Échantillonnage compressé et réduction de dimension pour l'apprentissage non supervisé
Texte intégral
Figure

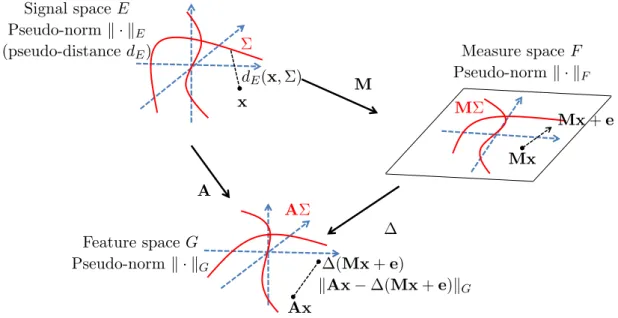


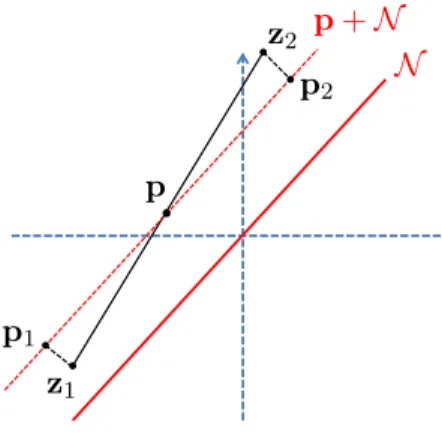

Documents relatifs
Aware of the grave consequences of substance abuse, the United Nations system, including the World Health Organization, has been deeply involved in many aspects of prevention,
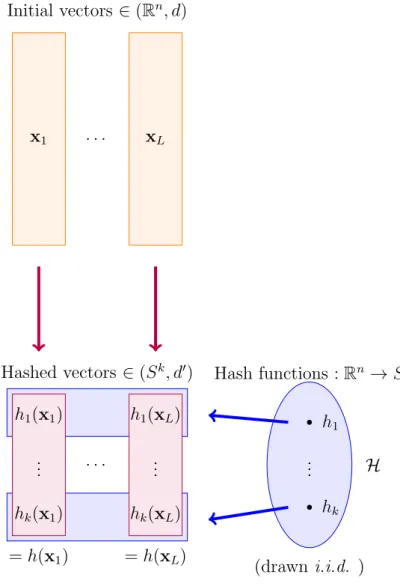
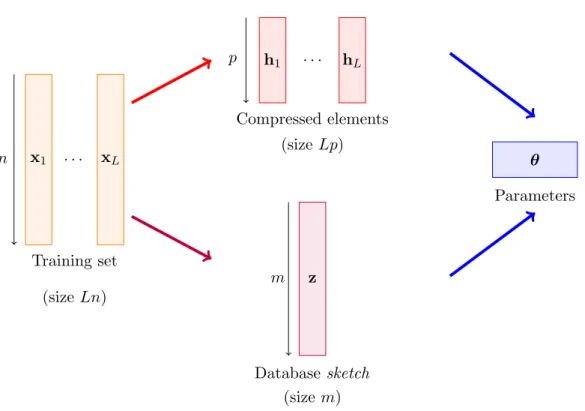
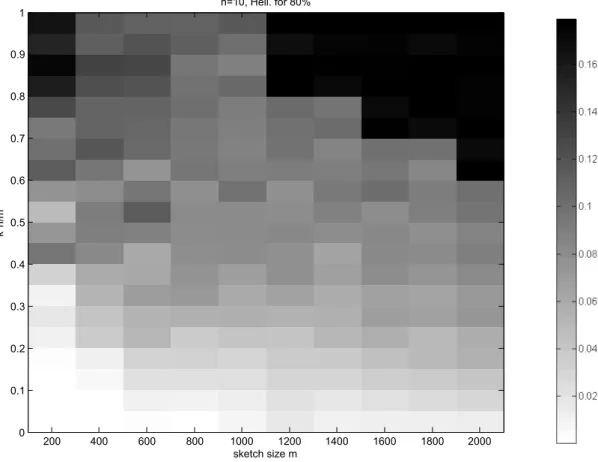
Puisque les divergences de Bregman englobent un large éventail de mesures de distorsion, en dimension finie ou infinie, et que l’algorithme des k-means s’étend à ces divergences,
The good part of this proceeding is that it preserves the continuity of the text. You are reading the original work, as it was graphically composed by its author, exactly as if you
The present research program proposes to investigate the possibility of explicitly discovering and learning unknown invariant transformations, as a way to go beyond the limits
This definition of the loss implicitly implies that the calibration of the model is very similar to the task of the market maker in the Kyle model: whereas in the latter the job of
• utilisation : pour une entrée X (de  d ), chaque neurone k de la carte calcule sa sortie = d(W k ,X), et on associe alors X au neurone « gagnant » qui est celui de sortie la
Our main contribution is a multiscale approach for solving the unconstrained convex minimization problem introduced in [AHA98], and thus to solve L 2 optimal transport.. Let us
In this paper, we provide separation results for the computational hierarchy of a large class of algebraic “one-more” computational problems (e.g. the one-more discrete
