Optimism in Reinforcement Learning and Kullback-Leibler Divergence
Texte intégral
Figure
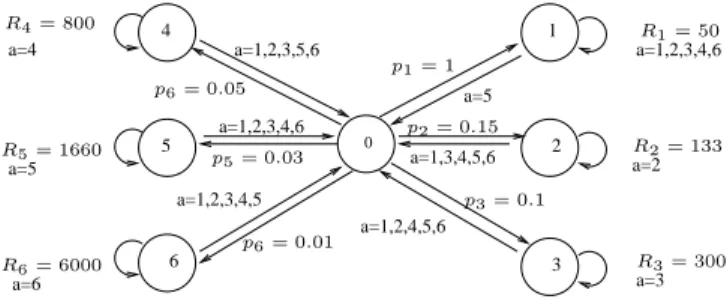
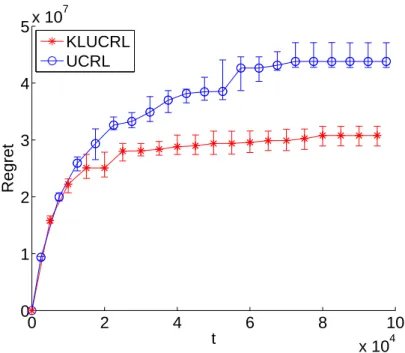
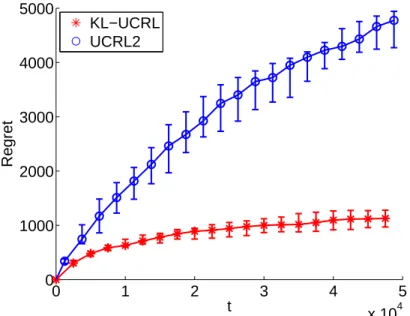
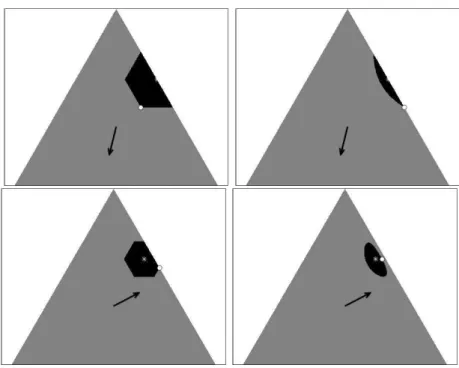
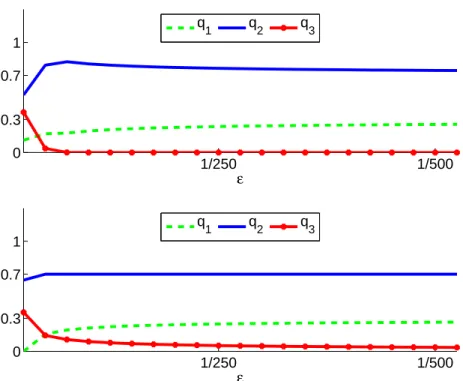
Documents relatifs
Cette partie décrit le comportement de fonctions de correspondances de modèles populaires de Recherche d’Information pour la contrainte DDMC. Nous passons en revue le modèle
Divergence de Kullback-Leibler en grande dimension pour la classification des prairies à partir de séries temporelles d’images satellite à haute résolution.. 48èmes Journées
Value of the objective function at each iteration solving Problem (2) varying the number of iterations to solve each ND problem..A. We appreciate that setting the number of
We propose two statistical classifiers for encrypted Internet traffic based on Kullback Leibler divergence and Euclidean distance, which are computed using the flow and packet
The ’global’ spectral analysis approach is applied to experimen- tal vibration signals generated by different types and sizes of bearing faults, for different operating points..
In this study, a statistical model is proposed to identify grassland management practices using time series of a spec- tral vegetation index (NDVI) with high temporal
(1997) gave an overview of several techniques of estimation. Two methods have been selected. The first one is a Monte Carlo method where the density function is replaced with
A comparative study between some multivariate models on the VisTex and Outex image database is conducted and reveals that the use of the MGΓU distribution of chromi- ance
