Identifying and exploiting problem structures using explanation-based constraint programming
Texte intégral
Figure
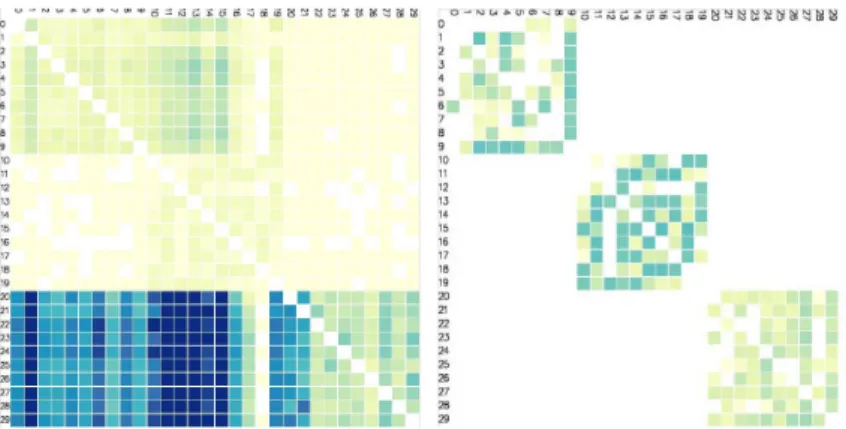

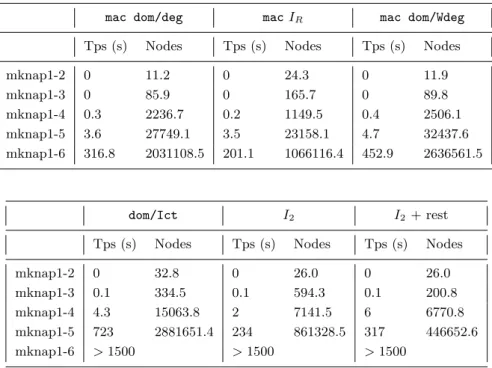
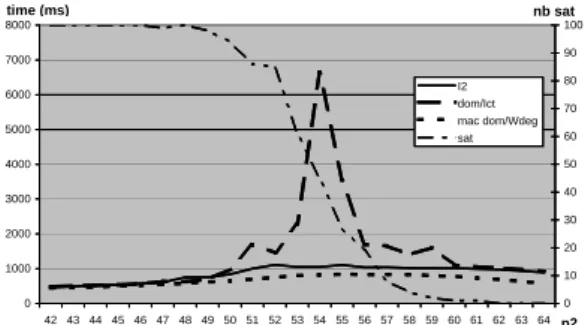
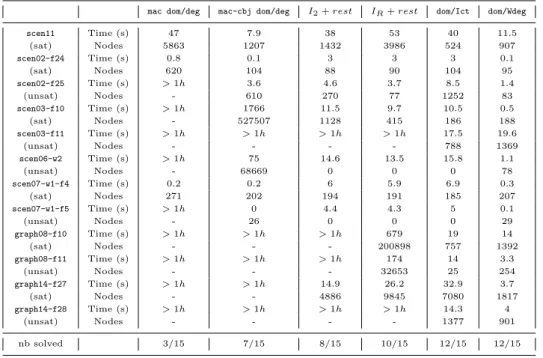

Documents relatifs
En conclusion, cette étude a permis de donner certaines informations sur les raisons les plus importantes de l’augmentation du taux de la réforme involontaire des vaches
On the one hand, turning from traditional extraction of red oil palm into artisanal extraction using a small- scale mill does not affect the quality of the oil and significantly
The objective is to cut datacenters operating costs and improve resource uti- lization by reducing the number of physical machines and using virtualization technology. In order
To deal with the continuous search scenario, we follow the same approach as in [1], where the authors propose to use a supervised Machine Learning algorithm to select the
Mariam El Khatib, Philippe Ferrandis, Erwan Morvan, Gérard Guillot, Georges Bremond. Al- GaN/GaN metal-insulator-semiconductor capacitors with a buried Mg doped layer characterized
En mode III (Fig.III.39.c), en pendant que le patient monte les escaliers, les deux pointes de fissures se développe pratiquement avec la même cinétique (les facteurs
«Il ne s'agit plus là d'une revue au sens traditionnel du terme, puisque ce titre publie presque chaque mois une œuvre, le plus souvent un roman, en entier, en
At the crossroad of CP and MCTS, this paper presents the Bandit Search for Constraint Program- ming ( BaSCoP ) algorithm, adapting MCTS to the specifics of the CP search.
