Image search, Match the fastener
Texte intégral
Figure




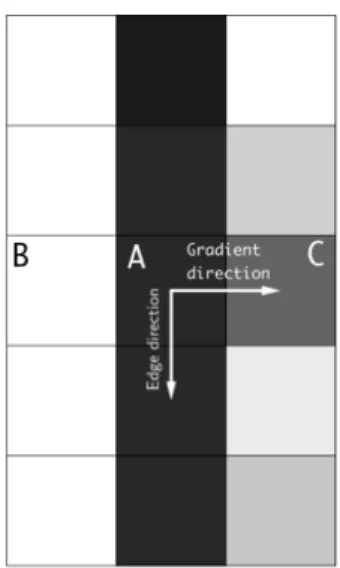


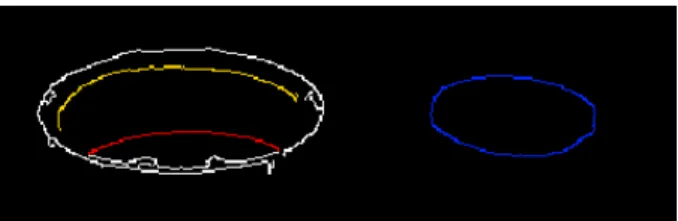

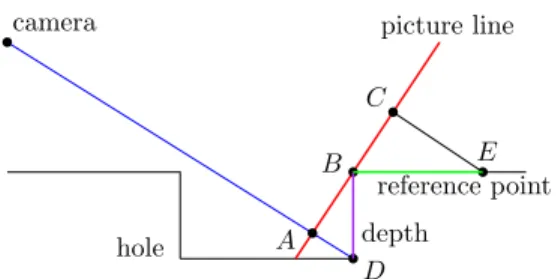
Documents relatifs
As part of their commitment to topicality, one of the fundamental premises of the Victorian illustrated press, The Graphic (1869-1932) and The Illustrated London
We will cover the section Darboux’s construction of Riemann’s integral in one variable faster than usual since you already know its material from MAT137. It will be easier if you
i) We need two image charges, one for each one of the real charges producing the constant external electric field.. The first term is just the potential due to the external field
Measure each segment in inches.. ©X k2v0G1615 AK7uHtpa6 tS7offStPw9aJr4e4 ULpLaCc.5 H dAylWlN yrtilgMh4tcs7 UrqersaezrrvHe9dK.L i jMqacdreJ ywJiZtYhg
Measure each segment in centimeters.. ©c i2Q0y1N1P nK8urtPal kS3oIfLtRwEa0rmeH 6LxLMCm.o m fAAlQla WrqiNgEhxtts4 drUeOsEeir6vje1dV.J U 0MzavdEeD ewDiRtehI
Finally, the results for Sub-Saharan Africa (SSA), the differences in the perception of corruption in this region are explained by freedom of the press, burden
Videotaped lessons of a model on energy chain, from two French 5 th grade classes with the same teacher, were analysed in order to assess the percentage of stability as
To go further, we propose to infer from the low-level visual features contextual information such that the dominant depth and position of the horizon line (if any):.. Dominant
