HAL Id: tel-01335745
https://pastel.archives-ouvertes.fr/tel-01335745
Submitted on 22 Jun 2016HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Data management in social networks
Silviu Maniu
To cite this version:
Silviu Maniu. Data management in social networks. Social and Information Networks [cs.SI]. Télécom ParisTech, 2012. English. �NNT : 2012ENST0053�. �tel-01335745�
2012-ENST-053
EDITE - ED 130
Doctorat ParisTech
T H È S E
pour obtenir le grade de docteur délivré par
TELECOM ParisTech
Spécialité « Informatique »
présentée et soutenue publiquement par
Silviu MANIU
le 28 Septembre 2012
Gestion des données
dans les reseaux sociaux
Directeur de thèse :Bogdan CAUTIS
Co-encadrement de la thèse :Talel ABDESSALEM
Jury
Mme Anne DOUCET,Professeur, LIP6, Université Paris 6 Examinateur
Mme Ioana MANOLESCU,Directeur de Recherche DR2, INRIA Examinateur
M. David GROSS-AMBLARD,Professeur, IRISA, Université Rennes 1 Examinateur
Mme Tova MILO,Professeur, Université de Tel Aviv Rapporteur
Abstract
We address in this thesis some of the issues raised by the emergence of social ap-plications on the Web, focusing on two important directions: efficient social search in online applications and the inference of signed social links from interactions between users in collaborative Web applications.
We start by considering social search in tagging (or bookmarking) applications. This problem requires a significant departure from existing, socially agnostic techniques. In a network-aware context, one can (and should) exploit the social links, which can indicate how users relate to the seeker and how much weight their tagging actions should have in the result build-up. We propose an algorithm that has the potential to scale to current applications, and validate it via extensive experiments.
As social search applications can be thought of as part of a wider class of context-aware applications, we consider context-context-aware query optimization based on views, focusing on two important sub-problems. First, handling the possible differences in context between the various views and an input query leads to view results having un-certain scores, i.e., score ranges valid for the new context. As a consequence, current top-k algorithms are no longer directly applicable and need to be adapted to han-dle such uncertainty in object scores. Second, adapted view selection techniques are needed, which can leverage both the descriptions of queries and statistics over their results.
Finally, we present an approach for inferring a signed network (a "web of trust") from user-generated content in Wikipedia. We investigate mechanisms by which rela-tionships between Wikipedia contributors - in the form of signed directed links - can be inferred based their interactions. Our study sheds light into principles underlying a signed network that is captured by social interaction. We investigate whether this network over Wikipedia contributors represents indeed a plausible configuration of link signs, by studying its global and local network properties, and at an application level, by assessing its impact in the classification of Wikipedia articles.
Keywords
Social applications, collaborative applications, social search, threshold algorithms, context-aware search, query processing, cached results, views, signed networks, Wiki-pedia, link inference/prediction, Web-scale algorithms.
Resumé
Nous abordons dans cette thèse quelques-unes des questions soulevées par l’éme-rgence d’applications sociales sur le Web, en se concentrant sur deux axes importants: l’efficacité de recherche sociale dans les applications Web et l’inférence de liens so-ciaux signés à partir des interactions entre les utilisateurs dans les applications Web collaboratives.
Nous commençons par examiner la recherche sociale dans les applications de “tag-ging”. Ce problème nécessite une adaptation importante des techniques existantes, qui n’utilisent pas des informations sociaux. Dans un contexte ou le réseau est im-portante, on peut (et on devrait) d’exploiter les liens sociaux, ce qui peut indiquer la façon dont les utilisateurs se rapportent au demandeur et combien de poids leurs actions de “tagging” devrait avoir dans le résultat. Nous proposons un algorithme qui a le potentiel d’évoluer avec la taille des applications actuelles, et on le valide par des expériences approfondies.
Comme les applications de recherche sociale peut être considérée comme faisant partie d’une catégorie plus large des applications sensibles au contexte, nous etudions le probleme de repondre au requetes a partir des vues, en se concentrant sur deux sous-problèmes importants. En premier, la manipulation des éventuelles différences de contexte entre les différents points de vue et une requête d’entrée conduit à des résultats avec des score incertains, valables pour le nouveau contexte. En conséquence, les algorithmes top-k actuels ne sont plus directement applicables et doivent être adap-tées aux telle incertitudes dans les scores des objets. Deuxièmement, les techniques adaptées de sélection de vue sont nécessaires, qui peuvent s’appuyer sur les descrip-tions des requêtes et des statistiques sur leurs résultats.
Enfin, nous présentons une approche pour déduire un réseau signé (un "réseau de confiance") à partir de contenu généré dans Wikipedia. Nous étudions les mécan-ismes pour deduire des relations entre les contributeurs Wikipédia - sous forme de liens dirigés signés - en fonction de leurs interactions. Notre étude met en lumière un réseau qui est capturée par l’interaction sociale. Nous examinons si ce réseau en-tre contributeurs Wikipedia représente en effet une configuration plausible des liens signes, par l’étude de ses propriétés globaux et locaux du reseau, et en évaluant son impact sur le classement des articles de Wikipedia.
Mots clés
Applications sociales, applications collaboratifs, receherche sociale, algorithmes de seuil, vues, reseaux signées, Wikipedia, algorithmes de grande echelle.
Resumé en Français
La possibilité d’interroger et d’analyser la quantité sans précédent de données présentes sur le World Wide Web, par des algorithmes rapides et efficaces, a largement contribué à la croissance rapide de l’Internet, ce qui en fait tout sim-plement irremplaçable dans notre vie quotidienne. Un développement récent sur le Web est représentée par le Web social, c’est à dire, les applications qui sont centrées autour des utilisateurs, leurs relations et leurs données.
En effet, les grandes communautés en ligne ou les utilisateurs contribuent et partagent leur contenu, font aujourd’hui une partie importante et très qualita-tive du Web. Elles peuvent être construites comme explicitement sociales (Face-book, Google+, Flickr ou Twitter), ou comme des applications dans lesquelles les communautés sociales représentent le “moteur” de la création de contenu (Wikipedia). Pour ces deux types d’applications Web, la présence des interac-tions entre utilisateurs est un élément crucial de leur succès. Pour ne citer que deux chiffres éloquents, dans les 3 dernières années, le nombre total des utilisa-teurs sur Facebook est passé d’environ 400 millions à près d’un milliard, tandis que le nombre de tweets par jour sur Twitter a augmenté de 40 millions à 340 millions. Avec des bases d’utilisateurs plus larges, plus de participation et de plus grands volumes de données vient la nécessité de garanties fraÃ˝ocheur et la pertinence des données, la nécessité de conduire pour une récupération rapide et une analyse efficace. En effet, les techniques de recherche et de la croissance du Web sont clairement inter-dépendants.
Malgré leur promesse, le potentiel des outils fournis par le Web social d’au-jourd’hui n’est pas encore pleinement réalisé. Systèmes de recherche dans lequel les relations entre les utilisateurs d’un site Web sont pris en compte sont encore relativement rares, et ils utilisent principalement des simples approches de filtrage afin de servir le contenu. La recherche sur les mesures de réputation dans les applications sociales qui permettent des sémantiques entre liens qui sont plus riches, au-delà de modeles liaison / non-liaison, comme la similitude et antagonisme dans les réseaux signés, est encore dans une phase très embry-onnaire. En outre, le manque d’outils contributeurs, tels que les classificateurs capables de différencier les contributeurs valables de ceux sans valeur (par ex-emple, les vandales) est l’une des raisons possibles derrière le déclin lent de
l’activité contributeur sur la Wikipédia.
Cela indique que, pour réaliser le potentiel du Web social et collaboratif, il ya un réel besoin de systèmes de gestion des données sociales, et en particulier pour des techniques capables de: (i) déduire des liens utilisateur, éventuelle-ment avec des semantiques plus riches, même dans des applications où ces liens n’existent pas, (ii) classifier les utilisateurs ou les collaborateurs du réseau social, pour une utilisation dans les systèmes de recommandation, dans des meilleurs modèles de classement de contenu, et (iii) classer et servir efficace-ment le contenu, en tenant en compte le fait que le classeefficace-ment des contenus ne dépend pas seulement des proprietes des données – comme c’est le cas dans les systemes IR – mais aussi sur la relation entre l’utilisateur demandant des données et les propriétaires ou producteurs de contenu pertinent.
Dans cette thèse, nous nous concentrons principalement sur deux des trois aspects mentionnés ci-dessus: la déduction des liens sociaux implicits et le problème de la recherche efficace dans les applications sociales, avec des tech-niques qui représentent aussi les premiers pas vers le classement pertinent des donnees, ou vers des systemes de recommandation precises.
Donc, nous abordons trois problèmes importants dans le domaine de la ges-tion des données sociales:
1. Nous étudions le problème de la recherche sociale, dans son interpréta-tion centre reseau. Les scénarios de recherche dans lequel le réseau est une partie intégrante du modèle de classement contenu exigent des algo-rithmes qui vont au-delà de simples adaptations des algoalgo-rithmes top-k courants. La sémantique des requêtes change de maniere fondamentale: le modèle de notation doit prendre en compte non seulement les mots clés de la requête, mais aussi l’identite de l’utilisateur qui a initie la requête. Ce fait nécessité d’algorithmes adaptés, capables de calculer efficacement des réponses à ces requêtes. Plus important encore, ils doivent être ro-bustes en présence des mises à jour dans le réseau d’utilisateurs et de leurs données.
2. Deuxièmement, comme une extension naturelle du problème ci-dessus, nous étudions le scénario où les résultats des recherches peuvent être mis en cache, une fonctionnalité importante pour tous les types d’applications de recherche. Nous étudions les requetes top-k en présence de résultats requête précalculées (que nous appelons vues), dans le cadre plus vaste des systemes sensibles au contexte, couvrant non seulement la recherche sociale, mais aussi la recherche spatiale. Contrairement aux algorithmes top-k classiques qui utilisent les vues, dans notre contexte les données
dans les vues ne peuvent pas être utilisés tel que. Le contexte dans lequel les vues ont été calculées doitêtre transposé dans le contexte de la requête actuelle. Cela introduit une incertitude dans les scores des données dans les vues, et conduit a des nouveaux semantiques de requête et des algo-rithmes.
3. Troisièmement, nous étudions le problème de l’inférence des liens soci-aux a partir des interactions, en allant au-delà de prédiction lien simple. Nous étudions les reseaux signes dans lesquels les liens peuvent avoir non seulement une une interpretation positive de l’attitude inter-utilisateurs, mais aussi un cÃt’té négatif. Plus précisément, nous montrons qu’il ex-iste un reseau signe implicite des contributeurs de Wikipedia, et nous decrivons une approche de la déduire. La sémantique plus riche des liens dans ce réseau signé, que nous appelons WikiSigned, peut aider à des tôcches comme la classification des contributeurs, des pages ou meme du contenu. Comme une preuve de concept, nous montrons que le classe-ment des articles de Wikipedia peut être considérableclasse-ment améliorée par la prise en compte du réseau signé des contributeurs.
Recherche sociale
Une classe importante d’applications sociales sont les applications de mar-quage collaboratif, aussi connus comme des applications de bookmarking,avec des exemples populaires, y compris Delicious, StumbleUpon ou Flickr. Leur fonctionnement général est le suivant:
• former les utilisateurs dans un réseau social, ce qui reflète peut-être la proximité, similitude, l’amitié, la proximité, etc,
• des éléments d’une archive publique d’articles (par exemple: un docu-ment, des URL, des photos, etc) sont marqués par les utilisateurs avec des mots clés, à des fins telles que la description et la classification, ou pour faciliter la récupération ultérieure,
• des utilisateurs recherchent des articles ayant certains mots clés (tags) ou qu’ils sont des recommandations, basées sur la proximité dans le reseau. Les applications de marquage collaboratif et les applications sociales en général - peuvent offrir une perspective entièrement nouvelle à la façon dont on recherche
et retrouvent les informations. La raison principale de ceci est que les utilisa-teurs peuvent (et le font souvent) jouer un rÃt’le aux deux extrémités de la
circulation de l’information, en tant que producteurs et aussi en tant que de-mandeurs d’information. Par conséquent, trouver le articles les plus pertinents qui sont marqués avec quelques mots clés doit être fait d’une sensible au re-seau. En particulier, les éléments qui sont marqués par les utilisateurs qui sont “plus proches” de l’origine devraient avoir plus de poids que les articles qui
sont marqués par plusieurs utilisateurs distants.
Dans ce travail, nous etudions le problème de la récupération top-k dans les systèmes de marquage collaboratif. Bien que l’accent sur les applications de bookmarking peut paraÃ˝otre restrictif, ceux-ci représentent une bonne ab-straction pour d’autres types d’applications sociales, à laquelle nos techniques peuvent etre appliques directement.
Nous étudions ce problème en mettant l’accent sur l’efficacité, les techniques de ciblage qui ont le potentiel de passage a l’échelle pour les applications actuels sur le Web, dans un contexte, les données de marquage et même les préférences de recherche des demandeurs peuvent changer à tout moment. Dans ce contexte, un des principaux sous-problème pour requetes top-k que nous devons considerer est le calcul de scores candidats pour le top-k par con-siderer non seulement les éléments les plus pertinents à l’égard de la requête, mais aussi (ou surtout) en consultant les utilisateurs les plus proches et de leurs articles marquees.
Nous associer à la notion de réseau social une interprétation assez générale, sous forme de utilisateurs dont les liens sont marqués par des scores soci-aux,qui donnent une mesure de la proximité ou de la similitude entre deux utilisateurs. Ceux-ci sont ensuite exploitables dans les recherches, car ils disent à quel point les actions marquage doivent etres relevants. Par exemple, même pour les applications de marquage où si un réseau social explicite n’existe pas ou n’est pas exploitable, on peut utiliser l’histoire de marquage pour construire un réseau de similarité.
Example 1. Dans la reuseau de la figure, les utilisateurs ont associées des documents
et ils sont reliés entre eux par des liens sociaux. Chaque lien est marquée par son score social,dans l’intervalle
[
0, 1]
. Prenons l’utilisateur Alice dans le rÃt’le du chercheur. Le graphe n’est pas complète, comme le montre la figure, et seuls deux utilisateurs ont un score sociale explicite en ce qui concerne Alice. Pour ceux qui restent : Danny, . . . , Jim, seulement un score social implicite pourrait être calculée à partir des liens existants si une mesure précise de leur pertinence par rapport a la requete d’Alice est donnee.Supposons qu’Alice cherche les deux premiers documents qui sont marqués avec ”news“ et ”site“. En regardant les voisins immédiats d’Alice et de leurs documents
!"#$!"#$ !%#$%$&! !&#$%$&!'(!"#$ !&#$%$&! !'#$%$&!'(!"#$ !(#$%$&! !%#$!"#$ !&#$%$&! !(#$!"#$ !)#$%$&!'(!"#$ !(#$%$&! !%#$!"#$ !&#$%$&!'(!"#$ !%#$%$&!'(!"#$ !&#$%$&! !%#$!"#$ !&#$%$&!'(!"#$ !%#$!"#$ !"#$%$&! !&#(%$&! !"#$% &'( )*+,"#% -+../ 01% 2,+.3 4%',5% 6'""/ 78+ 9#: )*+ )*, )*-)*, )*+ )*-)*. )*.-)*/
respectifs, intuitivement, D3 doit avoir un score plus élevé que D4,puisque le premier est marqué par une utilisateur plus pertinent (Bob, ayant le score maximal sociale par rapport à Alice). Si nous étendrons la recherche à l’ensemble du graphe, le score de D4 peuvent toutefois bénéficier du fait que les autres, comme Holly, ont également marqué des documents avec ”news“ ou ”site“. En outre, des documents tels que D2 et D1 peut également être pertinent pour le meilleur résultat top-2, même si elles ont été marqués uniquement par les utilisateurs qui sont indirectement liés à Alice.
Sous certaines hypothèses a être clarifiés prochainement, le top-2 pour la requête d’Alice sera D4 et D2. Nous allons détailler le modèle sous-jacent et les algorithmes qui nous permettent de construire cette réponse dans ce qui suit.
L’algorithme NRA de Fagin s’appuye sur des listes inversees précalculées avec des scores exacts de chaque terme de la requête (dans notre contexte, un terme est une étiquette). Fans la Figure 1.1, nous avons deux listes inversés
IL
(
news) = {
D4 : 7, D2 : 2, D1 : 2, D3 : 1, D6 : 1, D5 : 1}
et IL(
site) = {
D2 :5, D4 : 2, D3 : 1, D6 : 1, D1 : 1, D5 : 1
}
, qui donne le nombre de fois qu’un document a été marque.Lorsque la proximité utilisateur est un élément supplémentaire dans le top-k, un adaptation de l’algorithme de seuil et ses variantes auraient besoin de listes inverses précalculées pour chaque paire (utilisateur, mot-clé). Par exemple, si nous interprétons les liens explicites dans le graphe comme l’amitié, ignorant les scores lien et consideront le marquage uniquement par des amis directs les
listes sont ILAlice
(
news) = {
D4 : 1, D6 : 1}
et ILAlice(
site) = {
D3 : 1, D6 : 1}
. 18 autres listes seraient exigees et, évidemment, cela aurait un espace prohibitif et des coûts d’execution trop grands dans un contexte reel. Amer-Yahia et al. est le premier à répondre à cette question mais dans un maniere simplifiée. Les auteurs considèrent une extension des algorithmes top-k classiques dans laquelle la proximite utilisateur est considérée comme une fonction binaire (0-1 proximité): seul un sous-ensemble des utilisateurs du réseau sont sélectionnés et peuvent influencer let top-k. Cela introduit deux fortes restrictions et sim-plifications: (i) seuls les documents etiquetes par les utilisateurs sélectionnés doivent être pertinents pour la recherche, et (ii) tous les utilisateurs ainsi sélec-tionnés sont egalement importants. La solution de base de est à conserver pour chaque paire de utilisateur-etiquette, au lieu des listes détaillées, seule-ment une valeur limite supérieure sur le nombre de tagueurs. Par exemple, la limite supérieure de (news, D4) serait de 2, puisque pour n’importe quel utilisateur il ya au plus deux voisins qui taggént D4 avec news. C’est ce qu’on appelle le algorithme GLOBAL-UPPERBOUND. Une version plus raffinée, qui echange l’espace pour l’efficacité, garde de la limite supérieure des valeurs au sein des communites d’utilisateurs, au lieu du réseau dans son ensemble.Seulement dans Schenkel et al., le problème de récupération sensible au réseau pour le marquage collaboratif est considérée selon une interprétation générale, celle que nous avons également adopte dans ce travail. Il estime que même les utilisateurs qui sont indirectement liés à l’origine peut être perti-nents pour le top-k Leur algorithme ContextMerge suit l’intuition que les util-isateurs les plus proches du demandeur ont plus d’influence dans le score d’un élément, et donc ils maximizent la chance que l’article restera dans le top-k fi-nal.Les auteurs décrivent une approche hybride dans laquelle, à chaque étape, l’algorithme choisit soit de consulter les documents marqués par le plus proche utilisateur ou sur les listes inversees pour chaque etiquette. Afin d’obtenir le prochain utilisateur l’algorithme précalcule à l’avance la valeur de proximité pour toutes les paires possibles d’internautes. Ces valeurs sont ensuite stock-ées dans des listes classstock-ées (une liste par l’utilisateur), et un incrément pointeur permet d’obtenir le prochain utilisateur concerné.
Example 2. Considérons le réseau de la figure. 1,1. En ce qui concerne le demandeur Alice, la liste des utilisateurs selon leur indice de proximité serait
{
Bob : 0, 9, Danny : 0, 81, Charlie : 0, 6, Frank : 0, 4, Eve : 0, 3, George : 0, 2, Holly : 0, 1, Ida : 0, 1, Jim : 0, 05}
,avec la proximité entre deux utilisateurs construits comme le produit maximal de liens sur un chemin entre eux (formalisée dans la section 2.2.1).Les principaux inconvénients de sont la scalabilite et l’applicabilité. De toute évidence, le précalcul d’une fermeture transitive pondérée sur l’ensemble du réseau a un coût élevé en termes d’espace et de calcul en même modérée de taille des réseaux sociaux. Plus important encore, le maintien de ces proximité listes à jour quand ils reflètent la similitude de marquage, serait tout simple-ment impossible dans le monde réel, très dynamique. (Nous revisitons ces considérations en section 2.6.)
Contributions Nous proposons un algorithme top-k dans le application
mar-quage collaboratif, qui a le potentiel de passer a l’échelle pour les applications actuelles et au-delà, dans un contexte où les changements du réseau et des actions marquage sont fréquents. Pour cet algorithme, nous avons aborde un aspect essentiel: l’accès efficace les utilisateurs les plus proches pour un chercheur donné. Nous décrivons comment cela peut être fait à la volée - (sans des calculs préalables) pour une grande famille de fonctions pour le calcul de proximité dans un réseau social, y compris les plus naturel. L’intérêt de le faire est triple:
• nous pouvons avoir une personnalisation complete de notation, où chaque utilisateur peut definir sa propre voie d’exécuter des requêtes, grôcce à des paramètres et des choix de fonctions de score,
• nous pouvons itérer sur les utilisateurs concernés de manière plus effi-cace, car un réseau typique peut facilement entrer dans la memoire princi-pale ce qui peut épargner les volumes de disque potentiellement énormes exigés par l’algorithmed (voir section 2.6), tout en ayant la potentiel de s’executer plus rapidement,
• les mises de liens social ne sont plus un problème, par exemple, si elle est fondée sur la similitude des actions de marquage.
Nos algorithmes sont correctes et complets. Nous montrons que, lorsque la recherche se fonde exclusivement sur le poids social de ces données, il est op-timale dâ ˘A ´Zinstance pour une grande classe des algorithmes. Des expériences approfondies sur des données réelles montrent que notre algorithme s’execute beaucoup mieux que les techniques existantes, avec jusqu’à 50% d’amélioration (voir section 2.7).
Pour plus d’efficacité encore, nous considérons alors des statistiques pour des résultats approximatifs. Nos approches présentent les avantages de la con-sommation de mémoire négligeable (ils s’appuient sur des statistiques concises
sur le réseau de l’utilisateur) et les frais généraux de calcul réduite. En plus, ces statistiques peuvent être tenus à jour avec un effort limité, même quand le réseau social est construit sur la base de l’histoire de marquage. Les ex-périences montrent que les techniques de recherche approximatives peuvent considérablement améliorer le temps de réponse, pour atteindre environ 25% du temps de fonctionnement de l’approche exacte, sans sacrifier la précision.
L’objectif principal de notre travail est sur les aspects sociaux de la recherche top-k dans les applications de marquage collaboratif et nos techniques sont conçus pour un meilleur reponse dans des scenarios où les actions marquage sont pour la plupart (sinon exclusivement) vue à travers le prisme de la perti-nence sociale.
Reseaux signées
Une tendance importante dans les plates-formes sociales vise à exploiter les re-lations d’utilisateurs déjà existants, les liens entre les utilisateurs (par exemple, les liens sociaux), afin d’améliorer les fonctionnalités de base du système. Ceci est particulièrement le cas lorsque les liens peuvent être considérés comme étant signé,indiquant une attitude positive ou négative; les significations pos-sibles des liens positifs pourrait être la confiance, l’amitié ou de la similitude, tandis que les liens négatifs pourraient representer la méfiance, de l’opposition ou d’antagonisme. Dans les situations où des relations explicites n’existent pas, sont rares ou sont des indicateurs inadéquats des attitudes envers les autres membres de la communauté, il devient donc important de découvrir connex-ions implicites, des liens positifs ou négatifs, a partir des activités d’utilisateurs concernés et de leurs interactions.
Contributions Ce travail représente une étude sur les modes d’interaction
en-tre les contributeurs de Wikipedia et des relations qui peuvent êen-tre déduites de leur activite.
Nous avons extrait le réseau signée par l’historique de révision totale de la Wikipédia en anglais, et nous présentons aussi une étude sur une plus pe-tite échelle - une collection de 563 articles du domaine politique. A partir de l’historique des révisions, nous étudions les mécanismes par lesquels les rela-tions entre les contributeurs - sous forme de liens dirigés signés - peuvent être déduites de leurs interactions. Nous prenons en compte les modifications plus souvent par des auteurs des articles, des activités telles que la voix pour les postes d’administrateur, la restauration d’un article à une version antérieure,
ou l’attribution d’un barnstar (un prix, tout en reconnaissant les contributions précieuses).
Vu que Wikipédia en anglais contient environ 5 million d’articles et plus de 260 millions de révisions, les algorithmes d’extraction décrits dans notre tra-vail doivent être adapté à un environnement distribué, comme le paradigme MapReduce et son implementation open-source, Hadoop . En outre, les primi-tives importantes telles que l’enumeration de triangles dans le graphe et algo-rithmes d’apprentissage machine ont besoin des algoalgo-rithmes adaptés.
Le réseau signé que nous construisons est basé sur un modèle local pour les relations utilisateur: une paire ordonnée entre des membres de la communauté en ligne - entre le générateur et le destinataire - assigne une valeur positive ou négative, quand cette valeur peut être déduite. Cela pourrait être interprété comme la confiance subjective / méfiance dans la capacité d’un editeur pour améliorer la Wikipedia, et nous appelons l’ensemble de ces valeurs dans le réseau le "web de confiance". En bref, notre approche vise à transformer les interactions en indicateurs d’affinité d’utilisateur ou de compatibilité: pour donner une breve intuition, la suppression de texte ou restauration des modifi-cations d’un autre editeur (retour en arrière dans le thread des versions) serait favorable à une relation négative, tandis que la modification du texte ou la restauration d’une version précédente conduit vers une expérience positive.
Example 3. Pour illustrer, prenons six editeurs des articles de Wikipedia, ayant inter-agi sur le texte de l’article de la manière indiquée dans le tableau 1.1. Nous détaillons dans la section 4.2 comment ces données agrégées interaction est construit en vecteurs d’interaction.
Generateur Destinataire Interactions inserées effacés remplancés
Dodo19 Loopy 10 247 0 10
Capt_Jim Zscout370 5 6 120 0
99.227.60.251 VolkovBot 1 0 1 0
En regardant la première paire de contributeurs
(
Dodo19, Loopy)
, on peut noter que, à travers 10 interactions, Dodo19 a ajouté 247 mots près du texte rédigé par Loopy, alors que seulement 10 mots on ete modifiees. Intuitivement, cela laisse entendre que Dodo19 considere le texte de Loopy comme relevant. Par conséquence, un lien dirige positif pourra être crée à de Dodo19 à Loopy.La deuxième paire de contributeurs,
(
Capt_Jim, Zscout370)
illustre la situation inverse. Dans 5 interactions, Capt_Jim a supprimé 120 mots de Zscout370’s alors quâ ˘A ´Zil a insere seulement 6 mots. Il peut être raisonnablement dit (voir la section 4.4 pour une évaluation empirique de cet argument) que le premier contributeur se méfieen général (ou n’aime pas) le texte de la deuxième contributeur. Dans ce cas, un lien dirige négatif pourrait être créé entre CaptJim et Zscout3709.
A cas où aucun lien ne peut être créé avec une bonne confiance est illustré par la troisième paire de contributeurs,
(
99.227.60.251, VolkovBot)
. Dans ce cas, comme une seule interaction composée d’un mot supprimé a eu lieu, il n’y a pas assez de preuves pour décider de l’existence et de la polarité d’un lien.Outre les interactions sur le texte Wikipedia, d’autres types d’interactions existent entre les contributeurs, par exemple, des votes ou des prix , et pour une interprétation positive ou négative, ils sont également pris en considération pour étayer ces liens signés.
Notre travail fournit des informations précieuses sur les principes qui sous-tendent signé un réseau qui est capturée par les interactions sociales. Nous ex-aminons si le réseau sur Wikipedia contributeurs, appelé ci-après WikiSigned, représente en effet une configuration plausible des signes des lien. Tout d’abord, nous évaluons les connexions aux théories sociales telles que l’équilibre struc-turel et de l’état, qui ont été testés dans les mêmes communautés en ligne . Deuxièmement, nous évaluons le WikiSigned la précision d’une méthode d’apprentissage pour la prédiction des liens signes. Cela revient à exploiter les liens existants - en particulier les triades lien - pour déduire de nouveaux liens et pourrait être considéré comme la propagation des relations signés. En utilisant des techniques d’apprentissage automatique qui ont été appliquées dans la littérature précédente , dans des reseaux signes explicites, comme:
• Slashdot, dans lequel les utilisateurs peuvent étiqueter les autres comme des amis ou des ennemis,
• Epinions, dans lequel les utilisateurs peuvent indiquer si la confiance ou la méfiance dans dâ ˘A ´Zautres utilisateurs,
• élection adminship Wikipedia, où les cotisants peuvent soutenir ou s’opposer à l’élection dâ ˘A ´Zun autre contributeur à des postes de responsabilité plus élevés dans Wikipedia,
on obtient une bonne précision sur le réseau WikiSigned (meilleur que celle obtenu avant dans une reseau election Wikipedia). Par cross-validations, nous obtenons des preuves solides que notre réseau révèle vraiment une configura-tion signe implicite et que ces réseaux ont des caractéristiques similaires au niveau local, même si WikiSigned est inférée à partir des interactions tandis que les autres réseaux sont explicitement déclarées.
Il existe de nombreuses possibilités qui présentent à nous pour exploiter un tel réseau au niveau de l’application, par exemple, dans les tôcches de gestion des contributeurs. Nous discutons une application qui sâ ˘A ´Zappuye également sur les lecteurs, specifiquement le classement des articles de Wikipedia par or-dre d’importance et de qualité. L’intuition est que ces caractéristiques dâ ˘A ´Zun article dépendra de la façon contributeurs se rapportent les uns aux autres.
La contribution de base de ce travail est une thèse: les interactions des util-isateurs des applications sociales en ligne peuvent fournir de bons indicateurs de relations implicites - dans un sens plus riche que des simples relations génériques - et devraient être exploitées comme telles.
Contents
1. Introduction 7
1.1. Social-Aware Search . . . 9
1.2. Context-Aware Query Processing Using Views . . . 13
1.3. Inferring Signed Social Networks . . . 18
2. Efficient Social-Aware Search 23 2.1. Related Work . . . 23
2.2. General Setting . . . 25
2.2.1. Computing Extended Proximities . . . 26
2.3. Top-k Algorithm for the Social Case . . . . 29
2.3.1. Instance Optimality . . . 33
2.4. Algorithm for the General Case . . . 36
2.4.1. Choosing Between the Social and Textual Branches . . . 37
2.5. Efficiency by Approximation . . . 39
2.5.1. Estimating Bounds using Mean and Variance . . . 40
2.5.2. Estimating Bounds Using Histograms . . . 41
2.5.3. Maintaining the Description of the Proximity Vector . . . 43
2.6. Scaling and Performance . . . 44
2.7. System Implementation . . . 46
2.8. Experimental Results . . . 47
2.9. Conclusions . . . 54
3. Context-Aware Search Using Views 57 3.1. Related Work . . . 58
3.2. Formal Setting and Problems . . . 59
3.3. Threshold Algorithms . . . 64
3.4. Extracting a Probable Top-k . . . . 68
3.5. View Selection . . . 69
3.5.1. Retrieving(G, P)After View Selection . . . 73
3.6. Formal Guarantees . . . 73
3.7. Context Transposition . . . 76
3.7.1. Location-Aware Search . . . 77
Contents
3.8. Putting It All Together . . . 81
3.9. Experiments . . . 82
3.10. Conclusions . . . 89
4. Inferring Signed Networks 91 4.1. Related Work . . . 91
4.2. Extracting Interactions from Wikipedia . . . 92
4.3. Building The Signed Network . . . 95
4.4. A Taxonomy of Delete and Replace Interactions in Wikipedia . . . 97
4.5. Empirical Validation . . . 99
4.6. Exploiting WikiSigned at the Application Level . . . 102
4.7. Extracting WikiSigned from the Complete History of Wikipedia . . . 104
4.8. Conclusion . . . 106
5. Research Perspectives 107 5.1. Social Search . . . 107
5.2. Context-Aware Search Using Views . . . 108
5.3. Signed Networks . . . 108
A. Other Collaborations 109
1. Introduction
The ability to query and analyze the unprecedented amount of data present on the World Wide Web, by fast and effective algorithms, has largely contributed to the rapid growth of the Web, making it simply irreplaceable in our every day life. A recent development to the Web is represented by the social Web, i.e., applications that are centered around users, their relationships and their data.
Indeed, large online communities that contribute and share content account nowa-days for a significant and highly qualitative portion of the data on the Web. They may be built as explicitly social (Facebook1, Google+2, Flickr3or Twitter4) or as applications in which social communities represent the “engine” creating content (Wikipedia5). For both these types of Web applications, the presence of user-to-user interactions is a cru-cial part of their success, with one quantifiable measure of this being the tremendous extent to which they have expanded lately. To give just two telling figures, in the last 3 years, the total number of users on Facebook has grown from around 400 million to almost a billion, while the number of tweets per day in Twitter has grown from 40 million to 340 million [76]. With larger user bases, more participation and larger volumes of data comes the need for freshness guarantees and data relevance, driving the need for fast retrieval and effective analysis. Indeed, search techniques and the growth of the Web are undoubtly inter-dependent, as few would publish data on the Web if it could not be found in relevant searches.
For all their promise, the potential of tools provided by today’s socially-enabled Web applications is not yet fully realized. Search systems in which the relationships between the users of a website are taken into account are still relatively rare, and they mainly use simple filtering approaches in order to serve content [33]. Research on reputation measures in social applications that allow for richer link semantics, beyond link/no-link models, like similarity and antagonism in signed networks [75, 60], is still in a very incipient phase. Moreover, the lack of contributor tools, such as classifiers able to differentiate worthwhile contributors from the worthless ones (e.g., vandals) is one of the possible reasons behind the slow decline in contributor activity on the
1http://www.facebook.com 2http://www.google.com/plus 3http://www.flickr.com 4http://www.twitter.com/ 5http://www.wikipedia.org
1. Introduction
Wikipedia [73]6.
This indicates that, in order to fulfill the potential of the social and collaborative Web, there is a real need for social data management systems, and especially for tech-niques able to: (i) infer implicit user links, possibly supporting richer, more informative semantics, even in applications where links do not exist, (ii) effectively rank and
clas-sify the users or contributors in the social network, for use in better recommendation
systems and content ranking models, and (iii) efficiently and effectively rank and serve
content, accounting for the fact that the ranking of content does not depend only on
its data – as is the case in document based IR systems [56] – but also on the relation-ship between the user requesting data and the owners or producers of relevant content.
In this thesis, we focus mainly on two of the three aspects outlined above: the inference of im-plicit social links and the problem of efficient search in social applications, with techniques that also represent first steps towards relevance or reputation ranking for recommendation systems.
More precisely, we approach three important problems in the area of social data management:
1. First, we study the problem of social search, in its network-aware interpretation. Search scenarios in which the network is an integral part of the scoring model require algorithms that go beyond simple adaptations of the current top-k pro-cessing techniques [43, 84]. The semantics of queries changes fundamentally: the scoring model needs to take into account not only the keywords of the query, but also the identity of the user who initiated the query. This brings the need for adapted algorithms that are able to efficiently compute answers for such query-seeker pairs. More importantly, they need to be robust in the presence of massive update rates in the network of users and their data.
The relevant publications for this work are [MCA12] and the corresponding demonstra-tion [MC12].
2. Second, as a natural extension of the above problem, for efficiency and scalabil-ity, we study the scenario where results of searches can be cached, an important functionality supported by all types of search applications. We investigate
top-k query answering in the presence of precomputed query results (that we call views), in the larger scope of context-aware search systems, covering not only
so-cial keyword search but also spatial search. Unlike context-unaware top-k com-putations using views [23, 49], in context-aware scenarios, the data in the views can not be used as is. Crucially, the context in which the views were computed
6The amount of content on the Wikipedia continues to increase, but the number of content creators is
declining.
1.1. Social-Aware Search
has to be transposed to the context of the current query. This introduces uncer-tainty in the views’ data, calling for new query semantics and algorithms.
The relevant publication for this work is [MC13].
3. Third, we study the problem of link inference from interactions in social appli-cations, going beyond simple link prediction. We study signed networks [52] in which links admit not only a positive interpretation of the inter-user attitude, but also a negative one. More precisely, we show that there exists an implicit signed network of contributors in Wikipedia, and describe an approach to infer it, at the scale of the full English Wikipedia. The richer semantics of links in the result-ing signed network, that we call WikiSigned7, can help with tasks like classifying nodes (contributors), pages, or more fined grained content in the network. As a proof-of-concept, we show that the classification of articles in Wikipedia can be significantly improved by taking into account the signed network of contributors.
The relevant publications for this work are [MCA11] and [MAC11].
We continue in the next three sections by giving an overview of the motivations and our contributions to these problems, and we detail them in the subsequent chapters.
1.1. Social-Aware Search
An important class of social applications are the collaborative tagging applications, also known as social bookmarking applications, with popular examples including Delicious8, StumbleUpon or Flickr. Their general setting is the following:
• users form a social network, which may reflect proximity, similarity, friendship, closeness, etc,
• items from a public pool of items (e.g., document, URLs, photos, etc) are tagged by users with keywords, for purposes such as description and classification, or to facilitate later retrieval,
• users search for items having certain keywords (i.e., tags) or they are recommended items, e.g., based on proximity at the level of tags.
Collaborative tagging – and social applications in general – can offer an entirely new perspective to how one searches and accesses information. The main reason for this is that users can (and often do) play a role at both ends of the information flow, as producers and also as seekers of information. Consequently, finding the most relevant
7http://perso.telecom-paristech.fr/~maniu/wikisigned/ 8http://www.delicious.com
1. Introduction
items that are tagged with some keywords should be done in a network-aware manner. In particular, items that are tagged by users who are “closer” to the seeker – where the term closer depends on model assumptions that will be clarified shortly – should be given more weight than items that are tagged by more distant users.
We consider in this work the problem of top-k retrieval in collaborative tagging systems. While the focus on bookmarking applications may seem restrictive, these represent a good ab-straction for other types of social applications, to which our techniques could directly apply.
We investigate this problem with a focus on efficiency, targeting techniques that have the potential to scale to current applications on the Web9, in an online context where the social network, the tagging data and even the seekers’ search preferences can change at any moment. In this context, a key sub-problem for top-k retrieval that we need to address is computing scores of top-k candidates by iterating not only through the most relevant items with respect to the query, but also (or mostly) by looking at the closest users and their tagged items.
We associate with the notion of social network a rather general interpretation, as a user graph whose edges are labeled by social scores, which give a measure of the proximity or similarity between two users. These are then exploitable in searches, as they say how much weight one’s tagging actions should have in the result build-up. For example, even for tagging applications where an explicit social network does not exist or is not exploitable, one may use the tagging history to build a network based on similarity in tagging and items of interest.
Example 1. Consider the collaborative tagging configuration of Figure 1.1. Users have
associ-ated lists of tagged documents and they are interconnected by social links. Each link is labeled by its (social) score, assumed to be in the[0, 1]interval. Let us consider user Alice in the role of the seeker. The user graph is not complete, as the figure shows, and only two users have an explicit social score with respect to Alice. For the remaining ones, Danny, . . . , Jim, only an implicit social score could be computed from the existing links if a precise measure of their relevance with respect to Alice’s queries is necessary in the top-k retrieval.
Let us assume that Alice looks for the top two documents that are tagged with both news and site. Looking at Alice’s immediate neighbors and their respective documents, intuitively, D3 should have a higher score than D4, since the former is tagged by a more relevant user (Bob, having the maximal social score relative to Alice). If we expand the search to the entire graph, the score of D4 may however benefit from the fact that other users, such as Eve or even Holly, also tagged it with news or site. Furthermore, documents such as D2 and D1 may also be relevant for the top-2 result, even though they were tagged only by users who are indirectly linked to Alice.
9The most popular ones have user bases of the order of millions and huge repositories of data; today’s
most accessed social Web application, which also provides tagging and searching functionalities, has almost reached a billion registered users.
1.1. Social-Aware Search !"#$!"#$ !%#$%$&! !&#$%$&!'(!"#$ !&#$%$&! !'#$%$&!'(!"#$ !(#$%$&! !%#$!"#$ !&#$%$&! !(#$!"#$ !)#$%$&!'(!"#$ !(#$%$&! !%#$!"#$ !&#$%$&!'(!"#$ !%#$%$&!'(!"#$ !&#$%$&! !%#$!"#$ !&#$%$&!'(!"#$ !%#$!"#$ !"#$%$&! !&#(%$&! !"#$% &'( )*+,"#% -+../ 01% 2,+.3 4%',5% 6'""/ 78+ 9#: )*+ )*, )*-)*, )*+ )*-)*. )*.-)*/
Figure 1.1.: A collaborative tagging scenario and its social network.
Under certain assumptions to be clarified shortly, the top-2 documents for Alice’s query will be, in descending score order, D4 and D2. We will detail the underlying model and algorithms that allow us to build this answer in the following.
Relation to the most relevant research Classic top-k retrieval algorithms, such as Fagin’s threshold algorithm [31] and the no random access (NRA) algorithm, rely on precomputed inverted-index lists with exact scores for each query term (in our setting, a term is a tag). Revisiting the setting in Figure 1.1, we would have two per-tag inverted lists IL(news) = {D4 : 7, D2 : 2, D1 : 2, D3 : 1, D6 : 1, D5 : 1} and
IL(site) = {D2 : 5, D4 : 2, D3 : 1, D6 : 1, D1 : 1, D5 : 1}, which give the number of times a document has been tagged with the given tag.
When user proximity is an additional ingredient in the top-k retrieval process, a direct network-aware adaptation of the threshold algorithm and variants would need precomputed inverted-index lists for each(user, tag)pair. For instance, if we interpret explicit links in the user graph as friendship, ignoring the link scores, and only tagging by direct friends matters, Alice’s lists would be ILAlice(news) = {D4 : 1, D6 : 1} and
ILAlice(site) = {D3 : 1, D6 : 1}. Other 18 such lists would be require and, clearly, this would have prohibitive space and computing costs in a real-world setting. Amer-Yahia et al. [4] is the first to address this issue, considering the problem of network-aware search in collaborative tagging sites, though by a simplified flavor. The authors consider an extension to classic top-k retrieval in which user proximity is seen as a
1. Introduction
binary function (0-1 proximity): only a subset of the users in the network are selected and can influence the top-k result. This introduces two strong simplifying restrictions: (i) only documents tagged by the selected users should be relevant in the search, and (ii) all the users thus selected are equally important. The base solution of [4] is to keep for each tag-item pair, instead of the detailed lists per user-tag pair, only an upper-bound value on the number of taggers. For instance, the upper-upper-bound for(news, D4)
would be 2, since for any user there are at most two neighbors who tagged D4 with
news. This is called the Global Upper-Bound strategy. A more refined version, which
trades space for efficiency, keeps such upper-bound values within clusters of users, instead of the network as a whole.
Only in Schenkel et al. [69], the network-aware retrieval problem for collaborative tagging is considered under a general interpretation, the one we also adopt in this work. It considers that even users who are indirectly connected to the seeker may be relevant for the top-k result. Their ContextMerge algorithm follows the intuition that the users closest to the seeker will contribute more to the score of an item, thus max-imizing the chance that the item will remain in the final top-k. The authors describe a hybrid approach in which, at each step, the algorithm chooses either to look at the documents tagged by the closest unseen user or at the tag-document inverted lists (a seeker agnostic choice). In order to obtain the next (unseen) closest user at any given step, the algorithm precomputes in advance the proximity value for all possible pairs of users. These values are then stored in ranked lists (one list per user), and a simple pointer increment allows to obtain the next relevant user.
Example 2. Consider the network of Fig. 1.1. With respect to seeker Alice, the list of users
ranked by proximity would be {Bob : 0.9, Danny : 0.81, Charlie : 0.6, Frank : 0.4, Eve :
0.3, George : 0.2, Holly : 0.1, Ida : 0.1, Jim : 0.05}, with proximity between two users built as the maximal product of scores over paths linking them (formalized in Section 2.2.1).
The main drawbacks of [69] are scalability and applicability. Clearly, precomputing a weighted transitive closure over the entire network has a high cost in terms of space and computation in even moderate-size social networks. More importantly, keeping these proximity lists up to date when they reflect tagging similarity10 (as advocated in [69]), would simply be unfeasible in real-world settings, which are highly dynamic. (We revisit these considerations in Section 2.6.)
Contributions We propose an algorithm for top-k answering in collaborative tagging, which has the potential to scale to current applications and beyond, in an online con-text where network changes and tagging actions are frequent. For this algorithm, we
10Tagging similarity may indeed be a more pertinent proximity measure than friendship for top-k search
in bookmarking applications.
1.2. Context-Aware Query Processing Using Views
first address a key aspect: accessing efficiently the closest users for a given seeker. We describe how this can be done on-the-fly (without any pre-computations) for a large family of functions for proximity computation in a social network, including the most natural ones (and the one assumed in [69]). The interest in doing this is threefold:
• we can support full scoring personalization, where each user issuing queries can define her own way to rank items, through parameters and score function choices – see also Section 2.7 for a detailed description,
• we can iterate over the relevant users in more efficient manner, since a typical network can easily fit in main-memory11; this can spare the potentially huge disk volumes required by [69]’s algorithm (see Section 2.6), while also having the potential to run faster.
• social link updates are no longer an issue; for example, if it is based on similarity in tagging actions, we can keep it up-to-date and, by it, all the proximity values at any given moment, with little overhead.
Based on the on-the-fly visit of the relevant network space, our top-k algorithm TOPKS is sound and complete. We show that, when the search relies exclusively on the social weight of the data, it is instance optimal within a large and important class of algorithms. Extensive experiments on real world data show that our algorithm performs significantly better than existing techniques, with up to 50% improvement (see Section 2.8).
For further efficiency, we then consider directions for approximate results. Our approaches present the advantages of negligible memory consumption (they rely on concise statistics about the user network) and reduced computation overhead. More-over, these statistics can be maintained up to date with limited effort, even when the social network is built based on tagging history. Experiments show that approximate search techniques can drastically improve the response time, reaching around 25% of the running time of the exact approach, without sacrificing precision.
The main focus of our work is on the social aspects of top-k retrieval in collabora-tive tagging applications, and our techniques are designed to perform best in settings where tagging actions are mostly (if not exclusively) viewed through the lens of social relevance.
1.2. Context-Aware Query Processing Using Views
Retrieving the k best data objects for a given query, under a certain scoring model, is one of the most common problems in database systems and on Web. In many
applica-11In our view, social networks, excluding the data published by their users, are not “Big Data”, since the
1. Introduction
tions, and in particular in current Web search engines, tens of thousands of queries per second need to be answered over massive amounts of data. Significant research effort has been put into addressing the performance of top-k processing, towards optimal al-gorithms – such as TA and NRA [31, 43] – or highly-efficient data structures [84] (e.g., inverted lists). In recent research, the use of pre-computed results (also called views) has been identified as a promising avenue for improving efficiency [49, 23].
At the same time, with the advent of location-aware devices, geo-tagging, bookmark-ing applications, or online social applications in general, as a way to improve the result quality and the user experience, new kinds of top-k search applications are emerging, which can be simply described as context-aware. The context of a query may represent the geographic location where the query was issued or the identity – within a social net-work – of the user who issued it. Indeed, the setting described in the previous section, i.e. network-aware social search, is an example of a context-aware search application.
More generally, a context could represent certain score parameters that can be de-fined or personalized at query time. For example, a query for top-class vegetarian
restaurants should not give the same results if issued in Paris or in Berlin, as it should
not give the same results if issued within a social community of culinary reviewers or within a student community.
Unsurprisingly, taking into account a query context in top-k processing represents a new source of complexity, and many of the common approaches employed in context-agnostic scenarios need to be revisited [22, 69, 55]. In context-aware scenarios, query processing usually entails an exploration of a “neighborhood” space for the closest or most relevant objects, which is often interleaved with some of the classic, context independent top-k processing steps, such as scans over inverted lists.
Consequently, materializing and exploiting in searches the results of previous queries can play an even more important role for efficient, online processing of queries with context. However, in this direction, a broader view-based answering problem than in the context-agnostic setting needs to be addressed, in which the cached results are modeled as unranked lists of objects having only uncertain scores or score ranges, in-stead of exact scores. The rationale is that, even when the cached results in views do have exact scores with respect to one context, we should expect these to evolve into score ranges when a context transposition is necessary. For example, answers to the pre-vious query, for the Paris context, may be useful – but only to a certain extent – when the same query is issued in a nearby Versailles context, as one has to adapt the scores of restaurants from the parisian perspective to the versaillaise one; this, inherently, introduces uncertainty.
The potential impact of view-based algorithms that can cope with such uncertainty is highly relevant but not limited to the context-aware setting. Indeed, even when queries are not parameterized by a context, some of the most efficient algorithms, such as NRA or TAZ [31] can support early-termination and output unranked results
1.2. Context-Aware Query Processing Using Views
with only score ranges (instead of a precise ranking).
We give next two example scenarios – mostly self-explanatory – from location-aware and social-aware search. They illustrate, on one hand, the fact that previous (cached) results pertaining to one context may be interpretable only as uncertain, by score in-tervals, when dealing with a new query and a new context. On the other hand, they illustrate the fact that it may be possible to corroborate such uncertain descriptions (of scores of objects) from different views, in order to build a most refined or informative approximation of the top-k result that would be obtained by looking at the actual data instead of the views.
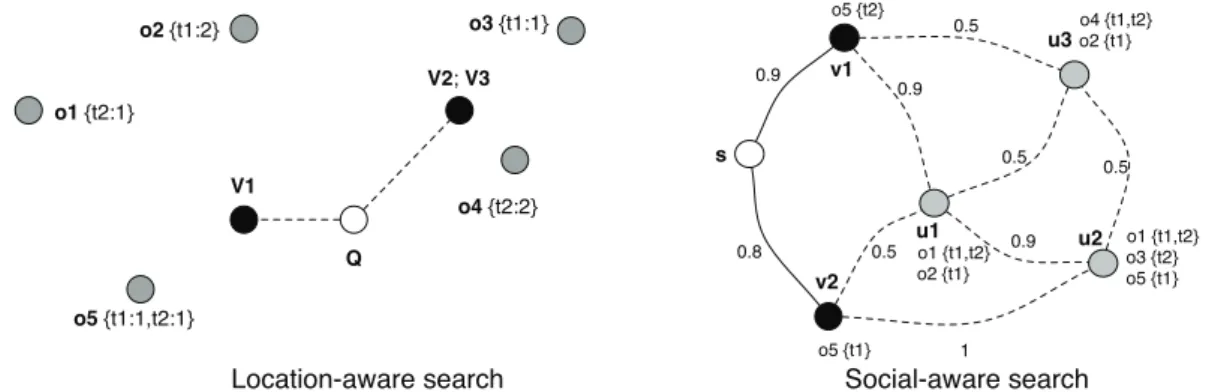
Motivation 1: Location-aware search. Let us consider the spatial-search scenario in
Figure 1.2, in which we have objects at various locations in an euclidian space (objects
o1, . . . , o5 in the figure, as gray dots). Each object (e.g., a Web document) is
character-ized by a bag of attributes. For instance, o5 has attributes t1 and t2, both with a single occurrence.
Now, users located at various points request the top-k objects with respect to a set of attributes. In response, objects are ranked by a combination between the distance of the object w.r.t. the seeker’s location and the object’s content. While the details of the spatial ranking model will be clarified in Section 3.7, let us assume in the following that the location relevance of an object contributes 30% to the score of an object. The remaining 70% represent the weight of the textual score (e.g., tf-idf measures).
Consider a new query Q in the system, asking for the top-2 items for attributes
{t1, t2}at the point marked by a white dot in the figure. Intuitively, spatial search al-gorithms [22], by using indices such as the R-tree [36], would proceed by incrementally increasing the search distance until enough objects are found. However, an alternative execution plan may be possible, if we assume access to cached results of previous queries (initiated at the black dots).
For example, let us assume that v1 gives the top-3 documents for {t1, t2}, as the ranked list {o5 = 1.062, o4 = 1.029, o2 = 1}. Also, sharing the same location, we have v2 and v3. The former gives the top-4 for {t1}as {o2 = 0.946, o3 = 0.575, o5 =
0.425, o4= 0.262}. The latter gives the top-4 for{t2}as {o4= 0.962, o1= 0.437, o5=
0.425, o2=0.246}.
Since v1, v2 and v3 are closer to Q than any of the objects, it would be tempting to use their lists of pre-computed results, instead of looking for the actual objects.
In particular, one may resort to using only the results of v1, as it is the closest to
Q both spatially and textually. For that, we need first to perform a change of
con-text, to account for the fact that objects that were close to v1 may be even closer to
Q, as they may be farther. This will introduce uncertainty in the scores of v1’s
re-sult set. More precisely, knowing that the normalized distance between Q and v1 is 0.175, for Q’s perspective, v1’s list should now have objects with score intervals, as
fol-1. Introduction !"!"#$%&' !#$"#&%$' !%!"#&%&' !&!"#&%&(#$%&' !'!"#$%$' ( )#)!)% )" ! * +" +# ," ,# ,% *+, *+-*+. *+. *+. & *+. *+-/&!"#&(#$' /$!"#&' /.!"#$' /0!"#&(#$' /$!"#&' /&!"#&(#$' /1!"#$' /.!"#&' /.!"#&' 2/34#5/674849:!;:493< =/354>74849:!;:493<
Figure 1.2.: Context-aware search scenarios.
lows:{o5∈[1.062−0.3×0.35, 1.062+0.3×0.35], o4∈[1.029−0.3×0.35, 1.029+0.3×
0.35], o2∈[1−0.3×0.35, 1+0.3×0.35]}={o5∈[0.957, 1.167], o4∈[0.924, 1.134], o2∈ [0.895, 1.105]}.12
We can see that v1’s result is not sufficient to answer Q with certainty, since any object among the three candidates may be in the top-2. Yet the solution can come from v2 and v3, albeit more distant, if we corroborate their results with the ones of
v1. Knowing that v2 and v3 are at a normalized distance of 0.25 the transposed scores
would be, for v2{o2∈ [0.871, 1], o3∈[0.5, 0.65], o5∈[0.35, 0.5], o4∈[0.187, 0.337]}and for v3{o4∈ [0.887, 1.037], o1∈[0.362, 0.512], o5∈ [0.35, 0.5], o2∈[0.171, 0.321]}.
Aggregating the three result sets, after accounting for the context transposition, would allow us to identify the top-2 objects for Q as{o4∈ [1.074, 1.135], o2∈[1.043, 1.106]}, since all other objects have scores of at most 1.043.13 We can output this result, without having to compute the exact locations and scores of o4 and o2.
Motivation 2: Social-aware search. As a second motivating example, we consider the
setting of collaborative bookmarking applications (such as Flickr or Del.icio.us). In these applications, users bookmark (or tag) objects from a common pool of objects (e.g., Web sites). Users form a social network, in which relationships are weighted (e.g., a similarity or proximity value). Such a setting is illustrated in Figure 1.2. For example, user u1 has tagged object o1 with t1 and t2, and o2 with t1, and it is 0.9-close (or similar) to u2.
We use the social ranking model introduced by Amer-Yahia et al. [4] and extended by Schenkel et al. [69] and ourselves in [MC12]. Intuitively, under this model, the score of an object for a given tag is proportional to the sum of the proximities of the taggers w.r.t. the seeker. The score of an object for a set of tags is then computed by
120.35 is obtained as 0.175+0.175, since the query has two tags.
13For example, o4 has a minimal score obtained as max(0.887+0.187, 0.924).
1.2. Context-Aware Query Processing Using Views
aggregating the per-tag scores, e.g., by summation.
Let us now assume that the top-3 items for {t1, t2} are requested by user s (the seeker). As in location-aware search, early termination algorithms [69] for social search would incrementally explore the most promising users (and their objects) until the
top-k is found. This may lead to the visit of a non-negligible fraction of the networtop-k. For
our query, an exploration of the network would need to go as far as u2 to establish a top-3 as{o1, o2, o5}.
Yet an alternative, more efficient processing approach may rely on pre-computed results. Let us assume that users v1 and v2 have such data: v2 has obtained the top-4 for {t1}, as {o1 = 1.71, o5 = 1.63, o2 = 0.5, o4 = 0.5}, and the one for {t2}
as {o1 = 1.71, o5 = 1, o2 = 0.9, o3 = 0.81}. v1 has obtained the top-5 for {t1, t2} as
{o1=3.42, o5=2.63, o2=1.35, o4 =1, o3=0.81}.
Knowing that the distance between s and v1 is equal to 0.9, in manner similar to the spatial-aware search scenario, the context transposition from v1 to s (the formal rank-ing model will be described in Section 2.2) leads to the followrank-ing result set for{t1, t2}:
{o1 ∈ [3.07, 3.8], o5 ∈ [2.27, 2.81], o2 ∈ [1.21, 1.5], o4 ∈ [0.9, 1.11], o3 ∈ [0.72, 0.9]}. Sim-ilarly, knowing the distance between v2 and s is 0.8, transposing the context leads to the results for {t1}: {o1 ∈ [1.36, 2.13], o5 ∈ [1.3, 2.03], o2 ∈ [0.4, 0.62], o4 ∈ [0.4, 0.62]}. and{t2}: {o1∈ [1.36, 2.13], o5∈ [0.8, 1.25], o2∈ [0.72, 1.12], o3∈ [0.64, 1.01]}.
It can hence be seen that, after visiting just the neighbors v1 and v2, the search for
s’s query can give the top-3 objects as{o1∈[3.07, 3.8], o5∈[2.27, 2.81], o2∈[1.21, 1.5]}. The general goal of this study is to enable efficient context-aware top-k retrieval through techniques that exploit exclusively the views. The rationale for this is that in many prac-tical applications, access methods may be extensively optimized for views, the size of cached results may be much less important than the one of the complete data (e.g., of the inverted lists), and view results (pre-computed for groups of attributes) may be much more informative towards finding the result for the input query. For instance, a user may go through a sequence of query reformulations, for which result caching may be highly beneficial. View results may even be bound to main-memory, in certain scenarios.
Contributions We formalize and study in this work the problem of context-aware top-k processing based on possibly uncertain precomputed results, in the form of
views over the data.
We start by investigating top-k processing after the context transposition has been per-formed, for a given input query and its context. The problem of answering such top-k queries using only the information in views, inevitably, requires an adaptation to the fact that these views may now offer objects having uncertain scores. Consequently, there might exist view instances from which an exact top-k cannot be extracted with
1. Introduction
full confidence. When this is the case, it would be unsatisfactory to simply refute the input query, or to consider alternative, more expensive execution plans (e.g., by going through the per-attribute lists). Instead, it would be preferable to provide a most
in-formative answer, in terms of (i) objects G that are guaranteed to be in the top-k result,
and (ii) objects P that may appear in the top-k result.
We formalize this query semantics and describe two adaptations of TA and NRA, called SR-TA and SR-NRA. They support precomputed lists with score ranges and the above described query semantics and are sound and complete, i.e., they output the
(G, P)-answer. Intuitively, they implement the corroboration principle illustrated be-fore, based on a linear programming formulation.
Given that in many applications the set of views may be very large – think of social applications in which many users may have pre-computed results – we also consider optimizations for SR-TA and SR-NRA, based on selecting some (few) most promising
views. Obviously, with fewer views, the most informative answer(G, P)may no longer be reached, and we are in general presented a trade-off between the number of selected views – which determines the cost of the top-k algorithms SR-NRA and SR-TA – and the “quality” of the result (a distance with respect to the most informative answer given by all the views). Importantly, we also show that SR-NRA and SR-TA, when selecting views, are complete and instance optimal for an important family of view spec-ifications. Complementing our top-k retrieval through view selection, we also show how a final refinement step allows us to reach the most informative result.
As a last level of service that can be provided to users, we then consider a sampling-based approach by which, from the most informative result, a probabilistic interpreta-tion can also lead to a most likely top-k answer to the input query.
Importantly, our algorithms provide a one-size-fits-all solution for many search appli-cations that are context-dependent, and we show how they can be directly applied in our two motivating applications scenarios for context-aware search. For both scenar-ios, we also describe the necessary step of context transposition, transforming scores or ranges thereof, valid in one initial context, to ranges that are valid in a new context, for ranking models combining textual and location dimensions.
Extensive experiments on both synthetic and real-world datasets illustrate the poten-tial of our techniques – enabling high-precision retrieval and important running-time savings. More generally, they illustrate the potential of top-k query optimization based on cached results in a wide range of applications.
1.3. Inferring Signed Social Networks
An important trend in social platforms aims at exploiting the already existing user relationships, links between users (e.g., social links), in order to improve core