Localisation d'objets urbains à partir de sources multiples dont des images aériennes
Texte intégral
Figure



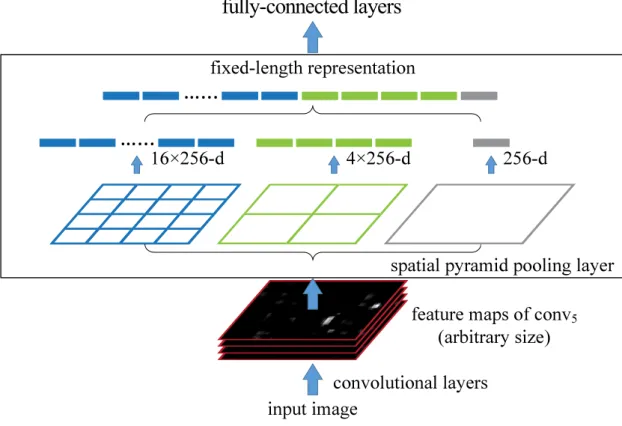
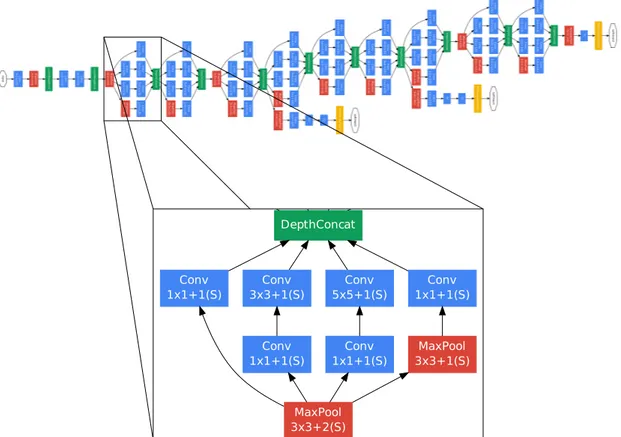
![Fig. 1: Architectures with changes compared to CaffeNet [12] visualized. C(f,s) represents a convolutional layer with f filters and a stride of s.](https://thumb-eu.123doks.com/thumbv2/123doknet/7724327.248707/72.892.122.752.260.602/architectures-changes-compared-caffenet-visualized-represents-convolutional-filters.webp)



Outline
Documents relatifs
Nous étudions ensuite la faisabilité d’un système de géolocalisation de ressources industrielles en utilisant des objets communicants de type beacon bluetooth low energy (BLE),
Nadia montrent clairement le caractère anxiogène du premier segment et érotique du second segment pour les jeunes femmes, on peut supposer à un moindre degré que c’est
L'absorption est le phénomène par lequel un objet éclairé absorbe une partie de la lumière incidente... Ex : une feuille blanche éclairée par une lumière blanche
Mais je me suis aussi inscrit en histoire, en philosophie (il y avait alors un certificat de sociologie qui accompagnait les études de philosophie), en science
L’espace des musées de la Shoah est à la fois contenu et contenant, construit politique, social et esthétique, matière, mémoires, circulations, déplacements et performances
Mais, autant les travaux autour des métadonnées pédagogiques sont actuel- lement en train de converger, autant le problème de la structuration même des objets pédagogiques est,
Le diaphragme d’ouverture ( DO ) permet de régler l’angle du cône de lumière qui pénètre dans le condenseur et qui éclaire la préparation en évitant des lumière parasites
Posez sur la platine le micromètre objectif divisé en 1/100 mm et déplacez le tube pour voir à la fois les divisions des deux micromètres.. Par rotation de l'oculaire sur
