MODÈLE DE SOCIALISATION AUTOMATIQUE: POUR LA CRÉATION DE COMMUNAUTÉS D'INTÉRÊT
THÈSE PRÉSENTÉE
COMME EXIGENCE PARTIELLE
DU DOCTORAT EN INFORMATIQUE COGNITIVE
PAR MÉLANIE LORD
Avertissement
La diffusion de cette thèse se fait dans le respect des droits de son auteur, qui a signé le formulaire Autorisation de reproduire et de diffuser un travail de recherche de cycles supérieurs (SOU-522 - Rév.01-2006). Cette autorisation stipule que «conformément
à
l'article 11 du Règlement no 8 des études de cycles supérieurs, [l'auteur] concèdeà
l'Université du Québecà
Montréal une licence non exclusive d'utilisation et de publication de la totalité ou d'une partie importante de [son] travail de recherche pour des fins pédagogiques et non commerciales. Plus précisément, [rauteur] autorise l'Université du Québec à Montréalà
reproduire, diffuser, prêter, distribuer ou vendre des copies de [son] travail de recherche à des fins non commerciales sur quelque support que ce soit, y compris l'Internet. Cette licence et cette autorisation n'entraînent pas une renonciation de [la] part [de l'auteur] à [ses] droits moraux nià
[ses] droits de propriété intellectuelle. Sauf entente contraire, [l'auteur] conserve la liberté de diffuser et de commercialiser ou non ce travail dont [il] possède un exemplaire.»REMERCIEMENTS
Ce document représente l'aboutissement d'un long processus de recherche au cours duquel j'ai côtoyé diverses personnes qui ont eu, de près ou de loin, une influence positive sur l'accomplissement de ce projet.
Je veux tout d'abord remercier Daniel Memmi et Pierre Poirier, professeurs à l'Université du Québec à Montréal, de m'avoir dirigée dans mes travaux de recherche. Ils ont su me guider et me conseiller de façon judicieuse, tout au long de cette thèse. Je les remercie aussi pour leur disponibilité, leur générosité et leur compréhension qui m'ont grandement motivée à mener à bien ce projet.
Aussi, je voudrais exprimer ma reconnaissance à Hafedh Mili, professeur à l'Université du Québec à Montréal, parce qu'il m'a accordé de son temps, à plusieurs reprises, en me permettant ainsi de profiter de son expérience et de ses remarques pertinentes.
Mes remerciements vont de plus à mes amis et à ma famille. En particulier, je remercie mon amie Ghizlane avec qui j'ai souvent discuté de ma thèse et que j'estime énormément. Je remercie mon amie Madeleine pour sa gentillesse, sa compréhension et son enthousiasme. Je remerc1e mes cousines Myriam et Valérie pour leur amitié et leurs encouragements continuels.
Enfin, je remerc1e mon père et ma mère pour leur amour, leur présence et leur soutien constant.
LISTE DES FIGURES ... vi
LISTE DE TABLEAUX ... viii
RÉSUMÉ ... ix
CHAPITRE 1 INTRODUCTION ... 1
1.1 Mise en contexte de la recherche ... 1
1.1.1 Traitement sociocognitif de l'information ... 3
1.1.2 Des communautés traditionnelles aux cybersociétés ... 4
1.1.3 La collaboration en ligne : exploiter les affinités ... 6
1.1.4 Tirer profit des liens sociaux ... 8
1.2 Problématique et objectifs de recherche ... 11
1.2.1 Défi de l'évolution des réseaux en contexte décentralisé ... 14
1.2.2 Problème de l'évolution des profils d'intérêts ... 22
1.2.3 Problème de l'évolution des catégories sémantiques ... 24
1.3 Méthodologie ... 29
1.3.1 Approche expérimentale par simulation ... 29
1.3.2 Collecte de données pour peupler nos simulations ... 30
1.3 .3 Mesures et critères d'évaluation ... 31
1.4 Contributions de la thèse ... 32
1.5 Organisation de la thèse ... 35
CHAPITRE II CONTEXTE THÉORIQUE ... 37
2.1 Introduction ... 37
2.2 La socialisation dans les réseaux virtuels ... 39
2.2.1 Qu'est-ce qu'un site de réseautage en ligne (médias sociaux) ... 39
2.2.2 Mécanismes généraux d'utilisation et de fonctionnement ... 39
2.3 Propriétés structurales des réseaux ... 41
2.3 .2 Étude de la structure des réseaux complexes ... 53
2.4 Modélisation des réseaux ... 64
2.4.1 Les graphes aléatoires ... 64
2.4.2 Les petits mondes ... 66
2.4.3 Modèles basés sur l'attachement préférentiel ... 70
2.4.4 Modèles basés sur la fermeture des triangles ... 76
2.5 Navigation et recherche dans les réseaux d'information ... 81
2.6 Diffusion de l'information dans les réseaux sociaux ... 86
2.7 Systèmes sociaux et collaboratifs ... 87
2. 7.1 La navigation sociale et la recherche collaborative ... 88
2.7.2 Les systèmes de recommandation par filtrage collaboratif.. ... 90
2.7.3 Compilation de profils d'intérêts ... 93
2.8 Conclusion ... 95
CHAPITRE III DESCRIPTION DU MODÈLE DE SOCIALISATION ... 97
3.1 Introduction ... 97
3.2 Formalisation du modèle ... 98
3 .2.1 Composants du modèle ... 98
3 .2.2 Comportements et règles d'évolution du modèle ... 100
3.3 Fonctionnement du modèle de socialisation ... 105
3.3.1 Structure du réseau et navigabilité ... 105
3.3.2 Regroupements autour de noeuds pivots simples ... 112
3.3.3 Regroupements autour de noeuds pivots chaînés ... 130
3.4 Considérations sur les profils d'intérêts ... 154
3 .4.1 Deux individus ne sont jamais identiques ... 154
3.4.2 Compilation et comparaison des profils d'intérêts ... 163
3.5 Conclusion ... 167
CHAPITRE IV EXPÉRIMENTATIONS ET RÉSULTATS ... 170
4.1 Introduction ... 170
4.2 Collecte de données pour la création de profils d'intérêts ... 171
4.4 Scénarios de simulations ... 176
4.5 Mesures utilisées et résultats attendus ... 181
4.5.1 Niveau fonctionnel ... 181
4.5.2 Niveau sociocognitif.. ... 185
4.6 Analyse des résultats de simulations ... 188
4.6.1 Analyse au niveau fonctionnel ... 188
4.6.2 Validation au niveau sociocognitif.. ... 205
4.7 Conclusion ... 216
CHAPITRE V CONCLUSION ET PERSPECTIVES ... 218
5.1 Contributions ... 218 5.2 Travaux futurs ... 222
5.2.1 Au niveau sociocognitif ... 222
5.2.2 Au niveau informatique ... 223
Figure Page
1.1 Problème de séparation des communautés lorsqu'un individu quitte le réseau . ... ... 17
1.2 Problème d'identification de la communauté d'appartenance d'un individu... 19
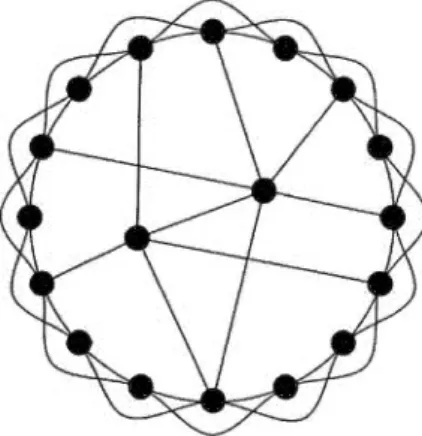
2.1 Illustration du « Ki te N etwork » développé par David Krackhardt.. .. . . 49
2.2 Distribution des degrés suivant une loi de puissance... 59
2.3 Graphe du réseau de contacts sexuels étudié par (Potterat et al., 2002) ... 60
2.4 Divers graphes aléatoires de taille net de degré moyen z... 65
2.5 Treillis régulier avec un degré moyen z = 4 ... ... ... 67
2.6 Modèle des petits mondes
f3
de Watts et Strogatz ... ... ... .. ... 682.7 Modèle de petit monde de Dorogovtsev et Mendes... 69
2.8 Illustration du graphe généré par le modèle de Jin, Girvan et Newman... 79
3.1 Structures de communautés (a) fortement transitives, et (b) en forme d'étoile ... 106
3.2 Densité et distance dans deux graphes de même taille... 107
3.3 Regroupement autour d'un nœud pivot .. .. .. .. .. .. .. .. .. .. .... .. .. .. .. . . .... .. .. .. .. .. .. . .. .. .. .. .. . .. .. .. .. . 113
3.4 Exemples de réseaux à pivots simples ... ... ... .... ... ... 115
3.5 Fusion de communautés dans un réseau à pivots simples ... 119
3.6 Connexions successives dans un réseau à pivots simples ... 122
3.7 Rencontre et recommandation dans un réseau à pivots simples ... 125
3.8 Déconnexions de noeuds pivots dans un réseau à pivots simples... 129
3.9 Regroupement autour de nœuds pi ots chaînés ... 133
3.10 Exemplaires de réseaux à pivots chaînés ... ... ... .... ... .... 135
3.11 Remplissage de chaînes libres dans un réseau à pivots chaînés ... 138
3.12 Libération de places dans un réseau à pivots chaînés ... ... ... ... 141
3.13 Fusion de communautés dans un réseau à pivots chaînés ... 144
3.14 Déconnexions de pivots initiaux dans un réseau à pivots chaînés ... 148
3.15 Déconnexion d'un pivot intermédiaire dans un réseau à pivots chaînés ... 149
3.17 Rencontre et recommandation dans un réseau à pivots chaînés... 153
3.18 Comparaison de la similarité entre trois profils d'intérêts Pl, P2 et P3 ... ... ... 156
3.19 Réseau parfait composé de 38 acteurs ... 160
3.20 Autre configuration d'un réseau parfait composé des mêmes 38 acteurs que la figure 3.19 ... 161
3.21 Vecteur de fréquences obtenu à partir d'une collection de ressources étiquetées de mots-clés... 165
3.22 Représentation vectorielle de profils d'intérêts .. .. .. .. .. . .. .. .. .. .. .... .. .... .. .... . .. .. . .... .. . .. .. .. .. . 166
4.1 Évolution de la densité en fonction du temps .. ... ... ... 189
4.2 Évolution du diamètre et de la distance moyenne pondérés en fonction du temps ... 191
4.3 Évolution de la proportion des nœuds pivots pondérée en fonction du temps... 195
4.4 Évolution de l'homophilie en fonction du temps... 199
4.5 Évolution de la proportion des rencontres effectuées en fonction du temps ... 203
4.6 Réseaux des noeuds pivots en fin de simulation pour les trois scénarios avec socialisation... 209
4.7 Estimation d'une loi de puissance sur la distribution des degrés d'un réseau pour chaque simulation avec socialisation .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. .. 211
4.8 Évolution de la centralité de proximité en fonction du temps ... 214
5.1 Interface simple pour une application de socialisation automatique ... 225
Tableau Page
2.1 Coefficients de clustering observés dans divers réseaux sociaux réels... 58
2.2 Valeurs de la modularité Q pour différents réseaux sociaux... 63
3.1 Regroupements d'individus dans le réseau de la figure 3.19 ... 160
3.2 Regroupements d'individus dans le réseau de la figure 3.20 ... 161
4.1 Description des paramètres du modèle ... 175
4.2 Sommaire des scénarios de simulations ... 178
4.3 Valeurs des paramètres qui varient d'un scénario à l'autre ... 178
4.4 Valeurs des paramètres communs à tous les scénarios ... 179
4.5 Densité pour tous les scénarios au pas de temps 2000 ... 190
4.6 Diamètre pondéré au pas de temps 2000 ... 192
4.7 Distance moyenne pondérée au pas de temps 2000 ... 193
4.8 Proportion des nœuds pivots pondérée au pas de temps 2000 ... ... ... 196
4.9 Hemophilie au pas de temps 2000 ... 200
4.10 Proportion des rencontres effectuées au pas de temps 2000 ... 204
4.11 Comparaison de la distance moyenne avec celle d'un graphe aléatoire de même taille ... 206
4.12 Modularité au temps 2000 pour les trois scénarios avec socialisation ... 207
4.13 Comparaison du coefficient de clustering avec celui d'un graphe aléatoire équivalent . . . .. ... . . .. . . .. . .. . . .. . . . .. . .. . . .. . . .. .. . . .. . . .. . . .. . . .. 208
4.14 Coeffic'ent de corrélation des droites estimées dans les graphes log-log de la distribution des degrés de nos réseaux, pour les scénarios avec socialisation ... 210
4.15 Coefficients de loi de puissance observés dans divers réseaux sociaux réels ... 212
Le développement rapide des technologies comme Internet et le Web a remarquablement intensifié la prolifération et la décentralisation de l'information à travers les nombreux réseaux électroniques et communautés virtuelles qui ne cessent de croître. Cette effervescence pose problème lorsqu'il s'agit de trouver de l'information pertinente dans le cadre de besoins spécifiques. Par ailleurs, ces mêmes technologies sont aussi responsables de l'ouverture ainsi que de la décentralisation des communautés traditionnelle et, plus récemment, de la multiplication de divers médias sociaux, qui permettent aujourd'hui d'avoir accès à une grande variété d'individus, provenant de divers milieux sociaux.
En effet, nos contacts sociaux sont des atouts précieux lorsqu'il s'agit de trouver de l'information utile et pertinente. Les connaissances acquises par échanges sociaux ont l'avantage non négligeable d'avoir déjà été traitées cognitivement, d'avoir été intériorisées, élaguées, contextualisées, élaborées, etc. Dans un contexte où l'information surabonde, de pouvoir profiter de ce prétraitement de l'information, par l'intermédiaire de nos contacts sociaux, est un avantage majeur pour acquérir plus rapidement les connaissances qui nous sont vraiment utiles. Toutefois, que ce soit dans nos réseaux sociaux réels ou virtuels, cette grande accessibilité à de nombreux individus ne facilite pas la localisation de ceux qui sont vraiment pertinents et intéressants. C'est par le biais de la socialisation que nous entretenons et renouvelons nos réseaux de contacts personnels, mais il faut du temps, de la motivation et un certain talent pour trouver les bonnes «connexions ». C'est dans cette optique que nous proposons, dans le cadre de cette thèse, un modèle de socialisation automatique qui favorise la rencontre des individus intéressants et utiles les uns pour les autres en formant et maintenant automatiquement des communautés d'intérêt, au sein d'un réseau social dynamique.
Plus précisément, les règles d'évolution du modèle proposé s'inspirent des mécanismes de socialisation qu'on observe dans nos réseaux sociaux habituels, et donc, gèrent un réseau complètement décentralisé (contrairement aux sites de réseau tage en ligne). D'un point de vue informatique, nous avons conçu notre modèle afin qu'il soit utilisable pour l'implémentation d'applications distribuées basées sur la formation de communautés d'intérêt au sein de réseaux sociaux virtuels. D'un point de vue sociocognitif, nous proposons aussi ces mécanismes de socialisation ainsi formalisés comme processus évolutifs des réseaux sociaux usuels, qui pourraient expliquer, dans une certaine mesure, les propriétés structurales typiques et récurrentes qu'on y retrouve.
Mots-clés : Modélisation sociale, Socialisation, Réseaux sociaux, Médias sociaux, Analyse de réseaux sociaux, Structures des réseaux sociaux, Systèmes collaboratifs, Systèmes décentralisés.
The rapid growth of technologies such as Internet and the Web has remarkably intensified the proliferation and the decentralization of information through electronic networks and virtual communities, which continue to grow. This profusion of information is problematic when it cornes to locate relevant informations that meet specifie needs. Moreover, these same technologies are also responsible for more open and decentralized societies and, more recently, for the proliferation of various social media, th at pro vide access to a wide variety of individuals, from different social environments.
Indeed, our social contacts are valuable assets when it cornes to find relevant information. Knowledge acquired by social exchanges has the advantage to have already been processed cognitively, to have been intemalized, pruned, contextualized, developed, etc. In a context where information is overabundant, to benefit from this human filtering of information, through our social contacts, is a major advantage to more quickly acquire the knowledge that is really useful to us. However, in our social networks, whether real or virtual, this great access to a wide range of people does not facilitate the task of finding those that are really relevant and interesting. lt is through socialization that we maintain and renew our networks of persona! contacts, but it takes time, motivation and talent to find the "right connections". lt is from this perspective that we propose, in this thesis, a model of automatic socialization that promotes interesting and useful encounters between individuals by automatically forming and maintaining communities of interest, within a dynamic social network.
More precisely, the evolution rules of our model are based on mechanisms of socialization that take place in our usual social networks, and therefore, manage a completely decentralized network (unlike comrnon online social network). From a functionnal point of view, we have designed our rnodel so that it can be implemented and used as a basis for distributed applications of social networks and comrnunities of interest. Morevover, from a socio-cognitive point of view, we also propose the se formalized socialization mechanisms as evolutionary social processes, which may explain, to sorne extent, typical and recurrent structural properties found in real social networks.
Keywords : Social modeling, Socialization, Social networks, Social media, Social network analysis, Social network structures, collaborative systems, decentralized systems.
INTRODUCTION
1.1
Mise en contexte de la recherche
Ce projet de recherche, portant sur la formation et le maintien de communautés d'intérêt, se situe selon nous dans un contexte plus large que nous aimerions expliciter avant de décrire le travail effectivement réalisé. Ce contexte comporte plusieurs aspects différents, social, économique, cognitif, et technique, mais qui forment un système globalement cohérent. On peut distinguer en gros les aspects suivants :
Aspect social
Depuis deux siècles envuon, nous sommes passés de petites communautés traditionnelles relativement fermées à des réseaux ouverts et flexibles, en constant remaniement. Plusieurs de nos interactions sociales prennent place dans ce nouveau cadre, notamment dans le domaine du travail. On ne peut pas comprendre le fonctionnement social réel si l'on ignore ce changement fondamental dans la structure sociale (Weber, 1956 ; Simmel, 1989).
Aspect économique
Les économies modernes incorporent une proportion croissante de connaissances, qui sont la condition de leur productivité et de leur croissance. Ces connaissances techniques ou portant sur la gestion sont maintenant le facteur prépondérant des évolutions économiques. L'acquisition et l'utilisation de connaissances sont un problème économique majeur pour nos sociétés (Foray, 2000).
Aspect cognitif
Information et connaissances ne sont pratiquement utiles que si elles sont cognitivement assimilées par les individus et organisations, c'est-à-dire filtrées, apprises, comprises et intégrées. Cette assimilation se fait le plus souvent au sein de relations sociales qui permettent d'accéder à l'information pertinente et facilitent son intégration cognitive. D'où la grande importance des relations sociales en jeu (Nonaka et Takeuchi, 1995).
Aspect technique
L'évolution socio-économique se poursuit en symbiose avec le développement accéléré de techniques de communication variées (du téléphone à Internet) qui facilitent la diffusion d'information et de connaissances. Mais cette diffusion ne peut être efficace que si elle respecte et favorise les relations sociales les plus appropriées à l'acquisition et l'assimilation de connaissances (voir Drucker, 1970).
On remarque la cohérence de ces différents aspects, qui se renforcent mutuellement depuis plus d'un siècle, et cela de manière qui s'accélère depuis quelques décennies avec le développement de plus en plus poussé des réseaux électroniques. Dans ce contexte historique, notre but est de proposer des techniques informatiques pour favoriser la construction de relations sociales utiles à la diffusion efficace d'information et de connaissances.
Plus précisément, nous allons montrer comment construire des réseaux sociaux virtuels regroupant automatiquement les individus ayant des intérêts similaires et donc, susceptibles d'échanger utilement de l'information et de collaborer à la résolution de problèmes. En partant d'une réflexion sur les mécanismes spontanés de socialisation dans la vie sociale habituelle, nous allons proposer des mécanismes automatiques de socialisation se voulant à la fois techniquement efficaces et socialement utiles. Mais pour cela, avant de parler des réalisations techniques, nous devons maintenant détailler davantage la problématique, notamment du point de vue cognitif.
1.1.1 Traitement sociocognitif de l'information
L'étude de la manière dont nous traitons l'information a donné lieu à un ensemble considérable de travaux, notamment en psychologie cognitive, qui nous a permis de mieux comprendre les capacités individuelles cognitives chez l'humain comme la perception, la mémoire, le raisonnement, l'apprentissage, la résolution de problèmes, le langage, etc. Plus récemment, cependant, on parle de cognition située (Brown et al., 1989 ; Rabbins et Aydede, 2009) et de cognition distribuée ou collective (Salomon, 1993; Hamad, 2005). La cognition collective renvoie au fait que l'interaction entre plusieurs individus cognitifs peut générer de nouvelles connaissances, que la connaissance du groupe est plus que la somme des connaissances de chaque individu. On parle ici d'un savoir cumulatif, collectif et collaboratif. La cognition située, quant à elle, est l'idée que l'on ne peut pas séparer la connaissance de son contexte. Les individus réfléchissent et apprennent en situation : en accomplissant différentes activités, en discutant avec les autres, en utilisant une langue particulière, en baignant dans une culture spécifique, etc. La connaissance est déterminée tant par l'individu qui apprend que par l'environnement (physique, biologique, social, etc.) dans lequel il évolue.
On constate cependant que l'environnement dans lequel nous évoluons est en grande partie social. Parce que nous fonctionnons la plupart du temps en société, une grande partie des informations que nous recevons proviennent de notre milieu social et nous sont aussi indispensables pour fonctionner au sein même de ce milieu. La majorité de nos activités journalières sont de nature sociale. On échange constamment de l'information les uns avec les autres pour accomplir des tâches sociales complexes : planifier et coordonner des activités, résoudre des problèmes, collaborer sur des projets, faire des choix, innover, etc. De ce point de vue, on peut donc comprendre le traitement de l'information (créer, collecter, transmettre, appliquer, échanger, interpréter, ense1gner, etc.) comme une activité collaborative située socialement.
D'autre part, le développement rapide des technologies (les ordinateurs, l'Internet, les réseaux électroniques, le Web, les appareils mobiles ... ) soulève de nouveaux défis quant au traitement de l'information. On assiste en effet à la prolifération croissante de données
électroniques de toutes sortes sur Internet et le Web. Cette effervescence pose un problème évident quant à la gestion de cette information surtout lorsqu'on considère que celle-ci est une ressource cruciale pour le développement économique, social et technologique de nos sociétés modernes (Foray, 2000). Cependant, ces mêmes technologies proposent aussi de nouveaux lieux de socialisation et de collaboration dont on peut tirer parti pour mieux canaliser ces ressources informationnelles.
1.1.2 Des communautés traditionnelles aux cybersociétés
La montée des technologies a intensifié le phénomène de reconfiguration graduelle des groupes sociaux traditionnels denses et cohésifs vers des réseaux sociaux plus ouverts et moins stables. Comme (Memmi, 2009) le fait remarquer, ce phénomène avait été observé, déjà vers la fin du 19e siècle, par des sociologues allemands comme (Tonnies, 1963), (Weber, 1956) et (Simmel, 1989) qui ont posé la distinction entre les communautés traditionnelles (Gemeinschaft) et les sociétés modernes (Gesellschaft) dans leurs travaux d'analyse sur les sociétés modernes et de la vie urbaine. Les communautés traditionnelles sont décrites comme des communautés personnelles locales assez petites, assez denses, très cohésives et très stables enracinées dans les villages et le voisinage. À l'opposé, on décrit les sociétés modernes comme des regroupements sociaux dans lesquels les relations entre les individus sont plutôt impersonnelles, souvent temporaires ou transitoires et fréquemment formées dans un but pratique. La distinction entre les relations durables observées dans les groupes traditionnels et ces liens temporaires qu'on retrouve dans les réseaux sociaux modernes a aussi été discutée, entre autres, par (Granovetter, 1973). Celui-ci explique, par exemple, que les liens faibles et superficiels, bien que ne permettant pas la formation de communautés fortes et solidaires, sont cependant très utiles pour la circulation de 1 'information.
Le développement des technologies a grandement favorisé ce passage graduel des communautés traditionnelles vers les sociétés modernes. Dans la deuxième moitié du 20e siècle, la prolifération de moyens de transport comme les automobiles, les avions, les autobus, le train ou des moyens de communication comme le téléphone a favorisé les
relations de longue distance et donc, la délocalisation progresstve des communautés. On observe alors le passage graduel des structures sociales traditionnelles vers des structures sociales intermédiaires, un peu moins denses et moins cohésives basées sur les réseaux. Ces réseaux sont formés de petites communautés locales fortement structurées (clusters), comme la famille et les collègues de travail, qui se connectent entre eux à l'aide de connexions de longue distance, plutôt que de ne former qu'une seule grande composante très cohésive à la manière des groupes traditionnels.
On observe aussi que la venue d'Internet et de sa progéniture (les courriers électroniques qui ont été suivis par les messageries instantanées, les espaces de clavardage, les blogues, les wikis, etc.), et l'expansion de l'utilisation des téléphones cellulaires et autres appareils mobiles ont amplifié ce phénomène de délocalisation de lieu en lieu vers des réseaux individualisés de personne à personne (Wellman, 2001 ; Castells, 2001). Par exemple, les gens sont connectés par des téléphones cellulaires qui ne sont plus assujettis à des endroits fixes et les courriels peuvent être consultés n'importe où moyennant une connexion Internet.
De telles structures sociales plus grandes, plus ouvertes et plus flexibles préservent les avantages des structures intermédiaires : l'accès à une grande variété d'informations et d'individus provenant de divers milieux sociaux ainsi que 1 'accès rapide à de nouveaux contacts par les super connecteurs (acteurs pivots, individus qui sont reliés à un grand nombre d'autres individus). Dans ces réseaux, les liens sont plus spécialisés, et fournissent aux individus, différents types de ressources, dans une multitude de milieux sociaux. Cette individualisation des connexions signifie que l'acquisition de ressources dépend maintenant essentiellement de la capacité et de la motivation des individus à maintenir et trouver les « bonnes connexions ». Chacun doit développer et constamment entretenir son propre réseau de relations.
Plus récemment, les réseaux électroniques, l'informatique sociale et l'avènement du Web 2.0 ont favorisé l'apparition et la prolifération de diverses communautés virtuelles. Qu'on les appelle wikis, laboratoires à distance, jeux en ligne, forums, communautés électroniques, réseaux sociaux virtuels, cybersociétés, groupes Web, sites de réseautage en ligne ou sites
d'achats en ligne, ces cybercommunautés sont des lieux de rencontre qui fournissent, à différents degrés, divers moyens de communication et d'échange d'informations entre les individus, peu importe la distance géographique qui les sépare. Ce sont des lieux cyberspatiaux où l'on socialise pour s'entraider, collaborer, apprendre, jouer, échanger, etc. En raison de leur nature virtuelle et intemporelle, (Korzeny, 1978 ; Wallace, 1999) font remarquer que les communautés en ligne se forment généralement autour d'intérêts communs ou d'affinités telles que l'éducation, la provenance ethnique, la langue, les passe-temps, les croyances, et que la proximité géographique ou l'attirance physique, par exemple, sont des facteurs de regroupement négligeables, contrairement aux communautés traditionnelles. Les développements les plus récents de l'informatique sociale sont les sites de réseautage en ligne comme Facebook, Twitter, Linkedln, etc. Ceux-ci, contrairement aux communautés virtuelles plus traditionnelles, consistent en des réseaux de personnes qui croissent et changent très rapidement.
Que le traitement de l'information soit une activité collective située socialement n'est pas un fait nouveau. Cependant, le développement rapide des nouvelles technologies, offrant de plus en plus de possibilités de socialisation, dans divers milieux cybernétiques, qui reformulent notre environnement social vers le réseautage actif et qui sont responsables de l'apparition de nouvelles façons de collaborer, de coordonner nos activités et d'interagir en temps réel, affecte nécessairement nos manières de gérer l'information.
1.1.3 La collaboration en ligne : exploiter les affinités
L'intérêt des cybercommunautés réside aussi dans le fait qu'elles génèrent de l'information électronique récupérable et exploitable. Par exemple, dans plusieurs de ces groupes sociaux, les utilisateurs peuvent publier explicitement un profil personnel décrivant leurs intérêts, leur nationalité, leur lieu de résidence, leur formation professionnelle, etc. C'est le cas de Facebook (http://www.facebook.com) ou Linkedln (http://www.linkedin.com), par exemple. Il devient aussi possible de déduire les intérêts des individus de manière implicite en collectant de l'information sur leurs activités en ligne : le genre de sites Web qu'ils fréquentent, les produits qu'ils achètent ou le type de recherche qu'ils effectuent dans Google.
Dans le cas particulier et de plus en plus populaire des communautés en réseaux, il est souvent possible d'extraire de l'information concernant la structure (et parfois la nature) des relations entre les individus faisant partie du réseau : qui connaît qui, qui collabore avec qui, etc. Bref, les participants de ces nouveaux lieux virtuels laissent inévitablement des traces électroniques récupérables qui deviennent une source d'information en soi.
Dès lors, on remarque l'apparition de nouvelles techniques de gestion de l'information, basées sur la collaboration en ligne, qui tentent de récupérer ces traces électroniques dans le but d'améliorer, de personnaliser la recherche d'informations : séparer l'information pertinente de celle qui ne l'est pas, selon les besoins particuliers d'un utilisateur. En effet, l'accès qu'offrent les communautés virtuelles à toutes sortes d'individus, provenant de divers milieux, a propulsé le concept de collaboration en ligne. On peut désormais non seulement utiliser les réseaux électroniques pour rechercher de l'information utile, mais aussi pour rechercher des individus pertinents : des experts, dans un domaine particulier, qui pourraient nous fournir l'information recherchée ou nous aiguiller vers celle-ci ou bien tout simplement des pairs qui partagent nos intérêts avec qui l'on pourrait échanger des connaissances utiles. On parle alors de navigation sociale, de recherche d'informations collaborative, de filtrage collaboratif, de systèmes de recommandation collaboratifs, etc. Ces techniques diffèrent quelque peu dans leur utilisation, mais leur objectif reste le même : tirer parti de la collaboration entre les individus pour élaguer l'information et ne conserver que celle qui est pertinente et utile dans le cadre de besoins spécifiques. L'hypothèse sous-jacente de telles méthodes est que les individus qui ont des profils similaires peuvent vraisemblablement s'entraider en partageant leurs expériences et leurs connaissances.
Les communautés virtuelles deviennent ainsi des lieux informationnels pouvant être exploités en associant les utilisateurs ayant des profils similaires, en créant des liens d'affinité implicites entre les individus qui se ressemblent. Considérons, par exemple, la communauté des consommateurs en ligne sur un site comme Amazon (http://www.amazon.com). En cataloguant les utilisateurs selon ce qu'ils achètent, on peut les comparer et déduire les profils de consommation qui se ressemblent. Avec cette information, on peut alors proposer à un utilisateur, des produits ayant été achetés par des consommateurs similaires, en supposant que
ces produits seront intéressants pour cet utilisateur. C'est l'idée principale des systèmes de recommandations collaboratifs. Dans cet exemple, on construit les profils des utilisateurs selon les produits qu'ils achètent, mais dans d'autres contextes on utilisera d'autres types d'informations disponibles pour décrire les utilisateurs et déduire ceux qui présentent des affinités. Nous discuterons de ces méthodes au chapitre 2 (voir sect. 2.7).
Notons que nous utilisons le terme "liens implicites", ici, pour parler des relations qui ne sont pas formellement déclarées, mais simplement tacites, déduites par affinité (par similarité des profils). La section suivante porte plus particulièrement sur les communautés en réseau (les réseaux sociaux) dans lesquelles nous parlerons plutôt de "liens explicites".
1.1.4 Tirer profit des liens sociaux
Nous utilisons le terme "réseau social" pour désigner plus spécifiquement les communautés dans lesquelles les membres sont considérés comme des entités sociales entretenant des relations avec d'autres membres du réseau. Peu importe l'intensité ou la nature de ces relations (professionnelles, de collaboration, d'amitié, etc.), on parle ici de liens explicites, formellement énoncés (et non déduits par calculs). Dans ce type de communautés, chaque membre possède son propre sous-réseau de contacts personnels et la réunion de tous ces (plus ou moins grands) réseaux locaux forme la structure globale du réseau entier; l'information structurelle, relationnelle, se trouve au niveau de chacun des membres.
Lorsqu'il s'agit d'un réseau social virtuel, comme Linkedln (http://www.linkedin.com), par exemple, il est possible de conserver l'information concernant les relations entre tous les individus et d'avoir, à tout moment, une vue globale du réseau social. Ceci nécessite cependant un lieu centralisé pour le stockage de cette information, un ou plusieurs serveurs, par exemple, qui doivent constamment être entretenus et mis à jour.
Par contre, au sem de réseaux complètement décentralisés (sans gestion centrale de l'information), comme c'est le cas du Web ou de nos réseaux sociaux réels, par exemple, le réseau global est inconnu de tous. Dans les réseaux sociaux, par exemple, on connaît nos
relations et peut-être certaines des relations de nos relations, mais pas beaucoup plus loin. Comme la seule façon de découvrir le Web est de parcourir les pages, d'hyperlien en hyperlien, la seule manière de découvrir un réseau social est de parcourir les individus, en suivant les liens, de personne en personne. Dans le cas du Web, on appelle cette technique crawling, dans le cas des réseaux sociaux, on parle de socialisation.
Dans ce contexte décentralisé, on réalise que la connmssance des propriétés structurales typiques des réseaux est un atout précieux pour rendre ces parcours à l'aveugle plus efficaces en regard de la recherche d'informations spécifiques ou d'individus intéressants. On aimerait savoir si nos réseaux sociaux possèdent des propriétés structurales récurrentes sur lesquelles on pourrait se baser afin de concevoir, par exemple, de meilleurs algorithmes de parcours efficaces du réseau, lors de la recherche d'informations ou d'individus pertinents. De même que l'étude structurale du graphe du Web a donné lieu au fameux algorithme PageRank de Google (Page et al., 1998 ; Brin et Page, 1998), on s'intéresse aux propriétés structurales des réseaux sociaux dans l'espoir d'améliorer les systèmes de diffusion et de recherche d'informations. On retrouve ainsi, dans la littérature, un ensemble considérable de travaux portant sur l'analyse structurale des réseaux sociaux, sur la diffusion de l'information au sein de structures typiques, sur les mécanismes d'évolution des réseaux, sur la manière de localiser des individus particuliers au sein d'un réseau (navigation) en tirant parti des propriétés structurales de celui-ci, etc. Nous aborderons ces travaux plus en détail au chapitre suivant.
Les réseaux sociaux peuvent être vus comme un type particulier de réseaux d'informations lorsqu'on considère les individus qui les composent comme des sources de connaissances. Cependant, l'information acquise par échanges sociaux a l'avantage non néglig able d'avoi déjà été traitée cognitivement, d'avoir été intériorisée, élaguée, contextualisée, élaborée, etc. Dans un contexte où l'information surabonde, de pouvoir profiter de ce prétraitement de l'information, par l'intermédiaire de nos contacts sociaux, est un atout majeur pour acquérir plus rapidement les connaissances qui nous sont vraiment utiles. L'apparition et la prolifération des communautés virtuelles ont favorisé l'accès aux individus (et à leurs connaissances) par échanges sociaux, et ce, dans divers milieux.
Toutefois, l'utilisateur de telles communautés doit entretenir, s'il y a lieu, ses différents profils sur les différentes communautés auxquelles il appartient, il doit visiter ces communautés pour demeurer au fait de ce qui se passe et surtout, il doit socialiser activement pour entretenir et enrichir son réseau de contacts personnels. De même qu'il faut du temps pour perpétuer nos relations dans nos réseaux sociaux réels, il faut du temps et un certain talent pour trouver et maintenir les "bonnes connexions" dans les réseaux sociaux virtuels afin d'en tirer vraiment parti.
L'idée initiale de ce projet de recherche a été motivée par cet état de fait. Oui, nous avons maintenant de multiples possibilités de socialisation, et celle-ci est en effet un moyen efficace, si l'on s'en donne la peine, pour découvrir du contenu pertinent, pour parfaire son réseau de contacts par la rencontre de nouveaux individus intéressants et pour entretenir les relations qui nous sont utiles, mais la socialisation active prend du temps et de l'énergie. Serait-il possible, alors, d'informatiser les mécanismes de socialisation et concevoir un système qui socialiserait pour nous ?
réseaux sociaux réels semblent
En effet, nos processus de socialisation dans les assez efficaces quant à la découverte de connaissances/contacts utiles en contexte non centralisé. Nous pensons donc que ces mécanismes pourraient aussi fonctionner au sein de réseaux sociaux virtuels décentralisés.
Sur la base d'observations des mécanismes de socialisation dans nos réseaux sociaux réels, nous voulons donc concevoir un modèle de socialisation automatique capable de trouver et maintenir les "bonnes connexions" c'est-à-dire, capable de gérer et maintenir les communautés d'intérêt au sein d'un réseau social non centralisé ainsi qu'en constante évolution.
La section suivante décrit en détailles problématiques abordées dans cette thèse ainsi que nos objectifs de recherche quant à la résolution de ces problèmes.
11
1.2 Problématique
et
objectifs de recherche
Les informations que nous recevons proviennent souvent de nos connaissances et contacts. Parfois, lorsqu'on s'intéresse à un nouveau sujet par exemple ou que l'on commence à explorer un nouveau domaine de recherche, nos idées ne sont pas toujours claires sur l'information que l'on cherche, faute d'une bonne connaissance du domaine. On fait souvent appel à nos contacts sociaux, que l'on sait plus experts que nous sur le sujet, pour obtenir, par exemple, quelques pointeurs de recherche ou pour nous diriger vers d'autres personnes susceptibles de nous aider.
D'autre part, on socialise aussi sans être en quête d'informations spécifiques. De discuter, d'échanger tout simplement avec des individus qui partagent nos intérêts permet aussi la découverte spontanée de nouvelles connaissances utiles et pertinentes qui ouvre nos horizons vers d'autres possibilités, parfois insoupçonnées. Ces deux types d'acquisition de connaissances (ciblée et non ciblée) par socialisation se renforcent mutuellement: la recherche explicite de connaissances nous amène à socialiser, puis en socialisant on découvre d'autres avenues, qu'on cherche ensuite à approfondir en socialisant de nouveau, etc.
Le fait d'obtenir de l'information par l'intermédiaire d'une personne humaine est très avantageux au sens où l'information que l'on reçoit a préalablement été traitée cognitivement (choisie, intégrée, assimilée, triée, mise en contexte ... ). Les individus agissent comme des filtres de l'infmmation lorsqu'ils partagent leurs connaissances. En ce sens, la socialisation est un processus collaboratif par lequel on réutilise le travail personnel de recherche, d'acquisition et d'élagage d'informations des uns pour augmenter les connaissances des autres. En effet, une information est utile lorsqu'elle répond à un besoin réel et d'autant plus utile lorsqu'elle est intégrée, comprise et contextualisée. C'est dans cette optique que (Nonaka et Takeuchi, 1995) font remarquer que la socialisation est effectivement un mécanisme efficace dans 1' acquisition de connaissances.
Les individus sont donc des sources d'informations avantageuses et la socialisation est le moyen de les découvrir. Par exemple, lorsqu'on participe à des événements sociaux comme
des colloques ou des congrès, on fait de nouvelles rencontres. On discute d'abord avec une personne possiblement rencontrée au hasard, puis une autre et une autre pour tranquillement se grouper naturellement et échanger plus longuement avec les gens qui partagent nos intérêts. Lorsqu'on socialise de cette manière, on ne cherche pas nécessairement une information particulière, mais on se dirige naturellement vers les gens avec qui l'on a des affinités et c'est en discutant avec eux qu'on apprend souvent beaucoup de choses utiles et pertinentes. La socialisation favorise ainsi les regroupements d'individus qui ont des affinités en commun.
Il est étonnant de voir comment cette navigation à l'aveugle nous permet tout de même assez efficacement de cheminer, dans le réseau des individus présents, vers ceux qui partagent nos intérêts (s'ils existent). On passe d'une personne à une autre, sans connaître la structure globale des relations qui unissent les individus présents, sans chemin tracé d'avance et ça fonctionne. Nous pensons que cette réalité s'explique, du moins en partie, parce que la plupart du temps, les gens qui socialisent aiment partager leurs "connaissances". Ici, l'emploi du terme "connaissances" n'est pas un hasard. En effet, on peut parler de connaissances en terme de savoir (ce que l'on connaît), mais aussi en terme de contacts (les individus que l'on connaît). En socialisant, on s'échange non seulement du "savoir", mais aussi des "contacts" c.-à-d. qu'on se guide mutuellement les uns vers les autres. Ainsi, tout au long de ce parcours social dans le réseau des gens présents, on a très probablement rencontré des gens qui n'avaient pas tout à fait les mêmes intérêts que nous, mais qui nous ont recommandés à des individus susceptibles de nous intéresser. On fait de même pour les autres. Bref, lorsque l'on socialise, on navigue dans le réseau de personne en personne et l'on tend à se regrouper avec d s indi idus qui partagent nos intérêts, par le biais de mécanismes de socialisation tels que les rencontres aléatoires et les recommandations.
De plus, lorsqu'on rencontre un individu intéressant (par hasard ou par recommandation), on risque aussi de rencontrer, par ricochet, les membres de sa communauté. La création d'un nouveau lien entre deux individus a pour effet de relier ensemble deux communautés dont certains membres sont susceptibles de partager des intérêts et d'ainsi bénéficier de cette seule rencontre. Dans cette optique, la socialisation est un processus collaboratif qui permet non
13
seulement de parfaire nos connaissances en réutilisant la connaissance des autres, mais aussi, d'élargir notre réseau personnel de contacts tout en augmentant aussi celui des autres.
En résumé, lorsqu'on socialise :
1. On fait des parcours de socialisation dans le réseau des gens présents. 2. On fait de nouvelles rencontres.
3. On se recommande les uns aux autres.
4. On se regroupe naturellement avec des individus partageant nos intérêts.
En nous inspirant des études sur la structure des réseaux sociaux ainsi que des travaux portant sur les systèmes collaboratifs, que nous aborderons au chapitre 2, notre thèse est que l'implémentation de mécanismes de socialisation dans un réseau social virtuel complètement décentralisé peut favoriser les regroupements automatiques d'individus similaires ainsi que le maintien de ces groupes, au sein d'un réseau en constante évolution.
Notre objectif principal est donc de concevoir un modèle de socialisation automatique, qui incorpore les mécanismes de rencontres aléatoires et de recommandation, par l'intermédiaire de parcours de socialisation dans le réseau. Nous attendons de ce modèle (1) qu'il puisse localiser automatiquement les individus semblables au sein du réseau, (2) qu'il les connecte entre eux sous forme de communautés d'intérêt et (3) qu'il maintie1me et renouvelle ces communautés, dans la mesure du possible, tout au long de l'évolution du réseau.
Les problèmes que nous abordons ici doivent être compris dans un contexte complètement décentralisé, comme nos réseaux sociaux réels, où il n'existe aucun lieu de coordination centrale ou entrepôt de données global sur les individus et la structure du réseau complet. La seule information disponible se trouve au niveau des individus et se résume aux attributs propres à l'individu comme ses intérêts, par exemple ainsi que la liste de ses contacts personnels. Les relations sociales sont donc un atout majeur pour accéder à l'information utile et pertinente. Mais comment trouver ces "bonnes" connexions dans un réseau social dont on ne connaît qu'une infime partie et qui évolue constamment ? Plus généralement, comment
construire des réseaux dont les mécanismes d'évolution intrinsèques favorisent les associations entre individus de profils similaires ?
Pour concevoir un modèle de socialisation automatique qui rassemble les individus en communautés d'intrérêt, les problèmes rencontrés ou les défis à relever, selon nous, peuvent se classer en trois catégories: l'évolution (1) des réseaux (2) des intérêts des individus et (3) des catégories sémantiques pour décrire l'information qui circule dans les réseaux. La problématique principale abordée dans cette thèse concerne l'évolution des réseaux, mais nous traitons partiellement l'évolution des intérêts et montrons comment notre modèle pourrait résoudre, dans une certaine mesure, l'évolution des catégories sémantiques.
1.2.1 Défi de l'évolution des réseaux en contexte décentralisé
1
.2
.1.1
Localisation d'individus dans
le réseau
Pour pouvoir regrouper ensemble les individus similaires, il faut d'abord les localiser dans le réseau, en faisant des parcours de socialisation : en explorant le réseau d'individu en individu, en suivant les liens. Au cours de ce parcours, chaque fois qu'on visite un individu, on compare, en quelque sorte, nos intérêts et s'ils sont similaires, on vient de rencontrer quelqu'un d'intéressant. Cependant, nos réseaux sociaux, en raison de leur nature dynamique, ne facilitent pas cette tâche de localisation d'individus de profils similaires. Le va-et-vient incessant causé par l'arrivée et le départ d'individus, par la création de nouveaux liens et la cessation d'anciennes relations modifient constamment le patron des connexions entre les individus : un nouvel arrivant crée de nouveaux liens, le départ d'un utilisateur a pour effet de couper tous les liens qui l'unissaient aux autres dans le réseau, etc. Ainsi, les chemins de lien en lien dans le réseau, qui connectent les membres les uns aux autres, sont aussi en perpétuel
remaniement. Par conséquent, l'exploration du réseau est d'autant plus difficile. De plus, dans
un grand réseau, on ne peut évidemment pas se permettre de visiter tous les individus
présents chaque fois qu'on socialise. Le problème, ici, est donc de trouver des chemins dans le réseau, des parcours de socialisation, qui demeurent assez courts par rapport aux nombres d'individus se trouvant effectivement dans le réseau et qui offrent tout de même une bonne chance de rencontrer des individus qui ont des intérêts similaires.
En effet, nous verrons, au chapitre 2, que dans nos réseaux sociaux réels, de tels chemins existent et qu'en général, les individus sont assez bons pour les trouver (Milgram, 1967 ; Dodds et al., 2003). Nous verrons aussi que les propriétés structurales des réseaux sociaux, qui définissent le patron des relations entre les individus présents dans le réseau, jouent un rôle important dans notre capacité à trouver ces chemins de comie distance, et ce, à l'aide d'informations locales uniquement.
Dans cette optique, la solution que nous proposons pour trouver ces chemins de courte distance lors de la recherche d'individus similaires dans un réseau en continuel remaniement est d'imposer aux réseaux générés par notre modèle des propriétés structurales désirables, c'est-à-dire qui favorisent la navigation efficace.
Plus précisément, nous voulons que la structure du réseau fournisse effectivement de courts chemins entre les individus, mais qu'elle ne comporte pas trop de chemins possibles entre les individus. On veut minimiser la redondance des chemins. En effet, plus le nombre de chemins possibles est grand, plus il sera difficile de découvrir celui qui est court. En contexte décentralisé, on navigue dans le réseau, d'individu en individu, et chaque fois qu'on visite un individu, on doit choisir, parmi ses voisins immédiats, le prochain individu à visiter. C'est de cette manière qu'on découvre les chemins, en suivant les liens, un lien à la fois. Si les individus dans le réseau ont tendance à avoir beaucoup de voisins (beaucoup de liens), ils offrent ainsi plusieurs possibilités de chemins différents dans le réseau : chaque fois qu'on visite un individu et qu'on doit choisir le prochain lien à parcourir, on aura ainsi plus de chances de choisir un mauvais chemin. En terme de théorie des graphes, on désire donc une structure qui présente à la fois une petite distance géodésique moyenne entre les individus (présence de courts chemins) et une faible densité (pas trop de liens dans le réseau).
Ainsi, notre objectif est de concevoir des algorithmes d'évolution du réseau, basés sur les mécanismes de socialisation, mais qui de plus contrôlent, dans une certaine mesure, tous les changements structuraux pouvant survenir au cours de l'évolution du réseau : le départ et l'arrivée d'individu dans le réseau, la création de nouveaux liens et la cessation d'anciennes relations. La difficulté, ici, est de maintenir ces propriétés structurales dans le réseau, et ce,
malgré sa constante évolution, de telle sorte que l'on puisse toujours s'y fier et les exploiter lors des parcours de socialisation dans le réseau. Ces algorithmes d'évolution du réseau sont expliqués en détail au chapitre 3 et constituent le cœur de cette thèse.
1.2.1
.2 Formation,
maintien et renouvellement des communautés d'intérêt
Dans ce contexte évolutif et décentralisé, pour former des communautés d'intérêt, la difficulté est aussi de trouver un mécanisme pour organiser dynamiquement les pairs entre eux, de les regrouper (et de maintenir ces regroupements) de manière à ce que les individus similaires demeurent proches les uns des autres, qu'ils soient accessibles les uns aux autres, et ce, malgré la constante restructuration des réseaux dans lesquels ils évoluent et sans la connaissance de la structure globale du réseau.
La constante évolution des réseaux suppose donc le remaniement continuel des communautés formées au sein de ces réseaux. Le maintien de ces communautés devient donc problématique. Supposons, par exemple, une communauté d'intérêt particulière, au sein d'un réseau, composée des membres A, B, C, D, E, F et G, telle qu'illustrée à la figure 1.1 (a). La figure 1.1 (b) montre que si le membre D s'en va, la communauté initiale se scinde en deux composantes qui ne peuvent plus communiquer l'une avec l'autre. Il faudrait, par exemple, que deux des voisins immédiats de D créent un lien pour maintenir la communauté, comme illustré à la figure 1.1 (c). Nos algorithmes d'évolution du réseau devront donc, en plus de maintenir les propriétés structurales pour une navigation efficace, proposer aussi des mécanismes de relais pour éviter de telles situations, et ce, tout en s'assurant que les propriétés structurales imposées pour favoriser la navigation sont respectées.
Ensuite, non seulement la structure inteme de nos communautés déjà formées risque de changer, comme on vient de l'expliquer, mais de plus, de nouveaux individus arrivent constamment dans le réseau et ceux-ci deviennent des membres potentiels pour ces communautés. Cependant, il n'est pas sûr qu'un individu qui arrive dans le réseau trouve tout de suite une communauté d'appartenance (et l'on suppose ici qu'il en existe une). S'il ne trouve pas, il forme donc une nouvelle communauté qui ne contient pour le moment qu'un seul individu. Puis, au fil du temps, d'autres individus de même profil qui arrivent dans le
réseau peuvent finir par se greffer à cette nouvelle communauté. Cependant, la communauté existante qui aurait pu être trouvée, au départ, existe encore. Ce phénomène a donc pour effet de produire différentes communautés éparpillées dans le réseau, qui partagent les mêmes intérêts, mais qui ne se connaissent pas encore. Le problème ici est donc de réunir ces communautés d'intérêts similaires dispersées dans le réseau.
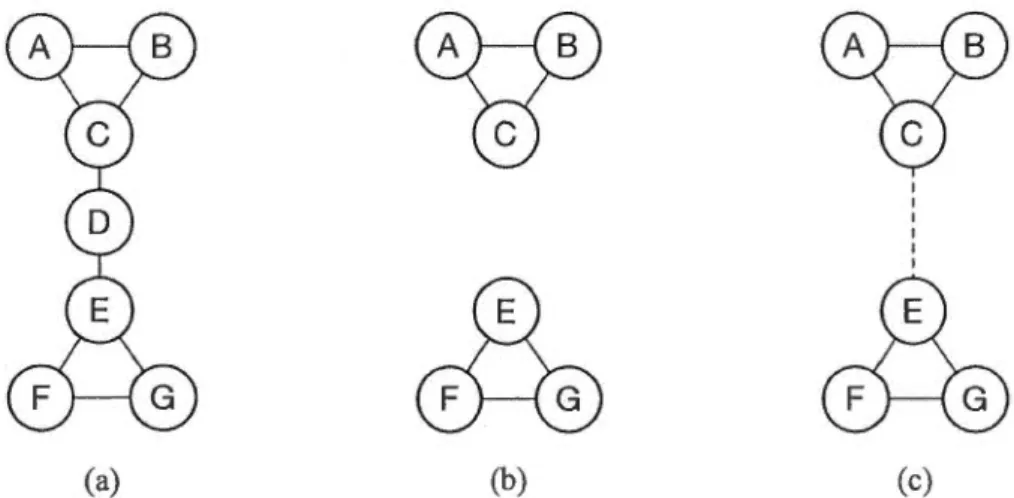
(a) (b) (c)
Figure 1.1 Problème de séparation des communautés lorsqu'un individu quitte le réseau.
En considérant le réseau de la figure (a) comme une communauté d'intérêt, la figure (b) montre que la déconnexion du nœud D aura pour effet de scinder la communauté initiale en deux communautés distinctes. La figure ( c) montre la nécessité de prévoir un mécanisme de relais pour éviter cette situation.
On a vu que c'est par les parcours de socialisation qu'un individu peut rencontrer d'autres individus de profil similaire. Lorsque deux individus se trouvent, on veut donc les réunir. Cependant, chacun des deux individus appartient peut-être déjà à une communauté d'intérêt. Si tel est le cas, on sait qu'on peut aussi fusionner les deux communautés d'appartenance de chacun d'eux qui sont nécessairement d'intérêts similaires. La socialisation d'un seul individu a donc pour effet de réunir les communautés d'intérêt similaires qui sont dispersées dans le réseau, et profite à tous les membres des deux communautés ainsi fusionnées en une seule. Le procédé est le même lorsqu'au cours d'un parcours de socialisation, on effectue une recommandation. On opère encore une fusion des communautés d'appartenance des deux individus recommandés l'un à l'autre. Ce mécanisme de réunion des communautés s'apparente (sans être identique, cependant) à un phénomène qu'on observe dans nos réseaux sociaux réels qui est la tendance à former des relations avec les amis de nos amis. Au chapitre 2 (voir
sect. 2.3), nous présenterons ce processus de transitivité, aussi connu sous le nom de fermeture des triangles dans la littérature. Notre objectif est donc d'incorporer, dans nos algorithmes d'évolution du réseau, ce mécanisme de fusion des communautés lors des rencontres et des recommandations effectuées dans un parcours de socialisation, et ce, tout en maintenant constamment les propriétés structurales imposées pour la navigabilité du réseau.
Finalement, ce n'est pas tout de rapprocher les individus d'intérêts similaires, le problème ici, est de les organiser, de les connecter de manière à ce qu'ils puissent se trouver, se visiter facilement à l'intérieur d'une même communauté. Il faut que la structure des regroupements induise naturellement un chemin optimal pour qu'un individu puisse parcourir tous les membres de sa communauté ; on ne veut pas refaire de parcours de socialisation chaque fois que l'on désire visiter un membre de notre propre communauté. Évidemment, on crée des communautés pour favoriser l'échange entre les individus qui se ressemblent, ceux-ci doivent donc pouvoir se côtoyer sans difficulté.
Comme on le sait, un individu connaît la liste de ses voisins immédiats. Cependant, certains voisins peuvent ne pas être de même profil que lui : si tous les individus ne possédaient que des voisins de même profil, les communautés seraient toutes séparées les unes des autres en composantes distinctes dans le réseau. Dans nos réseaux sociaux réels, on possède beaucoup de contacts qui ne partagent effectivement pas nos intérêts, ce peut être des membres de notre famille, des collègues de travail, etc. Cependant, cette variété de contacts constitue une richesse en soi et ce sont ceux-là qu'on "partage" lorsqu'on agit en tant qu'intermédiaire entre deux individus qui, on le pense, auraient intérêt à se connaître (on les recommande l'un à l'autre).
Au point de vue structural, on comprend aussi qu'un tel partitionnement des communautés n'est pas souhaitable puisqu'un individu présent dans une composante ne pourrait jamais être découvert par un autre individu qui socialise dans une autre composante. En effet, la connexité du réseau fait partie des propriétés structurales de base qu'on impose lors de l'évolution des réseaux générés par notre modèle.
19
Alors, étant donné l'information locale disponible dans ces conditions, nos algorithmes d'évolution de réseaux doivent non seulement former, maintenir et renouveler les communautés, mais aussi les former de manière à ce qu'un individu puisse visiter tous les membres de sa communauté, de manière optimale ; en ne parcourant pas plus de liens qu'il n'y a d'individus dans sa communauté.
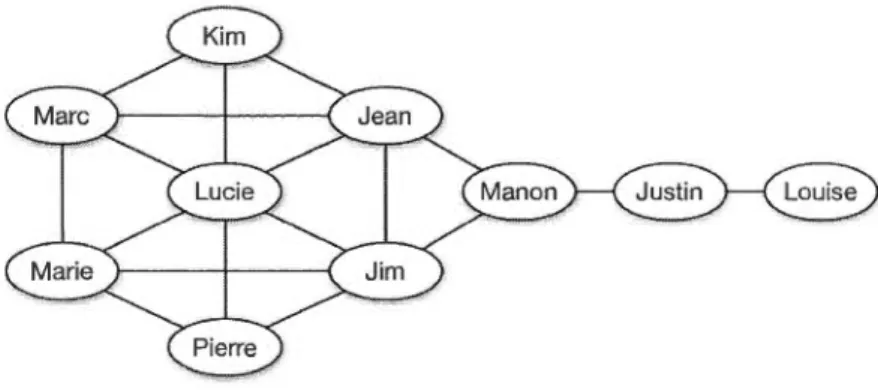
Par exemple, la figure 1.2 montre un réseau qui contient trois communautés différentes (représentées par trois couleurs différentes). On remarque que l'individu A possède un voisin immédiat blanc, un voisin immédiat gris et un voisin immédiat noir. En considérant seulement la structure (en oubliant les couleurs), on ne peut pas savoir si A appartient à la communauté noire, à la communauté grise ou à la communauté blanche, ou s'il fait même partie d'une de ces communautés. La seule façon de le savoir serait pour A de refaire une comparaison entre son profil d'intérêt et celui de chacun de ses voisins immédiats, pour déterminer lesquels sont de même profil que lui et appartiennent donc à sa communauté. Cependant, l'objectif de réunir les individus en communautés est justement de ne plus avoir à refaire ces comparaisons. On veut qu'une fois rassemblés, les individus puissent se visiter facilement.
Figure 1.2 Problème d'identification de la communauté d'appartenance d'un individu.
Dans le graphe illustré, on remarque que lorsqu'on ne connaît pas le profil (la couleur) des différentes communautés, on ne peut pas déterminer la communauté d'appartenance du nœud A.
De plus, lors d'une visite communautaire, supposons que A identifie son voisin immédiat similaire (B) dans la communauté blanche et qu'il désire visiter tous les membres de sa communauté. Disons qu'il choisit C comme prochain individu à visiter, puis qu'il choisit G, et puis H. Arrivé sur H, il n'a plus aucun choix possible et doit donc nécessairement revenir sur ses pas pour continuer son parcours. Dans ce cas, il pourrait revenir sur G ou sur C pour reprendre son parcours en choisissant un autre voisin qui n'a pas encore été visité. C'est ce retour arrière qu'on aimerait minimiser. Cette manière de faire suppose aussi que l'individu qui visite sa communauté conserve en mémoire tous les chemins vers tous les individus qu'il a visités, mais dont il n'a pas encore visité tous les voisins.
Encore une fois, nous voulons que les membres d'une communauté soient facilement accessibles les uns aux autres. Notre objectif est donc de trouver une façon de structurer les communautés au sein du réseau, en accord avec les propriétés structurales imposées pour la navigabilité, de telle sorte qu'elles induisent des parcours de visites communautaires simples et efficaces, sans avoir à comparer les profils pour pouvoir identifier les membres de sa propre communauté. Au chapitre 3, nous expliquerons plus en détail le type de structure des communautés que nous proposons pour aborder ce problème.
La difficulté de former, maintenir et renouveler automatiquement les communautés d'intérêts au sein d'un réseau décentralisé et en constante évolution constitue la problématique principale de cette thèse.
D'un point de vue informatique, nous faisons donc l'hypothèse que les mécanismes de socialisation, comme les rencontres et les recommandations qui sont effectuées au cours des parcours de socialisation, favorisent le regroupement des individus ayant des intérêts en commun. De plus, nous pensons qu'en contrôlant l'aspect structural du réseau, ces mécanismes de socialisation peuvent être implémentés de telle sorte qu'ils forment et maintiennent des réseaux qui favorisent la navigabilité, et donc la localisation d'individus similaires. La découverte d'individus similaires favorisant à son tour le rassemblement des communautés d'intérêt similaires qui étaient éparpillées dans le réseau, assure ainsi le renouvellement continuel des communautés dans un réseau en constante évolution.
Nous proposons donc de concevoir un modèle dynamique de réseaux sociaux dont l'évolution est basée principalement sur les mécanismes de socialisation et qui génère des réseaux possédant des caractéristiques structurales favorisant à la fois la navigabilité dans le réseau, et la formation de regroupements d'individus d'intérêts similaires pouvant aisément communiquer entre eux.
En résumé, nos algorithmes d'évolution du réseau devront gérer • l'arrivée et le départ d'individus,
• la création et la cessation de relations,
• les parcours de socialisation avec rencontres et recommandations (qui sous-entend ici la réunion d'individus et de communautés similaires)
et devront produire des réseaux • toujours connexes,
• qui permettent une navigation efficace lors des parcours de socialisation, • qui forment, maintiennent et renouvellent les communautés d'intérêt, • qui produisent des structures de communautés non équivoques.
Nous verrons aussi au chapitre 2, que les réseaux sociaux réels ne se forment pas de manière complètement aléatoire, mais qu'ils montrent plutôt des propriétés structurales particulières, récurrentes, qui suggèrent ainsi des processus d'évolution intrinsèques des réseaux.
Manifestement, notre choix de contrôler la structure du réseau dans le modèle que nous proposons est motivé par des raisons fonctionnelles (la navigabilité) cependant, la solution proposée est en partie cognitive. Dans cette optique, on peut considérer les mécanismes de socialisation en tant que processus d'évolution des réseaux sociaux.
D'un point de vue sociocognitif, nous faisons donc l'hypothèse que les mécanismes de socialisation peuvent servir à expliquer, du moins en partie, la manière dont se forment les réseaux, comment ceux-ci en viennent à posséder les propriétés structurales particulières
qu'on observe généralement dans les réseaux sociaux réels. Nous analyserons donc la structure des réseaux générés par notre modèle de socialisation pour comparer leurs propriétés structurales à celles qu'on observe dans nos réseaux sociaux habituels.
II est possible (mais nous ne tentons pas de le prouver) que nos réseaux sociaux se forment et se renouvellent dans le temps de manière à ce qu'ils nous soient utiles pour vivre en société. Nos relations sociales nous procurent, en effet, un certain capital social. L'idée principale derrière la notion de capital social est que l'investissement dans les relations sociales produit des bénéfices (Borgatti et Jones, 1998 ; Lin, 1999). Les individus socialisent, ils interagissent entre eux et se font de nouveaux contacts parce que ça leur est profitable. Par exemple, les liens sociaux permettent aux individus d'avoir accès à l'information et aux opportunités autrement inaccessibles, de se bâtir une bonne réputation qui favorise leur crédibilité sociale, de renforcer leur identité et leur sentiment d'appartenance par la reconnaissance des pairs, etc. Le capital social est alors cette valeur ajoutée que nous procurent nos relations sociales.
En termes de réseaux sociaux, des sociologues comme (Burt, 1992), par exemple, ont suggéré que certaines configurations des relations d'un acteur au sein d'un réseau sont plus profitables que d'autres ; que la position des acteurs dans un réseau influence directement leur source d'opportunités ainsi que leur lot de contraintes. Dans cet esprit, nous faisons aussi l'hypothèse que les mécanismes de socialisation favorisent, dans une certaine mesure, la création de capital social. Nous verrons, au chapitre 2 (voir sect. 2.3), des indicateurs de capital social que nous utiliserons ensuite pour mesurer le capital social dans les réseaux générés par simulation de notre modèle de socialisation.
La section suivante présente une autre problématique connexe, mais que nous n'abordons que partiellement dans le cadre de cette thèse.
1.2.2 Problème de l'évolution des profils d'intérêts
Pour construire des réseaux qui forment et perpétuent automatiquement les communautés d'intérêt, il faut pouvoir déterminer le niveau de similarité entre les individus. Pour ce faire, il