Analyse OLAP d'un entrepôt de documents XML
Texte intégral
Figure
Documents relatifs
1 -a – Compléter le schéma suivant avec les noms des changements d’état physique convenable ( fusion – vaporisation – solidification – liquéfaction ). 1 –b- donner le
Une version XML est le document de D qui correspond à un ensemble d’événe- ments de contrôle de versions, l’ensemble des événements qui a donné lieu à cette version. Dans
Donner la mesure de l’angle marqué en justifiant
En comparaison avec le lancer de marteau, quel type d’action doit exercer le Soleil sur une planète pour l’empêcher de s’échapper dans l’espace?. (figures 1 et
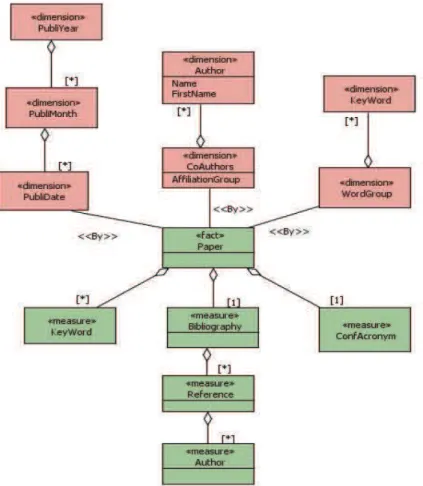
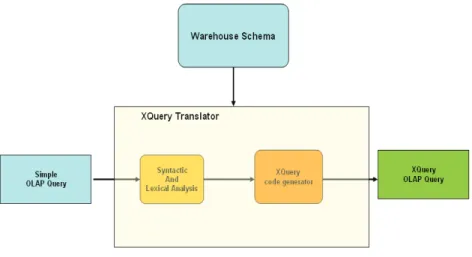
Dans cet article nous présentons un nouveau langage d’analyse OLAP destiné aux décideurs ; il permet d’exprimer des requêtes complexes sur un entrepôt de documents XML
En allant au-delà des propos de (Fankhauser et al., 2003), nous pensons que la techno- logie XML permet d’envisager l’intégration de documents dans un environnement OLAP. Ainsi,
Ce sont des supports de cours mis à votre disposition pour vos études sous la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes
We are developing an approach to computational prag- matics that combines the insights for argumentation that rhetorical figures provide, together with argument mining,
