L'HYPERTEXTE COMME MODE D'EXPLOITATION DES RESULTATS D'OUTILS ET METHODES D'ANALYSE DE L'INFORMATION SCIENTIFIQUE ET TECHNIQUE
Texte intégral
Figure
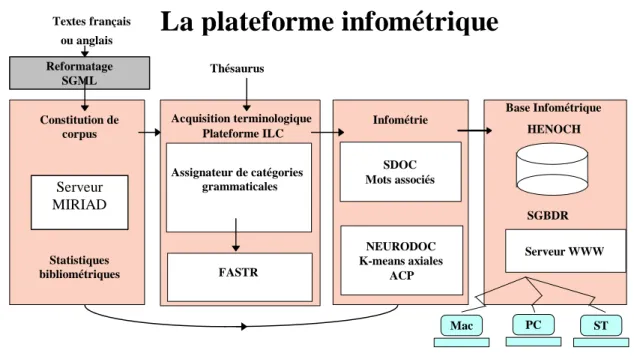
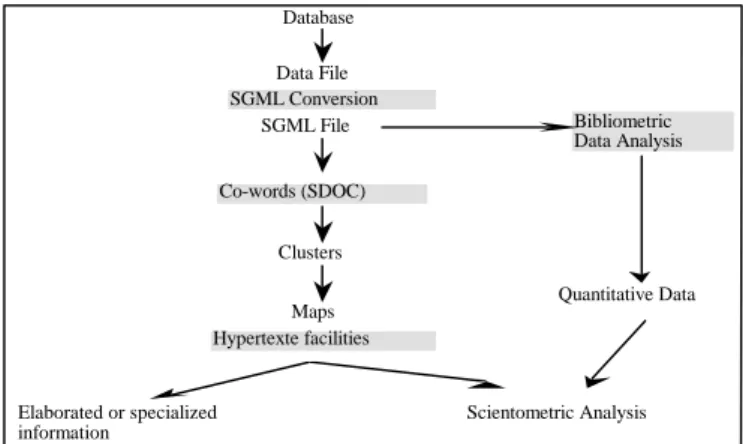


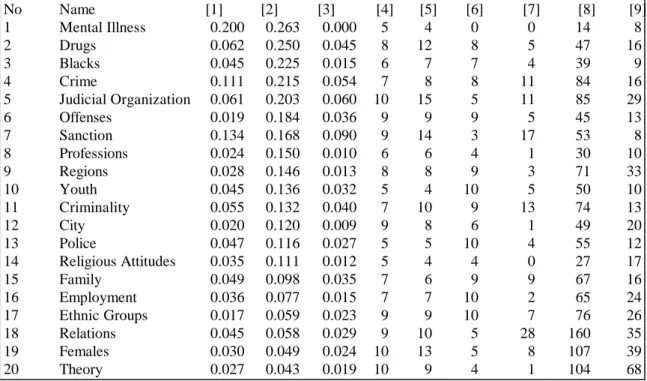

Outline
Documents relatifs
Suite au décès tragique de Mme Adeline Morel, ses proches, l’Etat de Genève et les Hôpitaux universitaires de Genève, ont abouti à un accord sur le règlement des
3- Ne cessant d’améliorer notre commande, nous avons constaté qu’un phénomène d’oscillation de l’eau autour d’un niveau provoque de nombreux démarrage et arrêt
On décompose le volume du liquide en rotation en couronnes cylindriques de rayon r, d’épaisseur dr et de hauteur z(r). Exprimer le volume dV d’une telle couronne. En supposant que
à un monde a dire" et à un · ,outil systémique: le langage, dans la communication désignée comme c~~tractuelle. Autrement dit, elle est issue.. de la théorie
L’agriculture étant le premier moteur de la déforestation en Côte d’Ivoire (DSRP, 2009) 2 , le MINAGRI devrait, dans le cadre du mécanisme REDD+ et conformément au décret portant
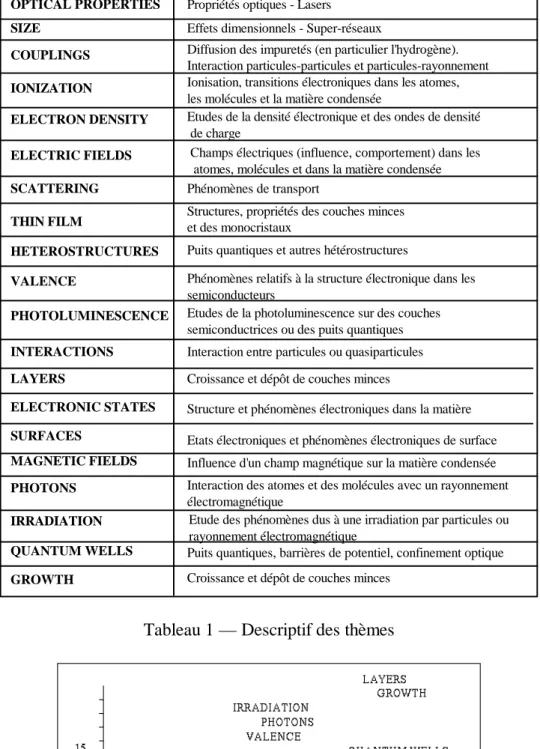
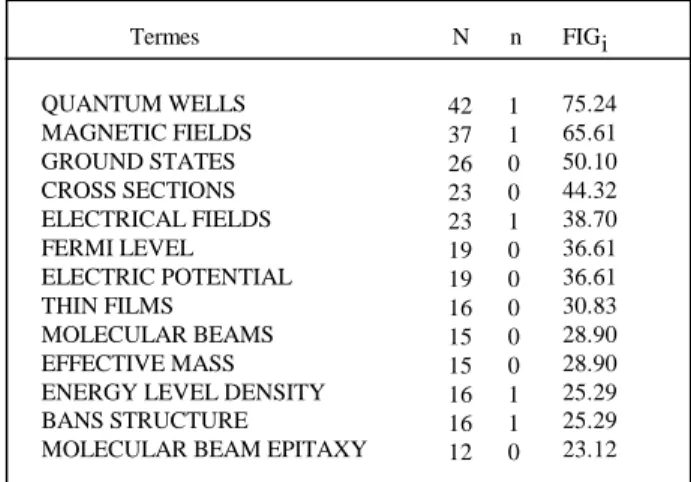
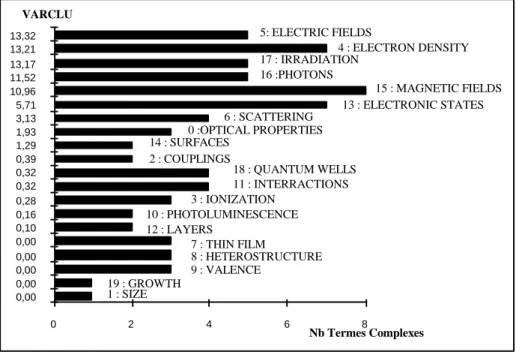
L’analyse de la structure des liens repose sur l’hypothèse que la structure hypertexte a un rôle sémantique dans l’interprétation des contenus des documents. En d’autres
o La signature doit être manuscrite en cas de réponse sur support papier. o La signature doit être authentifiée par un certificat de signature électronique en cas de réponse par
If the supply hub is good and the reference code continues to occur, exchange the remaining FRUs as needed, and run test 89 after each FRU is exchanged to verify the repair.. If
