HAL Id: tel-02524210
https://tel.archives-ouvertes.fr/tel-02524210
Submitted on 30 Mar 2020HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
Cecile Issard
To cite this version:
Cecile Issard. Dealing with acoustical variability in speech at birth. Cognitive Sciences. Université Sorbonne Paris Cité, 2018. English. �NNT : 2018USPCB173�. �tel-02524210�
UNIVERSITÉ PARIS DESCARTES
École doctorale 261 : Cognition, Comportements, Conduites Humaines
Laboratoire Psychologie de la Perception
Dealing with acoustical variability in
speech at birth
Par Cécile Issard
Thèse de doctorat de Neurosciences Cognitives
Dirigée par Judit Gervain
Présentée et soutenue publiquement le 29 novembre 2018
Devant un jury composé de :
Judit Gervain Directrice de thèse - CNRS & Université Paris Descartes
Anne-Lise Giraud Rapporteuse - Université de Genève
Fabrice Wallois Rapporteur - Université Jules Verne de Picardie
Gábor Háden Examinateur - Hungarian Academy of Sciences
3
Titre : Construction d’une représentation stable de la parole chez le nouveau-né humain
Résumé :
La parole représente probablement le son naturel le plus important pour l’homme. Les sons de parole étant variables, réagir préférentiellement aux sons de parole im-plique de répondre à la gamme de paramètres acoustiques qu’ils peuvent prendre. En effet, nous avons tous une voix différente, nous parlons avec des intonations différentes et nous avons peut-être un accent étranger, mais ceux qui nous écoutent perçoivent toujours les mêmes mots et les mêmes phrases. Cela implique que nous avons extrait des unités linguistiques invariantes à partir de sons variables. De même, les enfants apprennent leur langue maternelle à partir de différents locu-teurs qui parlent avec des rythmes différents et des intonations différentes d’un moment à l’autre. Cela implique que, dès le début de leur vie, les humains sont capables de former directement des objets invariants à partir du son variable. Pour cela, le code neural doit être flexible envers les paramètres acoustiques que les sons de la parole peuvent prendre, conformément à l’idée que les étages supérieurs du système auditif sont sensibles à la présence d’entités auditives abstraites (ici la parole), plutôt qu’à des paramètres spectro-temporels absolus. Une question clé est donc de savoir comment les humains parviennent à extraire ces représentations invariantes des sons de parole dès le début de leur vie. Cette thèse vise à décou-vrir comment celles-ci sont construites chez le nouveau-né humain en mesurant les réponses hémodynamiques et électrophysiologiques du nouveau-né à la parole naturelle et à la parole modifiée temporellement ou spectralement.
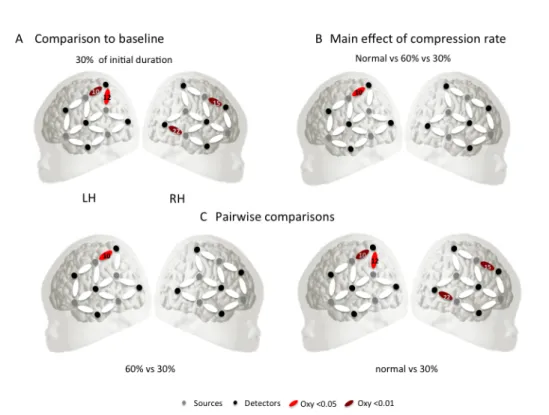
Lors d’une première expérience, nous avons présenté de la parole normale ainsi que de la parole modérément compressée (60% de la durée initiale) ou fortement compressé dans le temps (30% de sa durée initiale) dans la langue maternelle des participants. Nous avons enregistré la réponse hémodynamique à ces stimuli sur les cortex frontal, temporal et pariétal à l’aide de la NIRS. Les résultats ne montrent aucune différence entre la parole normale et la parole compressée à 60 %, mais des réponses différentielles entre la parole normale et la parole compressée à 30 % ainsi qu’entre la parole compressée à 60 % et la parole compressée à 30 % dans un en-semble de régions frontales, temporales, et temporo-pariétales, de la même manière que le cerveau adulte. Ceci montre que le cerveau du nouveau-né répond à la pa-role de manière stable sur une gamme d’échelles de temps similaire à celle observée précédemment chez l’adulte. Dans une deuxième série d’expériences, nous nous sommes demandé si cette capacité s’appuie sur l’expérience prénatale de la struc-ture rythmique de la langue maternelle. Nous avons reproduit la même expérience dans deux langues inconnues, l’une rythmiquement similaire à la langue maternelle (l’espagnol) et l’autre rythmiquement différente (anglais). En anglais, seule la pa-role compressée à 30% évoque des réponses significatives dans une région temporo-pariétale également activée pour le français, mais le schéma exact d’activations est différent de celui du français. Cela confirme que la parole compressée à 30% est
traitée différemment de la parole normale et de la parole compressée à 60%. Cela montre également que l’expérience prénatale façonne le traitement de la parole à la naissance. En particulier, une expérience prénatale de la structure prosodique ou phonologique de la langue pourrait aider les nourrissons à coder la parole de manière stable en fournissant des repères auditifs dans le signal.
En conclusion, les résultats présentés dans cette thèse soutiennet l’idée que la parole est codée comme un objet auditif abstrait dès les premières étapes du traite-ment auditif. Ce code auditif est en outre modulé par un traitetraite-ment linguistique de plus haut niveau, intégrant la connaissance de la langue maternelle de l’auditeur. Ces connaissances sont probablement acquises à partir de la vie intra-utérine, ce qui permet un codage stable de la parole, adapté à l’environnement linguistique de l’auditeur dès la naissance.
Mots-clés : Variabilité acoustique, perception de la parole, nouveau-nés,
spec-troscopie de proche infrarouge, électro-encéphalographie.
Abstract:
Speech probably represents the most important natural sound for humans. As speech sounds are variable, responding preferentially to speech sounds implies responding to the range of acoustical parameters that they can take. Indeed, we all have a different voice, we speak with different melodies, and we might have a foreign accent, but those who listen to us still all perceive the same words and phrases. This implies that we have extracted invariant linguistic units from variable sounds. Similarly, infants learn their native language from various speakers who speak with different speech rates and voice qualities from moment to moment. This means that, from the beginning of their life, humans are able to directly form invariant objects from the raw, variable sound. This implies that the auditory code should be flexible towards the broad range parameters than speech sounds can take, consistent with the idea that the higher stations of the auditory system are sensitive to the presence of abstract auditory entities (in our case speech), rather than absolute spectro-temporal parameters. Therefore a key question is how humans manage to extract these invariant representations of speech sounds from the beginning of their lives. The present thesis aims to uncover how these invariant representations of speech are built in human newborns by measuring newborns’ hemodynamic and electrophysiological responses to natural speech, and temporally or spectrally modified speech.
In a first experiment, we presented normal speech as well as moderately (60% of initial duration) or highly time-compressed (30% of its initial duration) speech in the participants’ native language (French). We recorded the hemodynamic re-sponse to these stimuli over the frontal, temporal and parietal cortices using NIRS. The results show no difference between normal and 60%-compressed speech, but differential responses between normal and 30%-compressed speech as well as
be-5 tween 60%- and 30%-compressed speech in a set of frontal, temporal, and temporo-parietal regions, similarly to the adult brain. This provides evidence that the newborn brain responds to speech in a stable manner over a range of time-scales that is similar to previous findings in adults. In a second set of experiments, we asked whether this ability relies on prenatal experience with the native language’s rhythmic structure. We replicated the same experiment in two unfamiliar lan-guages, one that is rhythmically similar to the native language (Spanish), and one that is rhythmically different (English). In English, only 30%-compressed speech evoked significant responses in a temporo-parietal region also activated for French, but the exact pattern of activations was different from those for French. This confirms that 30%-compressed speech is processed differently than normal and 60%-compressed speech. This also shows that prenatal experience shapes speech processing at birth. In particular, prenatal experience with the prosodic or phono-logical structure of the language might help infants encode speech in a stable way by providing auditory landmarks in the signal.
To conclude, the results presented in this thesis support the idea that speech is encoded as an abstract auditory object from the first stages of auditory process-ing. This auditory code is further modulated by higher level linguistic processing, integrating knowledge of the listener’s native language. This knowledge is likely acquired from intra-uterine life, enabling a stable encoding of speech, adapted to the listener’s linguistic environment from birth.
Keywords: Acoustical variability, speech perception, newborns, near-infrared spectroscopy, electro-encephalography.
Dédicace
Il paraît que personne ne lit les thèses. Pour ma part j’en ai lues plusieurs. Pour m’inspirer, pour trouver une revue de la littérature complète, ou tout simplement parce-que les travaux qu’elles rapportaient n’avaient pas été publiés ailleurs. Je dédis cette thèse à mes lecteurs potentiels, en espérant que ce manuscrit vous apporte quelque chose.
Acknowledgement
Une thèse est toujours un travail collectif. Je souhaite remercier toutes les personnes qui, de près ou de loin, ont contribué à ce projet.
Judit tout d’abord, merci de m’avoir poussée à défendre mes idées et de m’avoir appris à les exprimer clairement, dans un cadre théorique solide et cohérent.
Je remercie également ceux qui m’ont tranmis leurs expertises techniques ou ont répondu à mes questions bizarres : Renske Huffmeijer, Laura Dugué, Lionel Granjon, Nawal Abboub, Fabrice Wallois, Mehdi Mahmouzadeh, Adalan Aarabi, Chris Angeloni.
J’ai eu la chance de connaitre des laboratoires où règnait une atmosphère d’émulation. Thierry, je me suis souvent sentie comme un ovni dans ton équipe, mais j’admire toujours la cohésion qui y règne. Arlette, tu m’as transmis ton intérêt pour les nouveau-nés, et égayé mes déjeuners avec tes histoires abracadabrantes. Alejandrina, les quelques mois à travailler pour toi ont été une véritable bouffée d’oxygène. Maria, les quelques semaines passées dans votre laboratoire demeurent comme une parenthèse lumineuse dans ces quatre années, grâce à laquelle j’ai ensuite pu voir mon travail sous un autre angle. Merci pour votre soutien sans faille.
Merci aussi à tous ceux qui, par un regard, une écoute, un mot ou un geste, m’ont retenue ici: Elena Koulagina, Lucie Martin, Laurianne Cabrera, Carline Bernard, Léo Nishibayashi, Sophie Bouton, Maxine Dos Santos, Katie Von Holzen, Viviane Huet, Mélanie Hoareau, Caterina Marino, Vincent Forma, Arielle Veen-emans, Sergiu Popescu, Lisa Jacquey, Daphné Rimsky-Robert, Solène Le Bars, ainsi que tous mes amis.
Je remercie également ma famille qui, par son ignorance totale des sciences cognitives, m’a obligée à savoir vulgariser sans (trop) trahir les résultats. Vous avez été de supers cobayes pour le recrutement de familles à la maternité !
Enfin, Sandro, mon premier conseiller et soutien. Merci d’avoir été toujours présent et un parfait petit elfe de maison dans les dernières semaines.
Contents
Contents 9 List of Figures 13 List of Tables 17I
General Introduction
19
1 Theoretical background 231.1 What is a speech sound? . . . 23
1.1.1 Spectral characteristics of speech sounds . . . 23
1.1.2 Temporal characteristics of speech sounds . . . 24
1.1.3 Speech sounds are variable . . . 27
1.2 A stable perception of a variable sound . . . 30
1.2.1 Adaptation to spectral variability . . . 30
1.2.2 Adaptation to temporal variability . . . 32
1.3 Acoustical variability at birth . . . 34
1.3.1 Why newborns . . . 34
1.3.2 Auditory processing at birth . . . 35
1.3.3 Stable perception of speech at birth . . . 36
1.3.4 The aims of the current thesis . . . 38
2 Techniques used in this thesis 41 2.1 NIRS . . . 41
2.1.1 Basic principles of NIRS . . . 41
2.1.2 Why use fNIRS in infant research? . . . 43
2.1.3 Limitations of the fNIRS method . . . 44
2.2 EEG . . . 45
2.2.1 Basic principles of EEG . . . 45
2.2.2 EEG in infants . . . 48
2.2.3 Limitations of the EEG method . . . 49 9
II
Experimental contributions
51
3 Responses to time-compressed speech at birth 53
3.1 Introduction . . . 53
3.2 Materials and methods . . . 55
3.2.1 Participants . . . 55
3.2.2 Material . . . 56
3.2.3 Procedure . . . 58
3.2.4 Data processing and analysis . . . 59
3.3 Results . . . 60
3.3.1 Channel-by-channel comparisons . . . 60
3.3.2 Analyses of variance . . . 64
3.4 Discussion . . . 65
3.5 Conclusions . . . 69
4 Role of Linguistic Rhythm 71 4.1 Introduction . . . 71
4.2 Experiment 2.a.: Spanish . . . 74
4.2.1 Materials and Methods . . . 74
4.2.2 Results . . . 79
4.3 Experiment 2.b: English . . . 80
4.3.1 Materials and methods . . . 80
4.3.2 Results . . . 83
4.4 Discussion . . . 84
4.5 Conclusions . . . 89
5 Electrophysiological mechanisms 91 5.1 Introduction . . . 91
5.2 Experiment 3.a.: temporal variability . . . 94
5.2.1 Materials and methods . . . 94
5.2.2 Results . . . 96
5.3 Experiment 3.b.: spectral variability . . . 96
5.3.1 Materials and methods . . . 96
5.3.2 Results . . . 101
5.4 Discussion . . . 102
III
General Discussion
105
6 Theoretical discussion 107 6.1 Limits in auditory processing . . . 1086.2 Prenatal experience . . . 110
CONTENTS 11
7 Perspectives 115
7.1 Replications with simpler experimental designs . . . 115
7.2 Generalization to other acoustical parameters . . . 116
7.3 Brain networks supporting adaptation to spectral variability . . . . 116
7.4 Acoustical subspace of natural speech sounds . . . 117
Bibliography 119 Appendix 1: Issard & Gervain (2018) 141 .1 Variability of the hemodynamic response in infants . . . 141
.1.1 Variation in the shape of the hemodynamic response re-ported in the developmental literature between cortical regions142 .1.2 The factors influencing the hemodynamic response . . . 146
.2 Experimental complexity . . . 148
.2.1 Variation due to stimulus complexity . . . 148
.2.2 Variation related to developmental changes . . . 150
.3 Experiental design . . . 152
.3.1 Simple event-related or block designs . . . 152
.3.2 Repetition effects . . . 153
.3.3 Alternating presentation . . . 154
.4 Conclusions . . . 155
Appendix 2: SI Issard & Gervain (2018) 157
List of Figures
1.1 The vocal system as a carrier circuit . . . 25
1.2 Schematic representation of temporal modulations in speech. A:
Waveform of the original sentence (black), with its envelope super-imposed (red). B: Envelope of the sentence shown in A. C: Temporal fine structure of the sentence shown in A. Adapted from Moon &
Hong (2014). . . 26
1.3 Speech Temporal structure . . . 27
1.4 Spectral variations in the speech signal. Adapted from von
Krieg-stein et al. (2010). . . 28
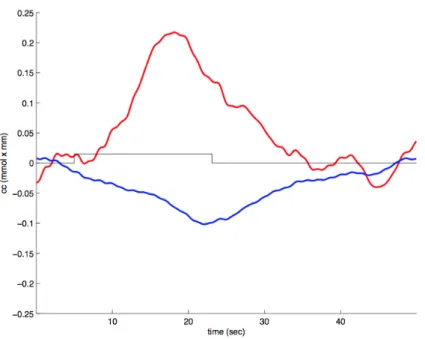
2.1 A typical hemodynamic response as observed in a newborn
partic-ipant in our laboratory. Red: HbO, Blue: HbR, Rectangle:
stimu-lation. . . 42
2.2 Pictures of different fNIRS headgears and their respective
approxi-mative channel locations. A: The UCL system (adapted from Lloyd-Fox et al., 2017). B: The Hitachi ETG-4000 system (adapted from May et al., 2011). C: The NIRx NIRScout system as used in our
laboratory. . . 43
2.3 EEG setup as used in our laboratory. . . 46
3.1 Waveform and spectrogram of french stimuli as used in experiment 1 57
3.2 Experimental design used in experiment 1 . . . 57
3.3 Optode placement in experiment 1 . . . 58
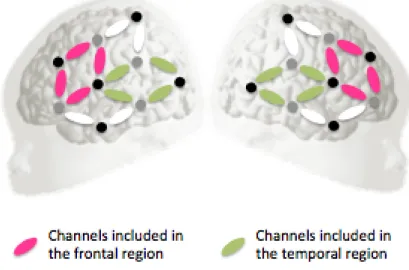
3.4 Regions of interest defined in experiment 1 . . . 60
3.5 Hemodynamic responses obtained in the non-alternating blocks of
experiment 1 . . . 61
3.6 Statistical maps of the results of experiment 1 . . . 62
3.7 Hemodynamic responses observed for 60%-compressed speech in
ex-periment 1 . . . 63
3.8 Results of the analysis by region of interest for 60%-compressed
speech in experiment 1 . . . 64
3.9 Results of the analysis by region of interest for 30%-compressed
speech in experiment 1 . . . 65
4.1 Channel localization as used in experiment 2 and 3 . . . 75
4.2 Waveform and spectrogram of Spanish stimuli as used in experiment
2.a. . . 76
4.3 Experimental design used in experiment 2.a. and 2.b. . . 77
4.4 Hemodynamic responses evoked by each of the three compression
rates in experiment 2.a. (Spanish). Shaded areas represent SEM.
Rectangles represent the stimulation. . . 79
4.5 Hemodynamic responses evoked by the alternating and non-alternating
blocks in the 60% compressed part of experiment 2.a. (Spanish).
Shaded areas represent SEM. Rectangles represent the stimulation. 80
4.6 Hemodynamic responses evoked by the alternating and the
non-alternating blocks in the 30% compressed part of experiment 2.a. (Spanish). Shaded areas represent SEM. Rectangles represent the
stimulation. . . 81
4.7 Waveform and spectrogram of English stimuli as used in experiment
2.b. . . 82
4.8 Hemodynamic responses observed during the non-alternating blocks
in experiment 2.b. . . 83
4.9 Cortical regions activated during the non-alternating blocks in
ex-periment 3 . . . 84
4.10 Hemodynamic responses observed for 60%-compressed speech in
ex-periment 2.b. . . 85
4.11 Hemodynamic responses observed for 30%-compressed speech in
ex-periment 3 . . . 86
4.12 Cortical region activated by 30%-compressed speech in experiment 3 86
5.1 Experimental design used in experiment 3.a. and 3.b. . . 95
5.2 Event-related potentials obtained in experiment 3.a. for each speech
rate. Shaded areas represent SEM. . . 97
5.3 Mean power change for each time-frequency bin in experiment 3.a.
for each speech rate. A: silence, B: 60%-compressed, C: 30%-compressed,
D: normal (100%). . . 98
5.4 Example of a sentence used in experiment 4.b., along with its
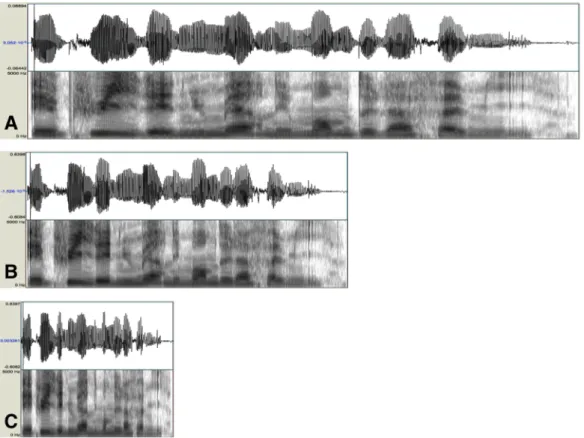
spec-trally distorded analogs. A: Normal. B: FM/4. C: FM*4. Top: sound waveform, middle: spectrogram with formants drawn in red on top, bottom: pitch (F0) contour. . . 100
5.5 Event-related potentials obtained in experiment 3.b. for each F0
range. Shaded areas represent SEM. . . 102
5.6 Mean power for each time-frequency bin in experiment 3.b. A:
silence, B: normal, C: FM/4, D: FM*4. . . 103
1 Canonical (A) and inverted (B) responses as observed in newborn
infants in our laboratory. Red: HbO, blue: HbR. . . 143
2 Hemodyamic response in the temporo-parietal junction as a function
LIST OF FIGURES 15
3 Alternating/non-alternating design with numerous variable stimuli
List of Tables
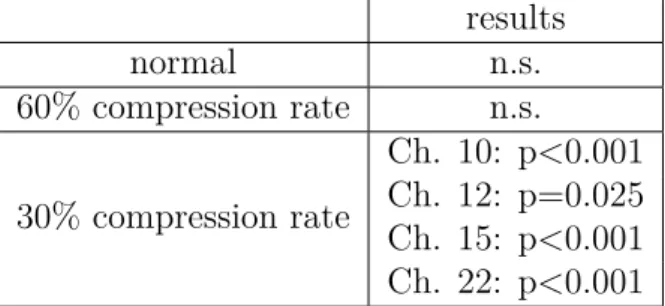
3.1 Statistical comparisons of the three different types of non-alternating
blocks to baseline . . . 61
3.2 Statistical comparisons of the three types of non-alternating blocks
to each other . . . 61
3.3 Statistical comparisons for the alternating and non-alternating blocks
to baseline and to each other . . . 63
The present work has led to the following publications:
Issard, C.& Gervain, J. (submitted). Adaptation to time-compressed speech
in the newborn brain in an unfamiliar language.
Issard, C.& Gervain, J. (2018). Variability of the Hemodynamic Response in
Infants: Influence of Experimental Design and Stimulus Complexity.
Developmen-tal Cognitive Neuroscience.
Issard, C. & Gervain, J. (2017). Adult-like perception of time-compressed
Part I
General Introduction
21 Speech probably represents the most important natural sound for humans. As speech sounds are variable, understanding speech sounds implies responding to the range of acoustical parameters that they can take. Indeed, we all have a different voice, speak faster or slower, the melody of our voice changes all the time, and we might have a foreign accent. Although a word is never pronounced twice the same way, and the sound corresponding to this word is never the same, those who listen to us perceive it as the same word containing the same syllables. We recognize words and other linguistic units although they sound very different, implying that we have extracted invariant linguistic representations from variable
sounds. Similarly, babies learn their native language from numerous speakers
who speak very differently. They hear many voices around them, but they easily learn their native language without explicit training in the first years of life. This means that, as adults, they are able to recognize speech and its linguistic units in various acoustical forms. This is even more impressive than in adults, as infants cannot look for something that resembles a word they already know, but have to directly form an invariant object from the raw, variable sound. This means that the auditory code needs to be flexible towards the broad range parameters than speech sounds can take, consistent with the idea that the higher stations of the auditory system are sensitive to the presence of abstract auditory entities (in our case speech), rather than absolute spectro-temporal parameters. Therefore a key question is how humans manage to extract these invariant representations of speech sounds from the beginning of their life. The present thesis investigates how these invariant representations of speech emerge in human newborns. More specifically, we aim to understand whether and how the newborn brain encodes speech so as to create invariant linguistic representations.
The human brain goes through dramatic changes during development. The auditory coding schemes observed in adult organisms might have emerged from more basic ones present earlier in development. A given function develops based on the already existing material. Thus newborns’ cerebral functional networks constitute the building blocks of the mature systems, in this case speech perception. The newborn brain, therefore, represents an opportunity to understand the initial state of speech encoding.
We seek to establish whether or not newborns can produce stable responses to variable speech sounds, and if yes under what conditions. Intra-uterine life offers an important amount of sensory stimulation. We, therefore, aim to understand how prenatal experience with speech shapes perception, in particular the abil-ity to extract invariance. Specifically, the prosodic structure of language, which is conveyed to the fetus by the uterine environment, might help infants encode speech in a stable way, flagging landmarks in the signal that cue the boundaries of linguistic units. We will address these issues experimentally by testing new-born infants’ brain responses to temporally or spectrally distorted utterances in the native language (French), in a prosodically similar unfamiliar language (Span-ish) and a prosodically different unfamiliar language (Engl(Span-ish) using near-infrared spectroscopy (NIRS) and electroencephalograny (EEG).
This thesis is organized as follows. In the General Introduction, we will first describe what a speech sound is (Chapter 1). We will then review how temporal and spectral variability of speech are managed in human adults. We will then focus on the neonatal population, explaining why it is an interesting one to study sensory processing and speech perception, reviewing the development of auditory perception at birth, and arguing that the numerous speech perception capacities displayed by newborns suggest that they are already able to deal with the acous-tical variability of speech. We will finally describe the two methodologies that we used in the following experimental chapters, namely NIRS and EEG (Chapter 2). Three experimental chapters will then report the NIRS (Chapters 3 and 4), and EEG (Chapter 5) studies conducted. The implications of the obtained results and future perspectives are then discussed in the General Discussion.
Chapter 1
Theoretical background
1.1
What is a speech sound?
1.1.1
Spectral characteristics of speech sounds
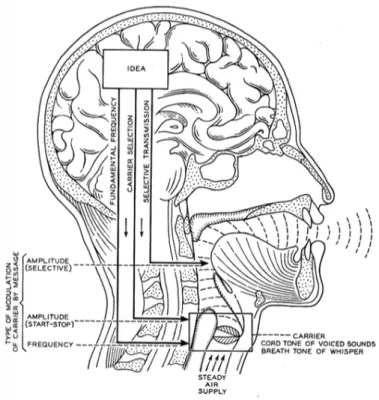
Speech is a complex sound created by a sound source, i.e. a carrier, dynamically modulated by the vocal tract. This carrier, together with the modulations, deter-mines the spectral structure of speech sounds at a given time point. Speech sounds might have one of two types of spectra: the harmonic and the continuous spec-trum. Therefore speech is a mix of harmonic sounds with periodic fluctuations, often comprised between 50 and 500 Hz, and non-harmonic sounds with aperiodic fluctuations, often above 1 kHz (Rosen, 1992).
The first type of spectral structure of speech sounds is the continuous, broad-band one. In this type of sounds, the carrier is the breath exhaled from the lungs without vibration of the vocal folds. When passing through the constrictions of the vocal tract the flow of air becomes aperiodic, i.e. turbulent, and produces a continuous, noise-like spectrum over a broad frequency band (Dudley, 1940). This category of sounds is called unvoiced and characterizes certain types of con-sonants. The aperiodic spectrum of unvoiced consonants has the highest energy at high frequencies (Rosen, 1992).
The second type of spectral structure of speech sounds is the harmonic one. This type of spectrum is produced by the vibration of the vocal folds. When in-dividuals speak, they tighten their vocal folds across the larynx in a cyclic way. This leads to the vibration of the vocal folds when breath is exhaled from the lungs. The periodicity of the vibration determines the spectrum of the sound: the frequency of vibration of the the vocal folds corresponds to the fundamental fre-quency (F0), i.e. the lowest frefre-quency of the spectrum, followed by its harmonics (also called formants), i.e. sine waves at each multiple of the fundamental fre-quency. The energy decreases with harmonics (i.e. the lowest harmonics have the most energy). The fundamental frequency is the main acoustic cue for perceived pitch (Moore, 2012), whereas formants characterize phonemic category. Speech sounds presenting this type of spectrum are called voiced sounds. They include
vowels and certain types of consonants (Chiba and Kajiyama, 1941).
This basic sound, the carrier, is dynamically modulated by the vocal tract. The vocal tract acts like a filter modulating the sound source (Fant, 1971). As the sound travels through the vocal tract, it is filtered by its cavities. By actively modifying the shape of their vocal tract and the size of the different cavities, speakers give rise to spectral peaks in the sound, suppress some frequencies, or introduce noise-like aperiodic sounds. Each cavity amplifies some frequencies, called its resonance frequencies, and reduces others depending on its shape and size. For voiced sounds, the vocal tract modulates the amplitude of the harmonics. As a result, some harmonics are more prominent than others in the speech spectrum.
For unvoiced, noise-like speech sounds, the vocal tract acts like a band pass. The final sound is aperiodic within a restricted frequency band centered at the reso-nance frequency of the vocal tract. The frequency band within which the spectrum is continuous depends on the location of constriction (Heinz and Stevens, 1961). If the constriction occurs at the back of the vocal tract (i.e. at or close to the vocal folds), the sound passes through several cavities and is therefore more modulated than if it is generated by a constriction at the front of the vocal tract (i.e. at the teeth or lips) and doesn’t travel through vocal cavities. The configuration of the vocal tract can also suppress some harmonics from the speech spectrum by shunting the sound to the nasal cavity. These suppressed frequencies are called zero poles or anti-formants (Fujimura, 1962). Noise-like, turbulent sounds can also be introduced on top of a harmonic voiced sound by blocking the air and suddenly releasing the air flow. In the case of unvoiced sounds, the air flow can be blocked at different locations of the vocal tract, creating a continuous spectrum in a frequency band corresponding to the resonance frequency of the cavity where blocking occurs. A continuous spectrum at low frequencies can also be introduced by shunting the air flow to the nasal cavity (Fujimura, 1962).
Therefore, a main characteristic of speech is that it is a modulated signal. In the spectral dimension by the vibration frequency of the vocal folds and the configuration of the vocal tract at each time point.
1.1.2
Temporal characteristics of speech sounds
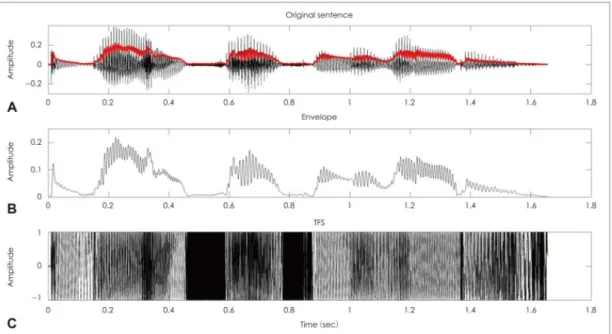
Speech intensity and spectral content vary over time in a characteristic way. The temporal structure of speech sounds can be decomposed into its amplitude enve-lope and its temporal fine structure (Rosen, 1992; Moore, 2008). The amplitude envelope, also known as amplitude modulations (AM) is defined by the slow fluc-tuations of the amplitude of the acoustic wave. Regardless of spectral content, the amplitude of a sound can vary, superimposing variations of intensity over time on top of the vibration frequency (Figure 1.1.2). In speech, modulations of ampli-tude over time are comprised between 2 and 120 Hz roughly (Rosen, 1992). The temporal fine structure can be defined as the instantaneous frequency, varying around a center frequency (Moore, 2008; Moon and Hong, 2014). Regardless of intensity, the instantaneous carrier frequency of the sound varies over time around
1.1. WHAT IS A SPEECH SOUND? 25
Figure 1.1: Speech as a modulated carrier. Adapted from Dudley et al. (1940).
a given central frequency. Temporal fine structure of speech is comprised between 600 Hz and 10 kHz (Rosen, 1992). They give speech sounds their spectral shape and so contain formant patterns. This temporal fine structure is modulated, as instantaneous frequency oscillates around a central value.
Temporal modulations in speech have characteristic rates and magnitudes, both for amplitude and frequency modulations. These characteristic values are visible in speech AM and FM spectra, defined as the amount of modulation as a function of modulation rate. The FM spectrum of speech follows a low-pass shape, with strong modulation below 8 Hz (Houtgast and Steeneken, 1985; Sheft et al., 2012; Varnet et al., 2017). The FM spectrum shows no difference between languages (Varnet et al., 2017). The AM spectrum shows a band-pass shape, with a peak of maximal amplitude or power between 4 and 5 Hz across numerous languages from different linguistic classes (Ding et al., 2017). However, small differences between languages arise in well-controlled semi-read speech segments, with a peak at about 5 Hz for syllable-timed languages and at about 4 Hz for stress-timed languages (Varnet et al., 2017).
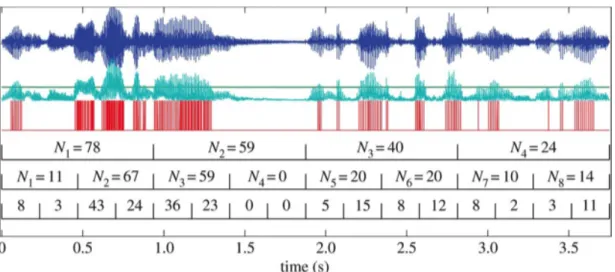
More complex models show that speech temporal structure comprises several temporal integration windows at different time scales (Selkirk, 1986; Nespor and Vogel, 2007). Peaks in the amplitude envelope are clustered at different time scales in a hierarchical way: they form small groups within small time-windows, and these small groups form larger ones when considered in larger time windows. This property has been found in a large variety of speech sounds (Kello et al., 2017).
Figure 1.2: Schematic representation of temporal modulations in speech. A: Wave-form of the original sentence (black), with its envelope superimposed (red). B: Envelope of the sentence shown in A. C: Temporal fine structure of the sentence shown in A. Adapted from Moon & Hong (2014).
The largest temporal window or slowest modulation scale is comprised between 1 and 4 Hz and corresponds to the phrasal level. Within these modulations, faster ones can be observed going from 4 to 8 Hz, corresponding to the syllable rate. This modulation rate has been identified as prominent across several languages, as visible in their speech modulation spectra (Ding et al., 2017; Varnet et al., 2017). This intermediate level finally contains smaller time windows of 20 to 30 ms, corresponding to modulations between 30 and 50 Hz. These rapid amplitude modulations correspond to the phonemic rate (Goswami and Leong, 2013). These models may differ in terms of the levels that they take into account: some models focus on the syllable (Ding et al., 2017), whereas others add the prosodic foot to take the stress-pattern into account (Goswami and Leong, 2013).
At the phonological level, speech temporal structure can be characterized by speech rhythm. Languages can be divided into three rhythmic classes: syllable-timed (e.g. French and Spanish), stress-syllable-timed (e.g. English), and mora-syllable-timed (Japanese). This hypothesis was originally made following impressionistic dif-ferences when listening to languages, with the idea that speech temporal struc-ture is organized in isochronous units, namely syllables, interstress intervals, and morae (Lloyd James, 1940; Pike, 1945). No acoustical evidence has supported the isochrony hypothesis. Instead, more recently, phonological accounts for these three categories have been provided. Relying on consonant and vowel durations, languages can be classified according to the ratio between the percentage of the
1.1. WHAT IS A SPEECH SOUND? 27
Figure 1.3: Top (blue): speech waveform. Middle (green): amplitude envelope. Bottom (red): peak event series. N: Event counts inside time windows (represented by brackets). Adapted from Kello et al. (2017).
sentence duration taken up by vowels, and the standard deviation of vocalic or con-sonantal intervals within sentences (Ramus et al., 2000). However, some languages remain difficult to classify in this typology (Grabe and Low, 2002). These metrics have also been shown to be highly sensitive to speaking style and speaker, more than to language and rhythmic class (Arvaniti, 2012), consistently with cross-linguistic differences in the AM spectra only for well-controlled speaking style (Varnet et al., 2017).
1.1.3
Speech sounds are variable
The acoustical characteristics of speech described in the two previous sections all vary in a significant way from one situation to another. Some acoustic variation carries linguistic significance, other differences are linked to meta-linguistic factors (e.g. speaker identity), yet others are random. Listeners need to be sensitive to relevant variation, while disregard irrelevant, random variability in the signal.
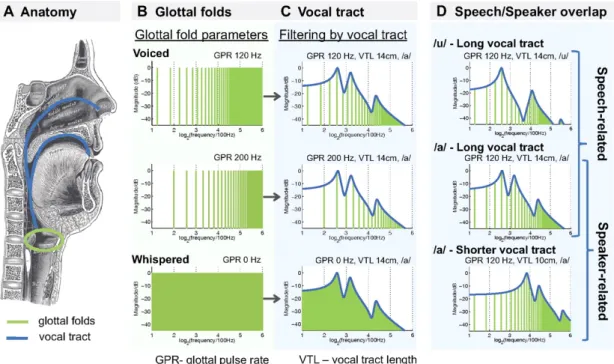
Linguistically, variability in the spectral domain allows to differentiate certain linguistic units. Spectral shape is one of the dimensions that define a phoneme. Therefore, spectral modulations introduced by the speaker’s vocal tract on a sim-ilar carrier differentiate phonemes (e.g. /u/ vs. /a/, see figure 1.1.3). In some languages, variation in pitch is used as a prosodical cue: higher pitch indicates stress, which allows listeners to discriminate words with different lexical stress. High-pitched syllables can also signal the boundaries between units at all levels of the sentence, e.g feet, words, or clauses (Nespor and Vogel, 2007). Variation in the F0 range within sentences can be used to emphasize a word or a clause (Vaissière, 1983). F0 contour also indicates whether a sentence is declarative or interrogative. Spectral variability can also carry information about the speaker. Formant
Figure 1.4: Spectral variations in the speech signal. Adapted from von Kriegstein et al. (2010).
ratio theories had initially stated that a given speech sound could be characterized regardless of its pitch: speech sounds would be relative patterns between formants, not absolute formant frequencies (Potter and Steinberg, 1950). Males and females have vocal tracts of different lengths. The longer vocal tract in males shifts the F0 the spectral content of speech, with male producing speech with a lower pitch than female speakers, who themselves produce speech with a lower pitch than children (e.g. Atkinson, 1978; Peterson and Barney, 1952). Accordingly, different spectral shapes between women and men have been measured for several types of consonants (Hagiwara, 1995; Schwartz, 1968). Regarding vowels, F0 and mean formants frequency vary between speakers of the same gender, speakers being distributed around an F1-F2 ratio for each vowel measured (Johnson et al., 1993). Finally, within speakers, F1 frequency may vary of +- 3 s.d. between acoustical realizations of the same vowel (Peterson and Barney, 1952). The scale factors of each vowel-formant couple were stable across languages (Fant, 1966, 1975), providing evidence for a range of variability that can be tolerated around the characteristic spectral shape.
Finally, F0 varies as a function of the speaking style and the emotion conveyed by the speaker. Emotions are associated with different mean F0 and different variability in F0. Sadness is reflected by reduced F0 and F0 range, whereas joy, anger, and fear are reflected by increased F0 and F0 range (Banse and Scherer, 1996). Although the mean F0 remains stable over speaking styles, vowel formants are shifted or spread compared to clear speech (Picheny et al., 1986).
1.1. WHAT IS A SPEECH SOUND? 29 Speech also varies significantly in the temporal domain. As for the spectrum, variability in the temporal domain can also differentiate units of different meaning. Vowel duration is reduced in function as compared to content words (Picheny et al., 1986). Some languages use variation of duration as phonologically contrastive, i.e. to define different phonemes (e.g. /a/ vs /a:/ in Finno-Ugric languages). Variation in the duration of speech sounds is also an important prosodic cue: longer syllables can indicate stress, which allows listeners to discriminate words in the case of lexical stress, or signal the boundaries between prosodic units (Nespor and Vogel,
2007). Speakers can also emphasize some words by varying their duration or
inserting pauses before an important one (Vaissière, 1983), which is reflected in speech rate.
Speech rate varies between speakers (Johnson et al., 1993), and across time. Various speech rates have been reported in the literature, from 130 words per minute (Keitel et al., 2018) to 160 (Giordano et al., 2017) and 210 words per minute (Di Liberto et al., 2015). Speech rate is also modulated by the emotions conveyed by the speaker. It is lower in fear than in joy and anger (Scherer et al., 1991).
This variability between utterances is context-dependent, varying with speak-ing style. In clear speech (i.e. when speakers aim to be more intelligible), speech rate is reduced by both inserting pauses between words and lengthening individ-ual speech sounds as compared to conversational speech. Conversely, in conversa-tional speech, vowels are reduced, and stop bursts are often not released, leading to shorter speech sounds (Picheny et al., 1986). Comparing adult-directed speech (ADS) to infant-directed speech (IDS), IDS has a slower rate. In IDS, temporal modulations are shifted towards lower modulation rates as compared to ADS. Even temporal structure can vary: in English, IDS presents a lower synchronization be-tween syllable-rate and phonemic-rate AM, but greater synchronization bebe-tween stress-rate and syllable-rate AM in IDS. This effect is modulated by the age of the targeted infant, highlighting the fact that speech sounds varies with context, which includes the listener (Fernald et al., 1989; Leong et al., 2014; Soderstrom, 2007).
Finally, as compared to conversational speech, clear speech shows a bigger dif-ference in power (perceived as loudness) between consonants and vowels (increase in RMS amplitude of consonants, particularly stop consonants) (Picheny et al., 1986). Variations in intensity are also used to indicate prosodic stress.
To sum up, the acoustical properties of speech constantly vary, both in the spectral and the temporal domains. The same variations carry both linguistic (e.g. word stress), and paralinguistic information (e.g. speaker identity or emotion). Variability is therefore a key feature of speech sounds, which contrasts with the invariant perception of speech that listeners experience everyday.
1.2
A stable perception of a variable sound
Despite the important variability described above, human listeners perceive speech in a stable way. They instantaneously recognize linguistic units such as phonemes, syllables and words. They perform this task effortlessly and are often not even conscious of the amount of variability between acoustical realizations of a given syllable or word. There is no direct relationship between the sound of a linguistic unit and its identity, but humans easily map the two. The efficiency of the human brain in this ability contrasts with the poor performance of machines in automatic speech recognition: for your cell phone to understand what you say, you need to articulate clearly and speak in a stereotyped way. This exemplifies that adapting to the acoustical variability in speech is a complex problem, and that to date we don’t understand how the human brain accomplishes this so efficiently. As speech sounds can be described in terms of their spectral and their temporal properties, we review the available data on this problem for these two sources of variability separately.
1.2.1
Adaptation to spectral variability
A great challenge for speech perception comes from the fact that spectral cues can carry both linguistic (e.g. phoneme identity) and paralinguistic information (e.g. gender or emotions) (see section 1.1). Listeners must tease apart spectral variability introduced by speakers and contexts to extract invariant linguistic units. At a behavioral level, adaptation to spectral variability of speech is performed effortlessly (e.g. Peterson and Barney, 1952). According to vocal tract normaliza-tion theories, listeners perceptually evaluate vowels on a talker-specific coordinate system (Joos, 1948). Hence, speaker normalization would be a necessary step achieved prior to the identification of specific speech sounds. In an MEG study, two vowel categories (/a/ vs /o/) were presented to participants, either shifting f0 trajectory (inducing a change in overall voice pitch) or modifying mean formant frequency (shift of the vowel spectrum without modifying spacing of harmonics nor formant pattern). Change in pitch elicited an N1m component in Heschl’s gyrus bilaterally, whereas change in vowel or mean formant frequency elicited an N1m in the planum temporale bilaterally, just behind Heschl’s gyrus (posterior STS). The early timing of this difference supports the claim that spectral normalization occurs prior to speech recognition (Andermann et al., 2017). In an identification task with lists of words said by multiple speakers, increasing variability (through the number of words and speakers) impeded the performance more when partici-pants attended to the voice than when they attended to the words (Mullennix and Pisoni, 1990). Consistently, adult participants better discriminated vowels while voice changes than they discriminate voices while the syllable changes. Looking at the ERPs, the P3 component was significantly smaller in amplitude and peaked significantly earlier in the vowel task than in the talker task, suggesting that, consistently with the behavioral results, discriminating vowels in the context of several voices required less resources than discriminating voices in the context of
1.2. A STABLE PERCEPTION OF A VARIABLE SOUND 31 several vowels (Kaganovich et al., 2006). Taken together, these results suggest that when listeners hear speech, they automatically normalize speaker variability at early stages of speech processing.
Other studies suggested that invariant representations could be extracted at higher levels of the speech processing stream. In an fMRI adaptation study, the left posterior medial temporal gyrus showed a rebound of activity when the word changed after adaptation to a word uttered by several speakers, meaning that an invariant representation of the word had already been coded in this region. No rebound of activity was observed when the speaker changed after adaptation to the same speaker pronouncing different words, meaning that this region was insensitive to speaker variability. This effect was not present when stimuli were pseudo-words, indicating that spectral normalization performed in the left medial temporal cortex (a region involved in auditory word form recognition) is specific to language processing (Chandrasekaran et al., 2011). In another study, the cortical activation pattern associated to discriminating several vowels uttered by several speakers partially overlapped with the one associated with discriminating speakers uttering different vowels, providing empirical support for speaker normalization at higher-level linguistic stages (Formisano et al., 2008).
At a behavioral level, variations both in F0 and in spectral shape (i.e. formant spacing) slow down vowel and word recognition (Magnuson and Nusbaum, 2007). fMRI studies revealed an increased activity in the right Heschl’s gyrus when par-ticipants discriminated shift in F0 despite changes of speaker (Kreitewolf et al., 2014). In another study, varying syllables f0 was associated with increased activity in Heschl’s gyrus in both hemispheres, whether the task performed by the partici-pants was linguistic (categorizing the syllables) or not (judging loudness). On the contrary, variations in spectral shape (i.e. mean formant frequency) activated the left STG/STS, and this activation was modulated by the task that participants performed: this region was more activated when participants had to categorize the syllables than when they had to judge the syllable loudness (von Kriegstein et al., 2010). Moreover, the same region was more activated when similar spectral manipulations were applied to speech sounds than when these spectral manipu-lations were applied to animal vocalizations (von Kriegstein et al., 2007). These results suggest that variability in spectral shape (i.e. mean formant frequency) is managed concurrently to speech recognition. All these results provide evidence that listeners deal with spectral variability in speech across different stages, with pitch normalization at early auditory stages prior to speech sound identification, and spectral shape normalization at later stages, integrated with linguistic pro-cessing. Several studies investigated how frequency modulations are encoded in humans. Although investigating the perception of spectral variability was not the main purpose of these studies, frequency modulations are dynamic changes around a center frequency. For this reason studies investigating the encoding of frequency modulations give insightful informations to study the encoding of spectral vari-ability, and build hypotheses about how this variability is managed. These studies used electro- or magneto-encephalography that provide information about neural
encoding at the population level (see section 2.2.1). In a first study, human par-ticipants listened to a tone modulated in amplitude at 37 Hz and in frequency between 0.3 and 8 Hz. An auditory steady-state response (aSSR, Picton et al. 2003) was observed in the auditory cortex at the AM frequency (i.e. 37 Hz) with spectral sidebands (i.e. secondary peaks) at AM+/- FM frequencies (e.g. 37.8 Hz if the tone FM rate was 0.8 Hz). Moreover, for slower FM (< 5 Hz), the phase of the aSSR at the AM frequency tracked the stimulus carrier frequency change (Luo et al., 2006). This encoding of frequency modulations through phase-locking was confirmed by subsequent studies. In particular, using complex tones frequency-modulated at 3 Hz, an aSSR was observed at the same frequency, and these delta oscillations were phase-locked to the tone FM (Henry and Obleser, 2012). Finally, using a larger range of FM, a last study replicated the aSSR at the FM frequency up to 8 Hz, but not above, providing further evidence for two distinct encoding mechanisms for FM (Millman et al., 2010). These studies show that frequency modulations are encoded by entrainment of neural activity at the FM rate, as shown by an aSSR at the corresponding frequency. Regarding spectral variability in speech, it is possible that a similar mechanism applies. Neural populations of the auditory cortex synchronize at the rate of the FM, this way adjusting their dynamic range to the range of the stimulus spectral variations.
1.2.2
Adaptation to temporal variability
As for spectral cues, temporal cues in speech can carry both linguistic (e.g. phoneme identity) and paralinguistic information (e.g. gender or emotions) (see section 1.1). Listeners must as well tease apart temporal variability linked to meta-linguistic informations or randomness to extract invariant linguistic units.
Adaptation to temporal variability of speech has been extensively studied using time-compressed speech. Behaviorally, successful adaptation to time-compressed speech has been observed in adults and older children, in tasks such as word com-prehension (Dupoux and Green, 1997; Orchik and Oelschlaeger, 1977; Guiraud et al., 2013), sentence comprehension (e.g. Ahissar et al., 2001; Peelle et al., 2004), or reporting syllables (Mehler et al., 1993; Pallier et al., 1998; Sebastián-Gallés et al., 2000). In these latter studies, participants had to report the words or sylla-bles they perceived in sentences compressed to 38%-40% of their initial duration, after having been habituated with compressed speech or after having received no habituation. Specifically, using 40% compression, Mehler et al. (1993) presented French or English sentences to French or English monolinguals and to French-English bilinguals. Participants reported higher numbers of words when they were initially habituated to and then tested in their native language. A follow-up study showed that Spanish-Catalan bilinguals adapted to Spanish or Catalan sentences compressed at 38% after habituation in the other language (i.e. habituation in Spanish before test in Catalan, and habituation in Catalan before test in Spanish). In two subsequent studies, English monolingual adults tested with 40% compressed English sentences benefited from habituation to time-compressed speech in Dutch,
1.2. A STABLE PERCEPTION OF A VARIABLE SOUND 33 which is rhythmically similar to English, and Spanish monolinguals tested with 38% compressed Spanish sentences benefited from habituation with Catalan and Greek, languages that shares rhythmic properties with Spanish (Pallier et al., 1998; Sebastián-Gallés et al., 2000). These studies show that adults are able to adapt to moderately compressed speech in their native language, as well as in unfamiliar languages, if those belong to the same rhythmic class as their native language.
Neuroimaging studies shed light on the cerebral networks supporting this abil-ity. In an fMRI study, (Peelle et al., 2004) presented syntactically simple or com-plex sentences compressed to 80%, 65%, or 50% of their normal duration. Time-compressed sentences produced activation in the anterior cingulate, the striatum, the premotor cortex, and portions of temporal cortex, regardless of syntactic com-plexity. Others studies found that some brain regions, e.g. Heschl’s gyrus (Nourski et al., 2009) and the neighboring sectors of the superior temporal gyrus (Vaghar-chakian et al., 2012), showed a pattern of activity that followed the temporal envelop of compressed speech, even when linguistic comprehension broke down, e.g. at 20% compression rate. Other brain areas, such as the anterior part of the superior temporal sulcus, by contrast, showed a constant response, not locked to the compression rate of the speech signal for levels of compression that were intelligible (40%, 60%, 80% and 100% compression), but ceased to respond for compression levels that were no longer understandable, i.e. 20% (Vagharchakian et al., 2012). This variety of response patterns is explained by different tem-poral receptive windows across brain regions: regions such as early auditory ar-eas have short temporal receptive window, integrating temporal events over short timescales, whereas higher regions such as anterior and posterior STG, IFG and supra-marginal gyrus integrate information over longer time windows and collapse above a certain amount of information contained in their temporal receptive win-dow, i.e. when speech is too compressed (Davidesco et al., 2018; Lerner et al., 2014). In children (from 8 to 13 years old), responses to fast speech occurred in the left-premotor, primary motor regions, and Broca’s area, as well as in right inferior frontal and anterior superior temporal cortices (Guiraud et al., 2018). In summary, adaptation to speech temporal variability involves a distributed cerebral network that includes both sensory and higher-level cortical regions.
On the neurophysiological side, several studies have investigated how adap-tation to speech rate is accomplished. The role of the theta rhythm (4-8 Hz) for adaptation to speech rate was first suggested by behavioral results. When silent in-tervals are introduced within sentences compressed to 33% of their initial duration, comprehension is restored if silences occur at a periodical rate that restores the theta-syllable rhythm – 80ms silences following 40 ms of time-compressed speech, aligning with the typical 120 ms duration of syllables (Ghitza and Greenberg, 2009). Accordingly, when adults listen to time-compressed speech, oscillatory ac-tivity is phase-locked to the envelope of the sound in the theta band. Speech com-pressed to 50% or 33% of its initial duration elicited an increase in power shared by EEG and acoustic signals in the frequency band corresponding to the syllabic rate of each condition. Moreover, increased syllable rate in time-compressed speech led
to an increase in power in the theta band, and a decrease in power in the gamma band (27-28 Hz). Phase-locking occurred for normal speech as well as for the two compression rates (Pefkou et al., 2017). These results were partly replicated in typically developing children (from 8 to 13 years old) who listened to normal and naturally fast speech while oscillatory activity was recorded through MEG. For both normal and fast speech, phase-coherence between oscillatory activity and the envelope of the sentences was increased in the theta band (4-7 Hz) as compared to baseline (when no sound was presented). However, no increase in power was observed in this group of children (Guiraud et al., 2018). Looking at a broader fre-quency band, oscillatory activity was phase-locked to the time-compressed speech envelope in a broad 0-20 Hz band (Ahissar et al., 2001). Phase-locking to the envelope of time-compressed sentences was also observed in the high-gamma band (70Hz and above) across compression levels from 20 to 75% of initial duration, i.e. even when participants didn’t understand the sentences (Nourski et al., 2009). All these results were observed whether or not the participant understands the sentences, although phase-locking correlated with comprehension in the broad 0-20 Hz range (Ahissar et al., 0-2001). These results highlight the fact that different brain regions respond differently to variations in speech rate: early auditory re-gions track envelope at all compression rates (Davidesco et al., 2018; Nourski et al., 2009), whereas regions further along the auditory hierarchy track the envelope only during comprehension (Davidesco et al., 2018). These results also stress the im-portance of envelope-tracking by cortical activity as a prerequisite to adapt (as reflected in adults by comprehension) to time-compressed speech, but also shows that envelope tracking is in itself insufficient to explain comprehension. To con-clude, adaptation to speech rate variability is done by following the envelope of speech sounds and phase-locking oscillations in the theta and high-gamma bands, which correspond to two important rhythmic scales of speech sounds (i.e. syllabic and phonemic scales), although other mechanisms are also necessary to provide a full account of the perception of time-compressed speech.
1.3
Dealing with acoustical variability in speech
at birth
1.3.1
Why newborns: Looking at the auditory foundations
of speech perception
Birth represents a particular moment in the course of sensory development. Sen-sory systems have already started their development and are functional in utero (Abdala and Keefe, 2012; Eggermont and Moore, 2012), but they have never faced faces and visual objects, experienced the intensity of daylight, smelled other odors than the amniotic fluid, or heard unfiltered sounds, without maternal physiological background noise. Sensory signals are greatly modified by maternal tissues that attenuate the light and high-frequency sounds (Querleu et al., 1988). Therefore,
1.3. ACOUSTICAL VARIABILITY AT BIRTH 35 at birth, the physical properties of sensory stimulations suddenly change. Despite transnatal continuity in sensory development, newborns face the external world for the first time, and as such have little experience with broadcast sensory signals. They experience a transition from a dark, attenuated environment to a bright one with louder and spectrally richer sounds. For this reason, they offer a window on the core of sensory systems. It has been suggested that the auditory system is adapted to the statistical structure of natural sounds (Mizrahi et al., 2014; The-unissen and Elie, 2014). Speech is a particularly significant one in the newborn’s environment, given the importance of vocal communication in our species. If this hypothesis is true, adaptation of the auditory system to speech should be ob-servable in the absence of linguistic expertise, at the first contact with broadcast speech, i.e. at birth.
The goal here is not to talk about innate capacities as opposed to acquired skills, but rather to describe a set of tools that newborns have to face the external world and with which they will start to build their cognitive skills during the first months of life. Among these available tools, auditory processing is of great importance as it constrains the information fed into the linguistic system (Friederici, 2002). It is thus essential to understand auditory perception in this transitional state in order to understand the building blocks of speech perception. Development provides the opportunity to observe how cognitive functions emerge as an interplay of different biological and experiential factors.
The majority of studies that investigated the processing of variability in speech, especially the perception of temporally and spectrally distorded sounds, involved adults and children (see section 1.2). These participants have high linguistic exper-tise, which makes it difficult to disentangle the relative contributions of auditory and linguistic linguistic knowledge. Infants are not yet linguistic experts, but they already have intensive experience with speech sounds and important linguistic ca-pacities by the end of the first year of life (Gervain and Mehler, 2010). Newborns represent a temporal window before language acquisition and considerable experi-ence with broadcast sensory signals influexperi-ence sensory perception. Thus, investigat-ing newborn’s speech perception abilities are essential to a better understandinvestigat-ing of the auditory foundations of speech processing. The present work focuses on this transitional period, testing infants between 1 and 4 days of life.
1.3.2
Auditory processing at birth
How are newborns equipped to perceive the auditory world when they face it for the first time? Humans are born with a relatively well-developed auditory system. The first behavioral signs of fetal audition, measured by motions or heat rate after a sound is presented close to the mother’s abdomen, can be observed around 26 weeks of gestation (Birnholz and Benacerraf, 1983). Anatomically, the cochlea is operational around 24 weeks of gestation. However, the outer and middle ear are still immature at birth, filtering and amplifying sounds differently than the adult ear. The auditory nervous system is also immature at birth, the auditory nerve
showing less precise phase-locking to temporal modulations (Moore and Linthicum, 2007; Abdala and Keefe, 2012).
Despite this physiological immaturity, numerous studies provide evidence for well developed functional responses to sounds. By the last month of gestation, fe-tuses discriminate speech from piano melodies, irrespective of spectral content, in-dicating that they perceive temporal structure of complex sounds (Granier-Deferre et al., 2011). Consistently, omission of the downbeat in sequences of musical in-struments provokes a mismatch response with two peaks, around 200 and 400 ms, showing that newborns build expectations about the temporal structure of a sound sequence (Winkler et al., 2009). Regarding spectral processing, a pure tone with a different pitch than the preceding ones elicits a mismatch negativity (MMN) response in newborns aged 1 to 4 days (Alho et al., 1990). This result was then replicated with more complex sounds. Newborns present a different brain response to musical sounds of different timbre but the same pitch, than to a sound with a dif-ferent pitch than the preceding ones (Háden et al., 2009). These results show that newborns are capable of extracting and processing pitch cues in complex sounds. Newborns can even detect complex spectro-temporal structures. Indeed, blocks of stimulation presenting sounds in which the temporal structure scaled relative to the center frequency (a characteristic feature of natural environmental sounds), or sounds that lacked this structure elicited a larger hemodynamic response in the left frontal and left temporal cortices than blocks with an alternation of the two types of structure, indicating that newborns discriminate the two types of spectro-temporal structure (Gervain et al., 2016). This provides evidence that newborns process spectral and temporal features in a integrated way to detect the complex spectro-temporal structures present in natural sounds.
Taken together, these results provide evidence for substantial auditory capac-ities at birth, laying the foundations for sophisticated speech perception abilcapac-ities. Given the fact that audition is functional during the last trimester of gestation, and that low-frequency components of speech are transmitted through the womb (Querleu et al., 1988), this opens the possibility of prenatal experience shaping speech perception at birth. In particular, if low-frequency modulations of speech are transmitted through the womb, it is possible that fetuses are familiarized with speech temporal envelope during the last trimester of gestation.
1.3.3
Suggestive evidence for stable perception of speech
at birth
Despite their lack of experience with broadcast speech, newborns show prelin-guistic capacities that suggest that they are capable of extracting an invariant representation of speech from variable sounds.
A first line of evidence is the preference for speech sounds from birth. Behav-iorally, newborns make more headturns to unfiltered speech than to heartbeat (a familiar stimuli from their intra-uterine life) or filtered speech, either low-pass as heard in the womb, high-pass or band-pass (Ecklund-Flores and Turkewitz, 1996).
1.3. ACOUSTICAL VARIABILITY AT BIRTH 37 They also adjust their sucking rate to hear speech sounds rather than sine waves tracking the fundamental and the first three formants. These stimuli retained the duration, pitch contour, amplitude envelope, relative formant amplitude, and rela-tive intensity of their speech counterparts (Vouloumanos and Werker, 2007). These results suggest that newborn participants prefer to hear natural speech sounds, a preference that cannot be explained by familiarity with the stimuli or the simple spectro-temporal properties of the sound. On the neural side, the right temporal and right frontal cortex respond more to speech sounds than to other vocal sounds such as human emotional sounds or monkey calls (Cristia et al., 2014). Together, all these results suggest that readily from birth humans would be equipped with an auditory module dedicated to speech sounds, to process them with auditory and cognitive mechanisms.
A second set of studies investigated speech-specific processing comparing it to backward speech. Backward speech preserves the spectral content of speech but disturbs its temporal structure, sounding nothing like speech while being a good acoustical control. At 3 months, forward speech produced a larger activation than backward speech in the left angular gyrus and left mesial parietal lobe. No greater activation was found for backward speech, adding evidence for a preferential pro-cessing of speech sounds from the first months of life (Dehaene-Lambertz et al., 2002). Here, the difference between natural speech sounds and spectral analogs appeared in cortical regions outside of STS and STG, which are typically acti-vated in studies comparing speech to other categories of natural sounds. Different results have been found in the neonatal brain. In a NIRS study, forward speech elicited a larger response than backward speech and silence in the temporal cortex, with larger responses in the left hemisphere for forward speech (Pena et al., 2003). Other studies investigated the role of prenatal experience. In these studies, partici-pants listened to their native language or a foreign language, played either forward or backward. Forward speech evoked a larger activity than backward speech in the left temporal area for the native, but not the foreign language (Sato et al., 2012). This result was replicated and extended in an independent laboratory: when the experiment presented forward and backward speech in the native and a foreign language, forward speech evoked a larger response than backward speech in bilateral fronto-temporal regions in the native language, but not in the foreign language. But when the same foreign language was presented with a whistled sur-rogate language, forward speech triggered a larger response than backward speech in a similar but smaller region, and only in the left hemisphere. No difference was observed between forward and backward for the surrogate whistled language (May et al., 2018). However, another similar study found the reverse pattern with speech low-pass filtered at 400 Hz to mimic what is heard in the womb. Backward speech elicited a larger response than forward speech in the bilateral temporal cortices and in the right frontal cortex for the foreign language, while the native language triggered a similar response independently of directionality in both the left and right temporal cortices (May et al., 2011). This suggests that the neonatal brain preferentially responds to sounds with the canonical temporal structure of speech,
and that this capacity modulated by context and prenatal experience.
A final set of studies have provided evidence for extraction of invariant speech patterns across speakers. In an ERP study, newborns were presented with se-quences of four syllables recorded from four different speakers. Among the four syllables, the first three were always from the same phonemic category, i.e. /ta/ or /pa/, and the fourth one were either from the same category as the first three (standard trials) or from the other category (deviant trials). In half of the tri-als, the four syllables were spoken by the same speaker, and in the other half by four different speakers. Newborn participants presented a mismatch response to the phonemic change (/ta/ vs /pa/), whether or not the speaker remained the same (Dehaene-Lambertz and Pena, 2001). This result was partially replicated in preterm newborns. In two EEG and NIRS experiments, participants listened to series of four syllables with the last one being either the same as the first three (standard blocks), or from another phonemic category (/ba/ vs /ga/) or spoken by a different speaker (deviant blocks). Interestingly, similar results were observed in ERP data, with a mismatch response only to the deviant phoneme, but time-frequency analysis of the EEG signal also revealed a response to the change of voice, although smaller and in different clusters of electrodes than the change of phoneme (Mahmoudzadeh et al., 2017). NIRS results mirrored the time-frequency results, with a larger hemodynamic response to deviant phoneme as compared to the standard blocks in large portion of the frontal lobe bilaterally, and smaller response that quickly faded away only in one channel of the right frontal lobe to the change of voice (Mahmoudzadeh et al., 2013). Taken together, these results suggest that the neonatal brain identifies speech sounds, and perform pre-linguistic operations on it despite acoustical variability due to multiple speakers.
1.3.4
The aims of the current thesis
To what extent is this preferential processing for speech robust to acoustical vari-ability and distortions? Does the capacity of adult listeners to normalize acoustical variability in speech come from their linguistic expertise or are they part of these initial speech- and vocalizations-specific auditory mechanisms? The present work aims at answering these questions by looking at the processing of spectral and tem-poral variability of speech before the emergence of considerable linguistic expertise, namely in the neonatal brain.
The aim of this work is to establish how newborns build a stable representation
of speech despite its acoustical variability. As described in section 1.1.3, this
variability is manifested both in the temporal and the spectral domains. It has been shown that adult listeners are able to normalize speech variability up to a certain level, both in the spectral and temporal domains. The speech perception abilities shown by newborns in the context of several speakers suggest that their auditory system is able to normalize this variability to build a stable auditory representation of speech. However, how the newborn’s brain achieve to manage this variability has never been explicitly investigated. This work therefore aims to
1.3. ACOUSTICAL VARIABILITY AT BIRTH 39 fill several objectives:
First to determine whether or not newborns can normalize acoustical variability in speech and build a stable representation of it. If this is the case, determine if this is possible for temporal variability, spectral variability, or both.
Second to elucidate the neural mechanisms that support this capacity in new-borns, and map them in the brain. We here aim to determine the building blocks of these circuits, i.e. the brain regions already involved at birth, and possibly cortical regions activated in newborns but not in adults. The existing models of electro-physiological mechanisms to encode speech are based on adult data, and don’t make predictions about the developmental origins of these mechanisms. We here aim to explore the neurophysiological tools that newborns have at their disposal to manage speech spectral and temporal variability.