Network-friendly box-powered video delivery system
Texte intégral
Figure

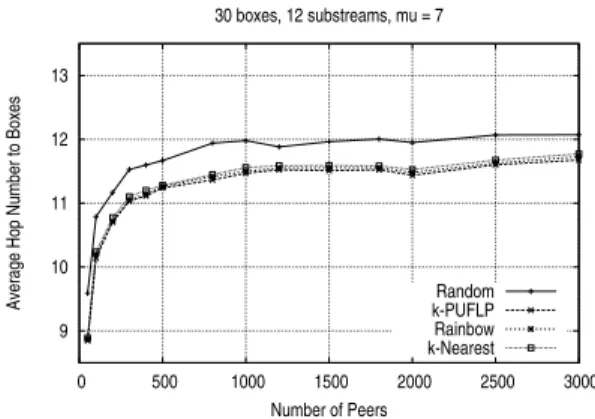
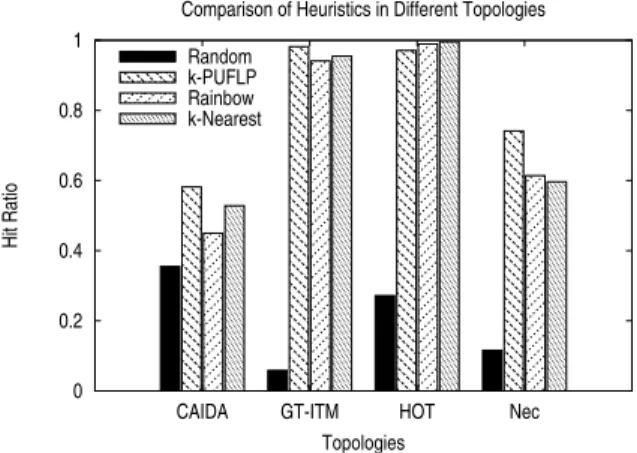
Documents relatifs
[r]
What we want to do in this talk is firstly to explain when (§1) and why (§2) a presupposition trigger becomes obligatory in the very case where it is redundant, and secondly
For if you remain silent and I confess, I shall get what I most want, no sentence at all ; whereas if you confess, then I shall do much better by confessing too (five years) than
Formally prove that this equation is mass conser- vative and satisfies the (weak) maximum principle.. 4) Dynamic estimate on the entropy and the first
We define a partition of the set of integers k in the range [1, m−1] prime to m into two or three subsets, where one subset consists of those integers k which are < m/2,
The paper is organised as follows: in Section 2, we give the basics of the behavioural theory of imprecise probabilities, and recall some facts about p-boxes and possibility mea-
If we measure centralities by means of unlabelled graphs, we may be rather misleading in defining the relevance or importance, in some sense of a vertex in the graph, since
In this paper, we assess the functional requirements of digital Musicology research questions, and propose ways for using the inherent semantics of workflow descriptions
