Une plateforme d'orchestration de conteneurs Docker tolérante aux fautes byzantines
101
0
0
Texte intégral
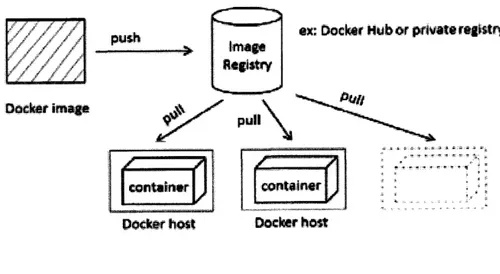
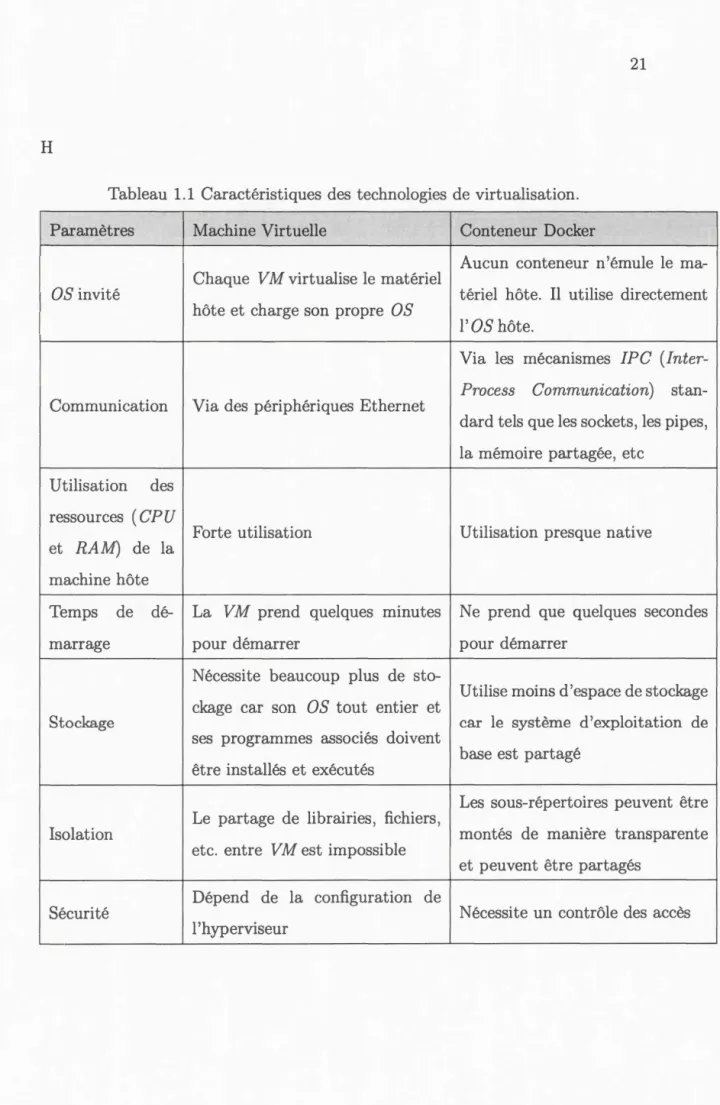
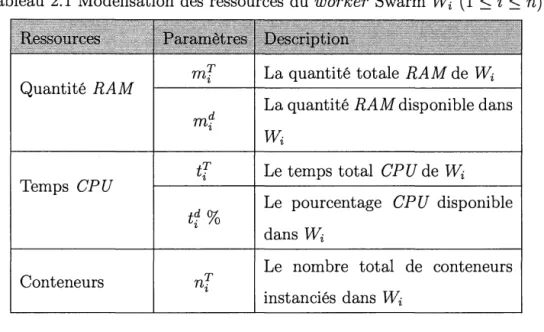
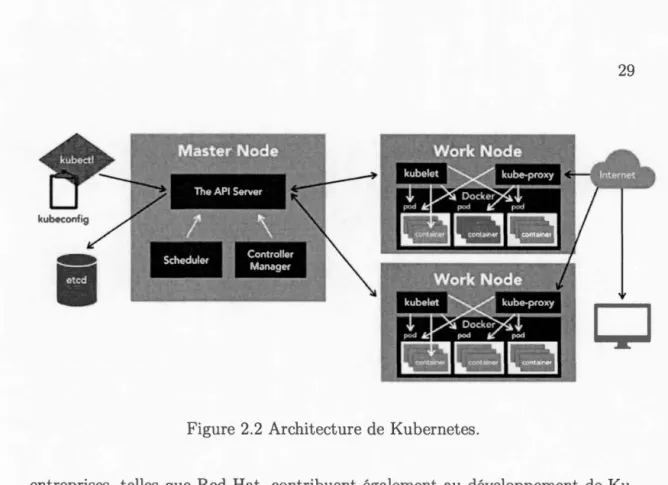
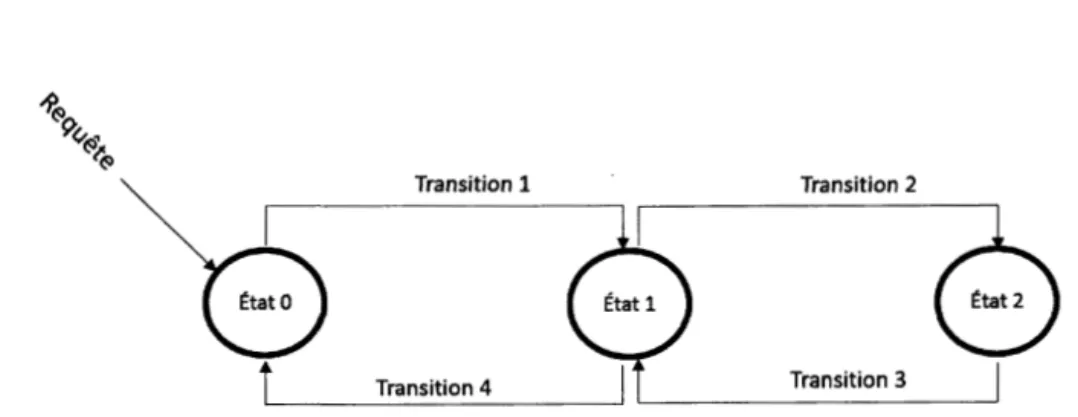
Figure



+7


Documents relatifs