Aggregating Interval Orders by Propositional Optimization
12
0
0
Texte intégral
Figure

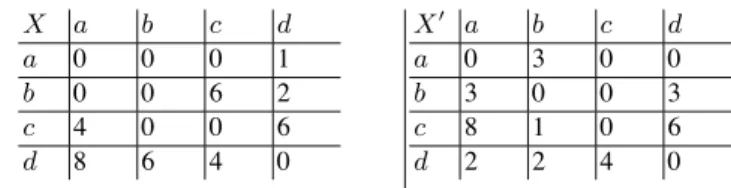
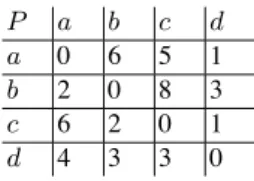
Documents relatifs
