Fine-grained multilayer virtualized systems analysis
Texte intégral
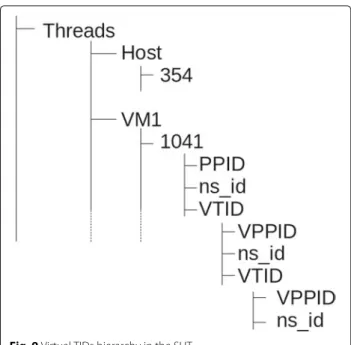
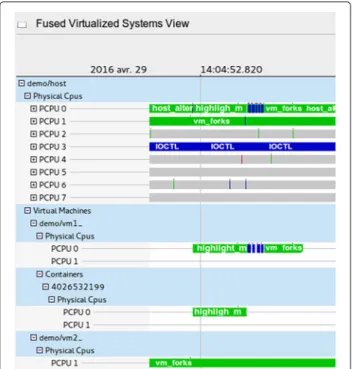
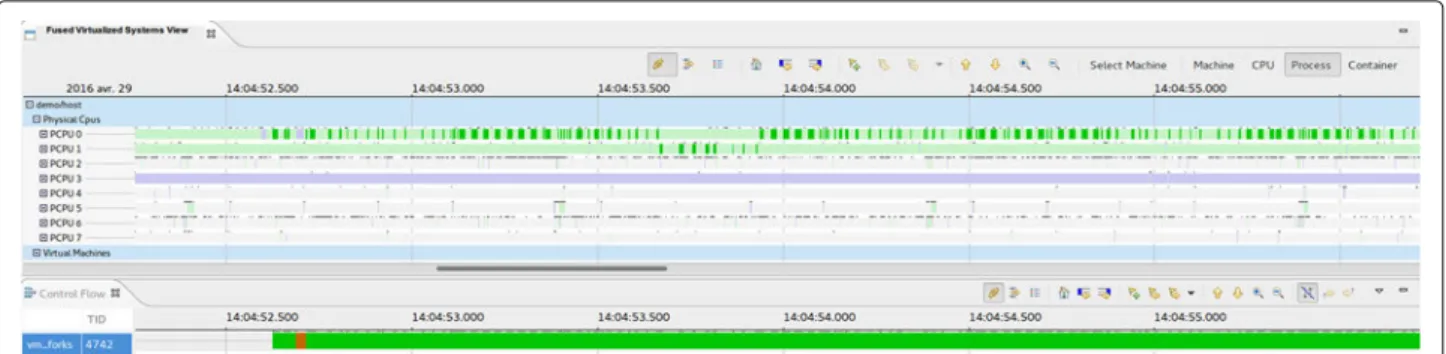
Figure
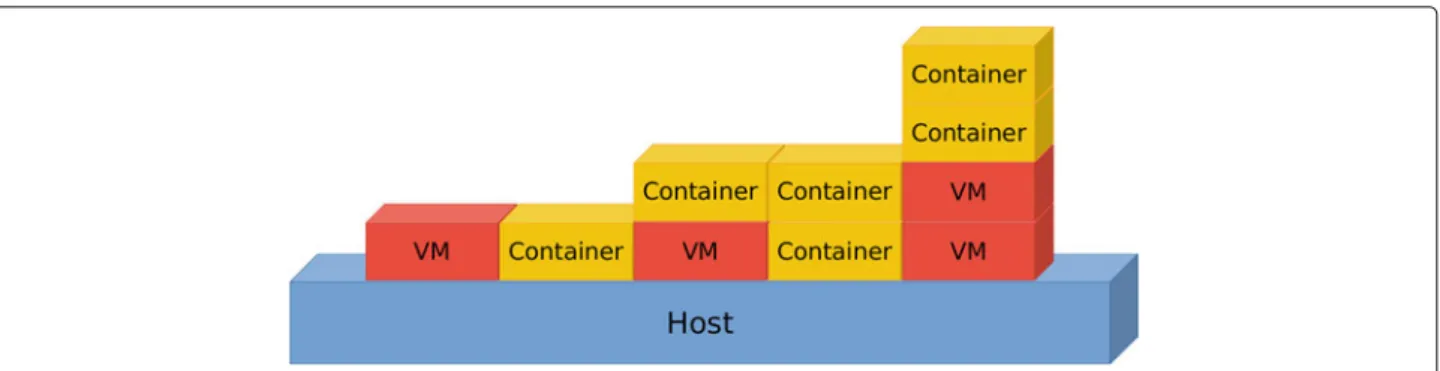
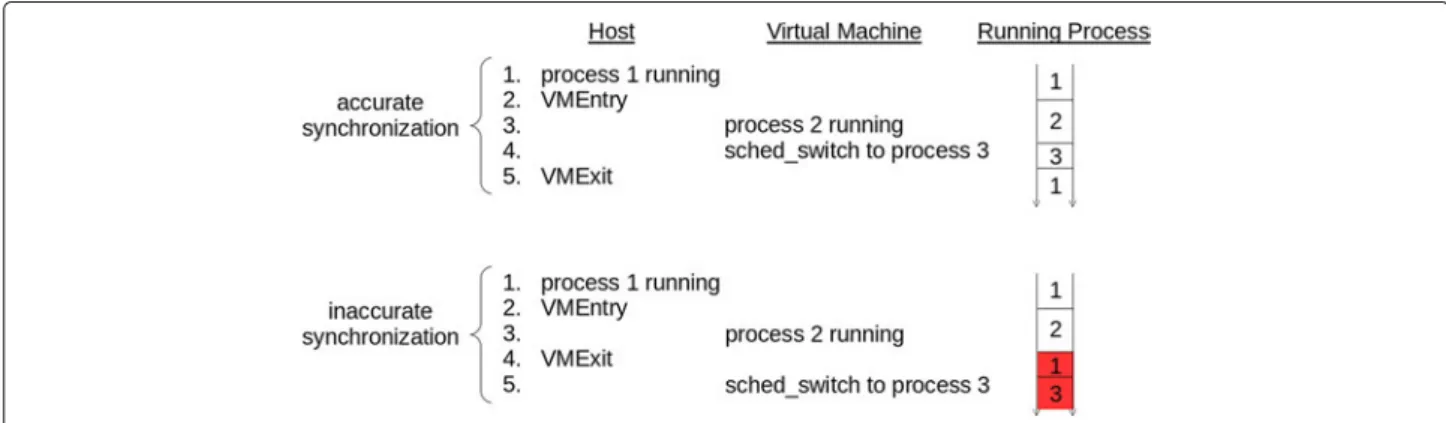
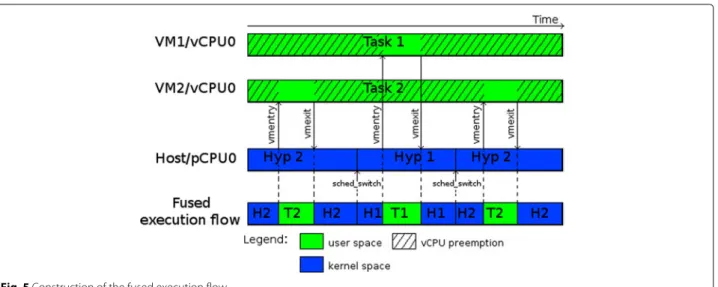
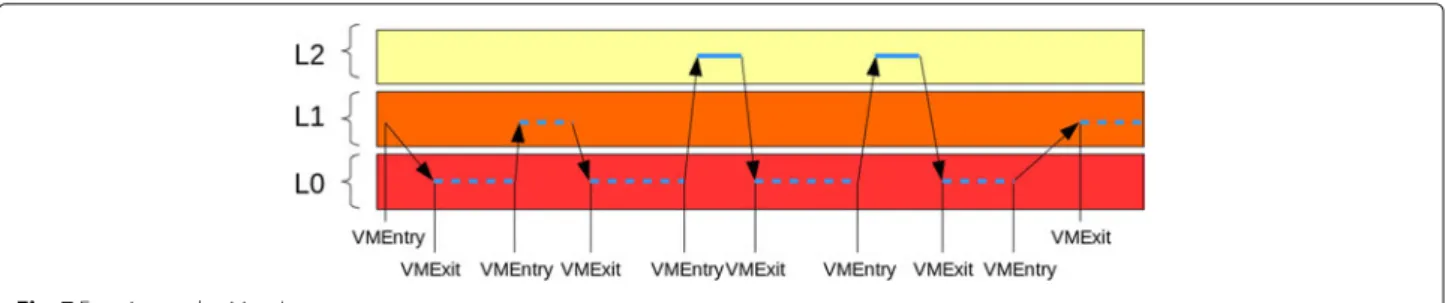



Documents relatifs
Change in the volume fraction of each layer contributing to the composite elastic modulus, according to the modified Korsunsky and Constantinescu model, as a function of
The shaping of connectivity is performed by a specific component called Network Shaper that filters packets between VMs applying drop rates and delays according to the
For a small cloud server cluster (for example, L < 50), increasing the number of user will increase rapidly the response time of request. But for a large cloud server cluster
The estimates given by Section 5.1 tell us that the microscopic stochastic process behaves as its deterministic approximation on compact time intervals, and we prove in Proposition
The contributions are (i) a new notion called loose-ordering, allowing to remove the sources of over-constraints due to the order of interactions between components in a TL model;
We advocate for an approach where the learning process and the creation process are managed sepa- rately and independently of each other, i.e.: (1) a LOs
In this Thesis, we mainly consider on Mandatory Information Flow Control at system level and see it not only as a standalone security mechanism but also as a way to configure
A transition metal that is useful in initial studies involving multidentate amido ligands is titanium since the resulting complexes are, in general, readily
