2012 — Improving evolutionary algorithms by MEANS of an adaptive parameter control approach
269
0
0
Texte intégral
Figure
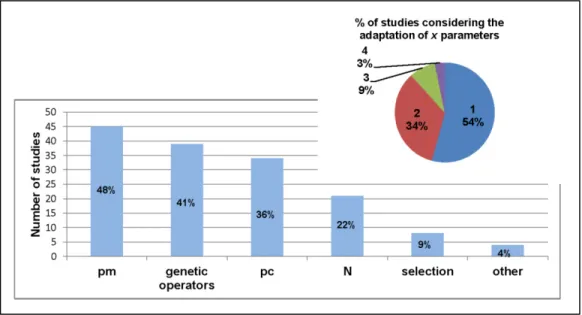
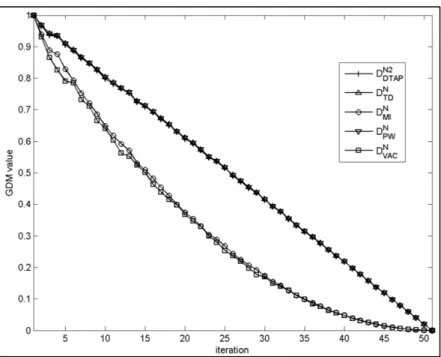
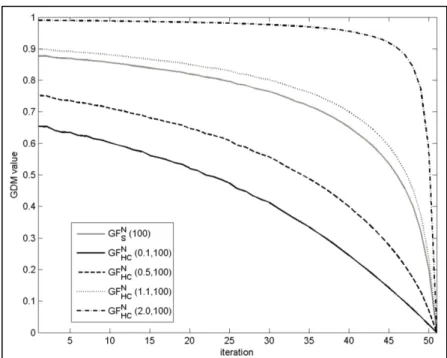
+7

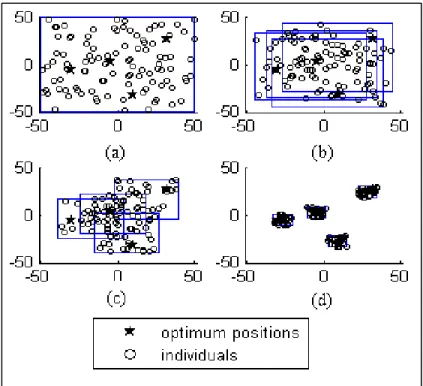
![Figure 2.2 Representation of a uniformly random population with 100 individuals bounded between [0, 1] 2 , where diversity is evaluated by: a) D L – union of the area associated with each](https://thumb-eu.123doks.com/thumbv2/123doknet/7448566.221184/93.918.223.718.177.442/figure-representation-uniformly-population-individuals-diversity-evaluated-associated.webp)

Documents relatifs
Si c’est correct, le joueur peut avancer du nombre de cases indiqué sur le dé de la carte. Sinon, il reste à
Les camarades de jeu retiennent la position des cartes pour former plus facilement de nouvelles paires. Pour l’impression du
On saute une ligne pour placer d’éventuelles retenues pour
[r]
Par la r´ eciproque de Pythagore, ABC est donc rectangle
[r]
[r]
Pour l’ouvrir il faut découvrir les trois chiffres qui composent
