Energy Efficient Techniques using FFT for Deep Convolutional Neural Networks
Texte intégral
Figure


Documents relatifs
The image has been restored exactly, because the point spread function used for deblurring was identical to the point spread function used for blurring, and there was no noise.
pushing forward to weakly supervised learning the problem Medical Image Segmentation of Thoracic Organs at Risk in CT-images..
As deep learning models show an impressive ability to recognize patterns in images, many researchers propose deep learn- ing based steganalysis methods recently.. [11] reported
This study deals with forecasting indoor pollutant concentrations and in particu- lar HCHO in an open place office, the focus goes beyond the mere estimation and take account of
2 A user-defined hyperparameter... Pavia University image. The output layer has only one neuron, and its activa- tion function is the sigmoid. After the training, the two
that the deep learning hierarchical topology is beneficial for musical analysis because on one hand music is hierarchic in frequency and time and on the other hand relationships
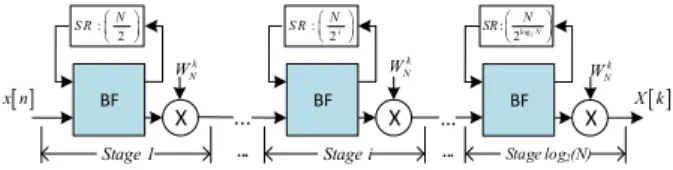
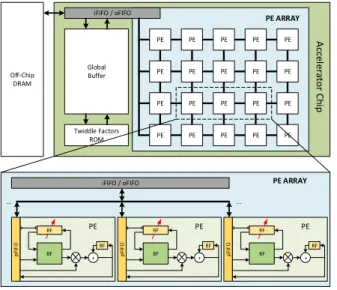
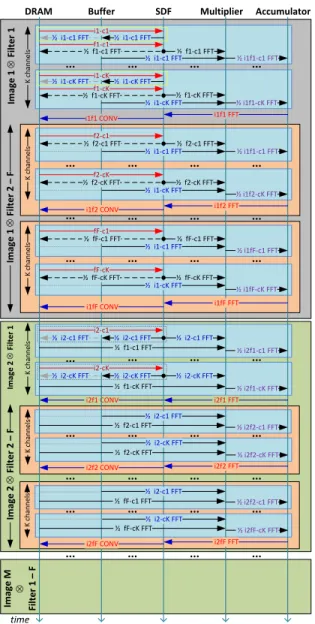
of parametrization, the FFT operator can be reconfigured to switch from an operator dedicated to compute the Fast Fourier Transform in the field of complex numbers to an operator
Even though our CPU is quite powerful, running the back-propagation algorithm took a long time (approximately 20 minutes to compute the feature importances for a 4 hidden layers
