Towards a Generic API for Data Load Balancing in Structured P2P Systems
Texte intégral
Figure
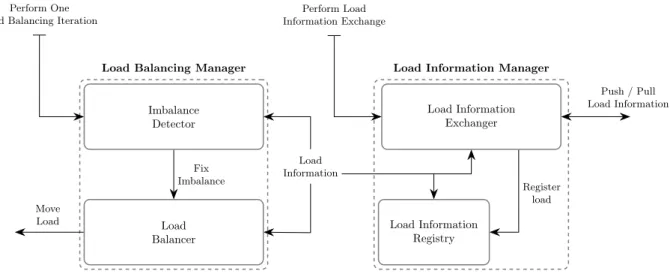
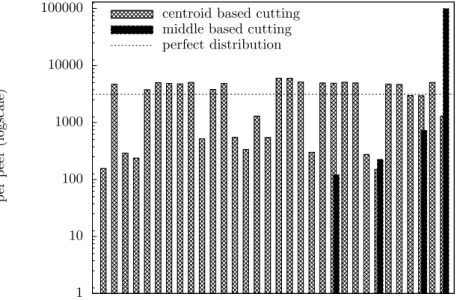
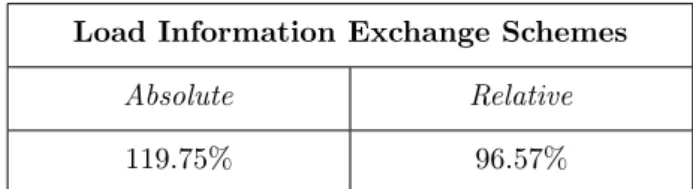
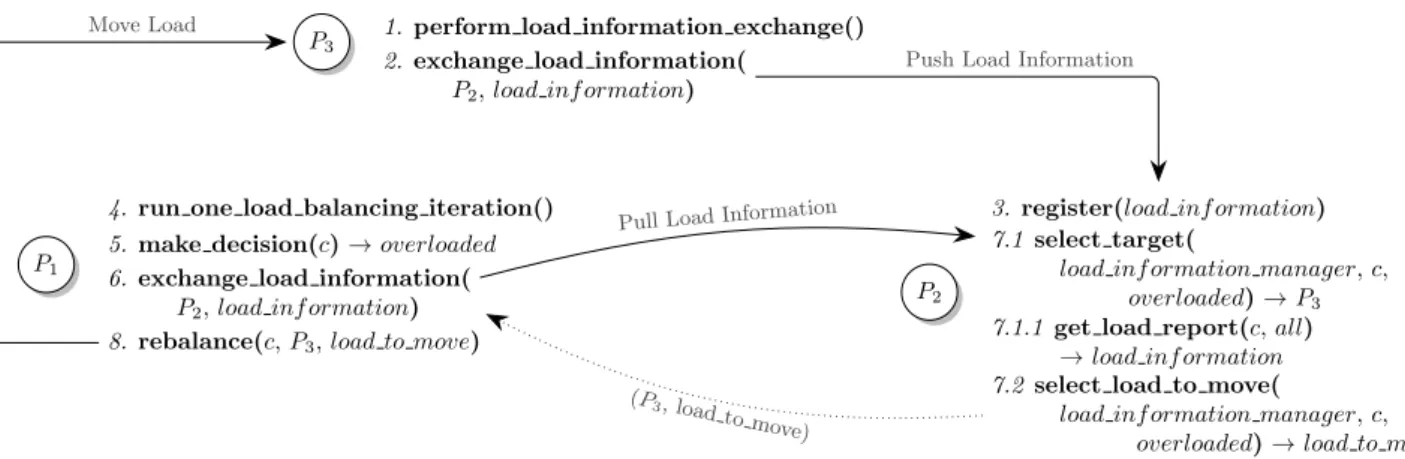
Documents relatifs
As in the case of a single class, we deduce from Theorem 2 that there exists an optimal admissible load balancing which is simple, for both the overall blocking probability and
As limit points of a dynamic correspond to stationary points, from this theorem, we can conclude that the dynamics (9), and hence the learning algorithm when b goes to 0, will
This paper presents SHELL, a stateless application-aware load-balancer combining (i) a power-of-choices scheme using IPv6 Segment Routing to dispatch new flows to a suitable
In clusters based event-driven model, a newly submitted trigger is assigned to the node where the relevant datasets set.. However triggers are not instantly executed after
At such a scale, these storage systems face two key challenges: (a) hot-spots due to the dynamic popularity of stored objects and (b) high reconfiguration costs of data migration due
When the agent considers tasks which have the same local availability ratio, it always browses them in the same order: from the costliest to the less costly task (cf. Thus, when
The centralized part supports evaluation of the peer degree, routing cost, arrival cost, departure cost, index management load balancing, and storage load balancing.. To ensure
We observed the performance of the storage load balancing method subject to three fac- tors : the storage utilization ratio, the peer dynamicity, and the storage load transfer
