Multidimensional Poverty Dominance: Statistical Inference and an Application to West Africa
Texte intégral
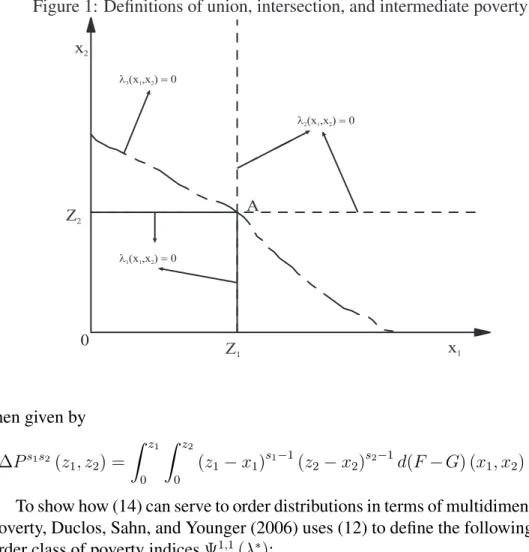
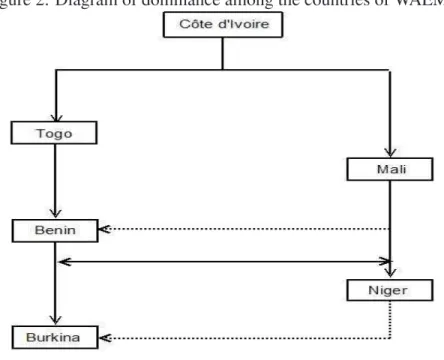
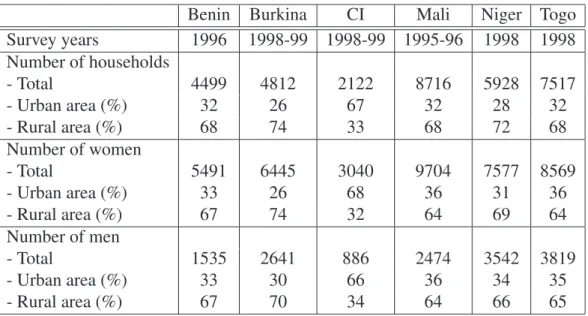
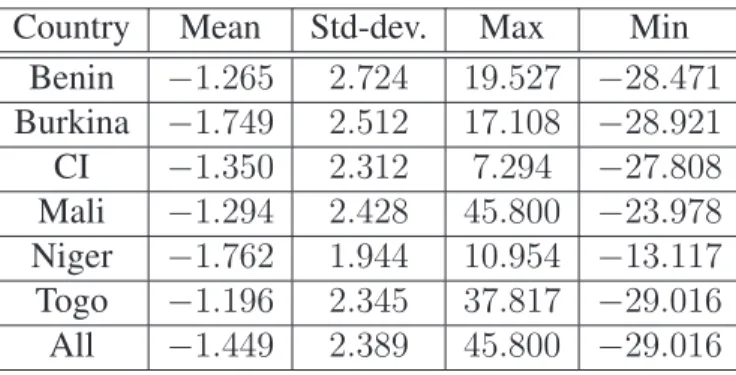
Figure

![Table 6: Tests for first-order stochastic dominance, country F versus country G, over a [z − , z + ] interval](https://thumb-eu.123doks.com/thumbv2/123doknet/7705677.246403/25.918.180.737.422.809/table-tests-stochastic-dominance-country-versus-country-interval.webp)
![Table 7: Tests of first-order stochastic dominance, rural area (F ) versus urban area (G) within different countries, over a [z − , z + ] interval](https://thumb-eu.123doks.com/thumbv2/123doknet/7705677.246403/26.918.196.719.321.527/table-tests-stochastic-dominance-versus-different-countries-interval.webp)
Documents relatifs
are decomposed into basic word with POS. 4 After this process, we evaluate statistical characteristics of terms about: number of one word terms and number of phrasal terms. In
To better analyze the impact of the explanatory variables on the probability of be- ing poor we apply in the next section the so-called Shapley decomposition procedure, a technique
La cobertura de los sistemas previsionales en América Latina: conceptos e indicadores (E.T.: Pension coverage in Latin America: concepts and indicators). Serie de Documentos
An important conclusion of this study is that a large majority of emaSwati children are deprived in more than one dimension of well-being at a time. It is therefore imperative
In particular, a multidimensional poverty measure takes into consideration all dimensions of well-being that may be of relevance (including non- material attributes such as
Dans cette partie, nous allons brièvement introduire les méthodes théoriques utilisées pour décrire les réactions de transfert, et montrer comment, à partir des
variational characterization of the self similar solution as in [5], or the construction of the solution by bifurcation as in the setting of Proposition 1.1, then the control of
7 If we compare all possible choice correspondences and all possible choices functions and pick one at random in each set, a choice function is 400 times more likely to satisfy WARP
