Université Ahmed Draïa d'Adrar Faculté des Sciences et de la Technologie Département de Mathématiques et Informatique
Mémoire de Fin d’étude
En vue de l’Obtention du Diplôme de Master en Informatique Option : Systèmes d’information
Thème
APPROCHE NEURO-SVM POUR LA
RECONNAISSANCE DES CARACTERES
MANUSCRITS ARABES
Préparé par :
M
me. DALIL Fatima Zohra et M
elle. GHAITAOUI Zahra
Encadrées par :Université Ahmed Draïa d'Adrar Faculté des Sciences et de la Technologie Département de Mathématiques et Informatique
Mémoire de Fin d’étude
En vue de l’Obtention du Diplôme de Master en Informatique Option : Systèmes d’information
Thème
APPROCHE NEURO-SVM POUR LA
RECONNAISSANCE DES CARACTERES
MANUSCRITS ARABES
Préparé par :
M
me. DALIL Fatima Zohra et M
elle. GHAITAOUI Zahra
Encadrées par :Remerciements
Avant tout, nous adressons nos respectueux remerciements à
الله
le puissant
pour tout ce qu'il nous a donné.
Nous tenons tout d’abord à exprimer notre profonde gratitude à Monsieur
«
MAMOUNI El Mamoun
», notre encadreur, et l’honneur qu’il nous a
fait en acceptant de nous encadrer. Avec un intérêt constant et une grande
compétence ainsi pour l’intérêt qu’il a bien voulu porter à notre travail.
Notre respect et notre gratitude vont également aux membres du jury qui
nous ont fait l’honneur de juger ce travail et qui par leur disponibilité, leurs
observations et leurs rapports nous ont permis d’enrichir notre travail.
Nous remercions également de tout notre cœur
tous les enseignants
qui ont
contribué à notre apprentissage depuis notre jeune âge à ce jour.
Nous remercions toutes les personnes qui ont participé de manière directe ou
indirecte à la concrétisation de ce travail.
Dédicace
«
Le plus grand merci s'adresse au
bon Dieu
»A
ma mère
et à
mon père
,
qui m'ont comblée de leur soutien et m'ont voué un
amour inconditionnel. Vous êtes pour moi un exemple de courage et de
sacrifice continu, que cet humble travail témoigne mon affection, mon
éternel attachement et qu'il appelle sur moi votre continuelle bénédiction.
A Monsieur «
MAMOUNI El Mamoun
», qui m’a permis, grâce à sa
confiance et à son soutien précieux, de réaliser et surtout de mener à termece
travail. A
Mes frères
et
Sœurs
qui n'ont cessé d'être pour moi des exemples
de persévérance, de courage et de générosité. A mes neveux et nièces.
Je le dédie aussi à mon binôme«
Fatima
».
Et à tous mes collègues d'étude surtout les étudiants de 2éme année master
informatique promotion
2017-2018
.
Enfin je le dédie à toute
ma famille
et tous mes
meilleurs enseignants
de la spécialité un par un et à tous qui me connaissent, en particulier les
gens de la faculté des sciences.
DEDICACES
Je commence tout d’abord par remercier
الله
tout
puissant pour l’accomplissement de mémoire.
Je dédie ce travail
À mon père
A mon mère
Dieu a pitié d'elle et fait son
paradis
À mes très chers parents qui m’ont soutenu tout
au long de mes études
À mon marié Abderrahmane
À ma petite fille Aicha Omkaltom
À ma sœur et mon amis khadidja pour leur
encouragement
À mon binôme
Zahra
À
toutes mes enseignants de la faculté.
À
toute personne ayant contribué de prés ou de
loin à la réalisation de ce mémoire.
Résumé
Ce présent travail est inscrit dans le domaine de reconnaissance automatique de caractères, en particulier la reconnaissance de caractères arabe manuscrite hors-lignes. Il consiste à la réalisation d‟un système complet de reconnaissance avec la proposition d‟une architecture hybride de classification multicouche, nous appelons NEURO-SVM. Cette architecture dispose deux modules en cascade : module d'extraction de caractéristiques et module de classification. Dans le module d'extraction de caractéristiques, nous utilisons un réseau de neurones, en particulier un perceptron multicouche (MLP). Dans le module de classification, nous utilisons les Machines à Vecteurs de Support (SVM). L‟approche NEURO-SVM profite les avantages des deux méthodes de classification, à savoir, les MLPs et les SVMs. Il peut nettement améliorer la performance de classification. La caractéristique la plus intéressante de NEURO-SVM est qu'elle élimine pratiquement la dépendance sévère de SVM sur le choix du noyau. Cela a été vérifié en ce qui concerne les noyaux linéaires et RBF. Mots-clés : Reconnaissance, caractère manuscrite, MLP, extraction de caractéristiques, machines à vecteurs de support (SVM), NEURO-SVM.
صخلم
:
يلاحلا لمعلا دعي فرعتلا ىلع ةردقلا اهيدل يتلا تلااجملا نم ءزج ىلع يئاقلتلا طوطخملا ىنعملاب ،عساولا ,ديلا طخب ةبوتكملا فورحلا ىلع فرعتلا اصوصخو لماك ماظن نم نوكتي وهو فرعتلل حرتقن . ل ةديدج ةينب ل ةدحوو ةزيملا صلاختسا ةدحو :نيتيلاتتم نيتدحو ىلع ةحرتقملا ةنيجهلا ةينبلا لمتشت .فينصت .تاقبطلا ةددعتم تانوبصعلا تاكبش مدختسن ، ةزيملا جارختسا ةدحو يف .فينصتلا و ةدحو يف ،فينصتلا مدختسن ( تاهجتملا معد تلاآ SVM ) . ديفتسي فنصملا نم ديدجلا يتقيرط فينصتلا .ةقباسلا ك ام هنأ نأ نكمي تي نسح يبك لكشب لأا يف ر مامتهلال ةرارث رركلأا ةزيملا .ءاد نبلا يف ي ةنيجهلا ة ىلع ديدشلا دامتعلاا ليزي داكي هنأ وه تلاآ تاهجتملا معد يف و ةيطخلا ىونلاب قلعتي اميف كلذ نم ققحتلا مت دقو .ةاونلا رايتخا ةيعاعشلا ةدعاقلا ةفيظو اذك . ةيحاتفملا تاملكلا : فرعتلا تاكبشلا ، ةيبصعلا تاكبشلا ،ديلا طخب ةبوتكملا فورحلا ، ةيبصعلا تاقبطلا ةددعتم ، بيردتلا ، ةيعاعشلا ةدعاقلا ةفيظو ةنيجهلا ةينبلا ، .Abstract
This present work is registered in the field of automatic recognition of characters, in particular the recognition of Arabic characters handwritten offline. It involves the realization of a complete system of recognition with the proposal of a hybrid architecture of multilayer classification, we call NEURO-SVM. This architecture has two modules in cascade: feature extraction module and classification module. In the feature extraction module, we use a neural network, in particular a multilayer perceptron (MLP). In the classification module we use Support Vector Machines (SVM). The NEURO-SVM approach benefits from the two classification methods, MLPs and SVMs. It can significantly improve classification performance. The most interesting feature of NEURO-SVM is that it virtually eliminates SVM's severe dependence on kernel selection. This has been verified with regard to linear and RBF cores.
Keywords: Recognition, handwritten character, MLP, feature extraction, support vector machines (SVM), NEURO-SVM.
Table des matières
Remerciements ... IV Résumé ... VII Abstract ... VIII Liste des tableaux ... XIII Liste des figures ... XIV Abréviations ... XV
Introduction générale
1. Contexte et But du mémoire ... 2
2. Plan de travail ... 2
Chapitre I 1. Introduction ... 5
2. Caractéristiques de l‟écriture Arabe ... 5
3. Différents aspects de l'OCR (Optical Character Recognition) ... 6
3.1 Reconnaissance En ligne et Hors ligne ... 6
3.1.1 Reconnaissance En ligne (on-line) ... 7
3.1.2 Reconnaissance hors-ligne (off - line) ... 7
Reconnaissance de texte ou analyse de documents ... 7
3.2 Reconnaissance de l‟imprimé ou du manuscrit ... 8
3.2.1Cas de l‟imprimé ... 8
3.2.2 .Cas du manuscrit ... 9
Reconnaissance mono-scripteur, multi-scripteur et omni-scripteur ... 9
3.3 Approches de reconnaissance ... 9
3.3.1 Approche globale ... 9
3.3.2 Approche analytique ... 9
4. Processus de reconnaissance ... 11
4.1. Phase d‟acquisition ... 11
4.1.1 Acquisition hors ligne ... 11
4.1.2 Acquisition en ligne ... 12 4.1.3 Etape d‟acquisition ... 12 a) L‟échantillonnage ... 12 b) La quantification ... 12 4.2 Phase de prétraitement ... 12 4.2.1 Binarisation ... 13
4.2.3 Transformation par dilatation ... 14
4.2.4 Ouverture morphologique ... 14
4.2.5 Fermeture morphologique ... 14
4.2.6 Squelettisation d'une image ... 14
4.2.7 Normalisation ... 15 4.2.8 Suppression du bruit ... 16 4.3Phase de segmentation ... 16 4.3.1 Techniques de la segmentation ... 16 a- Segmentation implicite ... 17 b- Segmentation explicite ... 17
4.4 Phase d‟extraction des caractéristiques ... 18
4.4.1 Caractéristiques structurelles ... 18 4.4.2 Caractéristiques statistiques ... 18 4.4.3 Transformations globales ... 19 4.5 Phase de classification ... 19 4.5.1Méthodes de reconnaissances ... 19 4.5.1.1 Réseaux de neurones ... 19
4.5.1.2 Machines à Vecteur de Support (Support Vector Machine) ... 20
4.5.2 Apprentissage ... 20
4.5.2.1 Apprentissage supervisé ... 20
4.5.2.2 Apprentissage non supervisé ... 20
4.5.3 Reconnaissance et décision ... 20 4.6 Phase de post-traitement ... 21 5. Conclusion... 21 Chapitre II 1.Introduction ... 23 2.Historique ... 23
3.Mise en œuvre des Réseaux de Neurones ... 23
3.1. Le neurone biologique ... 24
3.2. Les neurones artificiels ... 24
4.La modélisation des neurones ... 26
5.Architectures des réseaux de neurones ... 26
5.1. Réseau multicouche ... 26
5.2. Réseau à connexions locales ... 27
5.4. Réseau à connexions complexes ... 29
6.Les réseaux les plus célèbres ... 29
6.1. Le perceptron ... 29 6.2. Le modèle ADALINE ... 30 6.3. Perceptron Multi-Couches ... 30 6.3.1. La couche d‟entrée ... 31 6.3.2. La couche cachée ... 31 6.3.3. La couche de sortie ... 31 7.Apprentissage ... 31
7.1. Les type d'apprentissage des réseaux de neurones ... 32
a) Apprentissage supervisé ... 32
b) Apprentissage non supervisé (auto- organisation) ... 32
c) Apprentissages hybride ... 32
7.2. Règles d‟apprentissages ... 32
7.2.1. La règle de Hebb ... 32
7.2.1. La règle de Widrow-Hoff ... 33
7.2.1. Apprentissage du perceptron multicouche ... 34
8.Les avantages et les inconvénients de réseaux de neurone... 37
a. Les Avantage [32] ... 37
b. Les inconvénients [32] ... 38
9.Conclusion ... 38
Chapitre III 1.Introduction ... 40
2.Principe de fonctionnement général ... 40
2.1. Linéarité et non linéarité ... 41
2.1.1. Cas linéairement séparable : ... 42
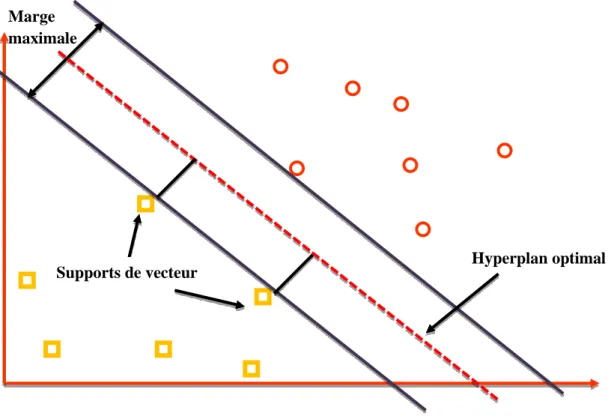
2.1.2. Marge maximale de l‟hyperplan ... 43
2.1.3.Cas non linéairement ... 44
3.Implementation multi classes ... 49
3.1 Un contre tous (OAA : One Against All) : ... 49
3.2 Un contre un (OAO : One Against One) ... 51
4.Les domaines d'applications des SVM ... 53
5.Les avantages et les inconvénients des SVM ... 54
6.Conclusion ... 54
Chapitre IV 1.Introduction ... 56
2.Classificateur NEURO-SVM proposé... 56
3.Avantages de proposée ... 57
4.Conclusion ... 58
Chapitre V 1.Introduction ... 60
2.Ressources matérielles et logicielles : ... 60
2.1. Ressources matérielles : ... 60
2.2. Ressources logicielles: ... 60
2.2.1. Bref présentation de C++ Builder ... 60
2.2.2. SVMmulticlass ... 61
3.Description de notre base de données ... 62
4.Description de notre système de reconnaissance ... 63
4.1. Acquisition de l‟image ... 63
4.2. Normalisation ... 64
4.3. L‟extraction des primitives ... 65
4.4. Construction de la matrice de distribution ... 65
4.4.1. Structure de vecteur de caractéristique ... 66
4.1.1.1 Corpus ... 67
5.Expérimentations et Résultats ... 68
5.1. Le système basé sur le réseau de neurones ... 68
5.1.1. Apprentissage et classification ... 68
5.1.2. Evaluation des résultats ... 68
5.2. Pour le système de méthode SVM ... 69
5.3. Pour le système NEURO-SVM ... 71
5.3.1 NEURO-SVM avec SVM une-contre-reste ... 71
5.3.2 NEURO-SVM avec SVM une-contre-une ... 72
6.Conclusion ... 73
Conclusion générale Conclusion générale et Perspectives ... 75
Bibliographie ... 76
Liste des tableaux
Tableau 2.1:Comparaison entre le nerveux biologique et artificiel. ... 26
Tableau 5.1:Représentation des caractéristiques techniques de l‟ordinateur de développement. ... 60
Tableau 5.2:Les lettres arabes utilisées (28 classes). ... 63
Tableau 5.3:Vecteur des caractéristiques de la lettre «ن». ... 67
Tableau 5.4:Le taux de reconnaissance obtenu par le noyau RBF. ... 69
Tableau 5.5:Le taux de reconnaissance obtenu par le noyau linéaire. ... 70
Tableau 5.6:Le taux de reconnaissance obtenu par le noyau RBF. ... 70
Tableau 5.7:Le taux de reconnaissance obtenu par le noyau linéaire. ... 70
Tableau 5.8: Les résultats de NEURO-SVM avec le noyau RBF et la stratégie une contre-reste.. ... 71
Tableau 5.9: Les résultats de NEURO-SVM avec le noyau linéaire et la stratégie une-contre-reste. ... 72
Tableau 5.10: Les résultats de NEURO-SVM avec le noyau RBF et la stratégie une contre-reste.. ... 72
Tableau 5.11: Les résultats de NEURO-SVM avec le noyau linéaire et la stratégie une-contre-une. ... 72
Liste des figures
Figure1.2: Reconnaissance d‟écriture en ligne. ... 7
Figure1.3: Reconnaissance d‟écriture hors ligne. ... 8
Figure1.4: Différents systèmes, représentations et approches de reconnaissance... 10
Figure1.5: Schéma général du système de reconnaissance des caractères. ... 11
Figure1.6: Effets de certaines opérations de prétraitement. ... 13
Figure1.7: Exemple de la binarisation [10]. ... 14
Figure1.8: Technique de semi-squelettisation [16]. ... 15
Figure1.9: Exemples de squelettisation [1]. ... 15
Figure1.10: Exemple de Suppression du bruit. ... 21
Figure 2.1: Simplification d'un neurone biologique [28]. ... 24
Figure 2.2: Simplification d'un neurone artificiel. ... 25
Figure 2.3: La fonction d‟Heaviside. ... 26
Figure 2.4: La fonction signe. ... 26
Figure 2.5: Réseau multicouche classique. ... 27
Figure 2.6: Réseau multicouche à connexions locales. ... 28
Figure 2.7: Réseau à connexions récurrentes. ... 28
Figure 2.8: Réseau à connexions complexes. ... 29
Figure 2.9: Structure d‟un perceptron ... 30
Figure 2.10: Architecture d‟un PMC à une seule couche cachée. ... 31
Figure 3.1: Séparation de deux ensembles de points par un Hyperplan H. ... 40
Figure 3.2: Hyperplan optimal, marge et vecteurs de support. ... 41
Figure 3.3: Linéarité et non linéarité. ... 42
Figure 3.4: hyperplan séparateur [41]. ... 43
Figure 3.5: Données dans le cas non séparables. ... 45
Figure 3.6: Transformation de l‟espace de représentation et l‟hyperplan séparateur dans le cas non linéairement séparables. ... 46
Figure 3.7: Fonction polynômiale. ... 48
Figure 3.8: Fonction RBF. ... 48
Figure 3.9: Approche une-contre-reste avec des zones d‟indécision. ... 50
Figure 3.10: Résolution des cas d‟indécision dans la méthode 1vsR. ... 51
Figure 3.11: Approche une-contre-une. ... 53
Figure 4.1:Schéma général du système NEURO-SVM. ... 57
Figure 5.1:L‟interface de C++ Builder... 61
Figure 5.2:Des échantillons de la base de données. ... 62
Figure 5.3:Interface d‟acquisition des images de notre application. ... 64
Figure 5.4:Interface de normalisation des images de l'application. ... 65
Figure 5.5:Exemple de matrice de distribution (7*7) de la lettre alphabet arabe «Noon». ... 66
Figure 5.6:Interface de création des corpus. ... 67
Figure 5.7:Taux de reconnaissance globale pour les caractères arabe. ... 68
Abréviations
MLP: Multi-layers Perceptron. OCR: Optical Character Récognition. PMC: Perceptrons Multi-Couches.
ADALINE : ADAptatif LINéaire Elément. RNA : Réseaux de Neurones Artificiels. SVM : Support Vector Machine.
CBIR: Content Based Image Retrieval. RBF: Radial Basis Function.
OAO: One Against One. OAA: One Against All.
RAD: Rapide Application Développements. RAM : Random Access Memory.
FM : Feature Model. CM : Classification Model.
1.
Contexte et But du mémoire
Le domaine de reconnaissance de caractère est devenu aujourd‟hui l‟un des grands domaines dans lesquels travaillent de plus en plus de chercheurs. Le but des chercheurs dans ce domaine est de trouver des algorithmes pouvant résoudre sur ordinateur les problèmes de reconnaissance de caractère qui sont intuitivement résolus par les êtres humains .
Les ordinateurs séquentiels sont très performants pour les calculs, ils peuvent exécuter des opérations complexes plus vite que le cerveau humain. En reconnaissance de caractère, ce dernier est capable d‟analyser une scène très complexe instantanément, alors que le meilleur des algorithmes de reconnaissance de caractère ne pourrait reconnaître que des caractères relativement simples.
La reconnaissance de caractère manuscrite par ordinateur est du domaine de la fiction pour quelques années encore surtout pour la langue arabe. Tous les chercheurs sont confrontés à un problème difficile et incontournable, celui delà d'extraction de l'information.
L‟objectif de ce mémoire est de proposer un système de reconnaissance de caractère manuscrite arabe hors-ligne. Ce système s‟appuie sur la méthode de réseaux de neurones dans la phase d‟extraction des caractéristiques et les Machines à Vecteurs de Support (SVM) dans la phase de classification.
2.
Plan de travail
Ce mémoire s‟articule autour de cinq (05) chapitres, comme suit :
Dans le chapitre1, nous avons définies quelque notions de reconnaissance et nous avons présenté un rapport contient une description du problème de reconnaissance de caractère manuscrits, ainsi queles différentes approches existantes pour la reconnaissance.
Puis dans le chapitre 2, nous introduisons la technique des réseaux de neurones avec toutes ses notions de base. On y trouve une description de l‟architecture générale d‟un réseau et de son mode de fonctionnement, et en particulier pour un perceptron et un réseau multicouches. Ensuite, on y présente les différentes étapes de mise en œuvre d‟un réseau de neurones.
Au niveau du chapitre 3 on va mettre l'accent sur la méthode de classification choisie, par l'étude de la méthode de Machines à Vecteurs de Support (SVM).
Dans le chapitre 4, l'étude de la méthode NEURO-SVM.
Au niveau du chapitre 5 baptisé Application et Résultats, nous présentons notre application de reconnaissance de caractère. On y présente d‟abord les techniques utilisées pour l‟acquisition des images et l‟extraction des attributs. On y décrit ensuite le réseau de neurones utilisé, la Machines à Vecteurs de Support et en fin la discussion des résultats obtenu
Chapitre I
1. Introduction
Les recherches sur la reconnaissance des caractères Arabes exposent un domaine qui s‟étend rapidement et indéfiniment évoquées par une place aussi importante dans les deux dernières décennies. C‟est ainsi que la reconnaissance des caractères Arabes constitue aujourd‟hui une préoccupation dont la pertinence est incontestée par la communauté de chercheurs qui ont dévoués leurs efforts à réduire les contraintes et à élargir le royaume de la reconnaissance des caractères Arabes.
Un système de reconnaissance de l‟écriture doit idéalement, localiser, reconnaître et interpréter n‟importe quel texte ou nombre écrit sur un support de qualité arbitrairement variable tel que des cartes, des formulaires, des agendas, des vieux manuscrits, etc.
Parmi les domaines d‟application, on trouve le domaine postal pour la reconnaissance du code, de l‟adresse postale et la lecture automatique des chèques bancaires; le domaine administratif pour la gestion électronique des flux de documents; les bibliothèques numériques pour l‟indexation de documents et la recherche d‟informations; la biométrie pour l‟identification du scripteur…etc.
2.
Caractéristiques de l’écriture Arabe
L‟écriture arabe possède des caractéristiques différentes d‟autres langues en structure et en mode de liaison entre les caractères formant un mot, ce qui rend l‟application de reconnaissance délicate pour leur reconnaissance [1].
La plupart des lettres s‟attachent entre elles.
Les caractères arabes ne possédant pas une taille fixe (hauteur et largeur). Six lettres ne s‟attachent jamais à la letter suivante : " ذ","د" ,"ر" ,"ز","أ et "
" و ".
Dans l‟alphabet arabe, 15 lettres parmi les 28 possèdent un ou plusieurs points et dans des positions différentes.
3. Différents aspects de l'OCR (Optical Character Recognition)
Il n‟existe pas de système universel d‟OCR mais plutôt des voies d‟approches dépendant du type de données traitées et bien sûr de l‟application visée. Nous allons donner, dans la suite, quelques caractéristiques des systèmes d‟OCR [2]. Il existe plusieurs modes de classification des systèmes OCR parmi lesquels on peut citer :
Les systèmes qualifiés de « en-ligne » ou « hors-ligne » suivant le mode d‟acquisition.
Les approches globales ou analytiques selon que l‟analyse s‟opère sur la totalité du mot ou par segmentation en caractères.
Les approches statistiques, structurelles ou stochastiques relatives aux traits caractéristiques extraits des formes considérées.
3.1 Reconnaissance En ligne et Hors ligne
Ce sont deux modes différents d'OCR, ayant chacun ses propres outils d'acquisition et ses algorithmes correspondants de reconnaissance.
Nombre de
points
Un point
diacritique
Trois points
diacritiques
Deux points
diacritiques
ض ف غ خ ج
ظ ز ب ن ذ
ي ق ت
ث ش
3.1.1 Reconnaissance En ligne (on-line)
Ce mode de reconnaissance s'opère en temps réel (pendant l'écriture). Les symboles sont reconnus au fur et à mesure qu'ils sont écrits à la main.
Ce mode est réservé généralement à l'écriture manuscrite, c'est une approche «signal» où reconnaissance est effectuée sur des données à une dimension. L'écriture est représentée comme un ensemble de points dont les coordonnées sont en fonction du temps [3].
3.1.2 Reconnaissance hors-ligne (off - line)
Elle démarre après l'acquisition, elle convient aux documents imprimés et les manuscrits déjà rédigés. Ce mode peut être considéré comme le cas le plus général de la reconnaissance de l'écriture. Il se rapproche du mode de la reconnaissance visuelle. L'interprétation de l'information est indépendante de la source de génération [4].
La reconnaissance hors-ligne peut être classée en plusieurs types : Reconnaissance de texte ou analyse de documents
Dans le premier cas il s'agit de reconnaître un texte de structure limitée à quelques lignes ou mots. La recherche consiste en un simple repérage des mots dans les lignes, puis à un découpage de chaque mot en caractères [2].
Dans le second cas (analyse de document), il s'agit de données bien structurées dont la lecture nécessite la connaissance de la typographie et de la mise en page du document. La démarche n'est plus un simple prétraitement, mais une démarche experte d'analyse de document : il y a localisation des régions, séparation des régions graphiques et photographique, étiquetage sémantique des zones textuelles à partir de modèles, détermination de l'ordre de lecture et de la structure du document.
En ligne
La Reconnaissance hors ligne est plus difficile à cause de l‟absence d‟informations temporelles (Figure 1.3).
3.2 Reconnaissance de l’imprimé ou du manuscrit
L‟approche n‟est pas la même selon qu‟il s‟agisse de reconnaître un imprimé ou un manuscrit.
3.2.1Cas de l’imprimé
Les caractères imprimés sont dans le cas général alignés horizontalement et séparés verticalement, c‟est la phase de lecture [2]. La forme des caractères est définie par un style calligraphique (fonte) qui constitue un modèle pour l'identification. Dans le cas de l‟imprimé la reconnaissance peut être mono-fonte, multi-fonte ou omni-fonte [5]. Reconnaissance mono-fonte, multi-fonte et omni-fonte
Un système est dit mono-fonte s‟il ne traite qu‟une fonte à la fois, c‟est-à-dire que le système ne connaît l‟alphabet que dans une seule fonte. L‟apprentissage y est simple puisque l‟alphabet représenté est réduit.
Système est dit multi-fonte s‟il est capable de reconnaître un mélange de quelques fontes parmi un ensemble de fontes préalablement apprises. Dans ce cas, le prétraitement doit réduire les écarts entre les caractères (taille, épaisseur et inclinaison), l‟apprentissage doit gérer les ambiguïtés dues aux éventuelles ressemblances des caractères des différentes fontes et la reconnaissance doit identifier les subtiles différences entre ces caractères.
Un système est dit omni-fonte s‟il est capable de reconnaître toute fonte sans l‟avoir absolument apprise, ce qui relève actuellement du domaine de la recherche [5].
Imprimé Manuscrite
ميحرلا نمحرلا الله مسب
نيملاعلا بر لله دمحلا
ميحرلا نمحرلا
3.2.2 .Cas du manuscrit
Dans le cas du manuscrit, les caractères sont souvent ligaturés et leur graphisme est inégalement proportionné provenant de la variabilité intra et inter scripteurs. Cela nécessite généralement l'emploi de techniques de délimitation spécifiques et souvent des connaissances contextuelles pour guider la lecture [6].
Dans ce cas, la reconnaissance peut être mono-scripteur, multi-scripteur ou omni-scripteur. L'écriture manuscrite hors-ligne peut être classée en deux catégories d'écritures : écriture cursive et écriture semi-cursive.
Reconnaissance mono-scripteur, multi-scripteur et omni-scripteur Un système est dit Mono-scripteur (propres au scripteur) : lorsque le système ne peut reconnaître qu'une seule écriture. Tous ces éléments influent sur la forme des lettres (écriture penchée, bouclée, arrondie, linéaire, etc.) et bien sûr sur la forme des ligatures.
Compromettant parfois le repérage des limites entre lettres [7].
Un système est dit Multi-scripteur (propres à l'écriture manuscrite):lorsque le système peut identifier et reconnaître l'écriture pour un certain nombre de scripteurs [2]. Un système est dit Omni-scripteur (propres à n‟importe quelle écriture manuscrite): c‟est le fait de réduire l‟information contenue dans l‟image au minimum nécessaire pour modéliser précisément la structure des caractères. À proposer une méthode d‟appariement de deux graphes structurels quelconques qui permet de déterminer la meilleure ressemblance ou correspondance entre deux formes, tandis que la reconnaissance consiste à sélectionner ensuite le meilleur appariement réalisé parmi un alphabet de référence [7].
3.3 Approches de reconnaissance
Deux approches s'opposent en reconnaissance des mots : globale et analytique. 3.3.1 Approche globale
L'approche globale se base sur une description unique de l'image du mot, vue comme une entité indivisible. Disposant de beaucoup d'informations, en effet, la discrimination de mots proches est très difficile, et l'apprentissage des modèles nécessite une grande quantité d'échantillons qui est souvent difficile à réunir [8].
3.3.2 Approche analytique
L'approche analytique basée sur un découpage (segmentation) du mot. La difficulté d'une telle approche a été clairement évoquée par Sayre en 1973 et peut être
résumée par dilemme suivant : "pour reconnaître les lettres tracé, il faut reconnaître les lettres". Il s'ensuit qu'un processus de reconnaissance selon cette approche doit nécessairement se concevoir comme un processus de relaxation alternant les phases de segmentation et d'identification des segments. applicable dans le cas de grands vocabulaires [8]. Reconnaissance globale APR OCHE
OCR
Reconnaissance Analytique Statistique Structurelle Syntaxique Stochastique SYSTEM Hors-ligne En -ligne Mono-fonte Multi-fonte Omni-fonte Mono-scripteur Multi-scripteur Omni-scripteur Document Manuscrit Texte Imprimé Mono-scripteur Multi-scripteur Omni-scripteur4. Processus de reconnaissance
Un système de reconnaissance fait appel généralement aux étapes suivantes : Acquisition, prétraitement, segmentation, extraction des caractéristiques, classification, suivies éventuellement d'une phase de post - traitement. La figure ci-dessous résume tout le chemin d‟un procédé OCR.
Figure1.5: Schéma général du système de reconnaissance des caractères.
4.1. Phase d’acquisition
L'acquisition permettant la conversion du document papier sous la forme d'une image numérique (bitmap). Cette étape est importante car elle se préoccupe de la préparation des documents à saisir, du choix et du paramétrage de scanner, ainsi que du format de stockage des images [4].
Le document numérisé est rangé dans un fichier des points appelés pixels, dont la taille dépend de la résolution. La technicité des matériels d'acquisition a fait progrès ces dernières années [4].
4.1.1 Acquisition hors ligne
Dans le cas hors ligne, il s‟agit de reconnaître des textes manuscrits à partir de documents écrits au préalable. L‟image du texte écrit est numérisée à l‟aide d‟un
scanneur, les informations recueillies se présentent sous la forme d‟une image discrète constituée d‟un ensemble de pixels [9].
4.1.2 Acquisition en ligne
Dans le cas en ligne, il s‟agit de reconnaître l‟écriture au fur et à mesure de son tracé. Le texte est saisi avec un stylo et une tablette à numériser, les informations recueillies sont constituées par une suite ordonnée de points (définis par leurs coordonnées) échantillonnés à cadence fixe. La reconnaissance hors ligne ne peut pas a priori s‟appuyer sur l‟information temporelle du tracé qui est perdue, mais elle peut tenir compte de l‟épaisseur du tracé (les pleins et les déliés). La reconnaissance en ligne peut disposer de l‟information temporelle (vitesse, accélération, levés de stylo, retours en arrière, points diacritiques), mais d‟aucune information sur l‟épaisseur du tracé si on ne dispose pas d‟un signal de pression de la pointe du stylet sur le support [9].
4.1.3 Etape d’acquisition
Elle consiste en deux phases : a) L’échantillonnage
(numérisation) d‟une image est spatial par découpage en pixels. b) La quantification
(codage) c‟est une valeur numérique donnée à l‟intensité lumineuse, c‟est un niveau de gris appelé la dynamique de l‟image [3]. Cette dynamique est donnée comme suit : , où m est le nombre de bits. Par exemple : le niveau de gris 256 est codé sur 8 bits, l‟image couleur est codée sur 24 bits (1 octet pour chaque couleur(R, V, B)) [11].
4.2 Phase de prétraitement
Le prétraitement consiste à préparer les données issues du capteur à la phase suivante. Il s'agit essentiellement de réduire le bruit superposé aux données et essayer de ne garder que l'information significative de la forme représentée. Le bruit peut être dû aux conditions d'acquisition (éclairage, mise incorrecte du document, ...) ou encore à la qualité du document d'origine. Parmi les opérations de prétraitement généralement utilisées on peut citer : la binarisation, la dilatation, l‟érosion, la squelettisation et la normalisation (figure1.6).
4.2.1 Binarisation
La binarisation c'est le passage d'une image en couleur, définie par plusieurs niveaux de gris en image bitonale (composée de deux valeurs 0 et 1) qui permet une classification entre le fond (image du support papier en blanc) et la forme (traits des gravures et des caractères en noir). Plusieurs techniques ont été développées dans le but de transformer une image à niveaux de gris ou en couleur, en image binaire. Toutes ces techniques sont basées sur le principe de seuillage comme le montre l‟équation suivante
( ) { ( ) ( )
( ) Décrit l‟intensité à "n" niveaux de gris à chaque point de l‟image, ( )représente l‟intensité à deux niveaux et T est le seuil de binarisation. Si ( ) est supérieur à la valeur de seuil alors on attribut le point image correspondant à la valeur d‟intensité maximale (le blanc). Dans le cas contraire, le point est considéré comme noir et on lui attribue la valeur d‟intensité minimale [12].
Pour des images de niveaux de gris, on peut trouver dans [13] une liste des méthodes de binarisation, proposant des seuils adaptatifs (ex. s'adaptant à la différence de distribution des niveaux de gris). Les auteurs dans [14] proposent une solution pour les images d'adresses postales.
La recherche du seuil passe par plusieurs étapes : binarisation préliminaire basée sur une distribution de mixture multimodale, analyse de la texture à l'aide d'histogrammes de longueurs de traits, et sélection du seuil à partir d'un arbre de décision.
Binarisation Erosion
Dilatation Squelettisation
Normalisation
Figure1.7: Exemple de la binarisation [10]. 4.2.2 Transformation par érosion
Si un pixel „p‟ est noir( ( ) ), et il y a au moins 3 pixels, ou 7 pixels dans les 4- voisins, ou les 8-voisins respectivement, qui sont blancs( ( ) ), alors on affecte à ce pixel la couleur blanche( ( ) ), c-à-d. on efface ce pixel, (C'est un lissage d‟un ou deux pixels d‟une forme connexe) [12].
4.2.3 Transformation par dilatation
C‟est l‟inverse de la transformation par érosion, si un pixel „p‟ est blanc ( ( ) ) et il y a au moins 3 pixels, ou 7 pixels dans les 4-voisins, ou les 8-voisins respectivement, qui sont noir( ( ) ), alors on affecte à ce pixel la couleur noir( ( ) ).
4.2.4 Ouverture morphologique
C'est une combinaison d'opérations : érosion suivie d'une dilatation d'une image par le même élément structurant. Servant à adoucir les contours, simplifier les formes en lissant les bosses tout en conservant l‟allure globale [12].
4.2.5 Fermeture morphologique
C'est le contraire de l‟ouverture, elle consiste en une combinaison d'opérations : une dilatation suivie d'érosion d'une image par le même élément structurant. Elle permet de simplifier les formes, en comblant les creux.
4.2.6 Squelettisation d'une image
Très utilisée dans le domaine de la „reconnaissance des formes‟, cette opération consiste à transformer une image binaire en un „squelette‟. Le squelette est un ensemble de lignes d‟épaisseurs infiniment petites. La squelettisation doit préserver la connexité de l‟image. En d‟autres termes, cette opération ne doit ni séparer les éléments connexes,
ni raccorder les éléments non connexes. Le but est de simplifier l'image du caractère en une image à « ligne » plus facile à traiter en la réduisant au tracé du caractère [15].
Il existe plusieurs techniques de squelettisation parmi celle-ci nous citons une technique de suivi appelée semi-squelettisation. Cette technique est basée sur la détection pour chaque colonne de pixels: les points de début, milieu et fin du tracé de l'écriture (figure 1.8)
Figure1.8: Technique de semi-squelettisation [16].
Les points de milieu extraits sont utilisés pour calculer au cours du balayage la longueur et l'angle de déviation du segment en cours de traitement tandis que les points d'extrémités sont utilisés pour extraire des informations sur la forme du segment [16].
4.2.7 Normalisation
L‟étude de discernement nécessite l‟élimination des conditions qui peuvent fausser les résultats, comme la différence de taille. Il faut donc aboutir à la normalisation de la taille des caractères. Après cette opération, les images de tous les caractères se retrouvent définies dans une matrice de même taille, pour faciliter les traitements ultérieurs. Cette opération introduit généralement de légères déformations
Points de fin
Points de milieu Points de début
sur les images. Cependant certains traits caractéristiques tels que la hampe dans des caractères ( ط ظ ل ا par exemple) peuvent être éliminées à la suite de la normalisation, ce qui peut entraîner à des confusions entre certains caractères [17]. Une application doit être définie pour effectuer cette tâche. Cette application doit être réversible pour pouvoir aller d‟une taille à une autre et revenir par la suite.
. ( ) ( ). G est défini de la façon suivante :
{ ( ) ( ) ( )
Tel que :
µ1 = (largeur du cadre du caractère)/ (largeur du cadre de la normalisation). µ2 = (hauteur du cadre du caractère)/ (hauteur du cadre de la normalisation). 4.2.8 Suppression du bruit
Consiste à détecter et à éliminer les pixels qui représentent des bruits. Il s'agit d'éliminer plus de bruit que d'information signifiante afin d'augmenter la discrimination.
Figure1.10: Exemple de Suppression du bruit. 4.3Phase de segmentation
La segmentation est une opération appliquée à l‟image qui consiste à subdiviser une scène réelle, en parties constituantes ou objets, en projetant une scène réelle sur un plan. Elle est la première opération à réaliser dans « la reconnaissance des formes ». Il faut donc, disposer d‟un certains nombres d‟attributs, représentatifs des régions que l‟on cherche à extraire, pour procéder à la classification individuelle des points [9].
4.3.1 Techniques de la segmentation
première, connue sous le nom de segmentation implicite, et la deuxième c‟est la segmentation explicite.
a- Segmentation implicite
Les méthodes de segmentation implicite s‟inspirent des approches utilisées dans le domaine de la parole, où le signal est divisé en intervalles de temps réguliers, et procèdent à une sur-segmentation importante de l‟image du mot à pas fixe (un ou quelques pixels). Cela permet d‟assurer un taux de présence important des points de liaison entre lettres considérées. La segmentation s‟effectue pendant la reconnaissance qui assure son guide. Le système recherche dans l‟image, des composantes ou des groupements de graphèmes1 qui correspondent à ses classes de lettres [18].
Classiquement, il peut le faire de deux manières :
soit par fenêtrage: le principe est d‟utiliser une fenêtre mobile de largeur variable (qui n‟est pas facile à déterminer) pour trouver des séquences de points de segmentation potentiels qui seront confirmés ou non par la reconnaissance de caractères. Elle nécessite deux étapes : la génération d‟hypothèses de segmentation (séquences de points obtenus par le fenêtrage) ;la deuxième est le choix de la meilleure hypothèse de la reconnaissance (validation).
soit par recherche de primitives: il s‟agit de détecter les combinaisons de primitives qui donneront la meilleure reconnaissance.
b- Segmentation explicite
Cette approche, souvent appelée dissection, est antérieure à la reconnaissance et n‟est pas remise en cause pendant la phase de reconnaissance. Les hypothèses des caractères sont déterminées à partir des informations de bas niveau présentes sur l‟image. Ces hypothèses sont définitives, et doivent être d‟une grande fiabilité car la moindre erreur de segmentation remet en cause la totalité des traitements ultérieurs.
Les approches de segmentation explicite, s‟appuient sur une analyse morphologique du mot manuscrit pour localiser des points de segmentation potentiels. Elles sont particulièrement adaptées à l‟analyse de la représentation bidimensionnelle et donc plus souvent utilisées dans les systèmes de reconnaissance hors-ligne de mots. Certaines méthodes de segmentation explicite sont basées sur une analyse par
morphologiques mathématiques, exploitent les concepts de régularité et singularité du tracé, analyse des contours supérieurs/inferieurs du mot. Les points de segmentation potentiels détectés sont confirmés à l‟aide de diverses heuristiques [18].
4.4 Phase d’extraction des caractéristiques
C'est l'une des étapes les plus délicates et les plus importantes en OCR. Les types des caractéristiques peuvent être classés en trois groupes principaux : caractéristiques structurelles, caractéristiques statistiques et transformations globales [19] [3].
4.4.1 Caractéristiques structurelles
Les caractéristiques structurelles décrivent une forme en termes de sa topologie et sa géométrie en donnant ses propriétés globales et locales. Parmi ces caractéristiques on peut citer :
Les traits et les anses dans les différentes directions ainsi que leurs tailles. Les points terminaux.
Les points d'intersections. Les boucles.
Le nombre de points diacritiques et leur position par rapport à la ligne de base. Les voyellations et les zigzags (hamza).
La hauteur et la largeur du caractère.
La catégorie de la forme (partie primaire ou point diacritique, etc).
Plusieurs autres caractéristiques peuvent être tirées, suivant qu'ils soient extraites d'une courbe, un trait ou d‟un segment de contour.
4.4.2 Caractéristiques statistiques
Les caractéristiques statistiques décrivent une forme en termes d‟un ensemble de mesures extraites à partir de cette forme. Les caractéristiques utilisées pour la reconnaissance de textes arabes sont: le zonage (zonning) et les caractéristiques de lieu géométrique (Loci) [19]. Le zonage consiste à superposer une grille (n×m) sur l'image du caractère et calculer pour chacune des régions résultantes, la moyenne ou le pourcentage de points en niveaux de gris, donnant ainsi un vecteur de taille (n×m) de caractéristiques. La méthode Loci est basée sur le calcul du nombre de segments blancs et de segments noirs le long d'une ligne verticale traversant la forme, ainsi que leurs longueurs [3].
4.4.3 Transformations globales
Elles sont naturellement basées sur une transformation globale de l'image. La transformation consiste à convertir la représentation en pixels en une représentation plus abstraite pour réduire la dimension des caractères, tout en conservant le maximum d'informations sur la forme à reconnaître. Par exemple : la transformée de Hough, la transformée de Fourier, et les moments de Zernike [18]
4.5 Phase de classification
La classification dans un système OCR regroupe deux tâches : l'apprentissage et la reconnaissance (décision). A cette étape les caractéristiques de l'étape précédente sont utilisées pour identifier un caractère et l'attribuer à un modèle de référence [20].
4.5.1 Méthodes de reconnaissances
Les méthodes de classification ont pour but d‟identifier les classes auxquelles appartiennent des objets à partir de certains paramètres descriptifs.
Elles s‟appliquent à un grand nombre d‟activités humaines et conviennent en particulier au problème de la prise de décision automatisée. La procédure de classification sera extraite automatiquement à partir d‟un ensemble d‟exemples. Un exemple consiste en la description d‟un cas avec la classification correspondante. Un système d‟apprentissage doit alors, à partir de cet ensemble d‟exemples, extraire une procédure de classification, il s‟agit en effet d‟extraire une règle générale à partir des données observées. La procédure générée devra classifier correctement les exemples de l‟échantillon et avoir un bon pouvoir prédictif pour classifier correctement de nouvelles descriptions. Parmi les méthodes qui ont été développées dans ce contexte (machine d'apprentissage), nous distinguons par exemple les réseaux de neurones et les machines à vecteurs du support (SVM : Support Vector Machines, en anglais) [21].
4.5.1.1 Réseaux de neurones
Un réseau de neurones est un assemblage de neurones connectés entre eux. Un réseau réalise une ou plusieurs fonctions algébriques de ses entrées, par composition des fonctions réalisées par chacun des neurones. La capacité de traitement de ce réseau est stockée sous forme de poids d'interconnexions obtenus par un processus d'apprentissage à partir d'un ensemble d'exemples d'apprentissage, Il arrive souvent que les exemples de la base d'apprentissage comportent des valeurs approximatives ou bruitées. Si on oblige le réseau à répondre de façon quasi parfaite relativement à ces exemples, on peut obtenir un réseau qui est biaisé par des valeurs erronées [22].
4.5.1.2 Machines à Vecteur de Support (Support Vector Machine)
Ces méthodes sont des classifiant à deux classes introduites par le mathématicien « Vladimir Vapnik » qui possèdent une grande capacité de généralisation. Les SVMs sont un ensemble d‟algorithmes d‟apprentissage qui permettent de discriminer les formes. Les SVMs sont des modèles discriminants qui tentent de minimiser les erreurs d‟apprentissage tout en maximisant la marge entre classes, c‟est- à-dire l‟espace sans exemple autour de la frontière de décision. Pour cela l‟algorithme d‟apprentissage sélectionne judicieusement un certain nombre de "vecteurs support" parmi les exemples de la base d‟apprentissage, qui définissent la frontière de décision optimale [23].
4.5.2 Apprentissage
Dans le cas d‟apprentissage il s‟agit en fait de fournir au système un ensemble de formes qui sont déjà connues (on connaît la classe de chacune d‟elles). C‟est cet ensemble d‟apprentissage qui va permettre de ≪ régler ≫ le système de reconnaissance de façon à ce qu‟il soit capable de reconnaître ultérieurement des formes de classes inconnues. Il existe deux types d‟apprentissage, supervisé et non supervisé [24].
4.5.2.1 Apprentissage supervisé
L‟apprentissage est dit supervisé si les différentes familles des formes sont connues a priori et si la tâche d‟apprentissage est guidée par un superviseur ou professeur, c'est-à-dire le concepteur, indique, pour chaque forme échantillon rentrée, le nom de la famille qui la contient. La tâche d‟apprentissage tente de conserver ses liens de parenté en répartissant les familles dans des classes séparées entre elles [25].
4.5.2.2 Apprentissage non supervisé
L‟apprentissage non supervisé ou sans professeur consiste à doter le système d‟un mécanisme automatique qui s‟appuie sur des règles précises de regroupement pour trouver les classes de référence avec une assistance minimale. Dans ce cas les échantillons sont introduits en un grand nombre par l‟utilisateur sans indiquer leur classe [25].
4.5.3 Reconnaissance et décision
La décision est l'ultime étape de reconnaissance. A partir de la description en paramètres du caractère traité, le module de reconnaissance cherche parmi les modèles de référence en présence, ceux qui lui sont les plus proches.
La reconnaissance peut conduire à un succès si la réponse est unique (un seul modèle répond à la description de la forme du caractère). Elle peut conduire à une
Chapitre I: OCR
confusion si la réponse est multiple (plusieurs modèles correspondent à la description). Enfin elle peut conduire à un rejet de la forme si aucun modèle ne correspond à sa description. Dans les deux premiers cas, la décision peut être accompagnée d‟une mesure de vraisemblance, appelée aussi score ou taux de reconnaissance [25].
4.6 Phase de post-traitement
L‟objectif du post-traitement est l‟amélioration du taux de reconnaissance des mots (par opposition au taux de reconnaissance du caractère). Cette phase est souvent implémentée comme un ensemble d‟outils relatifs à la fréquence d‟apparition des caractères dans une chaîne, aux lexiques et à d‟autres informations contextuelles. Comme la classification peut aboutir à plusieurs candidats possibles, le post traitement a pour objet d‟opérer une sélection de la solution en utilisant des niveaux d‟informations plus élevés (syntaxiques, lexicale, sémantiques…). Le post-traitement se charge également de vérifier si la réponse est correcte (même si elle est unique) en se basant sur d‟autres informations non disponibles au classifieur.
5. Conclusion
Nous avons présenté dans ce chapitre les différents problèmes à résoudre dans un système de reconnaissance de l‟écriture, ainsi que les techniques pouvant être utilisées. Il s‟agit premièrement d‟obtenir une base de données comportant des exemples de chaque caractère, puis de passer par une phase de prétraitement qui comporte une normalisation de chaque caractère, puis une extraction des attributs. La
Chapitre II
1.
Introduction
Un réseau de neurones est un processus distribué de manière massivement parallèle, qui a une propension naturelle à mémoriser des connaissances de façon expérimentale et de les rendre disponibles pour utilisation.
Les réseaux de neurones sont la réplique des neurones biologique c'est-à-dire les neurones qui existent en vous et moi. Un ensemble de cellules sont inter connectées d‟une manière à répondre d‟une manière bien spécifique à une excitation [5].
On recense aujourd‟hui des applications des réseaux de neurones dans des domaines très variés : la reconnaissance de caractères manuscrits, la robotique, la reconnaissance de paroles, etc. Toutes ces tâches ont un point en commun : elles sont complexes à modéliser, elles ne requièrent pas une solution unique et exacte, mais plutôt une estimation de la réponse la plus plausible, et enfin elles opèrent sur des données incertaines, toujours entachées de bruit .
Une approche par réseaux de neurones permet d‟esquisser des réponses à ces problèmes, en réduisant beaucoup le temps consacré par des ingénieurs à leur analyse .
Nous aborderons dans ce chapitre un résumé sur les réseaux de neurones et surtout les modèles des réseaux que nous utilisons dans notre application.
2.
Historique
Les premiers travaux sur les neurones artificiels ont débuté au début des années 1940 et ont été menés par McCulloch et Pitts. Ils décrivent les propriétés du système nerveux à partir de neurones idéalisés : ce sont des neurones logiques (0 ou 1).
Dix années plus tard, on a constitué le premier modèle réel d‟un réseau de neurones. En 1960, le premier perceptron est créé par Rosenblatt. Puis, durant les années 1970 il y eut une remise en cause de l‟intérêt des réseaux car les ordinateurs de neurones apprenaient lentement, coûtaient très cher et leurs performances n‟étaient pas si impressionnantes. La disponibilité croissante des minis et microordinateurs, vers la fin des années 1970, a permis aux réseaux de neurones de rendre un nouveau départ [27].
3.
Mise en œuvre des Réseaux de Neurones
Le principe de fonctionnement de réseau de neurone se base sur un modèle neuronique former d‟un grand nombre de cellules élémentaires appelées « neurone » son fonctionnement est fondé sur celui d‟un automate proposé comme une
approximation de fonctionnement de neurones biologique. Il convient pour les données linéairement séparables [17].
3.1. Le neurone biologique
Le neurone est une cellule vivante, qui peut prendre des formes variables. Il contient :
Un corps cellulaire, qui joue le rôle d‟un sommateur à seuil. Il effectue une sommation des influx nerveux par ses dendrites ; si la somme est supérieure à un seuil donné, le neurone répond par un flux nerveux ou potentiel d‟action qui se propage le long de son axone ; si la somme est inférieure au seuil, il reste inactif.
Des prolongements qui reçoivent les signaux en provenance d‟autres cellules. Ce sont les dendrites.
Un prolongement unique, appelé axone, diffuse le signal du neurone vers d‟autres cellules.
Un élément de jonction, appelé synapse qui permet aux cellules de communiquer entre elles, de plus il joue un rôle dans la modulation des signaux qui transitent le système nerveux [ 26].
3.2. Les neurones artificiels
La première étude systématique du neurone artificiel est due au neuropsychiatre McCulloch et au logicien Pitts qui, s‟inspirant de leurs travaux sur les neurones biologiques. Proposèrent en 1943 le modèle illustré à la figure 2.2.
Ce neurone formel est un processeur élémentaire qui réalise une somme pondérée des signaux qui lui par viennent. La valeur de cette sommation est ensuite comparée à un seuil et la sortie du neurone est:
∑ ( )
(Eq 2. 1) ( ) (Eq 2. 2)
Tel que :
: Les entrées du neurone formel.
y : sa sortie.
wj : Les paramètres de pondération(les poids). : La fonction d‟activation.
Ө : seuil.
Dans le modèle original de McCulloch et Pitts, la non linéarité était assurée par la fonction seuil d‟Heaviside « figure 2.3 », définie par :
( ) {
En place de la fonction d‟Heaviside, il est également possible de choisir la fonction de signe « figure 2.4 », définie comme suit :
( ) {
4.
La modélisation des neurones
La modélisation du système nerveux biologique repose sur la correspondance suivante:
Nerveux biologique RNA
Dendrite Fonction de combinaison
Corps du neurone Fonction de transfert
Axone Elément de sortie
Synapse Poids
Tableau 2.1: Comparaison entre le nerveux biologique et artificiel.
5.
Architectures des réseaux de neurones
Plusieurs architectures des réseaux existent, on peut citer : 5.1. Réseau multicouche
Les neurones sont arrangés par couche« figure 2.5 ». On place ensuite bout à bout plusieurs couches et l‟on connecte les neurones de deux couches adjacentes. Les
Figure 2.3: La fonction d’Heaviside.
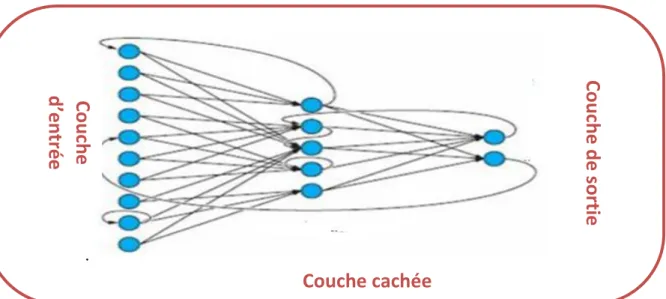
entrées des neurones de la deuxième couche sont en fait les sorties des neurones de la couche amont. Les neurones de la première couche sont reliés au monde extérieur et reçoivent le vecteur d‟entrée. Ils calculent alors leurs sorties qui sont transmises aux neurones de la seconde couche qui calculent eux aussi leurs sorties et ainsi de suite de couche en couche jusqu‟à celle de sortie. Il peut y avoir une ou plusieurs sorties à un réseau de neurones. Dans un réseau multicouche classique, il n‟y a pas de connexion entre neurones d‟une même couche et les connexions ne se font qu‟avec les neurones de la couche aval. Tous les neurones de la couche amont sont connectés à tous les neurones de la couche aval [30].
.
Les couches extérieures du réseau sont appelées respectivement couches d‟entrée et de sortie; les couches intermédiaires sont appelées couches cachées.
5.2. Réseau à connexions locales
C‟est aussi un réseau multicouche, mais tous les neurones d‟une couche amont ne sont pas connectés à tous les neurones de la couche aval «figure 2.6 ». Nous avons donc dans ce type de réseau de neurones un nombre de connexions moins important que dans le cas du réseau de neurones multicouche classique [29].
5.3. Réseau à connexions récurrentes
Un réseau de ce type signifie qu‟une ou plusieurs sorties de neurones d‟une couche aval sont connectées aux entrées des neurones de la couche amont ou de la même couche. Ces connexions récurrentes ramènent l‟information en arrière par rapport au sens de propagation défini dans un réseau multicouche « figure 2.7»
.
Les réseaux à connexions récurrentes sont des réseaux plus puissants car ils sont séquentiels plutôt que combinatoires comme l‟étaient ceux décrits précédemment. La rétroaction de la sortie vers l‟entrée permet à un réseau de ce type de présenter un comportement temporel [29].
Couche de
sortie
Couc
h
e
d’en
tr
ée
Couc
h
e
d’en
tr
ée
Couche cachée
Couc
h
e de
so
rt
ie
Couche Cachée
Figure 2.6: Réseau multicouche à connexions locales.
5.4. Réseau à connexions complexes
Chaque neurone est connecté à tous les neurones du réseau y compris lui-même, c‟est la structure d‟interconnexion la plus générale «figure 2.8».
6. Les réseaux les plus célèbres
Il y a de très nombreuses sortes de réseaux de neurones actuellement. Personnenesait exactement combien. De nouveau (ou du moins des variations de réseaux plus anciens) sont inventés chaque semaine. On en présente ici de très classiques [30].
6.1. Le perceptron
C‟est historiquement le premier réseau de neurone artificiel .C‟est un réseau de neurones très simple avec deux couches de neurones acceptant seulement des valeurs d‟entrées et de sorties binaires. Le procédé d‟apprentissage est supervisé et le réseau est capable de résoudre des opérations logiques simples: somme, AND ou OR. Il est aussi utilisé pour la classification. Sa principale limite est qu‟il ne peut résoudre des problèmes linéairement séparables [24].
6.2. Le modèle ADALINE
L‟ADALINE (ADAptatif LINéaire Elément) conçu par B.Widrow dans les années1960, est un perceptron sans couche cachée donc à un seul neurone qui reçoit le stimulus arrivant de la couche d‟entrée et donne la réponse correspondante.
6.3. Perceptron Multi-Couches
Les Perceptrons Multi-Couches (PMC) sont les réseaux de neurones les plus courants et les plus simples. Ils sont très largement utilisés en classification et en reconnaissance de caractère, notamment pour leurs bonnes performances et leur simplicité.
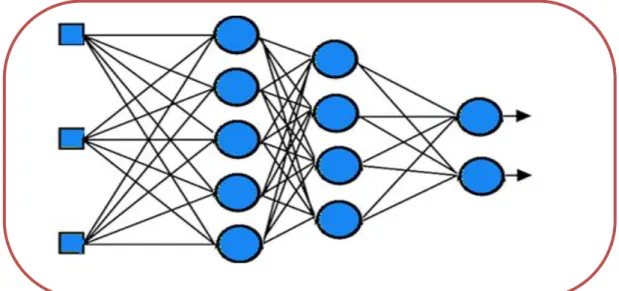
Le PMC est une extension du précédent Perceptron, avec une ou plusieurs couches cachées entre l'entrée et la sortie, donc un PMC possède trois types de couches: une couche d‟entrée, une ou plusieurs couches cachées et une couche de sortie. Chaque neurone d‟une couche est connecté à tous les neurones de la couche qui le précède, ce qui donne un réseau complètement connecté. Le schéma donné dans la figure 2.10 représente un PMC à trois couches, la couche d‟entrée, la couche cachée et enfin la couche de sortie. En particulier le nombre de couches et le nombre de cellules par couche cachées qui dépend principalement du problème étudié [29].
Dans cette application, nous mettons en œuvre un réseau de neurones multicouche avec une seule couche cachée (qui est un classificateur universel) dont la structure et le fonctionnement est décrit dans ce qui suit.
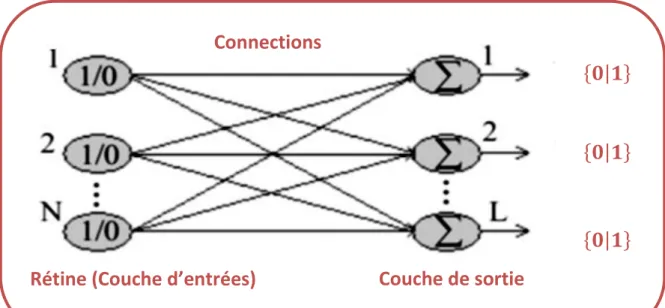
Connections
Rétine (Couche d’entrées)
Couche de sortie
*𝟎 𝟏+
*𝟎 𝟏+
*𝟎 𝟏+
6.3.1. La couche d’entrée
Le nombre de neurone de cette couche dépend du nombre de paramètres que peut générer chaque méthode d‟extraction des caractéristiques.
6.3.2. La couche cachée
Le nombre de neurones de cette couche est choisi après plusieurs essais. Le meilleur nombre étant celui qui donne le meilleur résultat dans le sens du pourcentage de reconnaissance.
6.3.3. La couche de sortie
Le nombre de neurones de sortie est dicté par le nombre de situation à séparer.
7. Apprentissage
Le principal problème pour les réseaux de neurones est d‟arriver à trouver un ensemble de valeurs les synapses (poids),qui sont les porteurs de l‟information, tel que les configurations d‟entée se traduisent par les réponses voulues, et cela en partant d‟une valeur particulière des poids des connections, le réseau améliore ces réponses en ajustant ses coefficients selon un algorithme ou une règle d‟apprentissage. Il existe trois classes d‟apprentissage : l‟apprentissage supervisé, l‟apprentissage non supervisé et l‟apprentissage hybride qui est une combinaison des deux premiers [23] [31].
Couc
he d’
entré
e
Couche cachée
Couc
h
e de
so
rt
ie
7.1. Les type d'apprentissage des réseaux de neurones a) Apprentissage supervisé
Lorsqu‟on dispose d‟un ensemble de données dont on connaît la classe d‟appartenance apriori (c‟est le cas de notre problème). Il s‟agit alors de chercher les sur faces de décision séparant au mieux les classes. La base d‟apprentissage est donc constituée des données et de la réponse que l‟on désire de la part du réseau. On calcul généralement une erreur entre la réponse du réseau et la réponse désirée. On modifie les paramètres du réseau de façon à réduire cette erreur [23].
b) Apprentissage non supervisé (auto- organisation)
Lorsqu‟on dispose d‟une base de données sans connaître leur classe d‟appartenance. Il s‟agit de découvrir la structure sous-jacente aux données sans imposer aucun modèle [24].
c) Apprentissages hybride
Plus rare cette approche combine méthodes numérique et méthodes symboliques. Certains auteurs, utilisent le terme d‟apprentissage hybride pour parle d‟un couplage supervise, non supervise ; dans ce cas il s‟agit d‟un réseau qui met en parallèle ou en série un entraine en mode supervise et un autre mode non supervise.
Dans notre application, nous consistons sur la apprentissage supervisé qui consiste à réduire progressivement la différence entre les valeurs de sortie désirée et les valeurs des sorties du réseau.
7.2. Règles d’apprentissages 7.2.1. La règle de Hebb
Dans le domaine de la recherche sur le fonctionnement des neurones biologiques et sur les mécanismes d‟apprentissage de l‟intelligence humaine, Hebb a proposé un type de réseau de neurones totalement interconnecté (c'est–à-dire ou les neurones sont reliés par des connexions de types synapse fonctionnant à la fois en « entrée » et en « Sortie ». Ces connexions sont affectées de poids qui évoluent au cours du temps et en fonction de l‟activation de chacun des deux neurones extrémités de cette connexion. Il a ainsi défini une règle d‟apprentissage dite de Hebb :
Cette règle considère alors que toute connexion entre deux neurones se renforce si ces deux neurones sont actifs au même moment. Si on note A1 et A2 l‟activation des neurones 1 et 2 et si on suppose qu‟un neurone actif à son activation qui vaut 1 et qu‟un neurone inactif son activation qui vaut 0 alors l‟expression de la règle de Hebb est la suivante :
( ) ( ) . (Eq 2. 3) Au départ on a ( ) pour tout i, j.
Ce type de réseaux a surtout une vocation pour la modélisation des neurones biologiques et reste peu utilisé en reconnaissance des formes. Un des inconvénients majeurs de ce modèle vient du fait que les ne peuvent qu‟augmenter au cours du temps [27].
7.2.1. La règle de Widrow-Hoff
La règle de Widrow-Hoff ou règle delta proposée en 1960, consiste à modifier chaque pas, les poids et les biais afin de minimiser la somme des carrées des erreurs en sortie en utilisant la règle suivante :
( ) ( ) (
)
(Eq 2. 4)A chaque pas d‟apprentissage k , l‟erreur en sortie est calculée comme la différence entre la cible recherché t et la sortie y du réseaux
∑ ( ) ( ) ( ) ( )(E2. 5)
Le gradient se calcule comme suite :
,
-
(Eq 2. 6).
(Eq 2. 7)D‟après l‟expression de et avec
les dérivées partielles sont :
![Figure 2.1: Simplification d'un neurone biologique [28].](https://thumb-eu.123doks.com/thumbv2/123doknet/2318895.28539/40.892.162.786.588.928/figure-simplification-d-un-neurone-biologique.webp)