Université de Montréal
La dynamique spatio-temporelle de l'attention dans la lecture
par
Augustin Achouline, B.sc
Mémoire
présenté en vue de l’obtention du grade de maîtrise en psychologie (M.Sc.) sous la direction de Martin Arguin, Ph.D.
Résumé
Mots-clés : lecture, attention, visuo-spatiale, parallèle, sérielle, processus, longueur, mot, effet
Un grand nombre d’études examinant les aspects cognitifs et neurobiologiques de la lecture ont étés conduites dans les dernières décennies. Cependant, la stratégie qui sous-tend l’identification de mots pour des lecteurs experts et la manière dont l’attention visuo-spatiale est déployée dans le temps et l’espace visuel demeurent méconnues. L’étude de Blais et al. (2009) nous apporte une avancée significative dans nos connaissances à ce sujet. La présente étude se propose d’étendre leur investigation initiale à l’aide d’un protocole capable de spécifier comment l’information visuelle est extraite dans l’espace et dans le temps au cours d’une tache de reconnaissance de mot chez des lecteurs neurotypiques.
16 étudiants ont été testés à l’aide d’une tâche inspirée de la méthode des « Bulles ». Ils devaient lire des mots français de cinq lettres présentés pendants 200 ms et échantillonnés dans l’espace-temps avec un ratio signal/bruit variant aléatoirement et de manière indépendante pour chaque position de lettre. Un bloc de 150 essais de pratique était d’abord complété, pendant lequel le ratio signal/bruit était ajusté de manière à maintenir le taux de succès à 51%. Ensuite, quatre blocs de 150 essais chacun étaient complétés, eux même suivis d’un nouveau bloc de 75 essais d’entrainement afin de réajuster le ratio signal/bruit maximum. Enfin, quatre blocs additionnels de 150 essais chacun étaient complétés.
Les analyses examinent comment les variations temporelles du ratio signal/bruit déterminent le taux d’acuité des participants. Des images de classification dans le domaine temporel ont été construites pour chaque participant en soustrayant la somme pondérée des profils temporels de ratio
signal/bruit des essais incorrects de ceux associes à une réponse correcte.
Nous avons également construit des images de classification dans le domaine temps-fréquence qui indiquent la contribution de bandes de fréquences spécifiques pour l’efficacité d’encodage en fonction du temps. Les images de classifications individuelles étaient transformées en scores Z afin d’être sur une même échelle et pouvoir ainsi calculer des moyennes de groupes. La significativité statistique était déterminée par l’application du test Pixel.
Les résultats suggèrent un processus d’extraction des lettres sériel, dans lequel l’ordre des lettres est fonction de la valeur diagnostique de cette lettre pour l’identification correcte du mot. Ces observations sont inconsistantes avec un modèle d’extraction parallèle, généralement admis pour expliquer l’absence d’effet de longueur de mot dans la lecture experte. Elles semblent en effet indiquer un mode de traitement sériel des lettres à l’intérieur duquel le traitement de plusieurs lettres conjointes reste possible. L’absence d’effet de longueur du mot dans un contexte de traitement sériel serait expliquée par l’hypothèse que le nombre de lettres à identifier (et/ou le nombre de fixations attentionnelles requis) demeure fixe, quelque soit la longueur du mot. Cependant, cette hypothèse reste encore à étayer ; en testant ce protocole sur des mots de différentes longueurs.
Abstract
Keywords: reading, visuospatial, attention, parallel, serial, processing, word, length, effect
A vast number of studies examining the cognitive and neurobiological aspects of reading have been conducted in the past decades. However, the strategy underlying expert word identification and the way visuospatial attention is deployed across time and space remains unknown. The study from Blais et al. (2009) offered a significant advance to our knowledge in this regard. The present study extends this initial investigation by using a protocol which can specify how visual information is extracted in space and time during visual word recognition in neurotypical readers.
16 students were tested using an adaptation of the « Bubbles » technique. Participants read five-letter French words exposed for 200 ms and sampled in space-time by random signal-to-noise ratio (SNR) variations which were independent for each letter position. Participants first completed a 150-trial practice session during which the maximum allowable SNR was adjusted in order to maintain accuracy at about 51% correct. Then, four experimental blocks of 150 trials each were completed. This was followed by a 75-trial practice block to readjust the maximum allowable SNR. Finally, four additional blocks of 150 experimental trials each were conducted.
Data analyses examined how the temporally varying signal/noise determined the response accuracy of participants. Classification images in the temporal domain were constructed for each participant by subtracting the weighted sum of the temporal profiles of signal/noise ratios of incorrect trials from those associated with correct responses. We also constructed classification images in the time-frequency domain which indicate the contribution of particular frequencies as a function of time to processing effectiveness. Individual classification images were transformed into Z scores to put them on the same scale, thereby allowing the calculation of group means. Statistical significance was
determined by the application of the Pixel test.
The results suggest a serial processing of letter extraction information in which the order of letters is a function of the diagnostic value of that letter for word identification. These observations are inconsistent with a parallel processing model, which is the generally accepted account for the invariant latency of expert visual word recognition as a function of word length. These would seem to indicate a serial processing of letters within which several joint letters are still possible. The absence of word length effect in the serial processing would be explained by the number of letters (and/or the number of attention attachments required) which remains constant whatever the length of the word. However, this hypothesis still need to be substantiated by testing this protocol on words of different lengths.
Table des matières
Résumé...2
Abstract...4
Table des matières...6
Liste des sigles...8
Remerciements...9
Introduction...10
Contexte théorique...13
Les bases neurobiologiques de la lecture...13
Oscillations cérébrales et lecture...16
Les mouvements des yeux au cours de la lecture ...18
Les modèles théoriques de la lecture...20
Objectifs et hypothèses...25 Méthodologie...25 Participants...25 Matériel...26 Procédure...28 Résultats...30 Domaine temporel...30 Analyses temps-fréquence...32 Analyses phase-amplitude...35 Analyses de conjonction...36 Discussion...47
Images de classification des profils d'échantillonnage...47
Images de classification des conjonctions de lettres...50
Conclusions...51
Références...52
Annexes...66
I) Liste des mots utilisés dans l’expérience...66
II) Matrices de corrélation de l'échantillonnage temporel (par paires de sujets)...86
Liste des sigles
CGP = Conversion graphème-phonème
DSM = Diagnostic and Statistical Manual of Mental Disorders HG/HD = Hémisphère gauche/droit
Hz = Hertz
INSERM = Institut national de la santé et de la recherche médicale (en France) IRM (fMRI anglais) = Imagerie par Résonance Magnétique
LCD (modèle théorique) = Local Combination Detectors LPL (dyslexie) = lettre-par-lettre
MTM (modèle théorique) = Multiple Trace Memory PDP (modèle théorique) = Parallel Distributed Processing PVL = Preferred Viewed Location
RD = Radial Diffusivity (ou diffusivité radiale) RSB = Ratio signal/bruit
V1, V2, V3, V4, VO, MT = Aires du cortex visuel
Remerciements
Je tiens à exprimer toute ma reconnaissance à mon directeur de mémoire, Monsieur Martin Arguin. Je le remercie de m’avoir encadré, orienté, aidé et conseillé tout au long de la réalisation de ce travail et de m’avoir encouragé dans les moments où je rencontrais des difficultés.
J’adresse mes sincères remerciements à mon camarade de laboratoire Simon Fortier-St-Pierre pour ses conseils et ses critiques qui ont guidé mes réflexions et pour avoir accepté de me rencontrer et de répondre à mes questions durant mes recherches. Je remercie également toutes les personnes qui par leurs paroles, leurs écrits, leurs encouragement ont su m’accompagner dans cette tâche.
Je remercie mes parents, Jeanne et Charles, qui ont toujours été là pour moi malgré la distance. Je remercie mes sœurs Laure, Sonia et Sarah pour leurs encouragements.
Enfin, je remercie mes amis Antoine, Tarik et Monsieur Luis pour leur soutien inconditionnel et leurs encouragements qui ont été d’une grande aide.
Introduction
Les premières traces connues de représentation graphique et de symbolisation de concepts remontent à la préhistoire comme l’atteste l'étude des peintures rupestres laissées par les homos sapiens dans des grottes paléolithiques tel que Chauvet aux alentours de 33 000 av. JC ou les grottes de Lascaux vers 18 000 av. JC (Deahene, 2007, p. 240 et p. 248). Celles-ci présentent déjà des formes très sophistiquées de représentation graphique. En effet, on observe dès lors une innovation majeure dans l’évolution des prémisses de l’écriture : Le simple tracé du contour d’une figure suffit à en évoquer l’objet (bison, cheval, etc) sans avoir besoin de passer par une reproduction de la forme en trois dimensions ni même d'en peindre la surface (Deahene, 2007, p. 240-257). Pourtant, l'invention de l’écriture moderne, c’est à dire en tant que « système codifié et organisé de signes en nombre limités permettant de transcrire l'ensemble des énoncés de la langue avec laquelle il entretient des rapports plus ou moins étroits » (Alain Gallay, 2008) est beaucoup plus tardive dans l’histoire de l’humanité. Classiquement on considère quatre grands centres géographiques au sein desquels l’écriture aurait été inventée de manière indépendante : la Mésopotamie, environ 3300 av. JC, l’Egypte vers -3000, la Chine aux alentours de -1500 ainsi que l’écriture Maya en Amérique centrale au IIIe siècle avant notre ère (Viviane et al., 2012).
Quand on considère l'ancienneté des premiers systèmes d’écriture, et la grande diversité des langues écrites à travers les cultures, on peut avoir tendance à considérer le langage écrit comme universel. C'est à dire comme une potentialité innée de l'être humain, présente dans sa génétique et s’exprimant par la faculté en puissance d'apprendre à lire qui ne pourra se développer que dans un contexte relationnel stable et stimulant (apprentissage scolaire, parental ou autre). Pourtant, comme le soulève Stanislas Deahene dans son livre, Les Neurones de la Lecture (2007), l'écriture est une
invention culturelle et, par conséquent, le système nerveux n'a pas pu évoluer en fonction d’elle. Il nous propose dans cet ouvrage l’idée suivante, si l'histoire de l'écriture est si ancienne, son usage n'a longtemps été réservé qu'à une couche restreinte de la population. Elle se serait ainsi développée par rapport à la reconversion d’aptitudes cognitives préexistantes dans notre système visuel.
L’invention de l'imprimerie par Gutenberg au XVe siècle ainsi que son développement au cours de la renaissance ont permis une démocratisation des savoirs. On estime à 20 millions le nombre de livres imprimés dans les 50 années suivant l'invention de l'imprimerie, l'Allemagne possédant à elle seule plus de 200 ateliers d'imprimerie en 1500 (Buringh & Van Zanden, 2009). Ainsi, grâce à l'impression, le coût du livre baisse, la main-d’œuvre devient bon marché et la matière première également. Nous avons donc une population pouvant se constituer une bibliothèque privée. La production d'ouvrages ne cesse de croitre durant tout l'ancien régime, passant de 200 millions au XVIe siècle au milliard en 1800 (Eisenstein, 1980) bien que le taux d'alphabétisation reste inférieur à 50% pour une bonne partie de l’Europe jusqu'à l'aube du XXème siècle. Aujourd'hui la lecture, et plus particulièrement la lecture de caractères dactylographiés, occupe une place centrale dans nos interactions avec nos pairs et notre environnement. Si les supports et les besoins auxquels ils répondent ont subi de profonds changements, la langue écrite n’a pas cessé de maintenir un rôle social important. En effet, la révolution numérique et les bouleversements qui en découlent dans les nations industrialisées à travers l'essor et le développement des technologies (notamment internet, informatique, téléphonie) se traduit par de nouvelles formes de communication et d'information (courriel, réseaux sociaux). Les supports papier traditionnels (journaux, livres) laissent progressivement leur place aux écrans (Donnat, 2009). La publicité, qui s’appuie sur des études en psychologie cognitive et en neuromarketing, utilise l'écriture combinée avec différents modes d'encodages (encodage visuel et auditif) afin de maximiser l'impact de son message sur la mémoire et le comportement des consommateurs (Fouesnant & Jeunemaître, 2012).
On observe ainsi dans les différentes sphères de nos sociétés, une abondance considérable de stimuli écrits qui placent l'individu dans une situation de surexposition quasi permanente. Selon Geisler et Murray (2003), un adulte de 25 ans, aurait lu en moyenne plus de cent millions de mots dactylographiés et été exposé à chaque mot courant de la langue plusieurs centaines de milliers de fois. Dans un tel contexte, le jeune lecteur devra accéder rapidement à un haut niveau d'expertise afin de s'émanciper intellectuellement et de parvenir à une bonne intégration sociale. Les aires visuelles de notre système nerveux semblent effectivement s'adapter à l'acquisition d'une telle expertise. Elles s'organisent et se spécialisent dans la reconnaissance et le traitement rapide de mots écrits au cours de l'apprentissage (Dehaene et al, 2010). Ainsi, d'après Dehaene et ses collaborateurs qui s’appuient sur des comparaisons avec le fonctionnement des aires visuelles chez le singe, le cortex visuel se recyclerait, effectuant une sorte de reconversion afin d'identifier et de traiter de manière spécifique les mots écrits à partir d'un système qui n'est pas, initialement et en termes d'évolution, prévu pour cette tâche. Sur la base de ces observations, deux questionnements sont soulevés par la littérature : Comment le système visuel réussit-il à s'adapter à la lecture experte et quelles sont ses limites ?
Pour appréhender ces questions, de nombreuses études en psychologie cognitive, neuropsychologie, optométrie, etc. ont proposé des paradigmes expérimentaux et permis de construire des modèles théoriques cohérents. Cependant, si certains des mécanismes sous-tendant la lecture sur les plans cognitif et neuronal sont mieux connus, de nombreuses zones d'ombre persistent encore dans la littérature. En effet, les modèles théoriques sont nombreux et en contradiction sur plusieurs plans, créant des divisions dans la communauté scientifique. Il devient ainsi primordial d'établir un protocole permettant d'appréhender plus finement la manière dont le lecteur extrait l'information visuelle contenue dans un mot, une lettre ou même un trait.
Comment l’attention visuelle se déploie-t-elle dans le temps et dans l’espace visuel pour que le lecteur puisse accéder à un encodage sémantique du mot ? C’est à cette question que nous tâcherons de
répondre afin de mieux cerner les mécanismes qui sous-tendent la lecture dite « normale » ou neurotypique.
Contexte théorique
Les bases neurobiologiques de la lecture
En 1892, le neurologue français Joseph-Jules Déjerine observe pour la première fois qu'une lésion située dans une région particulière de l’hémisphère gauche entraîne une perte sélective des capacités de lecture. Après autopsie du patient lésé, Déjerine découvrit que la zone atteinte était située dans la région ventrale occipito-temporale de l’hémisphère gauche. Par la suite, des travaux en IRM fonctionnelle vont confirmer que cette région du sillon occipito-temporal latéral présente des activations significatives lors d'une tâche de lecture. De plus, l’étude conduite par Cohen et ses collaborateurs (2002) a permis d’observer que l’aire occipito-temporale présentait des activations préférentielles à la présentation d'un mot plutôt que d'une chaine de consonnes. Cet effet est retrouvé de manière constante chez les bons lecteurs (Dehaene, Leclech, et al., 2002). Le sillon occipito-temporal latéral appelé également « aire de la forme visuelle des mots » (visual word form area, ou VWFA) est situé au sein d'une mosaïque de régions très spécialisées dans la reconnaissance de classes diverses de stimuli visuels, comme les visages, les maisons, les lieux ou les objets (Ishai et al., 2000. Hasson et al., 2002, 2003), ce que confirment les études en électrophysiologie (Bentin, Allison, Puce et al.,1996). On pourrait ainsi considérer cette région comme le centre intégrateur de la lecture dans le cerveau.
Si des différences inter-individuelles persistent (certains sujets présentant des activations plus bilatérales que d’autres), les activations liées à la lecture restent très nettement latéralisées à gauche pour une large majorité de la population (Dehaene, Leclech, et al., 2002). Ainsi, la région occipito-temporale ventrale gauche est la première à répondre de manière invariante chez les lecteurs normaux que le mot soit présenté du côté droit ou gauche d'un point de fixation (Cohen, Dehaene et al. Brain,
2000. Molto et al., 2002). Un phénomène appelé invariance spatiale entre les hémichamps, nous permet de maintenir des performances de lecture fonctionnelles pour des mots présentés dans les deux champs visuels et ce malgré la nette dominance de l’hémisphère gauche. Ce phénomène nécessite une transmission des informations visuelles entre les hémisphères via le corps calleux.
Un paradigme expérimental proposé par Binder et ses collaborateurs (2006) nous permet d’aller encore plus loin. Ces auteurs ont utilisé quatre catégories de non-mots construits en fonction de la régularité orthographique des bigrammes qui les constituent. C'est à dire que les paires de lettres sont contrôlées par rapport à leur fréquence d’apparition dans la langue. Ils remarquent de cette manière que les activations de la région occipito-temporale sont d'une amplitude proportionnelle à la fréquence des bigrammes utilisés pour construire les non-mots. Ces observations suggèrent que les règles d'orthographe arbitrairement apprises dans un cadre culturel défini (une langue, un alphabet) sont codées sur le plan physiologique, les neurones se spécialisant pour reconnaître des configurations de lettres fréquentes.
Des études en magnétoencéphalographie se sont penchées sur le trajet emprunté par l'information visuelle pendant une tâche de lecture (Donhg et al., 2001). Le sillon occipito-temporal semble ainsi occuper une place de carrefour dans ce circuit, il reçoit des afférences depuis la région occipitale puis l'information repart en transit vers les régions temporo-pariétales (accès aux sons), précentrale (accès à la prononciation et à l’articulation) et frontale (accès au sens). Il est possible de distinguer deux grandes voies empruntées par l’information visuelle (Milner et Goodale, 2008). Une voie dorsale qui projette l'information vers le cortex pariétal supérieur et qui serait impliquée dans la localisation ainsi que dans la production des représentations nécessaires pour interagir avec les objets visuels (où, comment ?) et une voie ventrale qui s'étend jusqu'au cortex inférotemporal et serait responsable de l’identification des objets (quoi ?). Dans le cas de la lecture, on constate que le traitement visuel de matériel écrit est susceptible d’activer ces deux voies. La voie ventrale semble
principalement impliquée dans une reconnaissance rapide et parallèle des mots écrits tandis que la voie dorsale contribuerait à une lecture sérielle et attentive (voir chapitre « les modèles théoriques »). Ainsi, chez un patient présentant des lésions de la voie dorsale, on constate une incapacité à utiliser la lecture sérielle pour des conditions d'altération du stimulus qui supposeraient la mobilisation de ces processus : orientation du mot cible à la verticale ou inversé (de droite à gauche), angle de rotation supérieur à 80°, espacement des lettres supérieur à deux espaces (Vinckier et al., 2006).
L’ensemble des aires visuelles de notre système nerveux est organisé de façon hiérarchique : l’information est d'abord traitée dans le cortex visuel primaire (V1) puis par les aires V2, V3, V4, VO et enfin VWFA dans le cas de la voie ventrale. D’autres aires comme l'aire MT sont activées par la voie dorsale. Cette dernière aurait une implication dans les mouvements oculaires et attentionnels pendant la lecture (Leigh et Zee, 2015). La lecture experte dite "normale" requerrait donc la collaboration des deux voies de traitement de l’information visuelle pour fonctionner de manière optimale.
En dehors du cortex visuel, de nombreuses autres régions cérébrales s'activent lors d'une tâche de lecture (Wandell, Rauschecker et Yeatman, 2012). Il s'agit d’aires ayant une implication dans le langage et donc par extension dans le traitement linguistique des mots écrits. Ainsi le gyrus temporal jouerait un rôle dans le traitement phonologique réceptif alors que le gyrus frontal inférieur "pars opercularis" serait lui impliqué dans le traitement phonologique productif. De même que le gyrus supramarginal et le gyrus frontal inférieur "pars triangularis" se rapporteraient plutôt au traitement sémantique. Les aires visuelles situées dans les lobes temporal et pariétal sont reliées à l’aire de Broca dans le cortex frontal par le faisceau arqué. Celui-ci semble occuper un rôle fondamental dans la lecture. Ainsi, l’étude en imagerie par diffusion de Yeatman et ses collaborateurs (2011) sur des enfants de 7 à 11 ans, mesure les activations d'une portion de matière blanche correspondant aux axones du faisceau arqué lors d’une tâche de lecture. Ces auteurs observent que la diffusivité Radiale (ou Radial Diffusivity, RD), correspondant au taux de diffusion de l'information dans le faisceau arqué, serait
corrélée positivement à la conscience phonologique. C’est à dire à la compréhension du fait que les mots sont composés de phonèmes ou de sons. Celle-ci se traduit notamment par la capacité à percevoir et manipuler les unités sonores du langage. Or, cette conscience phonologique représente une composante majeure de la lecture experte (Wandell et al., 2012).
Oscillations cérébrales et lecture
D’une manière générale, le terme d’oscillation renvoie à des fluctuations rythmiques de différents états d’un système. C’est à dire que les occurrences répétées d’un même état se retrouvent à des intervalles de temps similaires (Cohen, 2015). Dans le cas de systèmes biologiques, le temps entre les états n’est pas exactement identique mais possède néanmoins des propriétés rythmiques, on parlera alors avec plus de précision de « quasi-oscillation » ou de « signal quasi-périodique » comme par exemple le cycle jour-nuit, ou l’alternance des saisons. Les oscillations peuvent être représentées par une courbe sinusoïdale ou une collection de telles courbes. Elles sont toutes caractérisées par trois traits: la fréquence exprimée en Hertz (Hz) qui réfère à la vitesse des oscillations. Cela correspond au nombre de fluctuations par seconde. L’amplitude qui mesure la force de l’activité du système et la phase qui renvoie à la position du système par rapport aux oscillations.
Dans notre cerveau, des groupes de neurones présentent des activations alternantes entre des périodes d’excitabilité et d’inexcitabilité. Ces groupes de neurones agissent en envoyant des vagues d’impulsions électriques synchronisées dont l’activité est fortement oscillatoire. Plus précisément, les neurones excitateurs et inhibiteurs sont très densément interconnectés. Ainsi, lorsque des neurones excitateurs deviennent actifs, ils s’activent les uns les autres entraînant un gain massif d’excitation. Ils activeront également les neurones inhibiteurs, ce qui entraînera une diminution progressive de l’excitation. C’est ainsi qu’une activité cyclique se forme. Certains groupes de neurones répondent à
des fréquences bien spécifiques en ignorant les informations qui leur proviennent sous d’autres fréquences (Hutcheon et Yarom, 2000; Mehaffey et al., 2008). D’autres auteurs ont révélé que certaines oscillations allaient beaucoup varier alors que d’autre resteront totalement inflexibles. Il est ainsi possible de classer ces oscillations en fonction de leur flexibilité sur un axe Stabilité-Adaptation (Cohen, 2015; Falk, 2010). Notre cerveau est capable de prédire et de préparer des actions ou des événements sur la base de ces oscillations. On peut dire alors que le système nerveux est contraint de maintenir en permanence un certain équilibre entre assez de flexibilité pour s’adapter à l’environnement, donc aux événements extérieurs imprévus et assez de régularité pour conserver ce caractère prévisible des oscillations (Cohen, 2015).
Cohen observe également que des oscillations avec différentes fréquences peuvent se produire simultanément. La transformation de Fourier permettra alors de révéler des oscillations distinctes dans le domaine fréquence. Celle-ci peut être utilisée pour décomposer le signal sinusoïdal dans le domaine temporel en composants individuels et ainsi parvenir à analyser plus finement les oscillations impliquées dans une tâche cognitive spécifique (Bracewell, 1986).
Dans le cas de la perception visuelle, les bandes de fréquences les plus fortement impliquées sont les bandes alpha (environs 10 Hz). Les oscillations sensorielles permettent une certaine flexibilité et peuvent ainsi être entraînées. Des auteurs ont présenté à leurs participants un stimulus correspondant à un flash lumineux qui se répète régulièrement. Ils observent que les régions cérébrales impliquées pour traiter ce stimulus vont adapter leurs oscillations à la fréquence du flash et présenter de meilleurs résultats lorsque la fréquence du stimulus cible correspond à la fréquence du stimulus d’entraînement qu’en condition de non-congruence (Spaak et al., 2014). De la même manière, lorsque nous lisons, notre cerveau ne traite pas les mots écrits d’une manière constante mais plutôt en fonctions d’une succession de brefs pics d’activité neuronale (Cohen, 2015).
Un des déterminants essentiels à la lecture est la notion d’attention. En effet, il arrive qu’en lisant, on ne se souvienne plus instantanément de ce que nous venons de lire. Ces montées et descentes d’attention dans le temps suivent elles-aussi un cycle rythmique, on parlera alors de fluctuations attentionnelles (voir la partie « L’attention visuo-spatiale »). Des études ont montré qu’ une augmentation brusque de bande alpha se produit juste avant qu’un participant ne commette une erreur due à un écart d’attention (Cohen & Van Gaal, 2012). Ces observations semblent indiquer qu’il existe une forte corrélation entre les fluctuations attentionnelles et les oscillations d’activité neuronale dans le cortex visuel gauche pendant une tâche de lecture (Mathewson & al., 2011). En situation d’éveil, nos yeux sont en permanence en mouvement afin de collecter de nouvelles informations en provenance de notre environnement. Dans le cas de la lecture nous effectuons des saccades oculaires (voir partie suivante: « Les mouvements des yeux au cours de la lecture ») plusieurs fois par seconde en suivant, ici-encore, une rythmique répétitive. Des études ont pu montrer qu’il y avait une forte synchronisation entre les mouvements des yeux au cours de la lecture et les oscillations neuronales dans le cortex visuel (Pöppel, & Logothetis, 1986).Pour conclure, l’hypothèse qui nous servira de socle théorique pour interpréter les résultats de notre étude serait donc que l’activité fonctionnelle significative du cerveau (en l’occurrence pour une tâche de lecture de mot) serait directement sous tendue par les oscillations neuronales (Buzsaki, 2006; Arguin, 2018).
Les mouvements des yeux au cours de la lecture
Une des questions centrales pour appréhender le déploiement attentionnel au cours de la lecture est celle du contrôle oculomoteur. Ainsi, si nous sommes capables de lire, nous restons néanmoins inconscients des mouvements fins effectués par nos yeux afin de parvenir à récupérer rapidement et
efficacement l'information visuelle à partir d'un texte. De nombreuses études utilisant l’enregistrement oculaire (« Eye Tracking ») ont permis d'évaluer plus précisément la manière dont les mouvements oculaires permettent d'optimiser l'extraction d'informations visuelles à travers le temps. Cela, à l'aide d'un protocole qui laisse les stimuli inaltérés (ce qui présente l’avantage de ne pas interférer avec le processus de lecture normale). On constate alors que le regard ne suit pas une trajectoire rectiligne constante. En effet, il progresse au cours de la lecture par une succession de fixations et de saccades ainsi que par des saccades dites régressives (O'Regan, Lévy-Schoen, 1978). Lors des fixations, qui durent approximativement 200-250 ms (Rayner, 1998 ; Sereno et al., 1998 ; Sereno et al., 2000), l’œil est immobilisé sur un point du texte permettant un décodage très rapide du mot (Joseph et al., 2009 ; Quercia, 2010). C'est donc au cours de ces périodes que les opérations de saisie et de traitement de l'information visuelle vont être effectuées. Elles permettent également la préparation motrice de la prochaine saccade (Jacobs, et Lévy-Schoen, 1987). La fréquence à laquelle on estime les fixations oculaires est d’environ 3, 4 par seconde, alors que les fixations attentionnelles surviendraient à une fréquence d’environs 15-20 fixations par seconde (Wolfe, 1998). On parlera de « point de fixation initial » pour caractériser la position où le regard se pose sur un mot immédiatement après une saccade afin de le décoder rapidement. Rayner (1978) a été le premier à décrire un point de fixation initial moyen établit à partir des performances de lecteurs adultes neurotypiques. Ce point qu'il nomme PVL (Preferred Viewed Location) serait situé légèrement à gauche du centre du mot et tendrait à se rapprocher du centre à mesure que les mots présentés sont courts (McConkie et al. 1988). Les saccades, quant-à-elles, sont des mouvements balistiques extrêmement rapides d'une durée et d'une amplitude spatiale variables en fonction de la tâche et des individus (Joseph et al., 2009) ; l'amplitude moyenne d'une saccade au cours de la lecture étant de sept caractères (Quercia, 2010). Ces saccades seraient fortement influencées par la vision parafovéale du mot qui suit le mot-cible (Nazir, et al., 1998) et il est généralement admis que leur rôle est le déplacement du point focal du regard de manière à centrer
l'image d'intérêt sur la fovéa. Il n'y a donc pas d'acquisition de données écrites à proprement parler au cours des saccades (Chekaluk, et Llewellyn, 1990). De plus, on observe qu'outre les différences inter-individuelles, les saccades oculaires ainsi que les périodes de fixation sont affectées de manière différentielle par les spécificités de la tâche (Rayner, 1998). On observe également des saccades dont le mouvement est inversé (de la droite vers la gauche). Ces saccades dites « régressives » représenteraient 13 à 20% des saccades en moyenne pour une tâche standard de lecture de texte (Blythe et al., 1990). Elles sont également plus fréquentes pendant l’apprentissage de la lecture qu’à l'âge adulte. Ainsi, entre sept et vingt ans on remarque à mesure que la vitesse de lecture augmente, une diminution des temps de fixation, une augmentation de l’amplitude des saccades et une diminution de la fréquence des saccades régressives (Rayner, 1998. Joseph et al., 2009).
Les protocoles d'enregistrement oculaire ont également mis en évidence le fait que les mots monosyllabiques étaient appréhendés en une seule fixation alors que les mots de plus de deux syllabes en demandent deux ou plus (Rayner, 1998, Joseph, et al., 2009). Quoique cette méthode présente un intérêt indéniable, elle montre également des limites significatives. En effet, sa résolution temporelle est insuffisante pour révéler clairement la dynamique attentionnelle appliquée pour la reconnaissance d'un mot individuel. De plus, l'attention peut être orientée indépendamment des mouvements oculaires (Posner, 1980), ce qui implique la nécessité de coupler les résultats relatifs aux mouvements oculaires en lecture avec d'autres types de protocoles permettant un suivi des processus attentionnels au cours d'une même fixation oculaire.
Les modèles théoriques de la lecture
spatiale et temporelle de l'attention dans la lecture s’appuient sur des études qui infèrent l'ordre d’extraction des informations contenues dans les lettres à partir de l'analyse des temps de réaction et des scores de précision des participants (d'aprèsBlais et al, 2009). Les résultats de ces études s’avèrent peu contraignants sur le plan théorique et laissent ainsi place à de multiples interprétations et à des modèles explicatifs variés. Classiquement, on oppose deux grands concepts autour desquels les différentes théories vont s'articuler. Les modèles dits parallèles vont considérer que le traitement des lettres qui composent le mot est simultané. Par exemple, le modèle de traitement parallèle distribué (Parallel Distributed Processing) proposé parSeidenberg et McClelland (1989) qui consiste en l'interaction de trois ensembles de connaissances : l’orthographe, la phonologie et la sémantique. Ces ensembles sont constitués d'unités dont le pattern d'activation détermine la représentation du mot. L'hypothèse d'un traitement parallèle des indices visuels s’appuie principalement sur deux observations. Pour des mots allant de 3 à 7 lettres, on n'observe pas d'effet significatif de la longueur du mot sur la latencedes réponses correctes(Weekes, 1997 ; New, 2006). Ces résultatsont été répliqués de nombreuses fois dans la littérature et semblent consistants (voir Cohen et al, 2003 ; Fiset, Arguin, & McCabe, 2006). De plus, il a été montré que l'identification des lettres est faite avec une acuité accrue lorsque la lettre est incluse dans un mot plutôt que dans une séquence de lettres aléatoires (Cattell, 1886 ; Reicher, 1969). Cet effet de supériorité du mot par rapport aux non-mots ainsi que l'absence d'effet de longueur de mot sur les temps de réponse sont concordants avec ce type de modèle explicatif.
A l'opposé, des modèles purement sériels vont supposer que le traitement perceptif s'effectue de manière séquentielle. Une lettre après l'autre et de gauche à droite. C'est le cas du modèle SERIOL proposé parWhitney et Cornelissen (2008) qui propose une explication alternative à l'absence d'effet de longueur du mot. Le processus sériel d'extraction d'information pourrait ne pas entraîner un effet de longueur de mot sur les temps de réponses si l'augmentation de la longueur des mots avait aussi un effet facilitateur contrebalancé. C'est à dire qu'à mesure que les lettres sont traitées l'une après l'autre, le
nombre de possibilités incluses dans notre réserve lexicale diminue, ce qui cause une réduction des temps d’identification. Ainsi, sur la base de ces postulats, un traitement sériel pur, n'entraînant pas d'augmentation des temps de réponses dus à un effet de longueur du mot, s’avère autant en mesure d'expliquer les données empiriques considérées que les théories rivales supposant un traitement parallèle.
Cependant, de même que certains auteurs vont revenir sur cette conception stricte de la lecture sérielle (informations traitées de manière séquentielle et de gauche à droite), tous les modèles explicatifs ne se positionnent pas de manière exclusive en faveur du traitement sériel ou parallèle. D'autres, comme le modèle à deux voies de Coltheart et al. (2001), suggèrent ainsi la coexistence de ces deux processus, qui s'appliqueraient à des fins différentes. Ainsi, la voie par assemblage qui procède à la conversion des graphèmes en phonèmes, serait particulièrement exploitée lors de l'apprentissage de la lecture et, à l'âge adulte, pour déchiffrer des mots nouveaux ou moins courants. La voie par adressage qui fait la correspondance entre le lexique orthographique et la mémoire sémantique quant-à-elle, se rapprocherait plutôt d'une lecture parallèle, témoignant de l'expertise des lecteurs adultes pour reconnaître des configurations familières de lettres. De manière relativement majoritaire, on admet aujourd’hui l’existence de ces deux modes d’encodage de l’information écrite correspondant aux voies de lecture de Coltheart et collaborateur (2001), cependant, l’idée selon laquelle la voie de conversion graphème-phonème (CGP) correspondrait à un processus de lecture purement sérielle (de même que la voie lexicale correspondrait à un processus de prise d'information purement parallèle) reste très probablement inexacte. En effet, l’idée d'une lecture sérielle appuyée sur un processus de prise d’information sérielle de gauche à droite est contraire à la grande majorité des études qui s'appuient sur l'observation des mouvements oculaires (cf. point d'attention initiale, saccades oculaires, saccades régressives). Pourtant, la manière précise dont l'information est extraite à travers le temps reste encore largement à définir et peu prise en compte dans les différents modèles théoriques.
Le modèle MTM (Multiple Trace Memory) proposé par Ans, Carbonnel et Valdois en 1998 se présente comme opposé aux modèles à deux voies car il prône la présence d'une seule voie de lecture subdivisée en deux procédures, l'une analytique et l'autre globale. Ces deux procédures reposent sur un mode d'extraction d'information sériel (pas d'extraction en parallèle donc), la procédure globale n'intervenant que lorsque la procédure analytique s'avère inefficace. Les travaux de Juphard et ses collaborateurs en 2006 montrent qu'il existe un effet du nombre de syllabes sur la vitesse de lecture pour des mots allants de deux à quatre syllabes. De plus, ils observent en prononciation, un effet préférentiel pour les mots (vs non mots) qui disparaît lors d’une tâche de décision lexicale. Ces observations sont congruentes avec le modèle MTM en ce sens que la tâche de décision lexicale reposerait sur la procédure globale alors que la procédure analytique, plus tardive, s’appliquerait à la lecture de pseudo mots dans le cas d'une lecture à voix haute (impliquant un accès à la prononciation). Il est ainsi possible de considérer que la mise en place de la procédure globale va être effective lorsque des items fréquents sont présentés cependant que la procédure analytique se déclencherait pour traiter les items peu fréquents ; d’où l’effet de longueur de mot observé par Juphard et ses collaborateurs en 2006 (voir également Ferrand & New, 2003).
Ainsi, la plupart des modèles computationnels en psychologie cognitive s'appuient sur des fondements empiriques mais détachés des neurosciences en cela qu’ils se placent sur un plan théorique et formel, sans correspondance explicite avec les structures cérébrales impliquées. Le modèle LCD (pour Local Combinaison Detectors) imaginé par Dehaenne et collaborateur en 2005, tente de modéliser les informations en provenance de la neuropsychologie de la reconnaissance visuelle. Ce modèle a pour vocation de concilier les aspects cognitifs et les structures cérébrales, ainsi que les circuits neuronaux impliqués dans la reconnaissance visuelle de mots. L'hypothèse centrale concerne l'organisation hiérarchique des neurones du système visuel. Ceux-ci ont des champs récepteurs qui
croissent à mesure qu'on monte dans la hiérarchie et sont répartis en différents niveaux, chacun dépendant du niveau inférieur. Ainsi, les différents niveaux seraient capables de traiter des informations visuelles de plus en plus complexes, respectivement : les traits, les combinaisons de traits, les lettres particulières, les lettres abstraites (avec invariance pour la casse), les paires de lettres (ou bigrammes) et enfin les petits mots ou les morphèmes. L'étude en IRM fonctionnelle menée par Cohen, Dehaene, Vinckier, Jobert et Montavont en 2008, tend à confirmer ce mode d’organisation. Ces auteurs observent des seuils critiques de rotation du stimulus (environ 40°-50°), d'espacement des lettres (environs deux espaces) et de position des mots par rapport au point de fixation initial ; au-delà desquels les temps de réponse ralentissent significativement. Les temps de réponse augmentent alors de manière linéaire en fonction du nombre de lettres contenues dans le mot, ce qui suggère l’utilisation de la lecture sérielle (cf. effet de longueur de mot). L'imagerie montre qu'au-delà de ces seuils, les régions bilatérales du lobe pariétal postérieur s’activent, or il s'agit de régions qui sont reconnues comme étant impliquées dans l'orientation de l'attention visuelle (Biotti, Pisella et Vighetto, 2012). L’interprétation proposée est donc que la voie occipito-temporale (ou voie ventrale) sous-tende la lecture parallèle rapide alors que le processus de lecture lente, sérielle et attentive qui s'active lorsque le stimulus est "difficile" à lire, se ferait sous l'égide de la voie occipito-pariétale. La voie ventrale constitue un second réseau intervenant pour renforcer l'attention au niveau des lettres. Ainsi, pour ces auteurs, la région ventrale gauche, qui joue un rôle fondamental dans l'identification visuelle de mots, est organisée de manière partiellement hiérarchique permettant une reconnaissance spécifique pour les bigrammes plus fréquents dans la langue (en l'occurrence le français) qui progresse à mesure que l'on monte dans la hiérarchie. Sur le plan neuro-anatomique, la partie la plus antérieure de cette région occipito-temporale gauche serait effectivement sensible aux mots et aux chaînes de caractères qui respectent les régularités orthographiques de la langue (Vinckier, Dehaene, Jobert, Dubus, Sigman et Cohen, 2007).
Objectifs et hypothèses
L'objectif de la présente étude est de poursuivre l'investigation de la question examinée par Blais, Arguin et al (2009) en utilisant un échantillonnage spatial au niveau de la lettre plutôt que du pixel. En réduisant le nombre de points à échantillonner sur la dimension spatiale, l’échantillonnage appliqué au niveau de la lettre plutôt que du pixel devrait nous permettre d’effectuer des analyses statistiques ayant la puissance nécessaire pour déterminer s’il est effectivement possible d’effectuer un traitement parallèle de deux ou plusieurs lettres à l’intérieur d’une même fixation attentionnelle.
Compte tenu des résultats antérieurs de Blais et al., nous nous attendons à ce que les résultats démontrent un traitement sériel dans la reconnaissance de mots écrits où l’ordre dans lequel les lettres sont traitées est fonction de leur valeur diagnostique pour l’identification du mot. Ainsi, il est prévu que les résultats falsifient l’hypothèse généralement admise d’un traitement parallèle des lettres pour l’identification des mots, de même que l’hypothèse alternative d’un traitement sériel pur des lettres se faisant dans un ordre strict de gauche à droite.
Méthodologie
Participants
Un certificat d’éthique a été obtenu auprès du comité d'éthique de la recherche en Arts et Sciences (CERAS) autorisant la réalisation de la présente étude. Un groupe de 16 étudiants de l'université de Montréal a été testé. Ceux-ci sont âgés entre 18 et 35 ans, ont le français comme langue maternelle et un niveau d'études supérieur. Ils n'ont pas de trouble neurologique ou visuel (qui ne soit
pas corrigé) et ne présentent pas de difficulté avérée en lecture ni de retard d'apprentissage. Les informations concernant le sexe et la dominance manuelle des participants ont été prises en compte mais ne constituaient pas un critère de sélection.
L’âge moyen des participants est de 23,06 ans avec un écart type de 2,28. L’échantillon compte 10 femmes et 6 hommes, 12 droitiers et 4 gauchers. Le niveau d’études moyen est de 16,81 années (à partir de la première année du primaire) avec un écart type de 1,59.
Matériel
Une liste expérimentale de 600 mots et des listes de pratique de 225 mots ont été construites. Il s'agit de mots français de 5 lettres sans aucun signe diacritique. Les listes ont été construites à partir de la base de données Brulex. Les mots utilisés sont relativement fréquents (fréquence lexicale comprise entre 180 et 4000 occurrences par 10 millions) afin d'assurer un niveau minimal de familiarité. Les tâches informatiques ont été programmées à l'aide du logiciel MatLab et utilisent les fonctions de la Psychophysics Toolbox (Brainard, 1997). L'expérience est administrée à l'aide d'un ordinateur HP Compaq 6000 pro, les stimuli sont présentés sur un écran (Asus, VG248) de 1280*1024 pixels à un taux de rafraîchissement de 120 Hz. La distance des participants à l'écran est stabilisée à l'aide d'une mentonnière située à 57cm. Les mots étaient imprimés en noir (1 L) sur fond blanc (180 L).
Un stimulus est composé d’une séquence de 24 images ayant chacune une durée de 8.33 ms pour une durée totale de stimulation de 200 ms par essai. Ce stimulus consiste en un mot écrit en caractères minuscules noirs (1 lux) dactylographiés police Courier New présenté au centre de l'écran sur un fond blanc (180 lux) et combiné à un bruit blanc visuel. L'étendue spatiale de la lettre x (« x-size » : référent standard pour décrire la taille d’une police) était de 0,84 ° x 0,72 ° d’angle visuel (48
points). La fonction d'échantillonnage temporel est générée avec une valeur minimale de zéro et un maximum qui est ajusté selon les performances des participants. Le bruit qui sert de fond duquel le stimulus doit être discriminé correspond à une plage de points aléatoires; 50 % des points sont blancs, les autres sont noirs.
Le rapport signal/bruit varie aléatoirement pendant la présentation du stimulus et de manière indépendante pour chaque lettre. Ainsi, à certains moments les lettres sont facilement visibles alors qu’à d’autres elles sont fortement masquées. La limite supérieure du rapport signal/bruit est ajustée afin de maintenir la performance à 50 % de réponses correctes. Il est attendu que la durée maximale de la période de visibilité d’une lettre soit inférieure à 50 ms (ce qui, selon Wolfe, 1998 est insuffisant pour exécuter une saccade attentionnelle volontaire). En effet, la durée en question repose sur la fonction d’échantillonnage qui est constituée des fréquences de 5 Hz à 60Hz par paliers de 5 Hz. Il serait donc très improbable d’avoir une période soutenue de haute visibilité dont la durée soit supérieure à 50 m.
Procédure
La tâche expérimentale consistait à lire le mot présenté au centre de l'écran. Celui-ci était précédé d'une croix de fixation centrale d'une durée de 500 ms (intervalle inter-stimuli de 250 ms). Les mots constituant la liste décrite précédemment étaient présentés dans un ordre aléatoire. Immédiatement après la présentation du stimulus, les participants inscrivaient leur réponse au clavier de l’ordinateur. La touche « entrée » permettait de valider la réponse et de passer à l'essai suivant. Chaque participant a complété un total de 1200 essais expérimentaux en plus des 150 + 75 essais de pratique, ce qui correspondait à une durée de 90 à 120 minutes par participant.
Les propriétés temporelles de la stimulation à chaque essai ont été codées soit comme le RSB brut, soit d’après les caractéristiques de Fourier (amplitude et phase de chaque fréquence constitutive ; 5 à 55 Hz par pas de 5Hz) du RSB, ou comme le résultat d’une analyse temps-fréquence du RSB.
Dans le cas des analyses temps-fréquence, le profil temporel signal/bruit associé à chaque essai est soumis à une analyse temps-fréquence. Ainsi, la durée de stimulation de 200 ms a été segmentée en séries de fenêtres temporelles de Hamming avec un degré de chevauchement de 50 % entre fenêtres consécutives. Le nombre de ces fenêtres varie en fonction de la fréquence temporelle analysée (ici également, de 5 à 55 Hz par pas de 5 Hz). La règle appliquée à cette fin est la suivante : l'étendue de la fenêtre va chercher à maximiser le nombre de cycles de la fréquence temporelle analysée pouvant y tenir, jusqu'à un maximum de quatre cycles complets. Une fois cette segmentation complétée, une analyse de Fourier a été appliquée sur le contenu de chaque fenêtre.
Des images de classification reposant sur ces différentes propriétés ont ensuite été construites pour chaque participant et chaque position de lettre. Celles-ci sont construites en soustrayant la somme pondérée des propriétés temporelles correspondant aux essais erronée de celle des essais réussis. Ces images de classification ont par la suite été transformées en scores Z par bootsrap (1000 itérations) afin d'avoir tous les participants sur une même échelle et pouvoir ainsi construire des images moyennées à
travers les participants (Arguin, M., 2018). Enfin, le test Pixel (α = .05) a été appliqué aux données pour déterminer le critère de significativité de ces résultats (Chauvin et al., 2005). Ce test va nous permettre de déterminer les valeurs significativement différentes de 0 et d'identifier des plateaux de scores Z semblables (non-significativement différents entre eux) dans nos images de classification. L'amplitude des valeurs constituant les images de classification nous renseignent sur l’efficacité du participant à traiter l'information visuelle disponible.
Enfin, nous avons conduit des analyses de conjonction dans les domaines temporel et temps-fréquence pour toutes les combinaisons possibles de lettres afin de déterminer si la disponibilité simultanée de deux ou plusieurs de ces lettres avait un effet significatif sur l’efficacité du traitement visuel réalisé par le participant.
Une analyse de cohérence inter-sujet a également été faite pour les images de classification dans les domaines temporel et temps-fréquence. Pour chaque type d’images de classification et chaque position de lettre, une matrice des corrélations incluant toutes les paires possibles de participants a été construite. La valeur de cohérence inter-sujet retenue est constituée de la moyenne des corrélations présentes dans cette matrice. L’objectif de cette analyse était de déterminer dans quelle mesure les caractéristiques du traitement visuel reflétées par ces images de classification étaient partagées à travers les participants.
Les figures présentées dans la section Résultats ont été construites de manière à y intégrer les résultats des analyses statistiques. Ainsi, lorsque les points adjacents sur les images de classification avaient des valeurs significativement différentes l’une de l’autre, ces valeurs distinctes sont illustrées sur les figures. Par contre, lorsque sept points adjacents avaient des valeurs qui n’étaient pas significativement différentes l’une de l’autre, les valeurs illustrées sur les figures en sont la moyenne. Autrement dit, toutes les variations apparaissant sur les graphiques sont significatives.
L'interprétation des résultats a été faite sur la base de l’amplitude numérique des scores obtenus sans accorder de statut particulier pour la valeur de zéro ; donc sans considérer les valeurs positives comme reflétant une facilitation ou les valeurs négatives comme reflétant une inhibition.
Résultats Domaine temporel
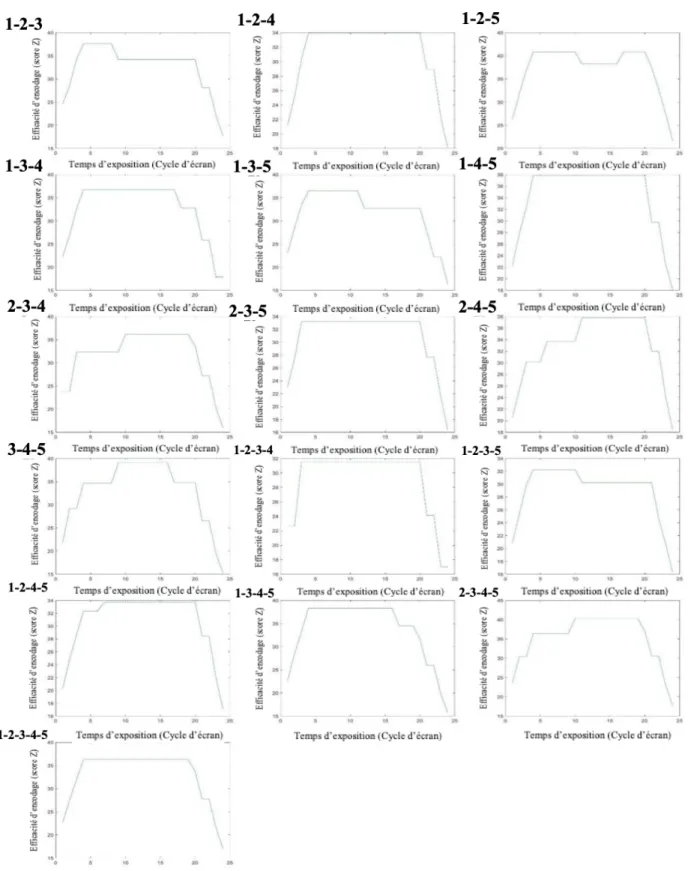
Pour l’ensemble des images de classification construites dans le domaine temporel l'efficacité de traitement augmente progressivement au début de la présentation pour diminuer progressivement à la fin. Les variations observées entre ces deux extrêmes expriment les variations de la capacité d'encodage visuel des participants (exprimée en score Z) à travers les 200 ms d’exposition au stimulus. Ces résultats ont été calculés en faisant la moyenne de tous les participants pour chaque position de lettre (référés par les chiffres de 1 à 5, correspondant à la position de la lettre en commençant par la gauche et terminant par la droite). La ligne bleue correspond au critère de signification pour la différence par rapport à 0 obtenu à l’aide du test Pixel. Il est important de noter que l’étendue couverte par l’axe vertical varie à travers les positions de lettres.
Figure 2 : Images de classification moyennes dans le domaine temporel pour chaque position de lettre
L’axe vertical correspond à l’efficacité d’encodage (en score Z) et l’axe horizontal au temps d’exposition (en cycle d’écran). Les chiffres qui précèdent les graphiques réfèrent aux positions de
lettres traitées (numérotées de 1 à 5, de gauche à droite). L’étendue représentée par l’axe vertical des graphiques n’est pas toujours la même.
Les profils temporels moyens pour chaque position de lettre (Figure 2) montrent des variations significatives à travers le temps d’exposition au stimulus. Ces variations sont rapides et d’amplitude importante. De plus, les patterns moyens obtenus présentent des différences conséquentes en fonction de la position de lettre traitée. On observe ainsi, pour les positions de lettres 1, 2 et 3, un pic d’efficacité d’encodage localisé respectivement entre les cycles d’écran 6 et 14 (soit entre 50 et 117 ms) ; 6 et 14 ; 14 et 19 (117 et 160 ms) soit dans la première moitié de la présentation pour les lettres 1 et 2 et dans la seconde moitié pour la lettre 3. Au contraire, les positions de lettres 4 et 5 indiquent chacune deux périodes distinctes (ou deux pics) d’efficacité maximale de traitement. Pour la quatrième lettre, Ces pics sont situés entre les cycles d’écran 3 et 11 (25 et 91 ms) ainsi que 20 et 22 (166 et 183 ms), soit à des périodes particulièrement précoces et tardives de l’exposition du stimulus. Pour la cinquième lettre, ces maximums sont atteints aux cycles d’écran 2 et 4 (17 et 33 ms) ainsi que 16 et 19 (133 et 158 ms). On remarquera également que les variations d’efficacité d’encodage paraissent moins marquées sur cette cinquième position de lettre que sur les graphiques correspondants aux autres positions.
Les indices de corrélation inter-individuelles sont de .01 pour la lettre 1, -.01 pour la lettre 2, .05 pour la lettre 3, -.02 pour la lettre 4 et -.02 pour la lettre 5. À travers les différentes positions de lettres, l’indice de cohérence moyen est de .01 (Annexe II).
Analyses temps-fréquence
figure 3. On observe ici, dans une mesure nettement supérieure à ce qui a été constaté dans le domaine temporel, des variations substantielles de l’activité fonctionnelle au cours du temps ainsi que l’émergence de patterns représentatifs et spécifiques à chaque position de lettre.
Figure 3 : Images de classification temps-fréquence moyennes pour chaque position de lettre
L’axe vertical de chaque graphique correspond à la fréquence d’oscillation du stimulus et l’axe horizontal à la période d’exposition (exprimée à travers des fenêtres temporelles, en ms). L’efficacité d’encodage est illustrée par le code couleur en légende, sur la droite de chaque graphique. Il est à noter que l’étendue des valeurs reflétées par ce code de couleur n’est pas identique pour tous les graphiques. Les données ont été moyennés entre les participants pour chaque position de lettre et lissées en plateaux tel que décrit précédemment.
La cohérence inter-sujet est particulièrement robuste dans le domaine temps-fréquence, avec des indices de de .79 pour la lettre 1, .84 pour la lettre 2, .78 pour la lettre 3, .90 pour la lettre 4 et .87 pour la lettre 5. À travers les différentes positions de lettres, l’indice de cohérence moyen est de .84 (Annexe II). Cela semble indiquer que nos résultats parviennent effectivement à capturer des propriétés fondamentales qui sont applicables d’un individu à l’autre de l’évolution du processus de traitement visuel à l’intérieur d’une même période de fixation oculaire.
L’examen des images de classifications moyennes pour chaque position de lettre dans le domaine temps-fréquence (Figure 3) révèle une faiblesse relative des scores Z filtrés pour les positions de lettre 1 et 3, comparativement aux positions 2,4 et 5. On observe un creux conséquent d’efficacité d’encodage sur une large bande de fréquences en début de présentation pour la première lettre. Ce creux atteint ses valeurs minimales entre 0 et 100 ms à des fréquences situées entre 20 et 55Hz. Cette première position de lettre présente également un second creux d’efficacité vers la fin de la durée d’exposition (entre 132 et 200 ms) qui se concentre particulièrement sur les hautes fréquences temporelles (entre 45 et 55Hz). On remarquera également un léger pic, pour des fréquences aux alentours de 35 Hz entre 67 et 133 ms et pour des fréquences entre 40 et 55 Hz vers 100-167 ms. Un profil comparable émerge pour la troisième lettre, mais avec des fluctuations moins importantes de
l’efficacité d’encodage (i.e. les creux et les pics d’efficacité d’encodage apparaissent aux mêmes moments et pour les mêmes bandes de fréquences mais de manière plus atténuée).
La seconde position de lettre indique un pic d’efficacité constant tout au long de la présentation pour la bande de fréquences de 15 à 25 Hz. Celui-ci est accompagné de deux pics ponctuels situés à de hautes fréquences (45-55Hz) : entre 33 et 100 ms et entre 100 et 167 ms, de manière plus atténuée. On constate aussi deux creux marqués sur le plan de l’efficacité de traitement entre 0 et 133 ms pour des fréquences allant de 30 à 55 Hz. Le profil de la lettre 4 s’apparente dans une certaine mesure à celui de la lettre 2, mais avec des variations moins marquées. Notamment pour la bande de fréquences 10-25 Hz, où l’efficacité d’encodage est nettement moindre sur l’ensemble de la durée d’exposition. Cependant, des pics particulièrement marqués apparaissent entre 25 et 35 Hz aux étapes les plus précoces et sur une plus large bande de fréquences (25-45 Hz) aux étapes les plus tardives. Enfin, la lettre 5 présente des niveaux d’efficacité de traitement globalement plus faibles que pour les lettres 2 et 4. Ceux-ci sont caractérisées par des creux conséquents entre 10 et 15 Hz tout au long de la durée d’exposition de la cible et entre 40 et 55 Hz de 33 ms jusqu’à la fin. Les pics maximaux d’efficacité d’encodage pour la lettre 5 se retrouvent aux étapes les plus précoces (bande de fréquence : 35-50 Hz) et tardives (bande de fréquence : 20-30 Hz) de la durée d’exposition.
Analyses phase-amplitude
Les images de classification phase x amplitude ont toutes échoué à démontrer un quelconque effet significatif sur l’efficacité de l’encodage visuel dans la réalisation de la tâche de lecture. En effet, les images de classification ressortant de ces analyses se sont toutes avérées parfaitement uniformes (voir Annexe III).
Analyses de conjonction
Des analyses de conjonction ont été conduites afin de déterminer si la disponibilité simultanée à l’écran de deux ou plusieurs lettres avait une incidence sur les performances. On observe d’importants effets de la disponibilité conjointe de plusieurs lettres sur l’efficacité de traitement du stimulus qui varie de manière significative à travers la durée d’exposition du stimulus (Figure 4 et 5). De telles observations révèlent une capacité de traitement des conjonctions de lettres ; autrement dit, une capacité de traitement parallèle pour les combinaisons de lettres considérées. Les fluctuations de ces fonctions à travers la durée d’exposition du stimulus indiquent de quelle manière cette capacité de traitement des conjonctions varie à travers le temps. La variable utilisée pour ces analyses est le degré de visibilité conjointe de deux ou plusieurs lettres dont on examine la conjonction. Celle-ci est calculée à l’aide de la formule suivante: (SNR1 * SNR2 * SNRn)^(1/n) où SNR correspond au rapport signal/bruit et 1, 2, n spécifie les lettres dont on examine la conjonction, n étant le nombre de lettres considérées.
Figure 4 : Images de classification temporelles moyennes pour toutes les paires de lettres possibles
Les chiffres qui précèdent les graphiques réfèrent aux positions de lettres traitées conjointement (numérotées de 1 à 5, de gauche à droite). L’étendue représentée par l’axe vertical des
graphiques n’est pas toujours la même.
On observe d’importantes variations de la capacité d’encodage de plusieurs lettres conjointes à travers le temps et ce, pour l’intégralité des combinaisons de lettres (Figures 4 et 5). Ces observations semblent indiquer que le traitement de l’information visuelle bénéficie de la présence conjointe de deux ou plusieurs lettres afin de maximiser son efficacité. De plus, cette capacité n’est pas limitée aux lettres qui sont voisines ni aux conjonctions d’un petit nombre de lettres ; des périodes de haute efficacité sont également évidentes même pour des conjonctions de quatre ou cinq lettres.
Figure 5 : Images de classification temporelles moyennes pour toutes les configurations de plus de 2 lettres
On observe sur l’ensemble des graphiques (Figure 4 et 5) que pratiquement toutes ces fonctions temporelles pour les conjonctions suivent un rythme qui semble relativement similaire partout. Cela quelque soient les localisations de lettres ou le nombre de lettres dans la conjonction. Ainsi, l’efficacité est plus basse au tout début de la présentation, puis augmente très rapidement, demeure à peu près stable jusqu’aux étapes les plus tardives de la présentation, moment auquel il y a une chute dans l’efficacité.
Des analyses de cohérence inter-sujet ont été menées afin de déterminer si les patterns observés semblaient représentatifs de la population des normolecteurs. Toutes les paires de sujets ont été testées (voir annexe II). Les indices de corrélations moyens à travers les différentes positions de lettres sont de .01 dans le domaine temporel et de .84 dans le domaine temps-fréquence.
Les analyses de conjonctions ont également été effectuées dans le domaine de la puissance de Fourier (Figure 6). Ici aussi, les courbes ont essentiellement toutes la même forme. Les niveaux d’efficacité les plus bas sont retrouvés aux fréquences les plus basses et augmentent avec la fréquence jusqu’à un plateau qui peut débuter dés 30 Hz et qui se termine au plus tard à 50 Hz. Pour certaines conjonctions, le plateau couvre toute cette étendue. Plus communément, l’étendue retrouvée est entre 35 et 45 hertz inclusivement.
Figure 6 : Images de classification moyennes pour toutes les combinaisons de lettres dans le domaine de la puissance de Fourier
L’axe vertical correspondà l’efficacité d’encodage (en score Z) et l’axe horizontal aux fréquences (en Hz).
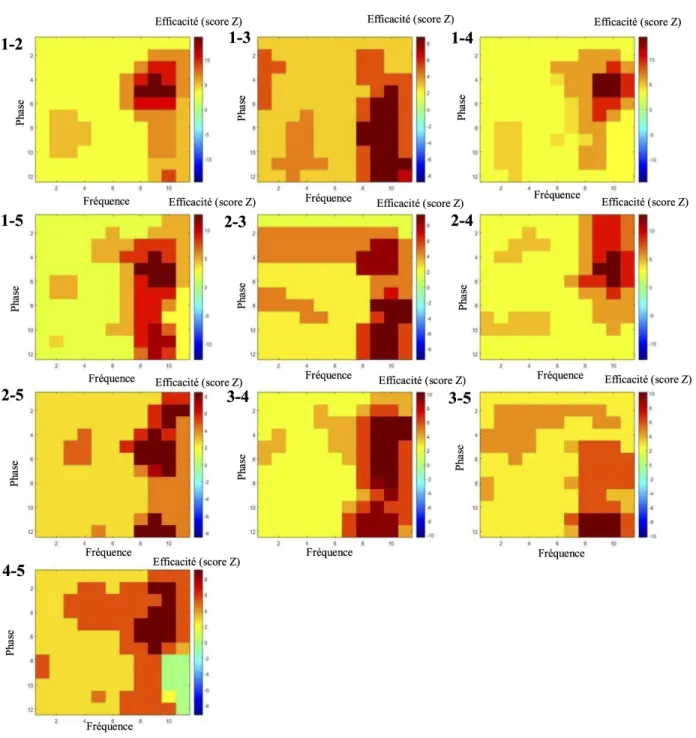
Figure 7 : Analyses de conjonctions phase-amplitude moyennes pour toutes les paires de lettres
L’axe vertical correspond à la phase (12 niveaux), l’axe horizontal correspond à la fréquence (11 niveaux) et le code couleur correspond à l’efficacité d’encodage (en score Z). Une valeur de phase de 1 correspond au début d'un cycle et une valeur de 12 correspond à sa fin. À l'intérieur d'un cycle, l'amplitude maximale du signal est atteinte à une valeur de phase de 4 alors que le minimum est atteint à une valeur de phase de 10.
Figure 8 : Analyses de conjonctions phase-amplitude moyennes pour toutes les combinaisons de plus de deux lettres
Il est possible de dégager quatre groupes présentant des patterns d’activité similaires ainsi que différents sous-groupes de ces analyses :
Groupe 1 : Une constante qui est partagée par toutes les images de classification, quelque soit la localisation ou le nombre de lettres concernées, est un niveau d’efficacité très élevée (en général le pic le plus élevé sur l’image de classification) aux fréquences de 45-50 Hz et aux phases 4 et 5. Parfois, ce sommet déborde un peu vers des fréquences légèrement inférieures ou supérieures. L’étalement de ce sommet à travers les phrases est généralement très étendu.
Pour plusieurs de ces images de classification (conjonctions de : 1-3, 1-5, 2-4, 2-5, 1-2-3, 1-3-4, 2-4-5) on retrouve également deux pics qui se situent dans les basses fréquences (5-25 Hz) et qui sont généralement décalés les uns par rapport aux autres en termes de fréquences et présentent un décalage plus important sur le plan de la phase. En général, le pic présentant la phase la plus basse se situe autour de 3-4 mais parfois peut aller aussi haut que 6. Le pic présentant la phase la plus élevée se retrouve habituellement autour des phases 8-10.
Pour d’autres images de classification (conjonctions de : 1-2, 1-4, 3-4, 4-5, 1-2-4, 2-3-5, 3-4-5, 2-3-4-5), on ne retrouve qu’un seul de ces deux pics de basse fréquence.
Groupe 2 : ce qui distingue ces images de classification de celles du Groupe 1 est l’extension du pic 45-50Hz, phases 4-5, en direction des fréquences les plus basses (jusqu’à 5-10 Hz) tout en maintenant une valeur à peu près constante pour la phase (conjonctions de : 2-3, 3-5) ou sinon qui a tendance à descendre en phase à mesure qu’on descend en fréquence (conjonctions de 2-5, 3-4, 1-2-3-5, 1-2-4-5, 2-3-4-5).
Groupe 3 : Correspond à peu près au groupe 1 sauf qu’on identifie 3 pics dans les régions de basse fréquence (5-25 Hz) ; (conjonctions de : 1-3-5, 1-3-4-5).
complètement uniforme en dehors du sommet de haute fréquence (45-50Hz).
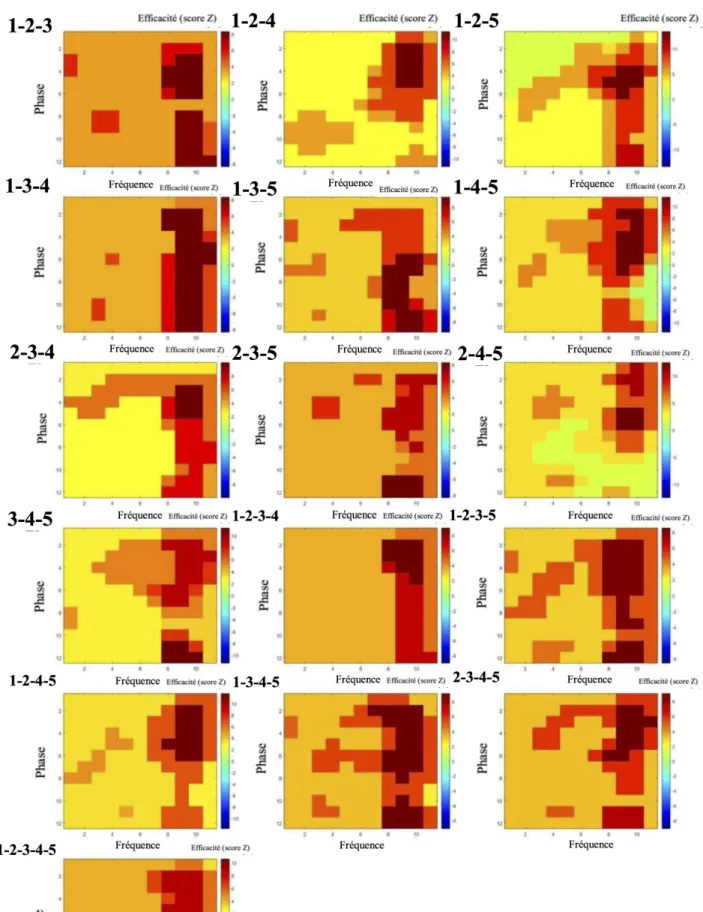
Figure 10 : Analyses de conjonction temps-fréquence moyennes pour toutes les configurations de plus de 2 lettres
Les analyses de conjonction temps-fréquence ont pour objectif de mettre en évidence l'efficacité du traitement conjoint de deux ou plusieurs lettres en fonction des fréquences d'oscillation pour la reconnaissance correcte du mot présenté. Comme dans les analyses temps-fréquence précédentes, l’axe vertical des deux graphiques présentés ci-dessus correspond à la fréquence d’oscillation du stimulus et l’axe horizontal à la période d’exposition (exprimée à travers des fenêtres temporelles, en ms). L’efficacité d’encodage de combinaisons de lettres est illustrée par le code couleur en légende, sur la droite de chaque graphique. Il est à noter que l’étendue des valeurs reflétées par ce code de couleur n’est pas identique pour tous les graphiques. Les données ont été moyennées entre les participants pour chaque combinaison de lettres et lissées en plateaux tel que décrit précédemment.
Les niveaux d’efficacité observés à partir des analyses de conjonction dans le domaine temps-fréquence sont particulièrement élevés tout au long du temps de présentation du stimulus. De plus, la localisation des sommets les plus hauts pour chaque image de classification s'avèrent particulièrement dispersée. Pour ces raisons, nous ne sommes pas parvenus à dégager de tendance systématique de l’ensemble de ces images de classification.
Discussion
Images de classification des profils d'échantillonnage
Les indices de corrélations des profils temporels individuels des participants sont plutôt bas, avec un indice de cohérence inter-sujets de .01 (annexe II. Cette observation suggère que le déroulement de l’encodage visuel à travers le temps reflété par ces images de classification n’est pas très largement partagé à travers les participants.