A combined fast/cycle accurate simulation tool for reconfigurable accelerator evaluation: application to distributed data management
Texte intégral
Figure

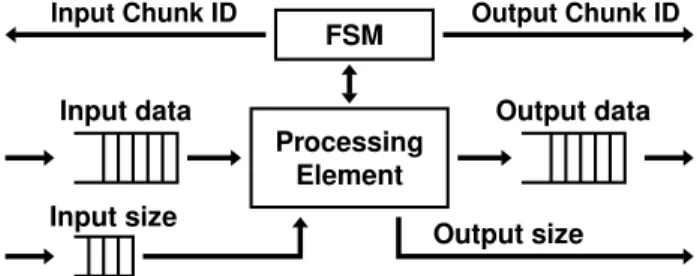

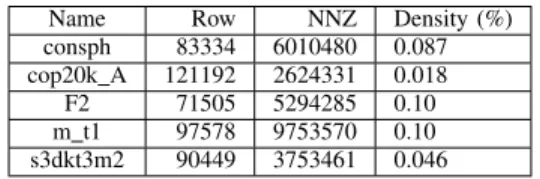
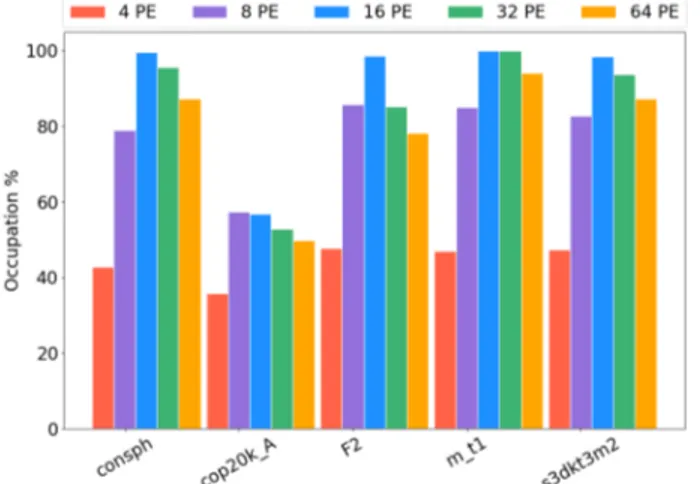
Documents relatifs
In this paper, we have presented different ways to model this NoC using the network calculus framework: the explicit linear model, that has been developed to both compute the routing
Apart from discrete groups and duals of compact groups, the first test examples for a quantum Property RD should be the free quantum groups introduced by Wang [6], which are
ﺰﻴﻛﱰﻟا ﻊﻣ ﺔﻴﺴﻓﺎﻨﺗ ةﺰﻴﻣ ﻖﻴﻘﺤﺘﻟ نﻮﺑﺰﻟا ﻊﻣ ﺔﻗﻼﻌﻟا ﺔﻴﺠﻴﺗاﱰﺳا دﺎﻤﺘﻋﺎﺑ ﺔﻴﻘﻳﻮﺴﺘﻟا ﺔﻓﺮﻌﳌا ةرادا رود ﺔﻓﺮﻌﻣ ﱃا ﺔﺳارﺪﻟا ﻩﺬﻫ ﺖﻓﺪﻫ ﻖﻠﻌﺘﳌا ﺎﻬﺒﻧﺎﺟ ﰲ ﺔﻴﻘﻳﻮﺴﺘﻟا ﺔﻓﺮﻌﳌا ةرادا
The approaches suggested in the article allow us to use the minimum number of pre-installed components for the purpose of deploying and managing an array of physical and
In our implementation we offer these Mementos (i.e., prior ver- sions) with explicit URIs in different ways: (i) we provide access to the original dataset descriptions retrieved
Heatmaps of (guess vs. slip) LL of 4 sample real GLOP datasets and the corresponding two simulated datasets that were generated with the best fitting
Assuming that a representative catalog of historical state trajectories is available, the key idea is to use the analog method to propose forecasts with no online evaluation of
Management of multi-modal data using the Fuzzy Hough Transform: Application to archaeological simulation.. First IEEE International Conference on Research Challenges in
