To cite this document:
Roussouly, Nicolas and Petitjean, Frank and Salaün, Michel and
Buffe, Fabrice and Carpine , Anne Application des surfaces de réponse pour l’analyse
fiabiliste d’une structure spatiale. (2010) In: JFMS10 - Journées Fiabilité des Matériaux
et des Structures, 24-26 Mar 2010, Toulouse, France.
O
pen
A
rchive
T
oulouse
A
rchive
O
uverte (
OATAO
)
OATAO is an open access repository that collects the work of Toulouse researchers and
makes it freely available over the web where possible.
This is an author-deposited version published in:
http://oatao.univ-toulouse.fr/
Eprints ID: 9179
Any correspondence concerning this service should be sent to the repository
administrator:
[email protected]
Application des surfaces de réponse pour
l’analyse fiabiliste d’une structure spatiale
Méthode de Propagation d’incertitudes et applications
Nicolas Roussouly
*,** —Frank Petitjean
* —Michel Salaun
** —Fabrice Buffe
*** —Anne Carpine
*****Institut Catholique d’Arts et Métiers (ICAM)
75 avenue de Grande Bretagne, 31300 Toulouse, France [email protected], [email protected] ** Université de Toulouse ; ISAE ; Institut Clément Ader 10 avenue Edouard Belin 31055 Toulouse, France [email protected]
***Centre National d’Etudes Spatiales (CNES) 18 Avenue Edouard Belin 31401 Toulouse, France [email protected]
****Thales Alenia Space
100 boulevard du Midi 06156 Cannes la Bocca, France [email protected]
RÉSUMÉ.Cette communication présente une application des surfaces de réponse pour l’analyse de la fiabilité d’une structure satellite. Les méta-modèles sont construits par régression itéra-tive où seul les termes significatifs sont sélectionnés parmi une liste de regresseurs potentiels préalablement déterminée par une analyse de sensibilité. Les méta-modèles sont ensuite véri-fiés par une méthode de bootstrap où les variations observées sur les prédictions sont prises en compte dans le calcul des probabilités de défaillance afin de valider le résulat.
ABSTRACT.In this paper, response surface methodology is applied for reliability assessment of a spacecraft structure. Meta-models are built with stepwise regression from a potentiel set of regressors determined by sensitivity analysis. Variations observed through a bootstrap method are taken into account in the probability of failure assessment in order to validate results. MOTS-CLÉS :Surfaces de réponse, régression, validation croisée, bootstrap, algorithme de Mor-ris, fiabilité
KEYWORDS:Response surface, regression, cross validation, bootstrap, Morris algorithm, relia-bility
1. Inroduction
Le domaine spatial est de plus en plus régi par des considérations économiques fortes qui nécessitent la recherche de solutions optimales intégrant des informations techniques et financières. L’approche déterministe actuellement employée dans la spé-cification des structures rend difficile ce couplage technico-financier. L’information fournie est limitée et les résultats ne font pas apparaître les hypothèses faites sur cer-taines valeurs utilisées dans les calculs (facteur de sécurité, valeur A, valeur B). L’ap-proche probabiliste est un moyen de fournir une information plus riche pour l’aide à la décision. En associant une probabilité de défaillance à un coût de défaillance, les choix de designs peuvent être faits de manière mieux fondée.
C’est dans cet objectif qu’une première application de la démarche probabiliste a été mise en oeuvre sur une structure industrielle, à savoir le satellite TARANIS (cf. figure 1), développé par le CNES. L’intérêt grandissant de l’analyse fiabiliste et plus généralement de l’approche probabiliste dans le monde industriel, a entraîné ces dernières années un grand nombre de développements permettant d’introduire cette approche dans l’analyse mécanique des structures de taille plus ou moins importante. Citons par exemple les méthodes de simulation directionnelle et par sous-ensembles (Pradlwarter et al., 2005; Pellissetti et al., 2006; Au et al., 2001), les méthodes de fiabilité FORM et SORM (Ghanem et al., 2003; Berveiller, 2005; Sudret, 2007), les éléments finis stochastiques intrusifs et non-intrusifs (Ghanem et al., 2003; Berveiller, 2005; Sudret, 2007) ou les méthodes de méta-modélisation offrant une large possibi-lité d’approximation (Wang et al., 2007; Simpson et al., 2001). C’est cette dernière démarche que nous avons employé sur le satellite TARANIS et plus particulièrement celle des surfaces de réponse. Ce choix a été fait pour plusieurs raisons : la structure est modélisée sur le logiciel commercial MSC NASTRAN donc la démarche doit être non-intrusive ; le nombre de variables et de réponses à prendre en compte sont rela-tivement importants. De plus, l’avantage des méta-modèles est de pouvoir mener une réanalyse à moindre coût en changeant les hypothèses stochastiques des paramètres d’entrée. En effet les lois de distribution n’étant généralement pas bien connues, il est souvent utile de mener plusieurs analyses afin d’identifier plus précisément celles qui sont influentes. Parmi les types de méta-modèles, les surfaces de réponse ont été choi-sies car les a priori basés sur le comportement linéaire de la structure et les faibles variations des paramètres ont laissé penser qu’elles seraient suffisantes.
Les développements sont présentés en deux parties dont la première s’intéresse à la démarche de construction des surfaces de réponse qui inclue la recherche du modèle ainsi que le processus de vérification et de validation ; la seconde présente l’application de la démarche sur la structure satellite industrielle TARANIS.
2. Démarche de construction des surfaces de réponse
Les surfaces de réponses utilisées dans cette communication sont des fonctions polynomiales du second ordre, c’est à dire munies de termes linéaires, quadratiques
et d’interaction du premier ordre. A partir d’un échantillon statistique de taille n, on cherche à déterminer la relation linéaire entre une variable à expliquer Y et les ré-gresseurs Xk (k = 1,...,K) de variables explicatives Zp(k = 1,...,P ). L’équation du modèle de régression linéaire est défini par :
y = Xβ + ε (1)
où y est le vecteur des observations de Y , X est la matrice des régresseurs de taille n × K, β est le vecteur des coefficients à déterminer et ε est le vecteur des erreurs εi(i = 1,...,n) en chaque point de l’échantillon. Rapporté au problème mécanique, Y correspond à la réponse étudiée et les Zpsont les paramètres d’entrée du modèle. La méthode des moindres carrés permet de définir une estimation ˆβ des coefficients β, par le système :
ˆ
β = (XTX)−1XTy (2)
Une fois le modèle identifié, le coefficient de détermination, noté R2, permet de mesu-rer la qualité de l’ajustement aux données. Il est compris entre 0 et 1 et vaut 1 lorsque l’erreur est nulle aux points de l’échantillon. Cependant, pour éviter le phénomène de surapprentissageil n’est généralement pas intéressant de chercher un coefficient R2 proche de 1. Le but est de construire un modèle prédictif, c’est à dire qui garantit de bonnes prédictions sur des données qui ne sont pas utilisées pour l’identifier. Il s’agit de la capacité de généralisation. Pour cela, l’estimation de l’erreur des prédictions du modèle doit intégrer la précision de l’ajustement mais aussi la stabilité du modèle qui caractérise ses variations en fonction de l’échantillon d’apprentissage. Plusieurs outils sont disponibles dans la littérature.
2.1. Estimation de l’erreur de prédiction
Pour estimer l’erreur de prédiction de manière plus fiable, il faudrait par exemple mesurer l’ajustement sur un ensemble de données différent de celui d’apprentissage. L’inconvénient est qu’il faut disposer de deux ensembles. Pour y remédier il est pos-sible d’utiliser des estimations par pénalisation ou des estimations par simulation.
Les estimations par pénalisation consistent à pénaliser la somme des carrés rési-duelle (SCR = kεk2) par une fonction du nombre de termes dans le modèle. Les plus connues sont le Cp de Mallows qui est une estimation de l’erreur quadratique moyenne (égale au carré du biais ajouté à la variance des prédictions), l’AIC (Akaike informa-tion criterion), le BIC (Bayesian informainforma-tion criterion) et le R2a (R2ajusté ) qui est une forme pénalisée du coefficient de détermination1(Azaïs et al., 2005; Besse, 2009; 1. Le Cp, l’AIC et le BIC suppose que les résidus du modèle de régression sont des variables aléatoires gaussiennes centrées réduites, indépendantes et identiquement distribuées. Cette hy-pothèse n’est pas justifiée dans notre cas car les réponses sur l’échantillon sont issues d’un code numérique déterministe. Les erreurs représentent simplement les écarts entre le modèle réel (éléments finis) et le modèle approché (méta-modèle). Nous reviendrons sur cette hypothèse dans la suite.
Cornillon et al., 2007). En tenant compte du nombre de termes, ces critères favorisent les modèles parcimonieux qui sont caractérisés par une meilleure stabilité.
Le principe de l’estimation par simulation est d’évaluer l’ajustement du modèle sur des ensembles de points non utilisés dans l’identification du modèle et construits à partir de l’ensemble d’apprentissage. On trouve notamment la validation croisée et le bootstrap. Leur avantage est qu’ils ne font aucune hypothèse sur le modèle mais demandent en revanche plus de calculs.
Dans la partie suivante nous présentons la manière dont le modèle est construit puis vérifié à partir de ces outils.
2.2. Choix des régresseurs
Lorsque le nombre de variable est important, la construction d’un modèle de ré-gression à partir de tous les régresseurs disponibles demande un échantillon de grande taille (i.e un coût de calcul élevé). De plus, étant donné que certaines variables peuvent se révéler insignifiantes, il est plus intéressant de rechercher un sous-ensemble de ré-gresseurs parmi les potentiels suivant un critère défini. Nous utiliserons pour cette recherche les estimateurs d’erreur de prédiction par pénalisation présentés précédem-ment. Ils ont l’avantage de nécessiter d’un temps de calcul quasi-nul mais certains d’entre eux s’appuient sur des hypothèses non vérifiées. Il faut bien noter que ces cri-tères ne seront pas utilisés de manière absolue dans la certification du modèle mais ils serviront d’aide pour proposer un modèle dont la qualité sera évaluée grâce aux estimations par simulation. Étant donné qu’il n’est pas envisageable d’étudier la tota-lité des sous-ensembles de modèles, la recherche sera effectuée de manière itérative. Plusieurs méthodes existent sous le nom de sélection forward, backward, stepwise ou sequential replacement (Besse, 2009; Cornillon et al., 2007; Miller, 2002). Pour pouvoir utiliser les quatre critères précédents (Cp, AIC, BIC et R2
a) sans effectuer plu-sieurs fois la procédure, on peut établir une recherche forward, backward ou sequen-tial replacement par rapport à la somme des carrés résiduelle (SCR) et sélectionner parmi les modèles de niveaux différents (avec 1 régresseur puis 2 puis 3 ...) ceux qui sont optimums au sens des critères. Cela est possible car tous les critères sont fonction de la SCR et les pénalisations dépendent du nombre de régresseurs dans le modèle (Lumley, 2009). La procédure du choix des régresseurs conduit finalement à quatre modèles dont le meilleur sera sélectionné puis vérifié en vue d’une validation finale.
2.3. Sélection et vérification du modèle
Parmi les quatre modèles déterminés dans la procédure de recherche itérative, le meilleur est sélectionné par une méthode de validation croisée. Il s’agit de celui qui possède la plus faible erreur estimée par validation croisée. Étant donné que cette méthode possède une part d’aléatoire dans le découpage de l’ensemble d’apprentis-sage, si les erreurs estimées sont proches (avec un écart relatif inférieur à 10%) le
modèle sélectionné sera le plus parcimonieux, c’est à dire celui qui contient le moins de régresseurs. Cela permet de favoriser les modèles plus stables. Le modèle choisi est ensuite étudié par une méthode de bootstrap où les erreurs maximales et mini-males observées sur les prédictions peuvent être comparées à la variation maximale de la réponse observée lors de l’échantillonnage. Cela permet d’avoir une comparai-son entre l’erreur du modèle et l’incertitude associée à la réponse. Cependant, même si l’erreur du modèle est relativement faible rien ne permet de dire si elle l’est suffi-samment pour obtenir une bonne précision des résultats souhaités. Pour connaître son influence, nous en avons tenu compte dans l’évaluation de la probabilité de défaillance. Pour cela, on considère le méta-modèle ˆφ d’une réponse mécanique et la fonction de performance G(X1, ˆφ(X2)) associée où X1 et X2 sont des vecteurs de variables aléatoires. Le domaine de défaillance associé à la fonction de performance est tel que G(X1, ˆφ(X2)) ≤ 0 et la probabilité de défaillance est Pf = P(G(X1, ˆφ(X2)) ≤ 0). On définit :
Pf += P(G(X1, ˆφ+(X2)) ≤ 0) = P(G(X1, ˆφ(X2) + εsup) ≤ 0) Pf −= P(G(X1, ˆφ−(X2)) ≤ 0) = P(G(X1, ˆφ(X2) − εinf) ≤ 0)
(3) où εsupet εinf sont des valeurs reportées sur le méta-modèle, qui permettent d’inclure les variations observées par bootstrap et les valeurs exactes de la réponse échantillon-née. En définitive, Pf +et Pf −permettent d’obtenir une information sur la variation de la probabilité de défaillance en fonction de l’erreur du méta-modèle.
2.4. La démarche en pratique, échantillonnage et analyse de sensibilité
Dans la pratique, la construction du modèle est faite de manière progressive. Cela signifie que, dans un premier temps, un modèle linéaire est construit. La base d’ap-prentissage du modèle est obtenu par plusieurs simulations du modèle éléments finis de référence. Pour mieux répartir les points dans l’espace et répondre au besoin d’un modèle prédictif, nous avons utilisé une méthode de Latin Hypercube Sampling (LHS) largement employée dans la littérature. De plus, pour que l’échantillonnage soit indé-pendant de l’analyse probabiliste qui suivra, les lois des variables sont considérées uniformes. Bien qu’un échantillon de dimension 2K (K est le nombre de régresseurs) est généralement suffisant, nous avons préféré un échantillon de taille 3K pour que les informations issues de la validation croisée et du bootstrap ne soit pas trop détériorées. Si le modèle linéaire ne convient pas il est nécessaire de passer à l’ordre supérieur en intégrant les termes quadratiques et d’interaction du premier ordre. Étant donné que les termes linéaires insignifiants ne sont pas sélectionnés dans le modèle lors de la recherche itérative, il est possible d’y inclure de nouveaux termes sans augmenter la taille de l’échantillon. Cependant, tenir compte des termes d’interaction du premier ordre dans la liste des régresseurs potentiels rend bien plus coûteuse la recherche de modèle (surtout s’il faut construire plusieurs modèles). Dans ce cas il est parfois plus favorable (en fonction du temps d’un calcul éléments finis) de mener une analyse de sensibilité qui donne une “idée” des termes les plus influents afin de procéder à une pré-sélection. C’est le cas pour le modèle qui est traité dans la suite. L’analyse de
sen-(a) Modèle éléments finis complet (b) Plateau inférieur Figure 1. Satellite TARANIS
sibilité est effectuée par la méthode de Morris OAT (One At a Time) (Morris, 1991; Saltelli et al., 2000) faisant partie des méthodes de screening. Elle fournit l’influence linéaire des variables (mesure notée µ∗) ainsi que leur effet non-linéaire et/ou d’in-teraction (mesure noté σ) avec une autre variable. La précision obtenue dépend du nombre de calculs effectués. Le but, ici, étant d’obtenir une hiérarchisation, 3(P + 1) calculs seront effectués (P est le nombre de variables). Enfin, nous avons choisi d’ef-fectuer la sélection par un pourcentage de la réponse influencée en représentant les résultats sous la forme d’un diagramme de Pareto (cumul de l’influence des variables en fonction du nombre de variables). Étant donné que nous sommes intéressés par les variables les plus influentes non-linéairement ou par interaction, la sélection est faite en fonction de la mesure σ.
3. Application sur le satellite TARANIS 3.1. Description du modèle
La démarche précédente est appliquée au satellite scientifique TARANIS (cf. Fi-gure 1) développé par le CNES dont la plate-forme appartient à la famille Myriade. Le modèle éléments finis a été réalisé sur le logiciel MSC NASTRAN. Il est majori-tairement composé d’éléments surfaciques et contient au total un peu plus de 380 000 degrés de liberté. La structure possède un comportement mécanique linéaire élastique et est étudié sous 8 cas de chargements statiques. Ils consistent en des accélérations de −9,5g dans la direction longitudinale (axe X) et de 5,2g dans plusieurs directions latérales (axe Y et Z).
3.2. Description de l’étude
Nous cherchons à déterminer la probabilité de défaillance de plusieurs éléments de la structure qui sont les panneaux latéraux, le panneau supérieur (composite nida aluminium et peaux en aluminium) et inférieur (usiné dans la masse en aluminium) et les vis d’interface (titane) entre les panneaux latéraux et le plateau inférieur. Les critères de défaillance sont la limite élastique pour les panneaux et la limite de glisse-ment pour les vis. Ils représentent des critères de défaillance classiques utilisés pour le calcul des marges de sécurité dans une approche déterministe. Pour les panneaux, la marge élastique est notée M Selaset vaut :
M Selas= Re
σcalc − 1 (4)
où Re est la résistance élastique et σcalc est la contrainte maximale de Von Mises calculées par le code éléments finis. Dans un calcul déterministe un coefficient de sécurité est souvent associé à la contrainte calculée et la valeur de Reest une valeur quantile (valeur A, B). La marge de glissement concernant les vis est notée M Sgliss et vaut : M Sgliss= Fpreload− FN FT fass − 1 (5)
où Fpreloadest la force de précharge dans la vis, fassest le coefficient de frottement de l’assemblage, FN et FTsont respectivement les efforts normaux et tangentiels dans la vis calculés par le code éléments finis. Comme précédemment, la démarche détermi-niste tient compte d’un coefficient de sécurité et décale les valeurs de la précharge et du coefficient de frottement par rapport à leur moyenne. Finalement, les probabilités de défaillance sont définies par Pfelas = P(M Selas ≤ 0) et Pfgliss = P(M Sgliss ≤ 0)
pour chaque panneau ou vis. Pour garantir une meilleure qualité des méta-modèles et réduire le nombre de calcul, nous avons préféré les construire sur les réponses is-sues du code éléments finis plutôt que sur les marges. Ainsi, pour les panneaux, les méta-modèles sont identifiés sur la contrainte maximale de Von Mises ; pour les vis, ils sont identifiés sur les efforts suivant l’axe normal et les deux axes tangentiels (l’effort tangentiel résultant est obtenu par combinaison des méta-modèles des composantes de l’effort, toujours pour garantir une meilleure qualité des approximations). Dans le même objectif, le plateau inférieur subit un traitement particulier étant donné qu’il est plus complexe qu’une simple plaque (cf. Figure 1). Chaque partie de sa structure (raidisseurs, fonds, cylindre central,...) est étudié par un méta-modèle. Au final, en tenant compte des 8 cas de charges, le nombre de réponses à considérer et donc de méta-modèles à construire est de plus de 1200. Pour éviter d’en déterminer autant, nous avons considéré seulement les réponses qui impliquent une marge déterministe inférieure à 1, ce qui réduit le nombre de méta-modèles à 150. Les variables prises en compte sont toutes celles qui caractérisent les éléments structuraux présentés ci-dessus. Elles concernent les épaisseurs, toutes les caractéristiques mécaniques, les ré-sistances élastiques, les efforts de serrage, les coefficients d’assemblage ainsi que le chargement. On compte au total 151 variables dont 81 sont des paramètres du modèle
éléments finis. Ainsi l’échantillonnage n’est réalisé que par rapport à 81 variables, les autres ne sont prises en compte que lors du calcul de la probabilité de défaillance sur les marges définies ci-dessus. De ce fait, 243 calcul éléments finis sont réalisés. Les variables aléatoires sont supposées uniformes pour les épaisseurs avec une amplitude de ±10% et gaussiennes pour les autres avec des coefficient de variation de 4% pour les modules d’Young, les coefficients de Poisson, les modules de cisaillement et le chargement et un coefficient de variation de 10% pour les résistances élastiques, les efforts de précharge et les coefficients de frottement. Toutes les variables sont suppo-sées indépendantes.
3.3. Analyse des résultats
Nous avons préféré, dans un premier temps, tenir compte des régresseurs linéaires et quadratiques dans la recherche itérative étant donné que cela n’est pas beaucoup plus coûteux en temps de calcul. L’échantillon est tout de même dimensionné pour un méta-modèle linéaire. Cela signifie que le nombre de régresseurs potentiels est de 162 mais que les méta-modèles sont limités à 81 regresseurs. La procédure de recherche itérative permet de construire les 150 méta-modèles dont le nombre de regresseurs re-tenus est compris entre 13 et 74, la moyenne étant égale à 36 regresseurs. Pour chaque méta-modèle, nous avons comparé l’erreur maximale entre les prédictions supérieures et inférieures2, et les valeurs exactes de la réponse par rapport à des pourcentages de la variation observée lors de l’échantillonnage. Ainsi, aucun méta-modèle n’a une er-reur inférieure à 5%, 27% des méta-modèles ont une erer-reur inférieure à 10%, 45% ont une erreur inférieure à 15%, 68% à 20% et 91% à 25%. La plus importante erreur observée parmi les méta-modèles est égale à 32% de la variation de la réponse. Pour identifier l’influence de ces erreurs sur les probabilités de défaillance, 1 000 000 de tirages sont effectués sur les méta-modèles initiaux, supérieurs et inférieurs. A titre d’exemple, l’erreur constatée de ±14% sur le modèle de la contrainte maximale du panneau +Z (panneau dont la normale sortante est dans la direction +Z) sous le char-gement de −9,75g suivant X, −3,68g suivant Y et 3,68g suivant Z, entrainent un écart de la probabilité de défaillance de −16% à +20% par rapport au méta-modèle initial (ces écarts sont calculées par rapport au logarithme des probabilités de défaillance). Sous le chargement de −9,75g suivant X, 0g suivant Y et 5,2g suivant Z, les erreurs constatées de ±8%, ±24% et ±22% sur les méta-modèles des efforts suivant les axes X, Y et Z dans la vis 10001260 (cf. Figure 1) entrainent un écart de −6,2% à +6,6% sur la probabilité de glissement. Les écarts minimum et maximum observées sur la totalité des probabilités de défaillance sont respectivement de 2% et 20%.
L’étape suivante consiste à ajouter les termes d’interaction dans la recherche des regresseurs. Etant donné qu’aucun méta-modèle n’a atteint la limite imposée de 81 regresseurs, un certains nombre peuvent être ajoutés sans augmenter la base d’appren-tissage. Par contre, plusieurs calculs éléments finis supplémentaires sont nécessaires 2. Nous appelons les prédictions supérieures et inférieures, les prédictions décalées de +εsup
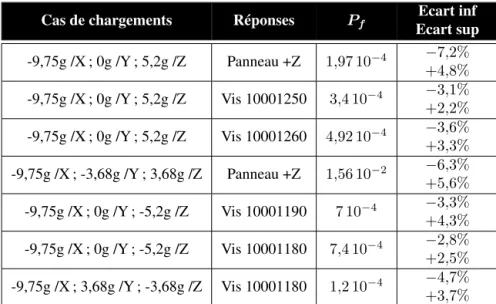
Cas de chargements Réponses Pf Ecart inf Ecart sup -9,75g /X ; 0g /Y ; 5,2g /Z Panneau +Z 1,97 10−4 −7,2% +4,8% -9,75g /X ; 0g /Y ; 5,2g /Z Vis 10001250 3,4 10−4 −3,1% +2,2% -9,75g /X ; 0g /Y ; 5,2g /Z Vis 10001260 4,92 10−4 −3,6% +3,3% -9,75g /X ; -3,68g /Y ; 3,68g /Z Panneau +Z 1,56 10−2 −6,3% +5,6% -9,75g /X ; 0g /Y ; -5,2g /Z Vis 10001190 7 10−4 −3,3% +4,3% -9,75g /X ; 0g /Y ; -5,2g /Z Vis 10001180 7,4 10−4 −2,8% +2,5% -9,75g /X ; 3,68g /Y ; -3,68g /Z Vis 10001180 1,2 10−4 −4,7% +3,7% Tableau 1. Valeurs des probabilité de défaillance les plus significatives
étant donné qu’il est plus intéressant dans notre cas de mener une étude de sensibilité pour pré-sélectionner les meilleurs termes. Pour cela, 246 calculs sont effectués. Le seuil de sélection des variables est fixé à 90% de la réponse influencée. Parmi les 150 réponses étudiées, le nombre de variables sélectionnées est compris entre 13 et 28, la moyenne étant égale à 20 variables. Rappelons qu’une variable qui n’est pas sélec-tionnée, n’est pas supprimée de l’étude mais seul son terme linéaire est pris en compte dans la liste des regresseurs potentiels. Comme précédemment, les méta-modèles sont construits par recherche itérative. A présent, 113 méta-modèles atteignent la limite de 81 regresseurs alors que le plus parcimonieux en contient 52. Leur qualité est nette-ment amélioré puisque 21% des méta-modèles ont une erreur inférieure à 5%, 75% ont une erreur inférieure à 10%, 97% à 15% et 100% à 20%. Les écarts minimum et maximum observés sur la totalité des probabilités de défaillance sont respective-ment de 1,2% et 7% Pour comparer avec les deux exemples précédents, l’écart de la probabilité de défaillance du panneau +Z est de −6,3% à +5,6% et celui de la vis 10001260 de −3,6% à +3,3%. Les probabilités de défaillance les plus significatives sont présentées dans le Tableau 1.
La valeur la plus critique égale à 1,56 10−2pour la limite élastique du panneau +Z a été comparée à celle obtenue par des tirages de Monte Carlo directement effectués sur le modèle éléments finis. Au total, 23 240 calculs ont permis d’évaluer une proba-bilité de défaillance égale à 1,4 10−2avec un coefficient de variation de 5,5%. Même si ce résultat ne valide pas totalement la démarche, il reste tout de même satisfaisant.
4. Conclusion
Cette communication présente une application des surfaces de réponse pour l’ana-lyse de la fiabilité d’une structure industrielle. La démarche mise en place tente de réduire le temps de calcul par une pré-sélection des termes influents grâce à une ana-lyse de sensibilité, et par une recherche itérative des meilleurs régresseurs pour la construction des méta-modèles. Nous tentons également de renforcer les étapes de vé-rification en regardant directement l’influence de l’erreur du modèle sur la probabilité de défaillance. Les écarts calculés ne sont pas, à coup sûr, les bornes d’un encadre-ment de la probabilité de défaillance, mais incluent l’erreur due au manque de stabi-lité et de précision qui sont constatées sur le méta-modèle. La variation observée sur la probabilité de défaillance semble plus pertinente que celle observée sur le méta-modèle étant donné qu’il s’agit de l’information finale qui nous intéresse. Comme le montre l’exemple précédent, certains méta-modèles dont l’erreur est plus importante que d’autres, entrainent un plus faible écart de la probabilité de défaillance. Il n’est donc pas toujours intéressant de chercher à améliorer au maximum la qualité du méta-modèle si celle-ci s’avère peu influente sur la fonction de performance. Le démarche permet également de se focaliser progressivement sur les réponses les plus impor-tantes. Dans notre cas, un certain nombre de réponses auraient pu ne pas être prises en compte dans la seconde étape (ajout des termes d’interaction). Cela reste également important dans une démarche industrielle où la quantité d’information à traiter devient rapidement fastidieuse. Rappelons également que les méta-modèles permettent de me-ner une nouvelle analyse à moindre coût en changeant les paramètres stochastiques, soit parcequ’ils sont mal connus, soit pour comparer des solutions technologiques. Ils peuvent aussi être utiliser en optimisation ou en optimisation fiabiliste.
Références
Au S., Beck J., « Estimation of small failure probabilities in high dimensions by subset simulation », Probabilistic Engineering Mechanics, vol. 16, n˚ 4, p. 263-277, 2001. Azaïs J., Bardet J., Le modèle linéaire par l’exemple : régression, analyse de la
va-riance et plans d’expériences illustrés avec R, SAS et Splus, Dunod, 2005.
Berveiller M., Éléments finis stochastiques : approches intrusive et non intrusive pour des analyses de fiabilité, PhD thesis, Université Blaise Pascal, 2005.
Besse P., Apprentissage Statistique & Data mining, Technical report, Institut de Ma-thématiques de Toulouse, Laboratoire de Statistique et Probabilités, Institut Natio-nal des Sciences Appliquées de Toulouse, 2009.
Cornillon P., Matzner-Lober E., Régression, Théorie et applications, Springer, 2007. Ghanem R. G., Spanos P. D., Stochastic finite elements : a spectral approach, Dover
Lumley T., « The leaps Package March 16, 2009 Title regression subset selection... », , http ://www.biometrics.mtu.edu/CRAN/web/packages/leaps/leaps.pdf, 2009. Miller A., Subset selection in regression, CRC Pr I Llc, 2002.
Morris M. D., « Factorial Sampling Plans for Preliminary Computational Experi-ments », Technometrics, vol. 33, p. 161-174, 1991.
Pellissetti M., Schuëller G., Pradlwarter H., Calvi A., Fransen S., Klein M., « Reliabi-lity analysis of spacecraft structures under static and dynamic loading », Computers and Structures, vol. 84, n˚ 21, p. 1313-1325, 2006.
Pradlwarter H., Pellissetti M., Schenk C., Schuëller G., Kreis A., Fransen S., Calvi A., Klein M., « Realistic and efficient reliability estimation for aerospace struc-tures », Computer Methods in Applied Mechanics and Engineering, vol. 194, n˚ 12-16, p. 1597-1617, 2005.
Saltelli A., Chan K., Scott E., Sensitivity analysis. Series in Probability and Statistics, Wiley, 2000.
Simpson T., Poplinski J., Koch P., Allen J., « Metamodels for Computer-based Engi-neering Design : Survey and recommendations », EngiEngi-neering with Computers, vol. 17, n˚ 2, p. 129-150, 2001.
Sudret B., Uncertainty propagation and sensitivity analysis in mechanical models -Contributions to structural reliability and stochastic spectral methods, PhD thesis, Université Blaise Pascal, 2007.
Wang G., Shan S., « Review of Metamodeling Techniques in Support of Engineering Design Optimization », Journal of Mechanical Design, vol. 129, p. 370, 2007.