“Brutification” et instauration des données. La fabrique attentionnée de l’open data
Texte intégral
Figure
Documents relatifs
« D’abord, le fait considérable de l’universalité du langage : « Tous les hommes parlent » ; c’est là un critère d’humanité à côté de l’outil,
Une Grandeur physique est mesurée par un nombre concret, ce nombre doit toujours être suivi d'une unité sans quoi il ne signifie rien.. Une grandeur physique
Si l’on compte précisément le temps que met la Terre pour faire un tour complet autour du Soleil, on trouve un peu plus d’une année : 365 jours et six heures. Pour tenir compte de
[r]
lire/écrire graduation comparer décomposer encadrer Fraction décimale. Les fractions
[r]
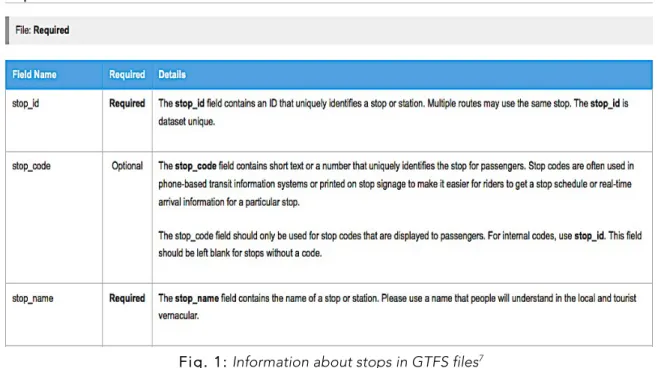
Alors que la rhétorique de l’open data met souvent l’accent sur « la libération » de données préexistantes du secteur public pour alimenter l’innovation et l’extraction
Il n’est pas inintéressant de considérer de ce point de vue les deux valeurs d’opinion telles qu’elles sont actualisées dans le sondage d’opinion d’une part et la
