Information Quality in Social Networks: Predicting Spammy Naming Patterns for Retrieving Twitter Spam Accounts
14
0
0
Texte intégral
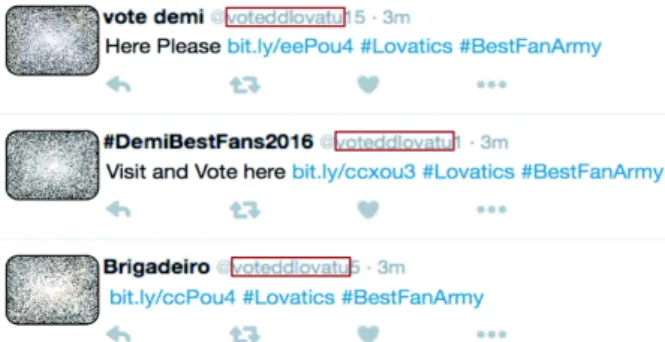
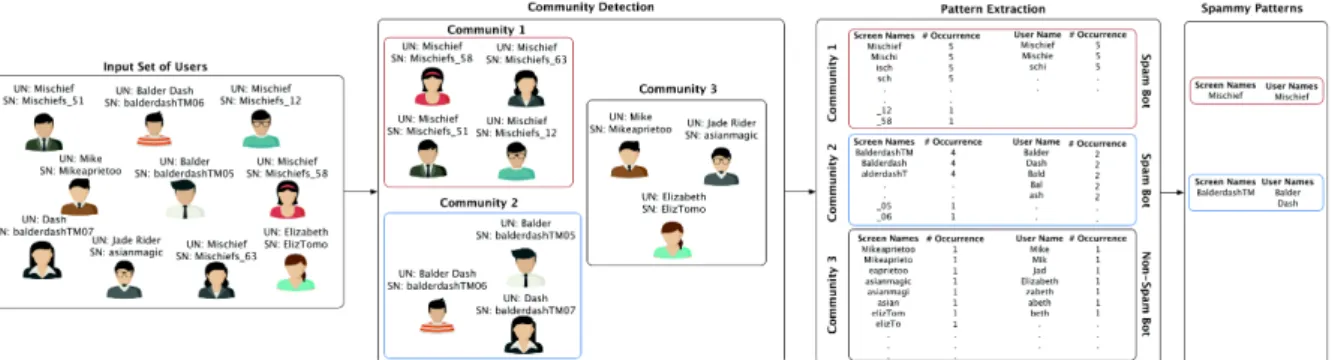
Figure


Documents relatifs
