made available during flight, providing the necessary information to train and evaluate a vision based autonomous flying system. These values, as well as control inputs given to the plane could also be recorded during each flight to be used for later training.
It is important to note that the dynamics used to control the aircraft during these flight tests were not particularly realistic. Drag was not modeled, and the vertical component of lift was always assumed to offset gravity exactly, regardless of roll angle. Consequently, the aircraft simply flew in the direction that its nose was pointing, and gravity only served to speed up or slow down the plane if it pitched down or up respectively. One of the more unusual outcomes of this resulted in the plane being able to fly sideways without losing altitude. Additionally, minimum and maximum speeds were enforced on the aircraft to ensure that it would not slow down arbitrarily or even start flying backwards.
4.2
Experimental Setup
4.2.1
Overall Strategy
With our plane environment and interaction tools set up, the next stage of the project was to create neural network models based on how we intended to fly our autonomous system. These models, in turn, would train our system and in the future, fly it. The first step was to decide an overarching strategy for how our plane would be flown. For this, we decided to use an end-to-end learning framework, which means the input image feeds are given to our neural network structure and our network outputs values that directly control the aircraft.
4.2.2
Neural Network Design
Next, we had to structure our network in a way that could appropriately handle this task. Since we would be processing image feeds from our cockpit RGB camera and depth sensors, we made the first few layers of the network convolutional layers. Initially, we composed this first half of the network with two parallel branches of convolutional layers, one branch for each video stream. However, later, we ended up only training using depth map video streams for simplification, allowing us to remove one of these branches and create a single input network. Another variation that we applied to our network was using pretrained ResNet50 neural network models with the classification layers removed as reliably trained replacements for our simple convolutional layer branches. This structure, however, contained more information than necessary, was more memory intensive, and also slower, so we avoided it when we could.
This first half structure of our network allowed us to segment the images into important versus irrelevant features, which would then be passed into the second half of the network allowing for suitable controls to be decided based on the relevant features. This second half of the neural network composed of fully connected layers allowing for direct translation from feature maps to a wide variety of potential control
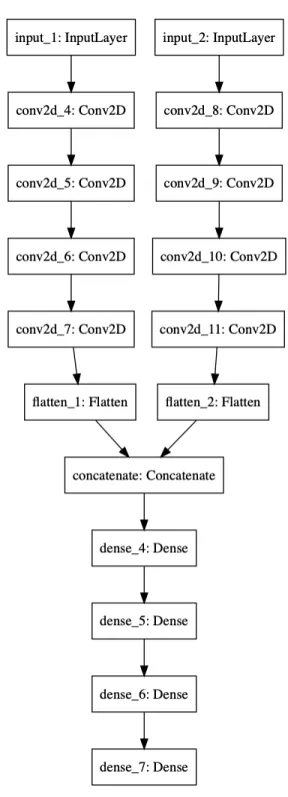
values. A visual representation of our initial neural network model can be seen in Figure 4-4. The implementation of our simple model that we used later on in the project is transcribed in Appendix A.
4.2.3
Machine Learning Techniques
Now that we had a model to train, the specific training strategies that we would use needed to be set up. As previously mentioned, we planned on training our network both with imitation learning and reinforcement learning. With imitation learning, we would first have an expert pilot fly the aircraft in our simulated environment. While this pilot flew, we needed to record the relevant information for training our network. Since the input to the network was simply video and depth map streams, we needed to record both of those from the cockpit view of the plane while the pilot flew. Additionally, we recorded velocity and orientation information about the plane as it flew as potential useful augmentations to our initial model. On the output side, we needed to record the control inputs that the expert pilot used that corresponded with the input that the pilot saw at that same time. These control inputs came from a joystick that we used to control pitch and roll values for the plane. Later, we also experimented with using this joystick to provide yaw controls for the plane instead. The control setup was such that pushing the joystick to the left would roll the plane to the left and pushing the joystick forward would pitch the plane nose down.
In addition, our imitation learning setup required us to have a way to pre-process our data before training the neural network with it. Since even our expert pilot did not have perfect reaction time and did not always make the best decisions for every given scenario, we needed a way to separate useful data from junk data. By displaying each given control input overlaid on the image frame that was recorded at the same time, we were able to label specific frames of data as reliable or not. Furthermore, this allowed us to ensure that our recorded control inputs were properly synced up with their corresponding image frames.
The second training strategy, reinforcement learning, did not require much addi-tional framework as the input to the network remained the same. However instead
of comparing the outputs that the network gave with controls that the expert pilot gave, this strategy needed to have feedback from the environment that would help the model learn what correct flight should look like. This meant that information such as when the plane ran into a wall or flew out of the canyon needed to be sent to the model to be used. Additionally, we made minor changes to our models based on information that we had learned from training with imitation learning, including only using depth map image streams and reducing the number of fully connected lay-ers used to translate image activations to control actions. The actual reinforcement algorithm that we used to train the neural network model was REINFORCE.
4.2.4
Training Environments
Throughout the course of our experiments we used multiple different training envi-ronments, all of which were structured as some sort of canyon that our aircraft had to fly through without crashing. We wanted the canyons that we used to have a random combination of straightaways, left, and right turns. We also wanted to be able to generate new canyons that had these types of turns in an unspecified order so that we could test if the plane would learn how to avoid walls and make turns in a canyon system that it had never scene before. To do this, we created canyon subsections that consisted of left and right turns from all four cardinal directions as well as vertical and horizontal straightaways. Then we randomly combined these shapes to create loops. This is what we used as our standard canyon setup in which we did the majority of our neural network training. The subsections that our canyon was created from are visualized in Figure 4-5.
Another canyon generator that was used utilized convex hull operations to create loops. This resulted in canyons that also included random turns with the added ben-efit of containing turns other than 90o to the left or right. This method of generating canyons also allowed us to easily change the width of the canyon the plane was flying in, ranging from wide bowl like structures to steep walls just barely separated by more distance than the airplane’s wingspan. These canyons also served as an additional diverse way to test the models on canyons that they had not been trained on, not only
varying in the order of turns, but also in the layout and appearance of the canyon as a whole.
In addition to the canyons that the plane flew through, we made further mod-ifications to the environment to test the model’s ability to respond to unexpected behaviors such as added wind to push the plane around and randomly appearing obstacles. Randomly appearing obstacles manifested as walls spanning the entire height of the canyon and about the width of the airplane that would appear at ran-dom about three plane lengths exactly in front of the direction the plane was flying at that moment in time.
4.2.5
Evaluation Strategies
After the neural network had been set up and trained, it was important to properly evaluate whether or not it performed well. For imitation learning, one possible solu-tion is to feed the network cockpit view images from an environment that the expert pilot flew the plane in. Then the outputs given by the network can be directly com-pared to the controls that the pilot used at that same point in the canyon. Plotting the pilot control input versus the network output for each control variable individ-ually should result in an approximate diagonal line with a slope of one. The closer the approximated lines are to this ideal line, the better the network was at exactly mimicking the pilot. This strategy required very little additional setup to test the networks.
Another strategy that works well for both training techniques is simply flying the plane in a newly generated an environment to see if the plane crashes or not. Information such as flight time until crash is one metric that can be used other than just visual inspection of the flight. To set this up, a script needed to be written that would fly the plane entirely with whichever model of the neural network was loaded. This script can be seen in Appendix C. It was used to test both training techniques.
4.3
Results and Discussion
Beyond the baseline learning techniques with the simple model that we created, we went through many iterations of models, input and output structures, and flight envi-ronments to evaluate how the learned algorithm behaved in various different scenarios. In the next two sections, the results that we achieved using various adaptations to our setup are discussed. Most of the results are given in the context of how well the plane was able to fly autonomously in a random environment without crashing into the walls. Select videos of our models performing autonomous flight can be accessed using the Dropbox link in Appendix E.
4.3.1
Imitation Learning
The first learning technique that we tried was imitation learning. With this, the quality and breadth of expert pilot flight scenarios was especially important. Early on we realized that just having the pilot fly around in various generated environments was not enough to sufficiently train the network. Since flying in the canyon was relatively straightforward, the expert pilot rarely deviated from safe flight in the middle of the canyon. As a result, there was very little training data for when the autonomous plane deviated from this region, and consequently, the model would not know how to recover when it ended up in an unsafe location in the canyon resulting in completely random movement. To solve this problem, two approaches were used. First the expert pilot’s flight would start in a relatively safe random location and orientation, forcing the pilot to recover back to the safest possible flight. To ensure that this recovery process happened more frequently, every so often while the pilot flew, the plane would get teleported to a nearby location or would have its orientation changed. Not only did this force the pilot to execute more recovery maneuvers, but it also ensured that the pilot flew the plane in the safest part of the canyon whenever possible to avoid the possibility of having the plane randomly teleport into a nearby wall. This random state change procedure made the preprocessing data for usable and non-usable control actions especially useful as the pilot was not able to react
instantaneously to these state changes. Using this approach resulted in a much larger coverage of potential canyon locations and aircraft orientations, allowing for much better autonomous flight results.
From these initial tests we learned a few things. First, even using our strategies to gain more canyon coverage from the expert pilot, we were not collecting enough data for all possible scenarios to fully train our simple network. Due to this, using the pretrained ResNet50 models to replace our image processing convolutional branches resulted in better results at this stage of the experiment. However, due to the size of these networks, we were unable to run them efficiently in real time as they were currently set up. Instead of having one ResNet50 model for each input video stream branch, we only had the time to run one image through one single ResNet50 model before the next image came in and needed to be processed. To alleviate this issue, multiple solutions were attempted, including condensing the images into two channels and putting the depth map in the third image channel. In the end, completely ignoring the RGB image stream and relying entirely on the depth map images gave the best result that still allowed for real time execution.
Second, we learned that the models that we trained had trouble differentiating between open space that resulted from turns in the canyon and open space that existed above the canyon. In other words, our model learned to very effectively turn in the direction of open space that was orthogonal to the open space in the current straightaway of the canyon. This meant that unless there was an immediate turn in the canyon, the aircraft would simply turn up out of the canyon. Since the plane was able to fly sideways without losing altitude, depending on its current orientation, pulling up out of the canyon required the exact same maneuver as pulling right or left around a turn. This meant that it never learned to differentiate between the two scenarios and therefore learned to turn into any open space available. To combat this, we tried two things. First, we added a roof to our canyon, effectively making it a cave. This worked, allowing the plane to fly reasonably well through the environment, making multiple turns before eventually crashing. The plane would have trouble doing two turns in opposite directions in quick succession but otherwise would not often
crash into the canyon walls. However, this wasn’t exactly the problem that we wanted to demonstrate and flying through a cave was not determined to be a particularly realistic scenario for an airplane. Instead we wanted to show a scenario where the plane flew autonomously through a canyon without flying above the canyon due to some threat in the sky above. To simulate this, we generated a fleet of simple enemy planes that would fly back and forth over the canyon in straight lines from randomly generated positions and orientations. This created a virtual roof to our canyon as a visual object that our neural network could learn to avoid, which can be seen in Figure 4-6. While somewhat effective, this was not as successful at keeping the plane from flying out of the canyon as the roof was. The plane would simply fly up out of the canyon as soon as there were no planes directly above that section of the canyon. A visualization of the activation function returned by the convolutional layers of our network for both of these scenarios can be seen in Figure 4-7. Regions that are highlighted in blue represent what that portion of our neural network had determined to be important, which in this case is open space that the plane should fly towards.
Both of these results, the inability to fully train our simple model with the expert pilot flight and the inability to train either model to stay within the bounds of the canyon without the presence a solid physical object above the canyon, pointed in the direction of our next planned machine learning technique, reinforcement learning. Not only would this technique allow us to get a significantly larger range of aircraft state scenarios due to the random control actions of reinforcement learning, but we could also impose direct penalties for undesirable behaviors, such as flying too high.
4.3.2
Reinforcement Learning
Moving on from imitation learning to reinforcement learning we had intended on using the previously learned imitation based neural network models to bootstrap the reinforcement learning. This would be particularly helpful since the aircraft can fly in many different ways and giving the reinforcement learning model a baseline idea of what normal flight should look like could be especially useful. However, we
Figure 4-7: CNN activations for the cave scenario (left) and the enemy planes scenario. The network is very effectively able to find the spaces that have the longest range of open space. This works well in the cave but although the adversary planes are detected, the model is still interested in the open space between them.
were unable to effectively do this since the ResNet50 model that we had used as our image processor for the simple imitation learning scenario ended up being too big to use with our reinforcement learning framework and our simple model from before had not produced many reasonable results with imitation learning. Therefore, we ended up training our reinforcement learning models from scratch, which worked out decently since straight and level flight for our aircraft required no control inputs.
Initially we placed the aircraft in the standard random canyon format that we used for training and allowed the neural network to learn all of the controls for the aircraft, which consisted of throttle, roll, and pitch control. Every time step that the plane completed without crashing or flying out of the canyon was given a reward. Once the plane crashed, the episode was ended, and then another training episode began. After training the network multiple times we were not getting particularly good results. The convolutional layers of our simple model were performing much better, accurately detecting important features in the canyon environment necessary for performing turns, but the controller half of the network was not coming up with suitable combinations of pitch and roll maneuvers to safely avoid the walls. We
determined that the complex maneuver of turning sideways and pulling back to get around each turn was a little too complicated to have the model learn from scratch, so we decided to simplify the environment and criteria for success in an attempt to slowly build up to this result.
The first thing we tried to simplify the problem was to straighten the canyon. We wanted to ensure that the plane was able to fly straight without any issues before building up to more complicated maneuvers. The neural network simple model was able to handle this without much issues and flew through the straight canyon indef-initely without crashing. It did however develop some interesting behavior. Since the canyon was taller than it was wide, the autonomous system learned that it was safer to fly sideways rather than in normal upright flight. This was likely because the plane had the most control over direction changes by pitching up or down. By turning sideways, the plane now had much more fidelity for moving left and right in the canyon, which was the more important axis to be able to adjust due to the narrow width of the canyon. While interesting, this behavior was not particularly concerning as the main goal was to have the plane fly safely through the canyon in spite of the slightly unusual dynamics that existed. An image of the canyon layout for this scenario and the plane flying through it is shown in Figure 4-8.
To slowly iterate from this positive result, we gradually added small turns that the model would have to deal with. We kept a straight canyon, but this time, started the aircraft at a random orientation. We made sure to bound these random starting orientations to make sure that the model wouldn’t have to deal with any sharp turns at the outset. This way, the model would have to learn how to deal with slight turns to avoid walls and then continue flying straight as it had learned before. The results for this part of the experiment were mixed. From most starting points, the plane was able to recover and start flying straight again, albeit still sideways. However, it usually didn’t align itself perfectly and eventually it would start drifting towards the top or bottom of the canyon. Once it was too close to one of those areas, the network wasn’t able to learn how to properly re-adjust its roll angle in order to pitch away from the top or bottom and usually ended up crashing.
Figure 4-8: Our plane flying sideways in the straight canyon. The orange above represents a no-fly zone.
As a next, potentially easier, way to try to gradually teach the network how to turn, we developed a new canyon model. With this model, the walls were farther apart and smoother, and the turns were not as sharp. Unfortunately, the results were more of the same; the model was able to pitch to avoid walls that were above or below the plane relative to its orientation, but it was unable to adjust the aircraft’s orientation once nearing an obstacle to allow for this evasive pitch maneuver to be used in all situations.
Finally, we decided to remove the coupling between pitch and roll that was required to make turns, which seemed to be the issue that was preventing the neural network model from learning how to effectively navigate in the canyon. To do this, we removed pitch and roll control completely from the model and replaced those with pure yaw control of the aircraft. That way, when the aircraft approached a turn, all it would have to do was yaw left or right to get around the corner. This ultimately became the simplification that allowed our model to perform quite well. We trained our model on our original canyon setup to start with, and quickly noticed positive results. Not only was the plane able to fly indefinitely without crashing in the exact same canyon that it was trained in, but it was also able to fly completely without crashing in most of the other canyon configurations that we put it in, despite it never having seen those sequences of turns before.
To continue to test the capabilities and limitations of this trained model, we continued to add more changes to the environment that the model had been trained on to see how it would respond. First, we added a pseudo-realistic wind term that resulted in arbitrary velocity changes. Any time the plane had a component of its forward motion face along a certain axis, it would either speed up or slow down proportional to the projection of its forward motion onto that axis. This resulted in the plane’s speed varying from its minimum speed of 75 units per second to its maximum speed of 225 units per second. Despite being trained entirely at a speed of 150 units per second, this model was able to handle these speed changes without any issues. Similar to before, for almost all of the random terrains that we had the plane fly in with this pseudo-wind, it was able to fly indefinitely without crashing.
The next change that we added was unexpected static obstacles. These plane-width walls appeared at random, directly in front of the direction the plane was flying. They were placed far enough away so that the plane would have a few image frames to respond to the new situation, but no farther away than three plane lengths. An image sequence of the aircraft avoiding random obstacles that had just appeared is shown in Figure 4-9. The model that was just trained to fly in a uniform canyon with consistent turns was able to navigate this new environment very well. Occasionally it did not react quickly enough and would crash into these random obstacles, but for the most part, it was able to avoid all of them.
Another change that we tested this flying configuration on was our alternate canyon environment setup. Since this canyon was generated in a completely dif-ferent way, its features were relatively difdif-ferent from the canyon that our model was trained on. Flying in this canyon would prove difficult if our model had only learned the features specific to our main canyon setup. Instead, our model proved that it had learned higher level features of what defined turns and open spaces in the canyons and was able to fly without fault in these randomly generated canyons as well. Since we were able to change the width of these canyons, we also tried to see how narrow we could make the canyon and still have the plane fly without crashing. Although the model had more trouble the thinner the canyon got, it was still able to fly quite well in a canyon that was only three times as wide as the aircraft itself, a scenario where even our human pilot was unable to complete more than a turn or two without crashing. These canyon variations can be seen in Figure 4-10.
4.3.3
Results Summary
This sections lists a concise summary of all meaningful techniques that extensive tests were performed on and their results. They are listed in order of simplicity of test environment, with imitation learning test listed before reinforcement learning tests. All tests were cut off after 5000 iterations and assumed to fly indefinitely after that point. 10 flights were recorded for each experiment with many more being flown while developing the various experiments.
Figure 4-9: An image sequence of our aircraft avoiding two consecutive random ob-stacles as they appear.
Figure 4-10: Flying through challenge environments. Note that although the canyon is a similar color as before, the model is operating using only depth map sensors and the shape of the canyons are very different than before.
Experiment 1
1. Environment: Standard canyon environment. Roof added.
2. Training Platform: Imitation Learning. Simple model.
3. Objective: Fly through the cave-like environment without crashing.
4. Performance: Average flight runs for 630 iterations.
Experiment 2
1. Environment: Standard canyon environment. Adversaries flying overhead.
2. Training Platform: Imitation Learning. Simple model.
3. Objective: Fly through the canyon without crashing. Don’t fly above the canyon.
4. Performance: Average flight runs for 215 iterations.
Experiment 3
2. Training Platform: Imitation Learning. ResNet50 model.
3. Objective: Fly through the canyon without crashing. Don’t fly above the canyon.
4. Performance: Average flight runs for 270 iterations.
Experiment 4
1. Environment: Standard canyon environment. Restricted to only straight pas-sageways. Full controller.
2. Training Platform: Reinforcement Learning.
3. Objective: Fly through the straight canyon without crashing.
4. Performance: Average flight runs for 5000 iterations.
Experiment 5
1. Environment: Standard canyon environment. Restricted to only straight pas-sageways. Random initial orientation bounded between -10 to 10 degrees of angle deviation. Full controller.
2. Training Platform: Reinforcement Learning.
3. Objective: Fly through the straight canyon without crashing after adjusting to initial orientation.
4. Performance: Approximately 50% of flights fly for 5000 iterations. The rest crash almost immediately.
Experiment 6
1. Environment: Standard canyon environment. Full turns. Yaw only controller.
3. Objective: Demonstrate ability to fly through an unseen canyon configuration with arbitrary turns using only yaw to control turns.
4. Performance: Average flight flies for 5000 iterations.
Experiment 7
1. Environment: Alternate wide canyon environment. Full turns. Yaw only con-troller.
2. Training Platform: Reinforcement Learning.
3. Objective: Demonstrate ability to fly through completely new canyon structures with arbitrary turns using only yaw to control turns.
4. Performance: Average flight flies for 5000 iterations.
Experiment 8
1. Environment: Alternate narrow canyon environment. Full turns. Yaw only controller.
2. Training Platform: Reinforcement Learning.
3. Objective: Demonstrate ability to fly through completely new canyon structures with arbitrary turns and narrow passageways using only yaw to control turns. 4. Performance: Average flight flies for 584 iterations.
Experiment 9
1. Environment: Standard canyon environment. Full turns. Wind added. Yaw only controller.
2. Training Platform: Reinforcement Learning.
3. Objective: Demonstrate ability to handle velocity changes and still avoid walls. 4. Performance: Average flight flies for 5000 iterations.
Experiment 10
1. Environment: Standard canyon environment. Full turns. Random obstacles added with a 1 in 250 chance every timestep. Yaw only controller.
2. Training Platform: Reinforcement Learning.
3. Objective: Demonstrate ability to avoid unexpected obstacles.
4. Performance: Average flight flies for 3623 iterations.
Experiment 11
1. Environment: Standard canyon environment. Full turns. Random obstacles added with a 1 in 50 chance every timestep. Yaw only controller.
2. Training Platform: Reinforcement Learning.
3. Objective: Demonstrate ability to avoid unexpected obstacles that occur at a high frequency.
4. Performance: Average flight flies for 650 iterations.
Experiment 12
1. Environment: Standard canyon environment. Full turns. Full controller.
2. Training Platform: Reinforcement Learning.
3. Objective: Demonstrate ability to fly through an unseen canyon configuration with arbitrary turns.
4. Performance: Unsuccessful. Planes do not demonstrate reasonable learned be-havior.
Figure 4-11: Flight times. Note that testing runs were cut off after 5000 iterations, so both the reinforcement learning setup in the simple environment and with added wind flew indefinitely. The two obstacles flights were run with varying frequency of obstacle appearance with obstacles having either a 1 in 50 or a 1 in 250 chance of appearing every frame.
4.3.4
Comparison of models
As evident from the previous few sections, the success of our models was varied. A vi-sual representation of how long the plane flew in the various environments with which it was presented as well as the various models and methods that were used to train those planes is shown in Figure 4-11. Overall, the best results were achieved from the reinforcement learning trained simple model that only had yaw control. This model was able to fly entirely without crashing both in new environments and in situations where wind was added. Even when random obstacles were introduced, this trained model was able to fly for a long amount of time before crashing. Following that, the simple model trained in a cave using imitation learning was the next most capable model, scenario pair. Although this model didn’t fly indefinitely as the yaw controlled reinforcement learning model did, it did demonstrate more complex maneuvers that combined both roll and pitch to turn corners. Finally, comparing the models that flew in the environment with no roof but instead with adversary aircraft overhead, the ResNet50 version of our model flew slightly longer than our simple model, but neither flew nearly as long as the other situations.
For reference, the simple imitation learning model flying in the cave scenario tended to complete on average three turns in its canyon environment before crashing.
Chapter 5
Conclusions
In this thesis, we set out to lay down the groundwork for creating a parallel autonomy system for fixed-wing aircraft. Over the course of this research, we were able to de-velop a simulator for fixed-wing flight with modular environments and external effects. We then developed models for training neural network models to fly these fixed-wing aircraft. Using both imitation learning and reinforcement learning techniques we were able to achieve various levels of success ranging from the plane crashing into canyon walls immediately to being able to fly indefinitely around a random looped track. Our results can be extended to broader scenarios in the future, and can slowly start to be integrated with human control to achieve the goal of parallel autonomy.
5.1
Future Work
One of the major issues that can still be worked on with this particular part of the project is improving the neural network’s ability to handle more complex maneuvers. While being able to handle unexpected environment changes on the fly is a great starting point, only controlling a plane using yaw control is not a very realistic or useful way to fly around a canyon. Ideally, in the future, this autonomous system should be able to learn how to fully control roll, pitch, and yaw in a similar matter as a real human pilot would.
situations with dynamic obstacles or even multi-agent situations. For example, an interesting question that has yet to be answered is if two aircraft both running the same model can fly in the same environment at the same time without crashing into each other or the walls.
On top of being able to handle more complex dynamics within the canyon envi-ronment, it is important to be able to start developing this system for flight in other scenarios outside of this particular canyon scenario that we came up with. Situations like the unknown upside-down flying described in the introduction, aerial refueling, formation flying, and even evasive maneuvers during dogfights are all possible cir-cumstances where assistance from an autonomous agent could be quite useful. In the aerial refueling and formation flying cases, this becomes a multi agent collaborative problem, and in the evasive maneuvers case, the autonomous system has to learn how operate with adversary agents with unknown behaviors.
Slightly tangential to the pushes to get this autonomous system to fly in our simulated environment would be trying to get a real system with one of these models flying in a real-life canyon or hallway. If some of the models that are described here are transferable to real flight, that would constitute a major success. This direction of the research still has some work before it is ready to go, but it is currently being developed.
Perhaps most importantly, these autonomous flight agents that are being devel-oped need to be integrated with human control. As this is the final goal of the project, it is an important aspect that will need to be addressed in the near future.
5.2
Lessons Learned
Over the course of this project, a few major lessons were learned. First of all, progress, especially when dealing with machine learning projects, usually isn’t linear. Dur-ing this project, the first major result that was achieved was flyDur-ing the aircraft au-tonomously for a few turns in the cave environment using imitation learning. This result was achieved in December. It took about four months of experimenting and
trying idea after idea to finally get another comparable or better result, which was the yaw turn controlled reinforcement learning trained model.
The success of the yaw turn controller taught another lesson, namely that starting with something simpler usually results in more success. From there the complexity can be increased, but until the simplest iteration of a project is working, it is unlikely that more complicated experiments will pan out. We learned this the hard way by trying out complex scenarios over and over again until finally trying to simplify things to get a decent result.
Potentially the most significant lesson learned from this research is that more scenarios, more training techniques, more testing and more training all need to be utilized to continue to achieve better results. As is often the case with machine learning, it is hard to predict what changes will result in better results and knowing when the trained model is good enough or as good as it can get is very difficult.
5.3
Conclusion
This project is far from over and while it is not nearly reliable enough yet to be useful for pilots flying in high stress environments, it is trending in the right direction. In some scenarios, this system was able to fly decently well in situations where our human pilot had trouble doing so, which is exactly the intention of this system. If we are someday able to get this system running reliably on a wide range of scenarios, it has the potential to allow pilots to put more focus into their missions as they would have less mundane plane control needs to address. In some scenarios, it may even be able to help save lives.