Algorithms for openings of binary and label images with rectangular structuring elements
Texte intégral
Figure

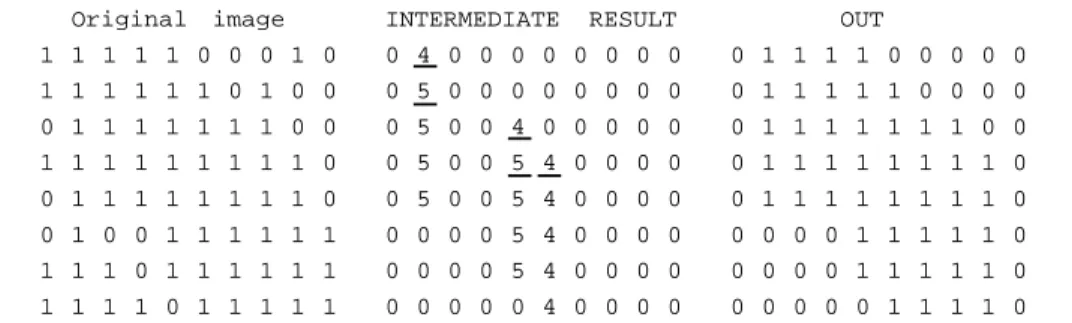


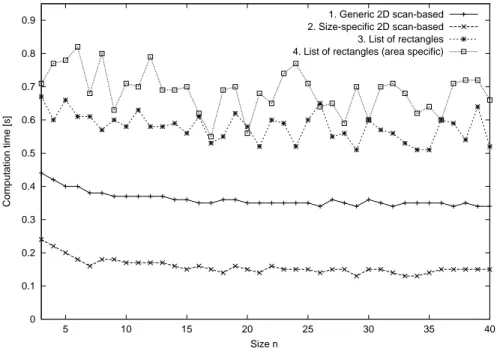
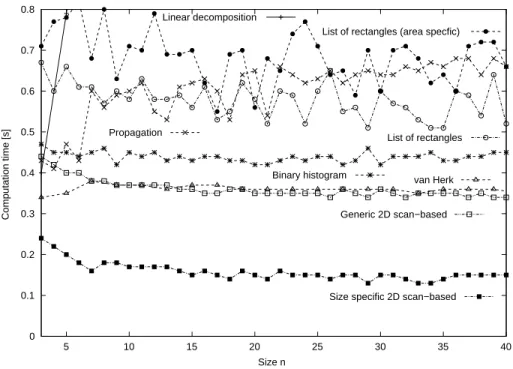
Documents relatifs
Table 6 shows the performances of each method in synthesizing the most frequent actual triplets. The total of pixels they represent amounts to 23 percent of the total number
To understand the mechanisms of breakdown of food matrices and their constituents in the gut and identify the beneficial/deleterious food components released during digestion..
Indeed, it classifies the content of a given audiovisual segment with respect to its potential contexts of uses (such as in formal or informal learning situations), to its
Finally, the non-parametric and the GARCH based variations of our proposed integrated algorithm are applied on real YouTube video content views time series, to illustrate
Furthermore, from the order structure that characterizes wavelet packet bases, we derive two different semantic templates for supporting a high level texture description: (1)
La répartition spatiale des dépôts évaporitiques du bassin de Guelma montre que les dépôts de sel gemme occupent la partie profonde du bassin, alors que
Le but de notre travail est l’étude de la convection naturelle à double diffusion afin d’étudier, d'observer de déterminer l’influence de la variation d’un
L’objectif principal de cette thèse sera donc, à partir des travaux de cartographie et de reconnaissances géologiques menés dans les régions du Pinacate et du Sonora central, de
