Filtre de Kalman discret pour l'estimation des moyennes inconnues de bruits blancs
90
0
0
Texte intégral
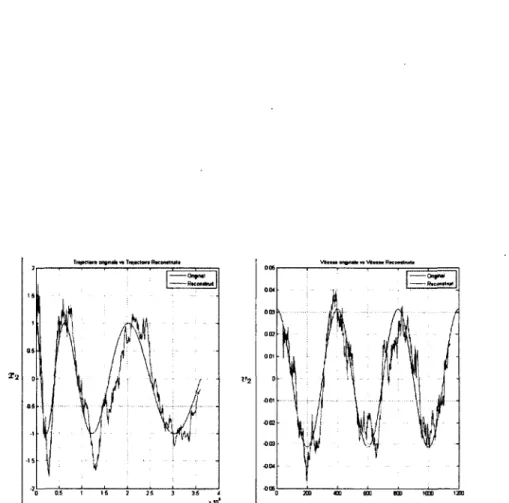
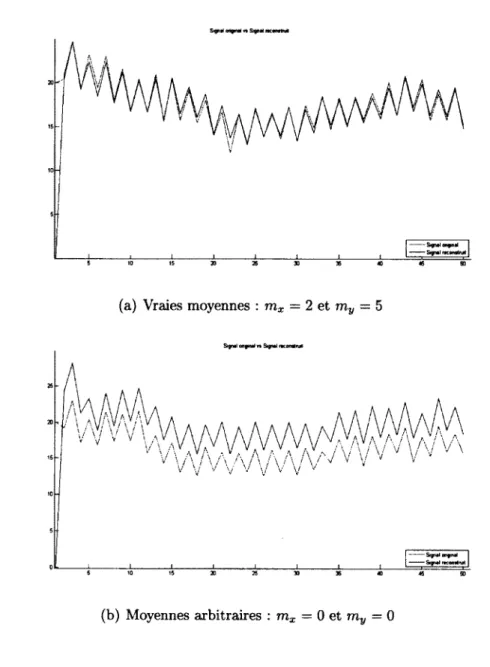
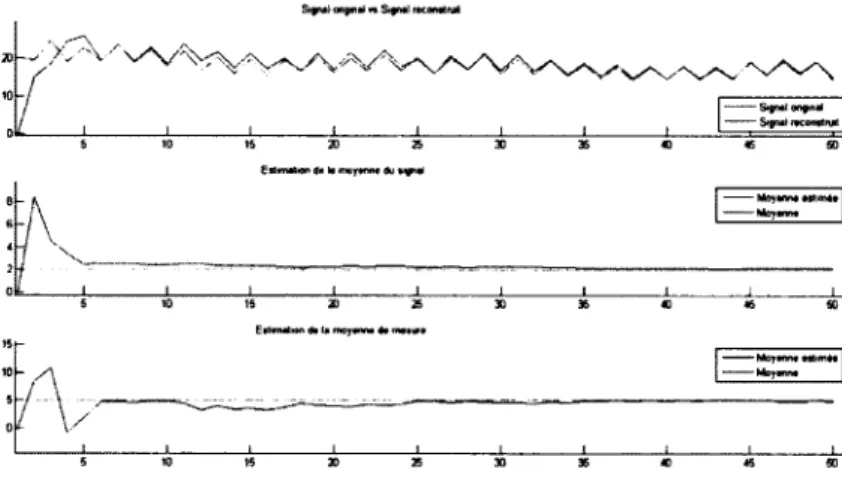
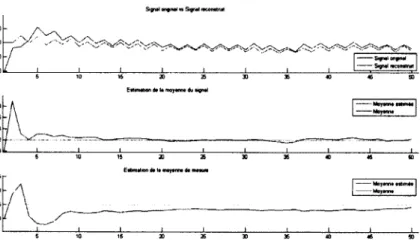
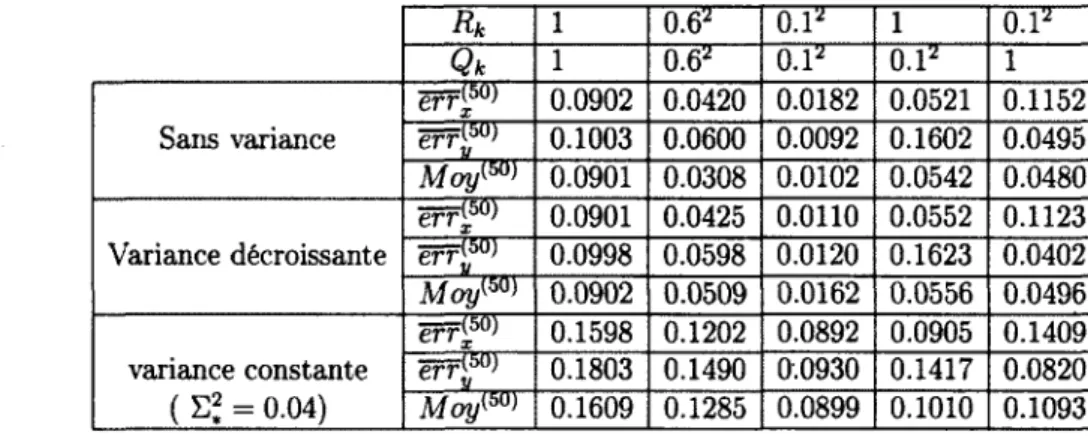
Figure

+7
Documents relatifs